Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬
字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的。
现在貌似不少网站都有采用这种反爬机制,我们通过猫眼的实际情况来解释一下。
下图的是猫眼网页上的显示:
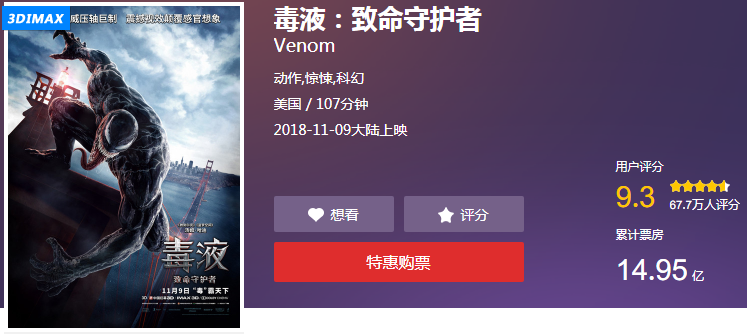
检查元素看一下
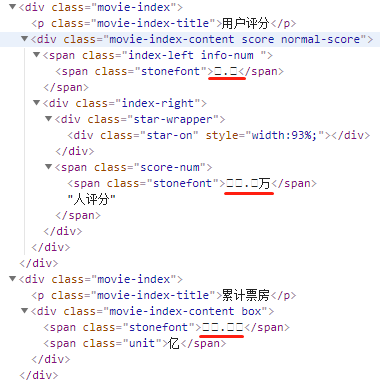
这是什么鬼,关键信息全是乱码。
熟悉 CSS 的同学会知道,CSS 中有一个 @font-face,它允许网页开发者为其网页指定在线字体。原本是用来消除对用户电脑字体的依赖,现在有了新作用——反爬。
汉字光常用字就有好几千,如果全部放到自定义的字体中,那么字体文件就会变得很大,必然影响网页的加载速度,因此一般网站会选取关键内容加以保护,如上图,知道了等于不知道。
这里的乱码是由于 unicode 编码导致的,查看源文件可以看到具体的编码信息。
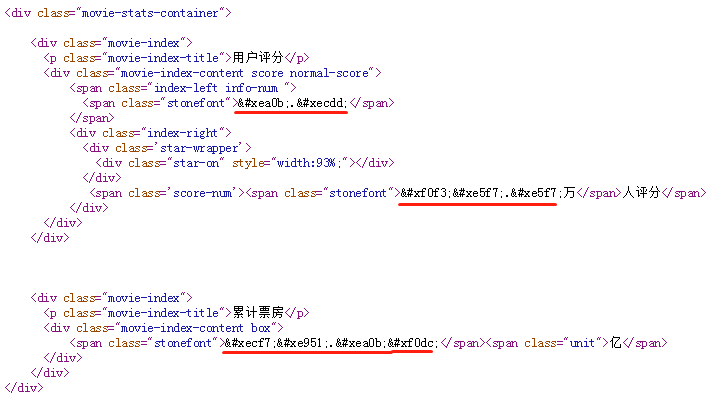
搜索 stonefont,找到 @font-face 的定义:

这里的 .woff 文件就是字体文件,我们将其下载下来,利用 http://fontstore.baidu.com/static/editor/index.html 网页将其打开,显示如下:

网页源码中显示的 跟这里显示的是不是有点像?事实上确实如此,去掉开头的 &#x 和结尾的 ; 后,剩余的4个16进制显示的数字加上 uni 就是字体文件中的编码。所以  对应的就是数字“9”。
知道了原理,我们来看下如何实现。
处理字体文件,我们需要用到 FontTools 库。
先将字体文件转换为 xml 文件看下:
from fontTools.ttLib import TTFont
font = TTFont('bb70be69aaed960fa6ec3549342b87d82084.woff')
font.saveXML('bb70be69aaed960fa6ec3549342b87d82084.xml')
打开 xml 文件
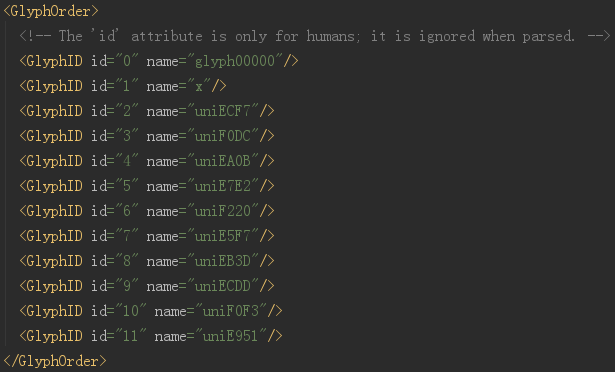
开头显示的就是全部的编码,这里的 id 仅仅是编号而已,千万别当成是对应的真实值。实际上,整个字体文件中,没有任何地方是说明 EA0B 对应的真实值是啥的。
看到下面
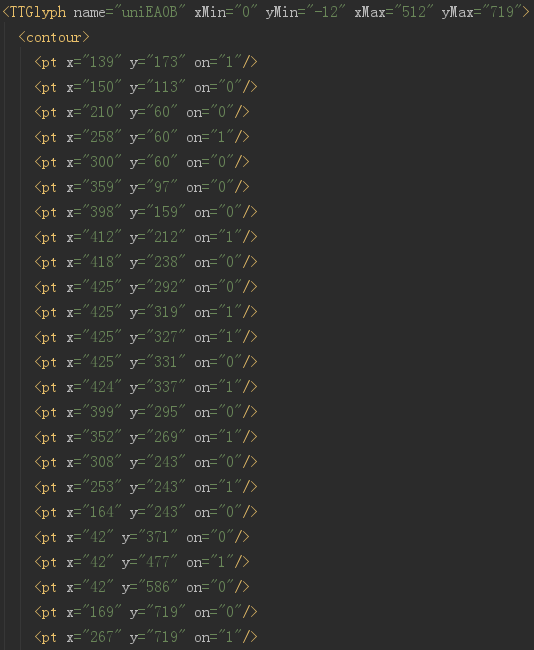
这里就是每个字对应的字体信息,计算机显示的时候,根本不需要知道这个字是啥,只需要知道哪个像素是黑的,哪个像素是白的就可以了。
猫眼的字体文件是动态加载的,每次刷新都会变,虽然字体中定义的只有 0-9 这9个数字,但是编码和顺序都是会变的。就是说,这个字体文件中“EA0B”代表“9”,在别的文件中就不是了。
但是,有一样是不变的,就是这个字的形状,也就是上图中定义的这些点。
我们先随便下载一个字体文件,命名为 base.woff,然后利用 fontstore 网站查看编码和实际值的对应关系,手工做成字典并保存下来。爬虫爬取的时候,下载字体文件,根据网页源码中的编码,在字体文件中找到“字形”,再循环跟 base.woff 文件中的“字形”做比较,“字形”一样那就说明是同一个字了。在 base.woff 中找到“字形”后,获取“字形”的编码,而之前我们已经手工做好了编码跟值的映射表,由此就可以得到我们实际想要的值了。
这里的前提是每个字体文件中所定义的“字形”都是一样的(猫眼目前是这样的,以后也许还会更改策略),如果更复杂一点,每个字体中的“字形”都加一点点的随机形变,那这个方法就没有用了,只能祭出杀手锏“OCR”了。
下面是完整的代码,抓取的是猫眼2018年电影的第一页,由于主要是演示破解字体反爬,所以没有抓取全部的数据。
代码中使用的 base.woff 文件跟上面截图显示的不是同一个,所以会看到编码跟值跟上面是对不上的。
import os
import time
import re
import requests
from fontTools.ttLib import TTFont
from fake_useragent import UserAgent
from bs4 import BeautifulSoup host = 'http://maoyan.com' def main():
url = 'http://maoyan.com/films?yearId=13&offset=0'
get_moviescore(url) os.makedirs('font', exist_ok=True)
regex_woff = re.compile("(?<=url\(').*\.woff(?='\))")
regex_text = re.compile('(?<=<span class="stonefont">).*?(?=</span>)')
regex_font = re.compile('(?<=&#x).{4}(?=;)') basefont = TTFont('base.woff')
fontdict = {'uniF30D': '', 'uniE6A2': '', 'uniEA94': '', 'uniE9B1': '', 'uniF620': '',
'uniEA56': '', 'uniEF24': '', 'uniF53E': '', 'uniF170': '', 'uniEE37': ''} def get_moviescore(url):
