scrapy CrawlSpider解析
CrawlSpider继承自Spider, CrawlSpider主要用于有规则的url进行爬取。
先来说说它们的设计区别:
SpiderSpider 类的设计原则是只爬取 start_urls 中的url,而 CrawlSpider 类定义了一些规则 rules 来提供跟进链接 link 的方便机制,从爬取的网页中获取link并继续跟进的工作。
先来看看刚创建一个crawlSpider的爬虫 -t 指定模板为crawlSpider
scrapy genspider -t crawl cf circ.gov.cn
LinkExtractor 的源码:
from scrapy.linkextractors import LinkExtractor

allow :满足括号中”正则表达式”的值会被提取,如果为空,则全部匹配。
deny :与这个正则表达式(或正则表达式列表)不匹配的url一定不提取
allow_domain:会被提取的连接的domains
deny_domains :一定不会被提取链接的domains。
restrict_xpaths :使用xpath表达式,和allow共同作用过滤链接。
restrict_css :使用css选择器
在CrawlSpider源码中最先定义的是类Rule:Rule对象是一个爬取规则的类
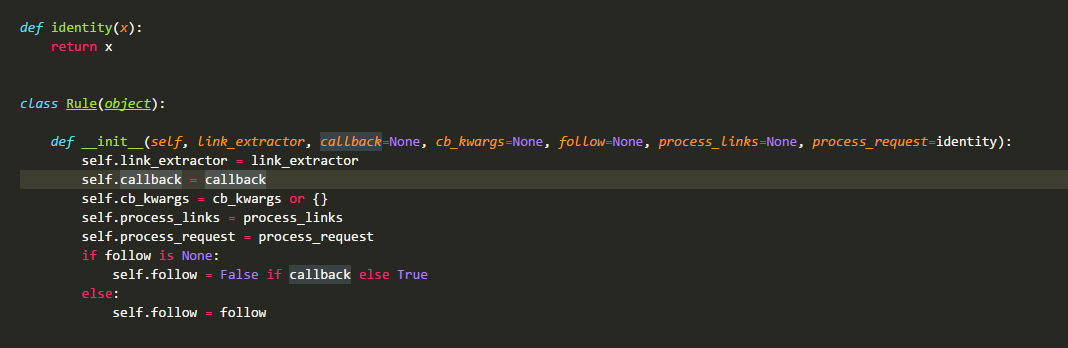
link_extractor :是一个Link Extractor对象。其定义了如何从爬取到的页面提取链接。
callback :是一个callable或string(该Spider中同名的函数将会被调用)。从link_extractor中每获取到链接时将会调用该函数。该回调函数接收一个response作为其第一个参数,并返回一个包含Item以及Request对象(或者这两者的子类)的列表。
cb_kwargs :包含传递给回调函数的参数(keyword argument)的字典。
follow :是一个boolean值,指定了根据该规则从response提取的链接是否需要跟进。如果callback为None,follow默认设置True,否则默认False。
process_links :是一个callable或string(该Spider中同名的函数将会被调用)。从link_extrator中获取到链接列表时将会调用该函数。该方法主要是用来过滤。
process_request :是一个callable或string(该spider中同名的函数都将会被调用)。该规则提取到的每个request时都会调用该函数。该函数必须返回一个request或者None。用来过滤request
CrawlSpider类的源码:
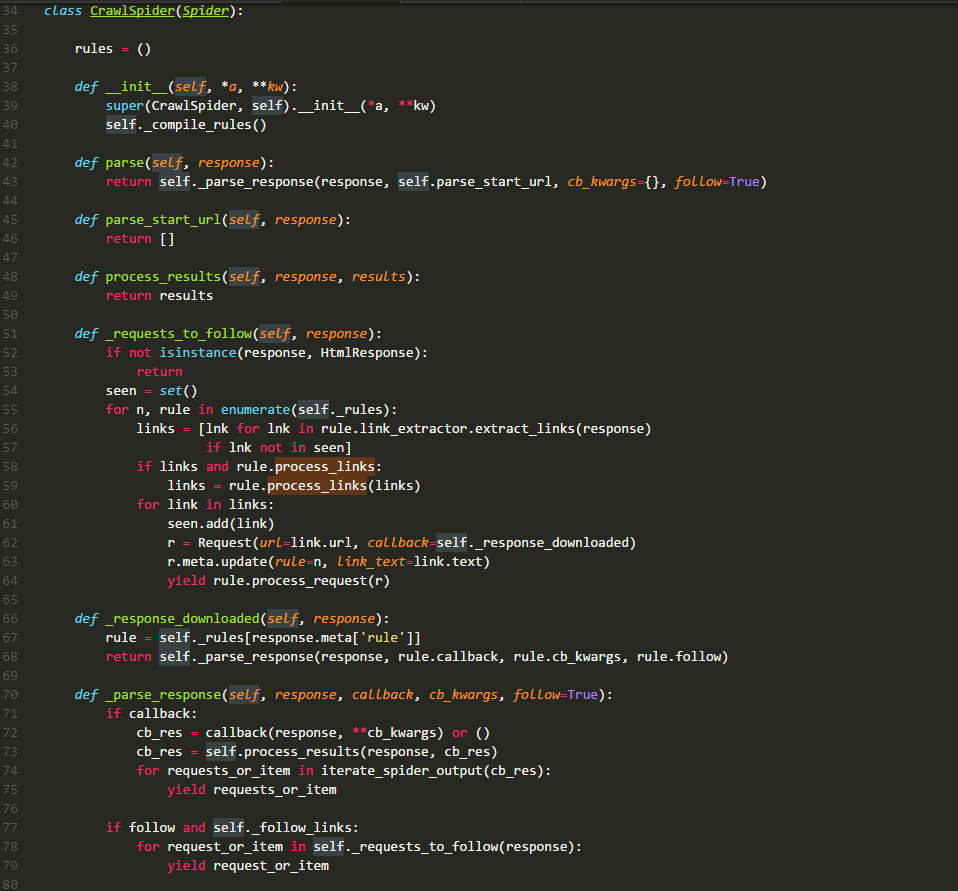

rules :
是一个列表,存储的元素是Rule类的实例,其中每一个实例都定义了一种采集站点的行为。如果有多个rule都匹配同一个链接,那么位置下标最小的一个rule将会被使用。
__init__ :
它主要就是执行了_compile_rules方法
parse :
默认回调方法。源码进行了重写,所以我们自定义的函数,不可以使用这个名,这里直接调用方法 _parse_response ,并把 parse_start_url 方法作为处理response的方法。
parse_start_url :
它的主要作用就是处理parse返回的response,比如提取出需要的数据等,该方法也需要返回item、request或者他们的可迭代对象。它就是一个回调方法,和rule.callback用法一样。
_requests_to_follow :
