linux内核堆栈
一:进程的堆栈
内核在创建进程的时候,在创建task_struct的同时会为进程创建相应的堆栈。每个进程会有两个栈,一个用户栈,存在于用户空间,一个内核栈,存 在于内核空间。当进程在用户空间运行时,cpu堆栈指针寄存器里面的内容是用户堆栈地址,使用用户栈;当进程在内核空间时,cpu堆栈指针寄存器里面的内 容是内核栈空间地址,使用内核栈。
内核为每个进程分配task_struct结构体的时候,实际上分配两个连续的物理页面,底部用作task_struct结构体,结构上面的用作堆栈。使用current()宏能够访问当前正在运行的进程描述符。
注意:这个时候task_struct结构是在内核栈里面的,内核栈的实际能用大小大概有7K。
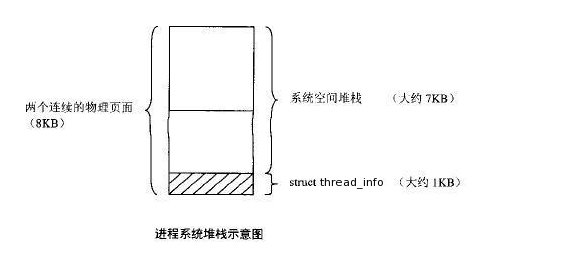
当内核栈为8K时,Thread_info在这块内存的起始地址,内核栈从堆栈末端向下增长。所以此时,要通过thread_info结构体中的task_struct域来获得于thread_info相关联的task。更详细的参考相应的 current宏的实现;
下面是struct thread_info的定义:
struct thread_info {
unsigned long flags; /* low level flags */
int preempt_count; /* 0 => preemptable, <0 => bug */
mm_segment_t addr_limit; /* address limit */
struct task_struct *task; /* main task structure */
struct exec_domain *exec_domain; /* execution domain */
__u32 cpu; /* cpu */
__u32 cpu_domain; /* cpu domain */
struct cpu_context_save cpu_context; /* cpu context */
__u32 syscall; /* syscall number */
__u8 used_cp[]; /* thread used copro */
unsigned long tp_value;
struct crunch_state crunchstate;
union fp_state fpstate __attribute__((aligned()));
union vfp_state vfpstate;
#ifdef CONFIG_ARM_THUMBEE
unsigned long thumbee_state; /* ThumbEE Handler Base register */
#endif
struct restart_block restart_block;
};
通过上面定义我们可以看出在thread_info结构体中有指向task_struct 的指针task;在struct task_struct 结构体中包含着进程的相关信息,下面是相关参数说明;
(1) unsigned short used_math;
是否使用FPU。
(2) char comm[16];
进程正在运行的可执行文件的文件名。
(3) struct rlimit rlim[RLIM_NLIMITS];
结 构rlimit用于资源管理,定义在linux/include/linux/resource.h中,成员共有两项:rlim_cur是资源的当前最大 数目;rlim_max是资源可有的最大数目。在i386环境中,受控资源共有RLIM_NLIMITS项,即10项,定义在 linux/include/asm/resource.h中,见下表:
(4) int errno;
最后一次出错的系统调用的错误号,0表示无错误。系统调用返回时,全程量也拥有该错误号。
(5) long debugreg[8];
保存INTEL CPU调试寄存器的值,在ptrace系统调用中使用。
(6) struct exec_domain *exec_domain;
Linux可以运行由80386平台其它UNIX操作系统生成的符合iBCS2标准的程序。关于此类程序与Linux程序差异的消息就由 exec_domain结构保存。
(7) unsigned long personality;
Linux 可以运行由80386平台其它UNIX操作系统生成的符合iBCS2标准的程序。 Personality进一步描述进程执行的程序属于何种UNIX平台的“个性”信息。通常有PER_Linux、PER_Linux_32BIT、 PER_Linux_EM86、PER_SVR3、PER_SCOSVR3、PER_WYSEV386、PER_ISCR4、PER_BSD、 PER_XENIX和PER_MASK等,参见include/linux/personality.h。
(8) struct linux_binfmt *binfmt;
指向进程所属的全局执行文件格式结构,共有a。out、script、elf和java等四种。结构定义在include/linux /binfmts.h中(core_dump、load_shlib(fd)、load_binary、use_count)。
(9) int exit_code,exit_signal;
引起进程退出的返回代码exit_code,引起错误的信号名exit_signal。
(10) int dumpable:1;
布尔量,表示出错时是否可以进行memory dump。
(11) int did_exec:1;
按POSIX要求设计的布尔量,区分进程是正在执行老程序代码,还是在执行execve装入的新代码。
(12) int tty_old_pgrp;
进程显示终端所在的组标识。
(13) struct tty_struct *tty;
指向进程所在的显示终端的信息。如果进程不需要显示终端,如0号进程,则该指针为空。结构定义在include/linux/tty.h中。
(14) struct wait_queue *wait_chldexit;
在进程结束时,或发出系统调用wait4后,为了等待子进程的结束,而将自己(父进程)睡眠在该队列上。结构定义在include/linux /wait.h中。
13. 进程队列的全局变量
