Elastic Stack-Elasticsearch使用介绍(三)
一、前言
上一篇说了这篇要讲解Search机制,但是在这个之前我们要明白下文件是怎么存储的,我们先来讲文件的存储然后再来探究机制;
二、文档存储
之前说过文档是存储在分片上的,这里要思考一个问题:文档是通过什么方式去分配到分片上的?我们来思考如下几种方式:
1.通过文档与分片取模实现,这样做的好处在于可以将文档平均分配到所以的分片上;
2.随机分配当然也可以,这种可能造成分配不均,照成空间浪费;
3.轮询这种是最不可取的,采用这种你需要建立文档与分片的映射关系,这样会导致成本太大;
经过一轮强烈的思考,我们选择方案1,没错你想对了,这里Elasticsearch也和我们思考的是一样的,我们来揭露下他分配的公式:
shard_num = hash(_routing)%num_primary_shards
routing是一个关键参数,默认是文档id,可以自行指定;
number_of_primary_shard 主分片数;
之前我们介绍过节点的类型,接下来我们来介绍下,当文档创建时候的流程:
假设的情况:1个主节点和2个数据节点,1个副本:
文档的创建:
1.客户端向节点发起创建文档的请求;
2.通过routing计算文档存储的分片,查询集群确认分片在数据节点1上,然后转发文档到数据节点1;
3.数据节点1接收到请求创建文档,同时发送请求到该住分片的副本;
4.主分片的副本接收到请求则开始创建文档;
5.副本分片文档完成以后发送成功的通知给主分片;
6.当主分片接收到创建完成的信息以后,发送给节点创建成功的通知;
7.节点返回结果给客户端;
三、Search机制
搜索的类型其实有2种:Query Then Ferch和DFS Query Then Ferch,当我们明白如何存储文件的是时候,再去理解这两种查询方式会很简单;
Query Then Ferch
Search在执行的时候分为两个步骤运作Query(查询)和Fetch(获取),基本流程如下:
1.将查询分配到每个分片;
2.找到所有匹配的文档,并在当前的分片的文档使用Term/Document Frequency信息进行打分;
3.构建结果的优先级队列(排序,分页等);
4.将结果的查询到的数据返回给请求节点。请注意,实际文档尚未发送,只是分数;
5.将所有分片的分数在请求节点上合并和排序,根据查询条件选择文档;
6.最后从筛选出的文档所在的各个分片中检索实际的文档;
7.结果将返回给客户端;
DFS Query Then Ferch
DFS是在进行真正的查询之前, 先把各个分片的词频率和文档频率收集一下, 然后进行词搜索的时候, 各分片依据全局的词频率和文档频率进行搜索和排名,基本流程如下:
1.提前查询每个shard,询问Term和Document frequency;
2.将查询分配到每个分片;
3.找到所有匹配到的文档,并且在所有分片的文档使用Term/Document Frequency信息进行打分;
4.构建结果的优先级队列(排序,分页等);
5.将结果的查询到的数据返回给请求节点。请注意,实际文档尚未发送,只是分数;
6.来自所有分片的分数合并起来,并在请求节点上进行排序,文档被按照查询要求进行选择;
7.最终,实际文档从他们各自所在的独立的分片上检索出来;
8.结果被返回给客户端;
总结下,根据上面的两种查询方式来看的DFS查询得分明显会更接近真实的得分,但是DFS 在拿到所有文档后再从新完整的计算一次相关性算分,耗费更多的cpu和内存,执行性能也比较低下,一般不建议使用。使用方式如下:

另外要是当文档数据不多的时候可以考虑使用一个分片;
这个地方我们在做一些深入的思考:我们搜索的时候是通过倒排索引,但是倒排索引一旦建立是不能修改的,这样做有那些好处坏处?