它的作用就是从response中解析出目标url,并将其包装成request请求。该请求的回调方法是_response_downloaded,这里为request的meta值添加了rule参数,该参数的值是这个url对应rule在rules中的下标。
_response_downloaded :
该方法是方法 _requests_to_follow 的回调方法,作用就是调用 _parse_response 方法,处理下载器返回的 response ,设置 response 的处理方法为 rule.callback 方法。
_parse_response :
该方法将 resposne 交给参数callback代表的方法去处理,然后处理callback方法的requests_or_item。再根据rule.follow and spider._follow_links来判断是否继续采集,如果继续那么就将response交给_requests_to_follow方法,根据规则提取相关的链接。spider._follow_links的值是从settings的CRAWLSPIDER_FOLLOW_LINKS值获取到的。
_compile_rules :
作用就是将rule中的字符串表示的方法改成实际的方法,方便以后使用。
from_crawler :
用于创建,在scrapy源码中这种创建方式比较多
整个数据的流向如下图所示:

示例:
1.创建项目
scrapy startproject circ
2. 创建crawl爬虫
cd circ
scrapy genspider -t crawl cf circ.gov.cn
3.编写cf.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
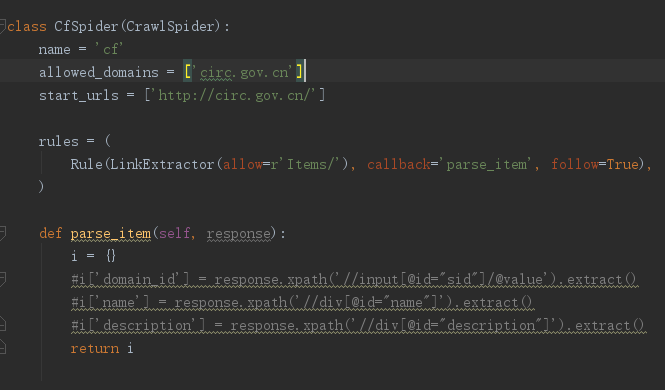
import re class CfSpider(CrawlSpider):
name = 'cf'
allowed_domains = ['circ.gov.cn']
start_urls = ['http://www.circ.gov.cn/web/site0/tab5240/module14430/page1.htm'] #定义提取url地址规则
rules = (
#LinkExtractor 连接提取器,提取url地址
#callback 提取出来的url地址的response会交给callback处理
#follow 当前url地址的响应是够重新进过rules来提取url地址,
Rule(LinkExtractor(allow=r'/web/site0/tab5240/info\d+\.htm'), callback='parse_item'),
Rule(LinkExtractor(allow=r'/web/site0/tab5240/module14430/page\d+\.htm'),follow=True),
) #parse函数有特殊功能,不能定义
def parse_item(self, response):
item = {}
item["title"] = re.findall("<!--TitleStart-->(.*?)<!--TitleEnd-->",response.body.decode())[0]
item["publish_date"] = re.findall("发布时间:(20\d{2}-\d{2}-\d{2})",response.body.decode())[0]
print(item)
scrapy CrawlSpider解析的更多相关文章
- scrapy -->CrawlSpider 介绍
scrapy -->CrawlSpider 介绍 1.首先,通过crawl 模板新建爬虫: scrapy genspider -t crawl lagou www.lagou.com 创建出来的 ...
