走进Java Map家族 (1) - HashMap实现原理分析
在Java世界里,有一个古老而神秘的家族——Map。从底层架构到上层应用,他们活跃于世界的每一个角落。但是,每次出现时,他们都戴着一张冷硬的面具(接口),深深隐藏着自己的内心。所有人都认识他们,却并非每个人都理解他们。在这个热闹的世界中,Map们活得光荣却孤独……这个系列博文,就将尝试透过接口的伪装,走进每个家族成员的内心世界,聆听家族内部的动人传说……
注:各种Map在不同的JDK中有不同的实现。如无特别声明,本文只针对当前(2019年3月)最新的OpenJDK(13-ea)的实现
一、从HashMap开始
好了,上面都是扯淡,目的是为了让气氛更加尴尬……
第一个介绍的Map成员是HashMap,因为它应用最广,实现也最简单——简单到我一直在纠结要不要单独为它写一篇文章。代码在这里
HashMap将键值对存储于若干个bin中。所谓bin(或者叫bucket、桶),是一个可以保存多个键值对的数据结构。初始状态下,一个bin就是一个链表。具体代码如下
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
transient Node<K,V>[] table;
Node类是链表的元素。变量table是一个链表的数组,或者说是bin的数组。HashMap所有的数据就保存在table中。(或许你注意到了transient关键字。HashMap并不直接序列化table变量,而是重写了writeObject和readObject处理数据的序列化)
当向HashMap中put数据时,首先计算key的hashCode,根据hashCode找到它所属的bin,然后将键值对放入bin中,也就是插入到链表的末尾。可见,有相同hashCode的两个key,一定会放入同一个bin中,这种现象叫hash冲突(hash collision)。而get的过程也一样,计算key的hashCode并找到对应的bin,然后在bin中搜索包含相同key的Node。
以上是HashMap的基本实现原理。
二、扩容(resize)与树化(treeify)
可见,put和get消耗的时间与链表长度是o(n)的关系。如果数据量太大,每一个链表都会很长;或者运气太差,大部分数据都集中于一个bin中,这时HashMap的性能就会迅速下降。怎么办呢?
有两种思路,要么是缩短链表长度,要么是提高bin的搜索速度。HashMap的具体策略也是从这两方面入手。每次put数据时,都记录Map中整体的数据量,以及链表的长度,然后
(1)当整体数据量超过bin的数量的3/4时,增加bin的数量,这个过程叫扩容(resize)。扩容后,各条数据都要重新计算它属于哪个bin,这叫做rehash。这样,有些数据移动到新的bin中,各个bin的链表长度就会缩短。
(2)当某个链表很长(超过7),而bin的数量很少(小于等于64个),也会扩容,以缩短链表。
(3)当某个链表长度超过7,而bin的数量大于64个,就将这个bin由链表转变为红黑树,提高搜索速度。这个过程叫做树化(treeify)。树化是在JDK 1.8才实现的。
为什么不一开始就使用树呢?个人理解,这是出于时间-空间的综合考量。当数据量很小时,树的搜索速度并不明显优于链表,而占用的空间却比链表多,因此初始选择是链表,遇到性能瓶颈也优先选择扩容。
而当bin足够多时,继续扩容就会出现问题:
(1)继续扩容也会增加空间占用(而且占用的是连续空间。还记得table是一个数组吗?)。相比于树化,扩容不再具有空间上的优势。
(2)resize之后要对所有的数据做rehash,当数据量很大时,rehash的性能负担远高于对单个bin做树化。
可以说,扩容改变所有数据的分布方式,是一种针对整体的优化方案;树化只改变单个bin的结构,是针对局部的优化方案。如果bin很多却依然存在很长的链表,说明整体优化方案对于某个bin不起作用,这可能是hashCode分布不均匀导致的。继续扩容徒然增加空间,效果却不见得理想。这时,就该采用局部优化方案,也就是树化了。
以上纯属个人理解与猜测,仅供参考。
最后说一点,bin的数量并非到了64之后就不再增长了。根据策略(1),只要整体数据量足够多,就会扩容。不过,扩容也不是无限的,毕竟数组太大了也会造成问题。bin的最大数量是2的30次方,或者写成1<<<30。