好处:
1.不用考虑并发写入文件的问题,杜绝锁机制带来的性能问题;
2.文件不再更改,可以充分利用文件系统缓存,只需载入一次,只要内容足够,对该文件的读取都会从内存中读取,性能高;
坏处:
写入新文档时,必须重新构建倒排索引文件,然后替换老文件后,新文档才能被检索,导致文档实时性差;
问题:
对于新插入文档的时候写入倒排索引,导致倒排索引重建的问题,假如根据新文档来重新构建倒排索引文件,然后生成一个新的倒排索引文件,再把用户的原查询切掉,切换到新的倒排索引。这样开销会很大,会导致实时性非常差。
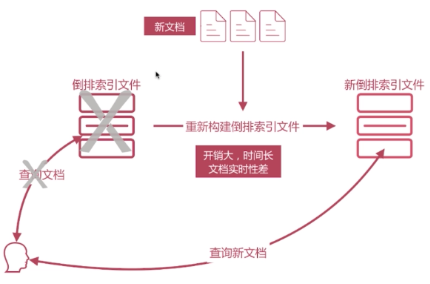
Elasticsearch如何解决文件搜索的实时性问题:

新文档直接生成新的倒排索引文件,查询的时候同时查询所有的倒排文件,然后做结果的汇总计算即可,ES是是通过Lucene构建的,Lucene就是通过这种方案处理的,我们介绍下Luncene构建文档的时候的结构:
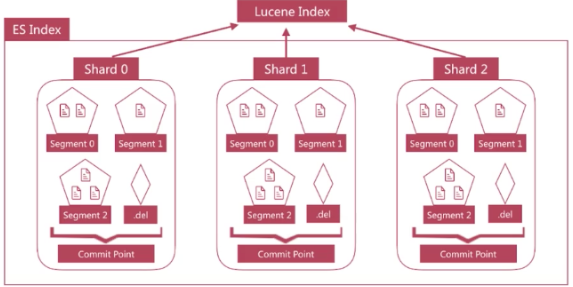
1.Luncene中单个倒排索引称为Segment,合在一起称为Index,这个Index与Elasticsearch概念是不相同的,Elasticsearch中的每个Shard对应一个Lucene Index;
2.Lucene会有个专门文件来记录所有的Segment信息,称为Commit Point,用来维护Segment的信息;
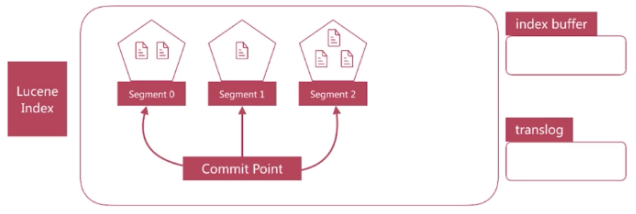
Segment写入磁盘的时候过程中也是比较慢的,Elasticsearch提供一个Refresh机制,是通过文件缓存的机制实现的,接下我们介绍这个过程:
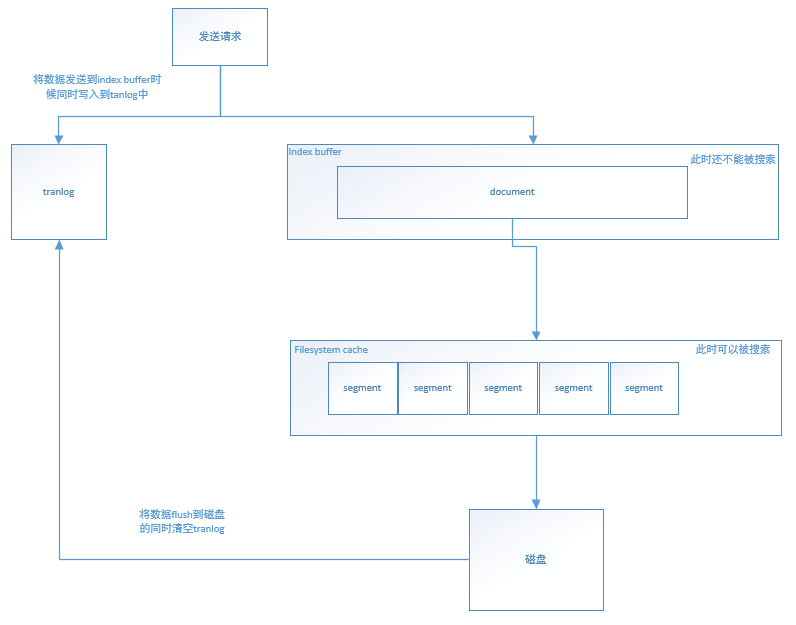
1.在refresh之前的文档会先存储在一个Buffer里面,refresh时将Buffer中的所有文档清空,并生成Segment;
2.Elasticsearch默认每1秒执行一次refresh,因此文档的实时性被提高到1秒,这也是Elasticsearch称为近实时(Near Real Time)的原因;
Segment写入磁盘前如果发生了宕机,那么其中的文档就无法恢复了,怎么处理这个问题?
Elasticsearch引入translog(事务日志)机制,translog的写入也可以设置,默认是request,每次请求都会写入磁盘(fsync),这样就保证所有数据不会丢,但写入性能会受影响;如果改成async,则按照配置触发trangslog写入磁盘,注意这里说的只是trangslog本身的写盘。Elasticsearch启动时会检查translog文件,并从中恢复数据;
还有一种机制flush机制,负责将内存中的segment写入磁盘和删除旧的translog文件;
新增的时候搞定了,那删除和更新怎么办?
删除的时候,Lucene专门维护一个.del文件,记录所有已经删除的文档,del文件上记录的是文档在Lucene内部的id,查询结果返回前过滤掉.del中的所有文档;
更新就简单了,先删除然后再创建;
随着Segment增加,查询一次会涉及很多,查询速度会变慢,Elasticsearch会定时在后台进行Segment Merge的操作,减少Segment的数量,通过force_merge api可以手动强制做Segment Merge的操作;
另外可以参考下这篇文段合并;
四、下节预告
本来还想说下聚合、排序方面的查询,但是看篇幅也差不多了,留点时间出去浪,最近不光要撒狗粮,也要撒知识,国庆节期间准备完成Elastic Stack系列,下面接下来还会有4-5篇左右,欢迎大家加群438836709,欢迎大家关注我公众号!

