HDFS简介及相关概念
HDFS简介:
HDFS在设计时就充分考虑了实际应用环境的特点,即硬件出错在普通服务集群中是一种常态,而不是异常。
因此HDFS主要实现了以下目标:
| 兼容廉价的硬件设备 | HDFS设计了快速检测硬件故障和进行自动恢复的机制,可以实现持续监视,错误检查,容错处理和自动回复,从而使得在硬件出错的情况下也能实现数据的完 整性 |
| 流数据读写 | |
| 大数据集 | HDFS中的文件通常可以达到GB甚至TB级别 |
| 简答的文件模型 | HDFS采用了“一次写入,多次读取”的简单文件模型,文件一旦完成写入,关闭后就无法再次写入,只能被读取 |
| 强大的跨平台兼容性 | 由于HDFS使用java语言实现的,具有很好的跨平台兼容性 |
HDFS的局限:
| 不适合低延迟数据的访问 | HDFS不适合用在需要较低延迟(如数十毫秒)的应用场合,对于低延迟要求的应用程序而言,HBase是一个更好的选择 |
| 无法高效存储大量小文件 | 小文件是指文件大小小于一个块的文件 |
| 不支持多用户写入及任意修改文件 | HDFS只允许一个文件有一个写入者,且只允许对文件执行追加操作,不能执行随机写操作(即:不能改变文件中的数据,只能在文件后增加) |
HDFS的相关概念:
块:在传统的文件系统中,为了提高磁盘读写效率,一般以数据块为单位,而不是以次节为单位。查找数据的存储位置时,通过查询一块块的数据块,找到数据在磁盘中的存储位置,然后进行读写。HDFS也同样采用了块的概念,默认一个块的大小是64MB,这样做得目的是为了最小化寻址开销。通常,MapReduce中的Map任务一次只处理一个块中的数据。HDFS采用抽象的块概念的好处:
| 支持大规模文件存储 | 文件在存储时别拆分为一定量的块,分发到不同的节点上,因此一个文件的大小不会受到单个节点的存储容量限制 |
| 简化系统设计 | 大大简化了存储管理,因为一个文件块的大小是固定的,这样就可以计算出一个节点可以存储多少文件块,且方便了元数据的管理 |
| 适合数据备份 | 每个文件块都可以冗余存储到多个节点上,大大提高了系统的容错性和可用性 |
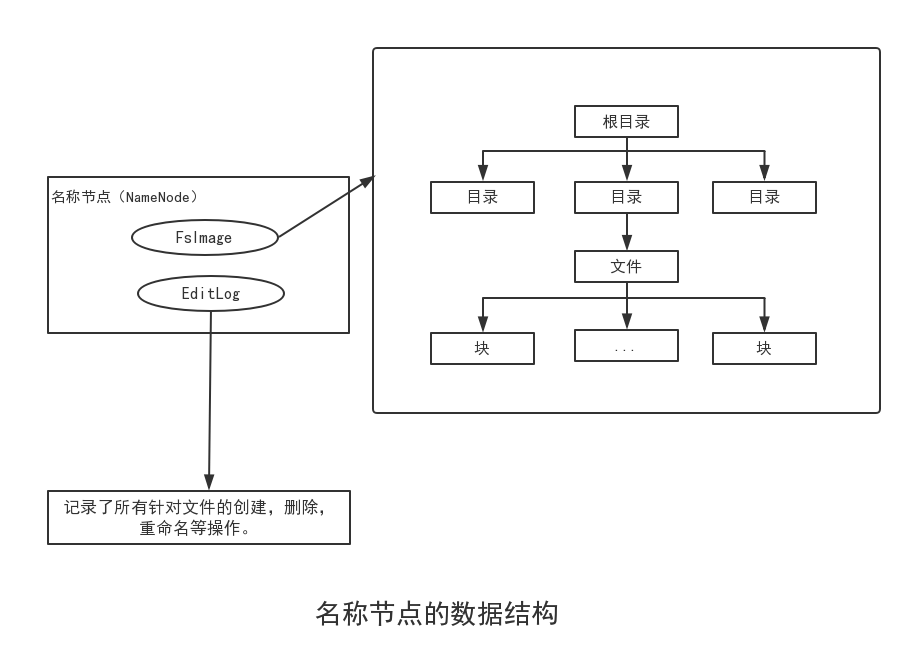
名称节点和数据节点:在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间,保存了两个核心的数据结构,即FsImage和EditLog。FsImage用于维护文件系统树以及文件数中所有的文件和文件夹的元数据。操作日志文件EditLog中记录了所有针对文件的创建,删除,重命名等操作。名称节点记录了每个文件中各个块所在的数据节点的位置信息,但是并不持久化存储这些信息,而是在每次系统启动时扫描所有的数据节点重构得到这些信息。