# headers = {"User-Agent": UserAgent(verify_ssl=False).random}
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/68.0.3440.106 Safari/537.36'}
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
ddlist = soup.find_all('dd')
for dd in ddlist:
a = dd.find('a')
if a is not None:
link = host + a['href']
time.sleep(5)
dhtml = requests.get(link, headers=headers).text
msg = {} dsoup = BeautifulSoup(dhtml, 'lxml')
msg['name'] = dsoup.find(class_='name').text
ell = dsoup.find_all('li', {'class': 'ellipsis'})
msg['type'] = ell[0].text
msg['country'] = ell[1].text.split('/')[0].strip()
msg['length'] = ell[1].text.split('/')[1].strip()
msg['release-time'] = ell[2].text[:10] # 下载字体文件
woff = regex_woff.search(dhtml).group()
wofflink = 'http:' + woff
localname = 'font\\' + os.path.basename(wofflink)
if not os.path.exists(localname):
downloads(wofflink, localname)
font = TTFont(localname) # 其中含有 unicode 字符,BeautifulSoup 无法正常显示,只能用原始文本通过正则获取
ms = regex_text.findall(dhtml)
if len(ms) < 3:
msg['score'] = ''
msg['score-num'] = ''
msg['box-office'] = ''
else:
msg['score'] = get_fontnumber(font, ms[0])
msg['score-num'] = get_fontnumber(font, ms[1])
msg['box-office'] = get_fontnumber(font, ms[2]) + dsoup.find('span', class_='unit').text
print(msg) def get_fontnumber(newfont, text):
ms = regex_font.findall(text)
for m in ms:
text = text.replace(f'&#x{m};', get_num(newfont, f'uni{m.upper()}'))
return text def get_num(newfont, name):
uni = newfont['glyf'][name]
for k, v in fontdict.items():
if uni == basefont['glyf'][k]:
return v def downloads(url, localfn):
with open(localfn, 'wb+') as sw:
sw.write(requests.get(url).content) if __name__ == '__main__':
main()
也可以扫码关注我的个人公众号,后台回复 “猫眼”获取源码,及代码中我使用的 basefont。
相关博文推荐:
Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
Python爬虫实例:爬取豆瓣Top250
Python爬虫实例:爬取猫眼电影——破解字体反爬的更多相关文章
- 爬虫基本库request使用—爬取猫眼电影信息
使用request库和正则表达式爬取猫眼电影信息. 1.爬取目标 猫眼电影TOP100的电影名称,时间,评分,等信息,将结果以文件存储. 2.准备工作 安装request库. 3.代码实现 impor ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- Python使用asyncio+aiohttp异步爬取猫眼电影专业版
asyncio是从pytohn3.4开始添加到标准库中的一个强大的异步并发库,可以很好地解决python中高并发的问题,入门学习可以参考官方文档 并发访问能极大的提高爬虫的性能,但是requests访 ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- # [爬虫Demo] pyquery+csv爬取猫眼电影top100
目录 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 代码君 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 https://maoyan.co ...