Elastic Stack-Elasticsearch使用介绍(三)的更多相关文章
- Elastic Stack之ElasticSearch分布式集群二进制方式部署
Elastic Stack之ElasticSearch分布式集群二进制方式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家都知道ELK其实就是Elasticsearc ...
- Elastic Stack之ElasticSearch分布式集群yum方式搭建
Elastic Stack之ElasticSearch分布式集群yum方式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搜索引擎及Lucene基本概念 1>.什么 ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- Elastic Stack核心产品介绍-Elasticsearch、Logstash和Kibana
Elastic Stack 是一系列开源产品的合集,包括 Elasticsearch.Kibana.Logstash 以及 Beats 等等,能够安全可靠地获取任何来源.任何格式的数据,并且能够实时地 ...
- ES 集中式日志分析平台 Elastic Stack(介绍)
一.ELK 介绍 ELK 构建在开源基础之上,让您能够安全可靠地获取任何来源.任何格式的数据,并且能够实时地对数据进行搜索.分析和可视化. 最近查看 ELK 官方网站,发现新一代的日志采集器 File ...
- 集中式日志分析平台 Elastic Stack(介绍)
一.ELK 介绍 二.ELK的几种常见架构 >>ELK 介绍<< ELK 构建在开源基础之上,让您能够安全可靠地获取任何来源.任何格式的数据,并且能够实时地对数据进行搜索.分析 ...
- 浅尝 Elastic Stack (一) Elasticsearch、Kibana、Beats 安装
Elastic Stack 包括 Elasticsearch.Kibana.Beats 和 Logstash,也称为 ELK Stack.能够安全可靠地获取任何来源.任何格式的数据,然后实时地对数据进 ...
- Elastic Stack(ElasticSearch 、 Kibana 和 Logstash) 实现日志的自动采集、搜索和分析
Elastic Stack 包括 Elasticsearch.Kibana.Beats 和 Logstash(也称为 ELK Stack).能够安全可靠地获取任何来源.任何格式的数据,然后实时地对数据 ...
- 三十八 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticse ...
随机推荐
- Python爬虫10-页面解析数据提取思路方法与简单正则应用
GitHub代码练习地址:正则1:https://github.com/Neo-ML/PythonPractice/blob/master/SpiderPrac15_RE1.py 正则2:match. ...
- Android开发:Eclipse+OpenCV环境搭建
一.OpenCV预备: OpenCV是一个跨平台计算机视觉库,可以运行在Linux.Windows.Android和Mac OS操作系统上.它由一系列 C 函数和少量 C++ 类构成,同时提供了Pyt ...
- 这些好用的 Chrome 插件,提升你的工作效率
本文首发于我的公众号 Linux云计算网络(id: cloud_dev),专注于干货分享,号内有 10T 书籍和视频资源,后台回复「1024」即可领取,欢迎大家关注,二维码文末可以扫. Google ...
- Identity Server 4 - Hybrid Flow - 使用ABAC保护MVC客户端和API资源
这个系列文章介绍的是Identity Server 4 实施 OpenID Connect 的 Hybrid Flow. 保护MVC客户端: https://www.cnblogs.com/cgzl/ ...
- Python + PyQt5 实现美剧爬虫可视工具(二)
美剧<权力的游戏>终于开播最后一季了,在上周写了个简单的可视化美剧的爬虫软件来爬取美剧,链接:https://www.cnblogs.com/weijiutao/p/10614694.ht ...
- NormalDialogFragmentDemo【普通页面的DialogFragment】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 该Demo主要演示DialogFragment作为普通页面,显示全屏和状态栏下方的效果以及动画效果. 效果图 代码分析 @Overr ...
- c++智能指针和二叉树(1): 图解层序遍历和逐层打印二叉树
二叉树是极为常见的数据结构,关于如何遍历其中元素的文章更是数不胜数. 然而大多数文章都是讲解的前序/中序/后序遍历,有关逐层打印元素的文章并不多,已有文章的讲解也较为晦涩读起来不得要领.本文将用形象的 ...
- 六大设计原则(四)ISP接口隔离原则(上)
ISP的定义 首先明确接口定义 实例接口 我们在Java中,一个类用New关键字来创建一个实例.抛开Java语言我们其实也可以称为接口.假设Person zhangsan = new Person() ...
- 可以让你神操作的手机APP推荐 个个都是爆款系列
手机在我们的生活中显得日益重要,根据手机依赖度调查显示,69%的人出门时必带手机,20%的人经常在吃饭睡觉.上卫生间时使用手机:43%的人早上起床第一件事就是查看手机,不用多说,我们对于手机的依赖性越 ...
- 使用 MapTiler 进行地图切片
在GIS开发中接触比较多的就是切图与发布,通常大家使用的是GlobalMapper.ArcGIS.GDAL等. 一般在使用Leaflet.js或其他框架开发时,使用的是TMS切片格式,大佬们基本用GD ...