名称节点在启动时,会将FsImage的内容加载到内存中,然后执行EditLog文件中的各项操作,舍得内从中的元数据保持最新。操作完成后,就会创建一个新的FsImage文件和一个空的EditLog文件。名称节点启动成功并进入正常运行状态后,HDFS中的更新操作都会被写入EditLog中,而不是直接写入FsImage中。名称节点在启动的过程中处于“安全模式”,只能对外提供读操作而无法提供写操作。启动过程结束后,系统就会退出安全模式,进入正常运行状态,对外提供读写操作。
数据节点(DataNode)负责数据的存储和读取。每个数据节点的数据会被保存在各自节点的本地Linux文件系统中。
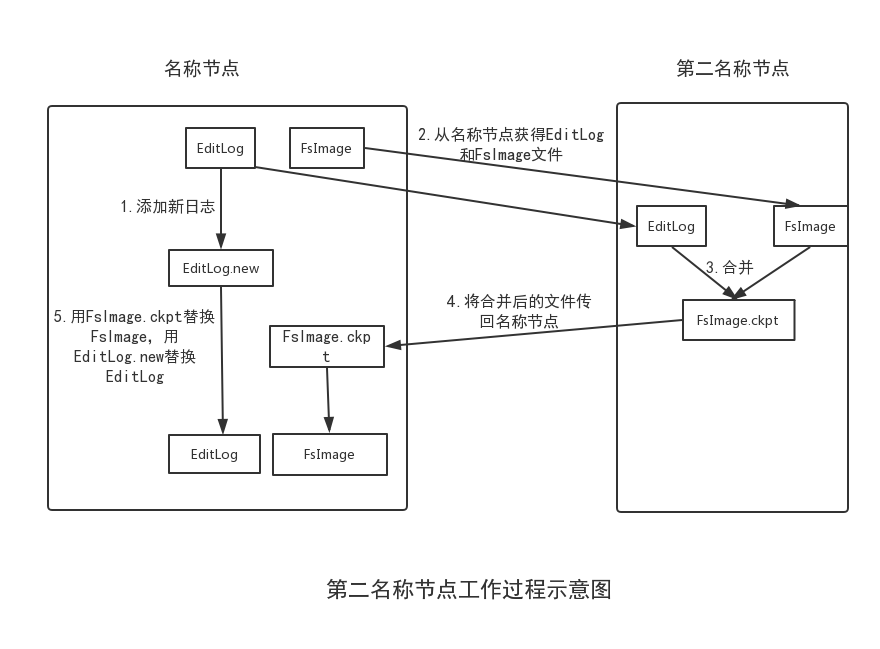
第二名称节点:在名称节点运行期间,HDFS会不断发生更新操作,这些更新操作都是直接被写入EditLog文件,因此EditLog文件也会逐渐变大,虽然EditLog不会对系统性能产生显著影响,但是当名称节点重启是,需要将FsImage加载到内存中,然后逐条执行EditLog中的记录,使得FsImage保持更新,可想而知,如果EditLog很大,就会导致整个过程变得非常缓慢,使得名称节点在启动过程中长期处于“安全模式”,无法正常对外提供写操作,影响了用户的使用。
为了解决这个问题,HDFS采用了第二名称节点。它具有两个方面的功能:
一是进行EditLog和FsImage的合并操作,每隔一段时间(假设为t1),第二名称节点会和名称节点通信,请求其停止使用EditLog文件,暂时将新到达的写操作添加到一个新的文件EditLog.new中。然后,第二名称节点把名称节点中的FsImage和EditLog文件拉回本地,再加载到内存中,对两者执行合并操作,即在内存中逐条执行EditLog中的操作,使得FsImage保持最新。合并结束后,第二名称节点会把合并得到的最新FsImage文件发送到名称节点。名称节点收到后,会用最新的FsImage文件去替换旧的FsImage文件,同时用EditLog.new文件去替换EditLog文件(假设这段时间为t2),从而减小了EditLog文件的大小。
二是作为名称节点的“检查节点”。从上面的合并过程中可以看出,第二名称节点会定期和名称节点通信,从名称节点获取FsImage和EditLog文件。这相当于第二名称节点是名称节点的“检查节点”,周期性地备份名称节点中的元数据信息,当名称节点发生故障时,就可以用第二名称节点对其进行恢复。但是,第二名称节点上合并操作得到的新的FsImage文件是合并操作发生时(即t1时刻)HDFS记录的元数据信息,并没有包含t1时刻和t2时刻期间发生的更新操作,如果名称节点在这段时间内发生故障,系统就会丢失部分元数据。在HDFS的设计中,也并支持把系统直接切换到第二名称节点。因此第二名称节点想到与系统的“冷备份”。
HDFS简介及相关概念的更多相关文章
- 01 HDFS 简介
01.HDFS简介 大纲: hadoop2 介绍 HDFS概述 HDFS读写流程 hadoop2介绍 框架的核心设计是HDFS(存储),mapReduce(分布式计算),YARN(资源管理),为海量的 ...