- scrapy初步解析源码即深度使用
scrapy深度爬虫 ——编辑:大牧莫邪 本章内容 深度爬虫概述 scrapy Spider实现的深度爬虫 scrapy CrawlSpdier实现的深度爬虫 案例操作 课程内容 1. 深度爬虫概述 ...
- scrapy系列(四)——CrawlSpider解析
CrawlSpider也继承自Spider,所以具备它的所有特性,这些特性上章已经讲过了,就再在赘述了,这章就讲点它本身所独有的. 参与过网站后台开发的应该会知道,网站的url都是有一定规则的.像dj ...
- Scrapy - CrawlSpider爬虫
crawlSpider 爬虫 思路: 从response中提取满足某个条件的url地址,发送给引擎,同时能够指定callback函数. 1. 创建项目 scrapy startproject mysp ...
- Python+Scrapy+Crawlspider 爬取数据且存入MySQL数据库
1.Scrapy使用流程 1-1.使用Terminal终端创建工程,输入指令:scrapy startproject ProName 1-2.进入工程目录:cd ProName 1-3.创建爬虫文件( ...
- scrapy递归解析和post请求
递归解析 递归爬取解析多页页面数据 每一个页面对应一个url,则scrapy工程需要对每一个页码对应的url依次发起请求,然后通过对应的解析方法进行作者和段子内容的解析. 实现方案: 1.将每一个页码 ...
- Scrapy CrawlSpider源码分析
crawl.py中主要包含两个类: 1. CrawlSpider 2. Rule link_extractor:传LinkExtractor实例对象 callback:传”func_name“ cb_ ...
- 别再滥用scrapy CrawlSpider中的follow=True
对于刚接触scrapy的同学来说, crawlspider中的rule是比较难理解的, 很可能驾驭不住. 而且笔者在YouTube中看到许多公开的演讲都都错用了follow这一选项, 所以今天就来仔细 ...
- scrapy架构解析
随机推荐
- grep 及正则表达式
grpe 及正则表达式 文本查找的需要:grep,egrep,fgrepgrep: 根据模式,搜索文本,并将符合模式的文本行显示出来.Pattern : 文本字符以及正则表达式的元字符组合而成的匹配条 ...
- 函数声明 和 var声明的优先级
function demo() { console.log(5) } var demo = function(){ console.log(4) } console.log(demo()) var d ...
- 【STM32H7教程】第3章 STM32H7整体把控
完整教程下载地址:http://forum.armfly.com/forum.php?mod=viewthread&tid=86980 第3章 STM32H7整体把控 初学STM32H7一 ...
- CTF取证方法大汇总,建议收藏!
站在巨人的肩头才会看见更远的世界,这是一篇来自技术牛人的神总结,运用多年实战经验总结的CTF取证方法,全面细致,通俗易懂,掌握了这个技能定会让你在CTF路上少走很多弯路,不看真的会后悔! 本篇文章大约 ...
- 记一发idea resources下rename的坑
resources rename文件 '.'不表示下级目录 只是作为一个字符 第一个com.uniubi.dao 是一层层创的.第二个是直接用idea 创的如下图. maven 打包后如下所示. ps ...
- Java核心技术第五章——1.类、超类、子类(2)
继上一篇Java核心技术第五章——1.类.超类.子类(1) 6.重载解析 假如调用ClassName.Method(args) 1.编译器列出类ClassName所有名为Method的方法. 2.编译 ...
- TCP三次握手和四次挥手的全过程
三次握手: 第一次握手:客户端发送syn包(syn=x)到服务器,并进入SYN_SEND状态,等待服务器确认:第二次握手:服务器收到syn包,必须确认客户的SYN(ack=x+1),同时自己也发送一个 ...
- mybatis框架(7)---mybatis逆向工程
mybatis逆向工程 逆向工程的目的就是缩减了我们的开发时间.所谓mybatis逆向工程,就是mybatis会根据我们设计好的数据表,自动生成pojo.mapper以及mapper.xml. 接 ...
- 轻量级数据库Sqlite的使用
SqLite是什么? SQLite是一个进程内的库,实现了自给自足的.无服务器的.零配置的.事务性的 SQL 数据库引擎.它是一个零配置的数据库,这意味着与其他数据库一样,您不需要在系统中配置. 就像 ...
- 从零开始学习PYTHON3讲义(十一)计算器升级啦
(内容需要,本讲中再次使用了大量在线公式,如果因为转帖网站不支持公式无法显示的情况,欢迎访问原始博客.) <从零开始PYTHON3>第十一讲 第二讲的时候,我们通过Python的交互模式来 ...