三、hashCode与扩容策略
如何根据hashCode找到数据所属的bin?每次扩容增大多少?如何rehash?这几个问题互相关联。
最简单的方案当然是取余。假设bin的数量为N,key的hashCode为H,那么key所属的bin就是第H%N个。而扩容可以任意增加bin的数量。比如扩容后的bin有N+M个,rehash时某个key所属的bin是第H%(N+M)个。
这种方法可以实现功能,但性能不好,rehash阶段会非常耗时。而且有可能两个bin中的数据被rehash到同一个bin中,从而构建了一个比以前更长的链表。而OpenJDK采用的方法则颇具技巧性,充分利用了高效的位运算。
/****开始说正事的分割线****/
OpenJDK要求bin的数量必须是2的整数幂,即1<<<N个(乘以2和左移一位等价,乘以N个2和左移N位等价)。初始状态N=4,即bin的初始数量是2的4次方,或者是1左移四位的结果,也就是16个。
有了这个要求,许多事情就变得简单了。
如何resize呢?为了保证上述条件成立,每次扩容,bin的数量都变为2倍。如果当前bin的数量为1<<<N,扩容一次后bin的数量是1<<<(N+1)。
一个key应该属于哪个bin呢?如果key的hashCode是H,bin的数量是B=1<<<N,则key所属的bin是第H&(B-1)个。也就是截取了hashCode最后的N位,如下图所示
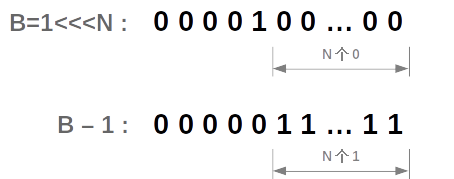
这种计算bin的方式与取余的结果实际是相同的。但是它利用了位运算,效率高于取余。而且这种方式对rehash很友好。
扩容之后,bin的数量是B'=1<<<(N+1)=B<<<1 。rehash前,key所属的bin是b1=H&(B-1),它是hashCode截取后N位的结果;rehash之后,key所属的bin是b2=H&(B'- 1),他是hashCode截取后N+1位的结果。可见,rehash前后的差异只在hashCode的第N+1位,也就是H^B'的结果。因此有
(1)如果H&B'==0,则rehash后这个key的位置不变
(2)如果H&B'==1,则rehash后这个key所属的bin是b2=b1+B。也就是将b1的第N+1位由0变为1
整个rehash过程,全部使用位运算以及一次简单的加法运算,保证了最高效率。而且两个bin的数据不会rehash到同一个bin中,也不会把数据rehash到一个扩容前就存在的bin中,保证了所有的bin在扩容后都不可能变得更长。
最后再说一个问题,hashCode如何计算?方法如下
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
将hashCode()方法的结果的高16位与低16位做亦或运算。为什么不直接用hashCode()方法的结果呢?OpenJDK的解释是,开发者可能用Double做为key,如果各个浮点数之间差别很小,那么它们的低位将相同。而bin的位置是由hashCode的低N位决定的。这种情况下,大量的数据将进入同一个bin,发生大量hash冲突,严重影响性能。于是,OpenJDK最终选择了高位低位混淆的方案。据说,这种方案得到的hashCode满足泊松分布(虽然我不知道为什么会满足),分布很均匀。
四、关于树的二三趣事
比起链表,红黑树更复杂,也要处理更多的问题和细节。可能这就是Java拖到1.8才实现树化的原因吧。许多关于树的问题并不重要,不影响整体思路,但细细品味很有意思。所以在最后写上一些。
(1)是一棵树,也是链表
树化后,新生成的树其实保持着原有链表的结构和顺序。它既是树,也是链表。树的节点用类TreeNode表示,贴一段TreeNode的声明
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
}
TreeNode间接继承自链表节点类Node,所以它也是链表节点。看到声明中的prev了吗?它不仅是链表,还是双向链表。
这么做意义何在呢?首先是方便遍历,我们大概都写过类似的代码
Map<Integer, String> m = new HashMap<>();
...