- # 爬虫连载系列(1)--爬取猫眼电影Top100
前言 学习python有一段时间了,之前一直忙于学习数据分析,耽搁了原本计划的博客更新.趁着这段空闲时间,打算开始更新一个爬虫系列.内容大致包括:使用正则表达式.xpath.BeautifulSoup ...
- 爬虫--requests爬取猫眼电影排行榜
'''目标:使用requests分页爬取猫眼电影中榜单栏目中TOP100榜的所有电影信息,并将信息写入文件URL地址:http://maoyan.com/board/4 其中参数offset表示其实条 ...
- Python 爬取猫眼电影最受期待榜
主要爬取猫眼电影最受期待榜的电影排名.图片链接.名称.主演.上映时间. 思路:1.定义一个获取网页源代码的函数: 2.定义一个解析网页源代码的函数: 3.定义一个将解析的数据保存为本地文件的函数: ...
随机推荐
- Grafana简单使用
下载安装 Grafana也是用GO语言写的,无任何依赖,安装非常简单. 启动 sudo service grafana-server start 运行 直接访问:http://your_ip:3000 ...
- bzoj 4556 字符串
后缀数组,暴力硬跑 贼快 #include<cstdio> #include<cstring> #include<iostream> #include<alg ...
- 毕业样本=[威尔士大学毕业证书]UWIC原件一模一样证书
威尔士大学毕业证[微/Q:2544033233◆WeChat:CC6669834]UC毕业证书/联系人Alice[查看点击百度快照查看][留信网学历认证&博士&硕士&海归&am ...
- Python + Appium 【已解决】driver(session)在多个class之间复用,执行完一个类的用例,再次执行下个类的用例时不需要初始化
实现效果:打开App进行自动化测试,只需打开APP一次,按先后顺序执行n个py文件中的相应操作,实现自动化测试. 示例:如截图示例,一个App,根据此APP内不同的模块,写成了不同的py文件, 预期结 ...
- 计算机17-3,4作业A
A货车过隧道问题 Description 输入若干组数据,每组数据中有三个整数分别表示某条公路沿途所经过的三个隧道的最大高度,数之间用单个空格分隔.输入高度单位是厘米,范围在0到762之间.现有一台高 ...
- hive删除表和表中的数据
hive删除表和表中的数据,以及按分区删除数据 hive删除表: drop table table_name; hive删除表中数据: truncate table table_name; hive按 ...
- Java8新特性之五:Optional
NullPointerException相信每个JAVA程序员都不陌生,是JAVA应用程序中最常见的异常.之前,Google Guava项目曾提出用Optional类来包装对象从而解决NullPoin ...
- 购物网站首页(学习ING)
这几天在学着做购物网站,初步的完成了首页的框架吧,记录下.慢慢加强.主要难点,是样式的设置问题,如果自己想,自己摸索,可能会需要很长的调试.也是一个孰能生巧的过程吧,有些部分没有按照学习资料的方法也做 ...
- (leetcode:选择不相邻元素,求和最大问题):打家劫舍(DP:198/213/337)
题型:从数组中选择不相邻元素,求和最大 (1)对于数组中的每个元素,都存在两种可能性:(1)选择(2)不选择,所以对于这类问题,暴力方法(递归思路)的时间复杂度为:O(2^n): (2)递归思路中往往 ...
- Java日志正确使用姿势
前言 关于日志,在大家的印象中都是比较简单的,只须引入了相关依赖包,剩下的事情就是在项目中“尽情”的打印我们需要的信息了.但是往往越简单的东西越容易让我们忽视,从而导致一些不该有的bug发生,作为一名 ...