- HDFS简介【全面讲解】
http://www.cnblogs.com/chinacloud/archive/2010/12/03/1895369.html [一]HDFS简介HDFS的基本概念1.1.数据块(block)HD ...
- 【Hadoop】一、HDFS简介及基本概念
当需要存储的数据集的大小超过了一台独立的物理计算机的存储能力时,就需要对数据进行分区并存储到若干台计算机上去.管理网络中跨多台计算机存储的文件系统统称为分布式文件系统(distributed fi ...
- java大数据最全课程学习笔记(3)--HDFS 简介及操作
目前CSDN,博客园,简书同步发表中,更多精彩欢迎访问我的gitee pages 目录 HDFS 简介及操作 HDFS概述 HDFS产出背景及定义 HDFS优缺点 HDFS组成架构 HDFS文件块大小 ...
- HDFS简介及基本概念
(一)HDFS简介及其基本概念 HDFS(Hadoop Distributed File System)是hadoop生态系统的一个重要组成部分,是hadoop中的的存储组件,在整个Hadoop中 ...
- Storm(一)Storm的简介与相关概念
一.Storm的简介 官网地址:http://storm.apache.org/ Storm是一个免费开源.分布式.高容错的实时计算系统.Storm令持续不断的流计算变得容易,弥补了Hadoop批处理 ...
- css简介及相关概念
一.简介: css全称为级联样式表(Cascading Style Sheet),通常又称为风格样式表(Style Sheet),是用来进行网页风格设计的. css优点: 内容与表现分离 表现的统一 ...
- HDFS简介
Hadoop是当今最为流行的大数据分析和处理工具. 其最先的思想来源于Google的三篇论文: GFS(Google File System):是 ...
- Hadoop 学习总结之一:HDFS简介
一.HDFS的基本概念 1.1.数据块(block) HDFS(Hadoop Distributed File System)默认的最基本的存储单位是64M的数据块. 和普通文件系统相同的是,HDFS ...
随机推荐
- Java 小记 — RabbitMQ 的实践与思考
前言 本篇随笔将汇总一些我对消息队列 RabbitMQ 的认识,顺便谈谈其在高并发和秒杀系统中的具体应用. 1. 预备示例 想了下,还是先抛出一个简单示例,随后再根据其具体应用场景进行扩展,我觉得这样 ...
- 爬虫(scrapy--豆瓣TOP250)
# -*- coding: utf-8 -*- import scrapy from douban_top250.items import DoubanTop250Item class MovieSp ...
- [Android]利用run-as命令在不root情况下读取data下面的数据
正文 一.关键步骤 主要是run-as命令: over@over-ThinkPad-R52:~$ adb shell $ run-as com.package $ cd /data/data/co ...
- Java 并发编程实践基础 读书笔记: 第三章 使用 JDK 并发包构建程序
一,JDK并发包实际上就是指java.util.concurrent包里面的那些类和接口等 主要分为以下几类: 1,原子量:2,并发集合:3,同步器:4,可重入锁:5,线程池 二,原子量 原子变量主要 ...
- 转载--MYSQL5.7:Access denied for user 'root'@'localhost' (using password:YES)解决方法
1.打开MySQL目录下的my.ini文件,在文件的最后添加一行"skip-grant-tables",保存并关闭文件; 2.重启MySQL服务; 3.通过cmd行进入MySQL的 ...
- 转载---SuperMap GIS 9D SP1学习视频播单
转自:http://blog.csdn.net/supermapsupport/article/details/79219102 SuperMap GIS 9D SP1学习视频播单 我们一直在思考什么 ...
- 关于php日期前置是否有0
例如:2018-01-04,这个日期和月份前置是有0 如果不想有0,date( 'y-n-j',time() ):默认的是date( 'y-m-d',time() ),这个日期和月份前置是有0. da ...
- xpath获取下一页,兄弟结点的妙用
第一页的情况: 第四页的情况 : 文章的链接: http://tech.huanqiu.com/science/2018-02/11605853_4.html 从上面我们可以看到,如果仅仅用xpat ...
- 2018上C语言程序设计(高级)作业- 第0次作业
准备工作(10分) 1.在博客园申请个人博客. 2.加入班级博客(2班班级博客链接地址)(1班班级博客链接地址) 3.关注邹欣老师博客.关注任课老师博客. 4.加入讨论小组,学习过程中遇到问题不要随意 ...
- 201421123042 《Java程序设计》第10周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结异常相关内容. 2. 书面作业 本次PTA作业题集异常 1. 常用异常 结合题集题目7-1回答 1.1 自己以前编写的代码中经常出现 ...