Iterator<Entry<Integer, String>> it = m.entrySet().iterator();
while(it.hasNext()) {
it.next();
}
Iterator的底层就是沿着链表的顺序遍历的。遍历链表,比遍历一棵树要高效得多。
然后,是方便逆树化(untreeify)。链表太长了会树化成一棵树。可树中的数据量可能因为resize或者remove而减少,数据太少了,树就会逆树化成一个链表。因为链表结构没有丢,逆树化就非常简单了。
(2)根节点在哪?
树的节点类TreeNode是链表节点类Node的子类。因此,树化不用改变table变量的类型
transient Node<K,V>[] table;
数组里的Node,我们称它为首节点(first node)。它可能表示链表,也可能表示树。如果是链表,首节点当然就是头节点。可如果是树,首节点是哪个节点呢?根节点(root)吗?不一定。
大部分情况下首节点都是红黑树的根节点,因为每次改变树的结构时,都会调用下面的moveToFront方法将根移动到table数组里
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {
int n;
if (root != null && tab != null && (n = tab.length) > 0) {
int index = (n - 1) & root.hash;
TreeNode<K,V> first = (TreeNode<K,V>)tab[index];
if (root != first) {
Node<K,V> rn;
tab[index] = root;
TreeNode<K,V> rp = root.prev;
if ((rn = root.next) != null)
((TreeNode<K,V>)rn).prev = rp;
if (rp != null)
rp.next = rn;
if (first != null)
first.prev = root;
root.next = first;
root.prev = null;
}
assert checkInvariants(root);
}
}
代码涉及到很多细节,只想了解基本思路的话,无需都看懂。但请注意第8行,root被放到table中。这时,根节点就是首节点了。
但是,有一个例外情况,就是在Iterator中remove一个数据时
Map<Integer, String> m = new HashMap<>();
...
Iterator<Entry<Integer, String>> it = m.entrySet().iterator();
it.remove();
为什么呢?注意moveToFront方法的第10-17行,改变了一些节点的next和prev指针,也就是改变了链表的顺序。因为root节点必须同时是链表的头节点。但是,(1)中说过,Iterator是靠链表遍历的,因此它不能随便改变链表的顺序,也就不会移动root。
这里需要多说一句,虽然单个bin中的数据构成链表,但不同bin的数据却没有联系,而且moveRootToFront还会改变链表顺序。因此,HashMap不是一个有序的数据结构。
(3)树中的数据如何比较
红黑树中的数据必须是可以比较的。那么HashMap的树如何比较呢。比较顺序如下:
a. 首先,比较key的hashCode;
b. 如果hashCode相同,检查key是否是Comparable的。是的话,直接比较key;
c. 如果key不是Comparable的,或者两个key比较结果相同,则比较两个key各自的类的字符创,即 key.getClass().getName()//看看你把JDK逼成什么样了 ;
d. 如果还是相同,就比较两个key的System.identityHashCode。
可见,从第三步起,事情就变得莫名诡异起来了。这也说明了,使用HashMap时,key最好是Comparable类型的,对性能有益。
五、最后吐个槽
本文是一篇薄码文,贴的代码很少。因为大多数代码比较长,又涉及诸多细节,不好看也无益于理解整体思路。
但是,从少数的代码中大概可以体会到,OpenJDK的代码质量真的不高。随处可见魔幻的变量声明和鬼畜的代码格式,就是照着写业务代码有可能会被打死的那种。学习JDK源码的主要目的是了解细节,方便开发。如果抱着参考优秀代码的目的,那你算来错了地方。
当然,这种底层的轮子,也许开发者更多考虑的是性能和可靠性,至于可读性或许并不那么重要。
走进Java Map家族 (1) - HashMap实现原理分析的更多相关文章
- java基础进阶二:HashMap实现原理分析
HashMap实现原理分析 1. HashMap的数据结构 数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端. 数组 数组存储区间是连续的,占用内存严重,故空间复杂的很大.但数组的二 ...
- java基础解析系列(七)---ThreadLocal原理分析
java基础解析系列(七)---ThreadLocal原理分析 目录 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析系列(二)-- ...
- 基础进阶(一)之HashMap实现原理分析
HashMap实现原理分析 1. HashMap的数据结构 数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端. 数组 数组存储区间是连续的,占用内存严重,故空间复杂的很大.但数组的二 ...