(1) current;
当前正在运行的进程的指针,在SMP中则指向CPU组中正被调度的CPU的当前进程:
#define current(0+current_set[smp_processor_id()])/*sched.h*/
struct task_struct *current_set[NR_CPUS];
(2) struct task_struct init_task;
即0号进程的PCB,是进程的“根”,始终保持初值INIT_TASK。
(3) struct task_struct *task[NR_TASKS];
进 程队列数组,规定系统可同时运行的最大进程数(见kernel/sched.c)。NR_TASKS定义在include/linux/tasks.h 中,值为512。每个进程占一个数组元素(元素的下标不一定就是进程的pid),task[0]必须指向init_task(0号进程)。可以通过 task[]数组遍历所有进程的PCB。但Linux也提供一个宏定义for_each_task()(见 include/linux/sched.h),它通过next_task遍历所有进程的PCB:
#define for_each_task(p) \
for(p=&init_task;(p=p->next_task)!=&init_task;)
(4) unsigned long volatile jiffies;
Linux的基准时间(见kernal/sched.c)。系统初始化时清0,以后每隔10ms由时钟中断服务程序do_timer()增1。
(5) int need_resched;
重新调度标志位(见kernal/sched.c)。当需要Linux调度时置位。在系统调用返回前(或者其它情形下),判断该标志是否置位。置位的话,马上调用schedule进行CPU调度。
(6) unsigned long intr_count;
记 录中断服务程序的嵌套层数(见kernal/softirq.c)。正常运行时,intr_count为0。当处理硬件中断、执行任务队列中的任务或者执 行bottom half队列中的任务时,intr_count非0。这时,内核禁止某些操作,例如不允许重新调度。
以上内容参考:http://www.cnblogs.com/hongzhunzhun/
下面我们要做的是写一个模块,打印当前进程的名字:
#include <linux/init.h>
#include <linux/module.h>
#include <linux/thread_info.h>
#include <linux/sched.h> MODULE_LICENSE("GPL");
MODULE_AUTHOR("bunfly"); int bunfly_init()
{ struct thread_info *tmp = NULL;
tmp = (struct thread_info *)((unsigned long )&tmp & ~0x1fff);//摸除低13位(8k对齐)获取thread_info首地址
struct task_struct *find = tmp->task;//得到对应的task_strcut地址
printk("name is: %s\n", find->comm);//获取当前进程名 return ;
} void bunfly_exit()
{
printk("goodbye bunfly_exit\n");
} module_init(bunfly_init);
module_exit(bunfly_exit);
在linux内核中,struct_task是以一个双向循环链表的形式存在:
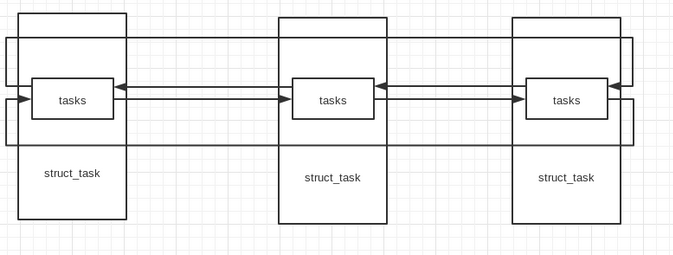
因此,我们可以循环打印所有的进程名,实现简易的ps命令:
下面是具体代码:
#include <linux/init.h>
#include <linux/module.h>
#include <linux/thread_info.h>
#include <linux/sched.h> MODULE_LICENSE("GPL");
MODULE_AUTHOR("bunfly"); int bunfly_init()
{
struct thread_info *tmp = NULL;
struct task_struct *next = NULL;
struct task_struct *find = NULL;
struct list_head *list = NULL; tmp = current_thread_info();//获得thread_info的首地址
find = tmp->task;//找到task_struct的首地址 next = find;
do {
printk("next is: %s\n", next->comm);
list = next->tasks.next;
/*通过tasks的地址找到它所在的结构体(task_struct)的首地址,从而得到comm*/
next = container_of(list, struct task_struct, tasks); } while (next != find);//循环打印 return ;
} void bunfly_exit()
{
printk("goodbye bunfly_exit\n");
} module_init(bunfly_init);
module_exit(bunfly_exit);
在linux内核中要经常用到宏container_of,这个必须掌握:它的原型如下:
#define container_of(ptr, type, member) ({const typeof( ((type *)0)->member ) *__mptr = (ptr); (type *)( (char *)__mptr - offsetof(type,member) );})
linux内核堆栈的更多相关文章
- Linux内核堆栈使用方法 进程0和进程1【转】
转自:http://blog.csdn.net/yihaolovem/article/details/37119971 目录(?)[-] 8 Linux 系统中堆栈的使用方法 81 初始化阶段 82 ...