- HashMap底层原理分析(put、get方法)
1.HashMap底层原理分析(put.get方法) HashMap底层是通过数组加链表的结构来实现的.HashMap通过计算key的hashCode来计算hash值,只要hashCode一样,那ha ...
- 总结HashMap实现原理分析
一.底层数据结构在JDK1.6,JDK1.7中,HashMap采用位桶+链表实现,即使用链表处理冲突,同一hash值的键值对会被放在同一个位桶里,当桶中元素较多时,通过key值查找的效率较低. 而JD ...
- Java源码学习:HashMap实现原理
AbstractMap HashMap继承制AbstractMap,很多通用的方法,比如size().isEmpty(),都已经在这里实现了.来看一个比较简单的方法,get方法: public V g ...
- Java面试& HashMap实现原理分析
1. HashMap的数据结构 数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端. 数组 数组存储区间是连续的,占用内存严重,故空间复杂的很大.但数组的二分查找时间复杂度小,为O( ...
- Java HashMap实现原理分析
参考链接:https://www.cnblogs.com/xiarongjin/p/8310011.html 1. HashMap的数据结构 数据结构中有数组和链表来实现对数据的存储,但这两者基本上是 ...
- HashMap实现原理分析(详解)
1. HashMap的数据结构 http://blog.csdn.net/gaopu12345/article/details/50831631 ??看一下 数据结构中有数组和链表来实现对数据的存 ...
随机推荐
- SuperMap iObject入门开发系列之六管线区域查询
本文是一位好友“托马斯”授权给我来发表的,介绍都是他的研究成果,在此,非常感谢. 管线区域查询功能针对单一管线图层进行区域多边形框选查询,然后将查询结果输出为列表,并添加定位和闪烁功能,效果如下图所示 ...
- Centos 7 django环境搭建
1.本机网卡配置信息如下: vim /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE=Ethernet PROXY_METHOD=none BROWSER ...
- 10分钟搭建服务器集群——Windows7系统中nginx与IIS服务器搭建集群实现负载均衡
分布式,集群,云计算机.大数据.负载均衡.高并发······当耳边响起这些词时,做为一个菜鸟程序猿无疑心中会激动一番(或许这是判断是否是一个标准阿猿的标准吧)! 首先自己从宏观把控一下,通过上网科普自 ...
- Intellij Idea 无法启动项目的配置坑
1. run/debug configuration里面,tomcat的deployment点击添加不能自动创建war-explorded包: 方案:删除project libraries,重新mav ...
- CMake简介
目录 一.CMake简介 二.CMake典型示例 源代码 demo.cpp cmake脚本 CMakeLists.txt 编译流程 三.CMake常用命令 常用命令介绍 设置编译目标类型 指定编译包含 ...
- Fiddler使用~知多少?
昨天已经说了Fiddler的原理,那么今天就说说它是如何使用.我们进入正题. 在大多数网站测试的情况下,我们执行检测一个端口号或网址,这种场景一定会出现,记住,是一定会. 那么就需要我们过滤了,我们需 ...
- 【工利其器】必会工具之(一)Source Insight篇
前言 “Source Insight(以下简称SI)是世界上最好的编辑器”,说这句话不知道会不会出门被打呢?-_- 中国古话说得好,“文无第一,武无第二”,所以不敢说SI是最好的,但是 ...
- 机器学习——决策树,DecisionTreeClassifier参数详解,决策树可视化查看树结构
0.决策树 决策树是一种树型结构,其中每个内部节结点表示在一个属性上的测试,每一个分支代表一个测试输出,每个叶结点代表一种类别. 决策树学习是以实例为基础的归纳学习 决策树学习采用的是自顶向下的递归方 ...
- 前端笔记之JavaScript面向对象(一)Object&函数上下文&构造函数&原型链
一.对象(Object) 1.1 认识对象 对象在JS中狭义对象.广义对象两种. 广义:相当于宏观概念,是狭义内容的升华,高度的提升,范围的拓展.狭义:相当于微观概念,什么是“狭”?因为内容狭隘具体, ...
- jenkins maven 自动远程发布到服务器,钉钉提醒团队
jenkins 自动远程发布到服务器 1.安装jenkins 安装过程:自行百度 英文不好的,不要装最新版的jenkins.建议安装Jenkins ver. 2.138.4,此版本可以设置中文语言,设 ...