- Linux内核分析——汇编代码执行及堆栈变化
张潇月<Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 一.实验步骤 首先借助实验楼这个平台进入Linux ...
- linux信号机制 - 用户堆栈和内核堆栈的变化【转】
转自:http://itindex.net/detail/16418-linux-%E4%BF%A1%E5%8F%B7-%E5%A0%86%E6%A0%88 此文只简单分析发送信号给用户程序后,用户堆 ...
- 第4天--linux内核学习
驱动使用方式1.编译到内核中 * make uImage进入到系统后mknod /dev/led c 500 0 创建设备节点 2.编译为模块 M make module进入到系统后 mknod /d ...
- linux内核分析作业6:分析Linux内核创建一个新进程的过程
task_struct结构: struct task_struct { volatile long state;进程状态 void *stack; 堆栈 pid_t pid; 进程标识符 u ...
- 读《linux内核完全注释》的FAQ
以下只是个人看了<linux内核完全注释>的一点理解,如果有错误,欢迎指正! 1 eip中保存的地址是逻辑地址.线性地址还是物理地址? 这个应该要分情况.eip保存的是下一条要执行的指令地 ...
- linux内核分析作业:以一简单C程序为例,分析汇编代码理解计算机如何工作
一.实验 使用gcc –S –o main.s main.c -m32 命令编译成汇编代码,如下代码中的数字请自行修改以防与他人雷同 int g(int x) { return x + 3; } in ...
- linux内核分析作业:操作系统是如何工作的进行:完成一个简单的时间片轮转多道程序内核代码
计算机如何工作 三个法宝:存储程序计算机.函数调用堆栈.中断机制. 堆栈 函数调用框架 传递参数 保存返回地址 提供局部变量空间 堆栈相关的寄存器 Esp 堆栈指针 (stack pointer) ...
- linux内核分析作业4:使用库函数API和C代码中嵌入汇编代码两种方式使用同一个系统调用
系统调用:库函数封装了系统调用,通过库函数和系统调用打交道 用户态:低级别执行状态,代码的掌控范围会受到限制. 内核态:高执行级别,代码可移植性特权指令,访问任意物理地址 为什么划分级别:如果全部特权 ...
随机推荐
- mysql进阶(二十)CPU超负荷异常情况
CPU超负荷异常情况 问题 项目部署阶段,提交订单时总是出现cpu超负荷工作情况,导致机器卡死,订单提交失败.通过任务管理器可见下图所示: 通过任务管理器中进程信息(见下图)进行查看,可见正是由于项目 ...
- Android高级控件(一)——ListView绑定CheckBox实现全选,增加和删除等功能
Android高级控件(一)--ListView绑定CheckBox实现全选,增加和删除等功能 这个控件还是挺复杂的,也是项目中应该算是比较常用的了,所以写了一个小Demo来讲讲,主要是自定义adap ...
- Leetocde_242_Valid Anagram
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/48979767 Given two strings s an ...
- SharePoint 搜索爬网第三方网站配置
介绍:SharePoint的搜索着实强大,而且最近用到SharePoint搜索第三方爬网,感觉收获挺大,而且网上资料没找到太多类似的,就小记录一下,分享给大家. 首先,我自己写了一个net页面,里面读 ...
- Digogo ugdx文件的制作
The openplatform source code is in old IT FTP server at "vte/KCD/20150814/openplatform_wallace. ...
- nasm预处理器(2)
多行宏 %macro: %macro foo 2 push rax push rbx mov rax,%1 mov rbx,%2 pop rbx pop rax %endmacro 宏名称后的数字代表 ...
- OVS+DPDK Datapath 包分类技术
本文主体内容译于[DPDK社区文档],但并没有逐字翻译,在原文的基础上进行了一些调整,增加了对TSS分类器的详细阐述. 1. 概览 本文描述了OVS+DPDK中的包分类器(datapath class ...
- Bash的一些零星笔记
1.变量带入操作符 在脚本中,使用变量前做检查是很重要的.通过代入操作符,可以实现这方面的功能.比如当变量未赋值时为变量赋默认值,以及更多内容: ${parameter:-默认为空}:当paramet ...
- JMeter——简单的接口测试实例(一)
场景:使用JMeter来实现接口测试 基本流程:添加线程组->添加http信息头管理器->添加http请求->添加断言->添加监听器->执行,查看结果 案例分析:下面以办 ...
- Tornado、Bottle以及Flask
最近接手一个Tornado项目代码,项目要在原有基础上做很大扩展,为了更好地吃透并扩展好这个项目,就对Tornado以及比较轻型的Bottle.Flask这些框架一一作了调研.其实若干年前做第一个Py ...