(数据科学学习手札57)用ggplotly()美化ggplot2图像
一、简介
经常利用Python进行数据可视化的朋友一定用过或听说过plotly这样的神器,我在(数据科学学习手札43)Plotly基础内容介绍中也曾做过非常详细的介绍,其渲染出的图像以浏览器为载体,非常精美,且绘制图像的自由程度堪比ggplot2,其为R也提供了接口,在plotly包中,但对于已经习惯用ggplot2进行可视化的朋友而言,自然是不太乐意转向plotly的学习,有趣的是plotly的R包中有着函数ggplotly(),可以将ggplot2生成的图像转换为交互式的plotly图像,且还可以添加上ggplot2原生图像中无法实现的交互标签,最重要的是其使用方法非常傻瓜式,本文就将结合几个小例子来介绍ggplotly()的神奇作用;
二、ggplotly()的使用
我们从一个简单的小例子出发:
library(tidyverse)
library(plotly) p <- ggplot(iris, aes(x=Sepal.Length, y=Sepal.Width, color=Species, shape=Species)) +
geom_point(size=, alpha=0.6)
p
这里我们利用R自带的鸢尾花数据绘制了一个简单的散点图,接着我们只需要简单的一行代码就可以实现神奇的转换效果:
library(plotly)
ggplotly(p)
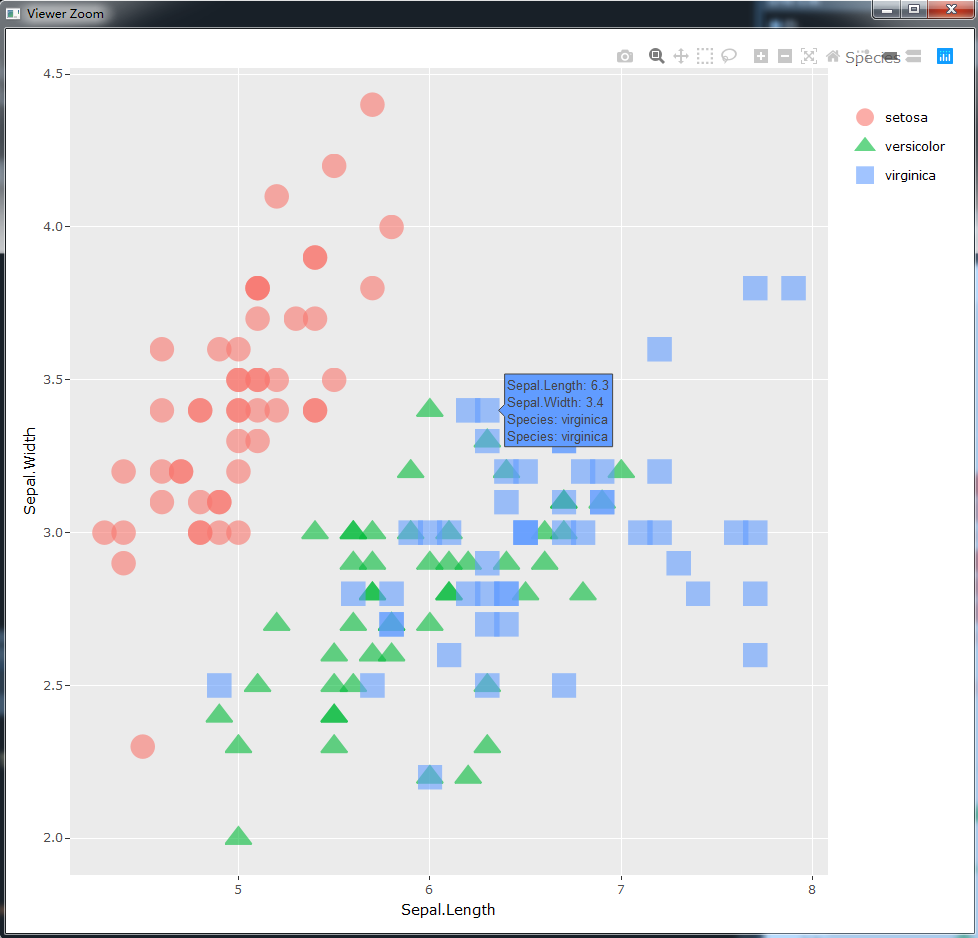
可以观察到,经过ggplotly()处理后的ggplot2图像通过R-studio中的viewer窗口打开,即当前的图像是网页文件,而随着我们鼠标的放置,可以在保留原有ggplot2外观的情况下,进行plotly式的交互操作,注意上图中我们鼠标放置点位对应显示的悬浮标签,其中的内容是默认的格式,即在这张ggplot2图像中所涉及到的所有信息,在上图中即为横纵轴对应的数据,以及在定义形状和颜色时使用到的分类属性信息,如果我们想要在原有的ggplot2图像的基础上对文本标签内容进行一些改变,可以利用下面的方式:
mytext <- paste("Sepal Length is ", iris$Sepal.Length, "\n" , "Sepal Width is ", iris$Sepal.Width, "\n", "Row Number: ",rownames(iris), sep="")
pp <- plotly_build(p)
style(pp, text=mytext, hoverinfo = "text", traces = c(, , ))
这里我们先定义mytext向量来保存每一个点我们希望其悬浮标签中显示的信息,接着利用plotly_build()函数(换成ggplotly()效果相同)来将原生的ggplot2图像转化为交互图像,再利用style()来调整交互图像上的悬浮标签信息,效果如下图所示:

可以看到悬浮标签内的信息如我们所愿,但ggplot2中的某些部件在plotly中是相冲突的,例如图例:
p_changed <- ggplot(iris, aes(x=Sepal.Length, y=Sepal.Width, color=Species, shape=Species)) +
geom_point(size=, alpha=0.6) +
theme(legend.position = c(., .)) p_changed

在上图中我们微调了图例的位置,但是对上图使用ggplotly()后效果如下:
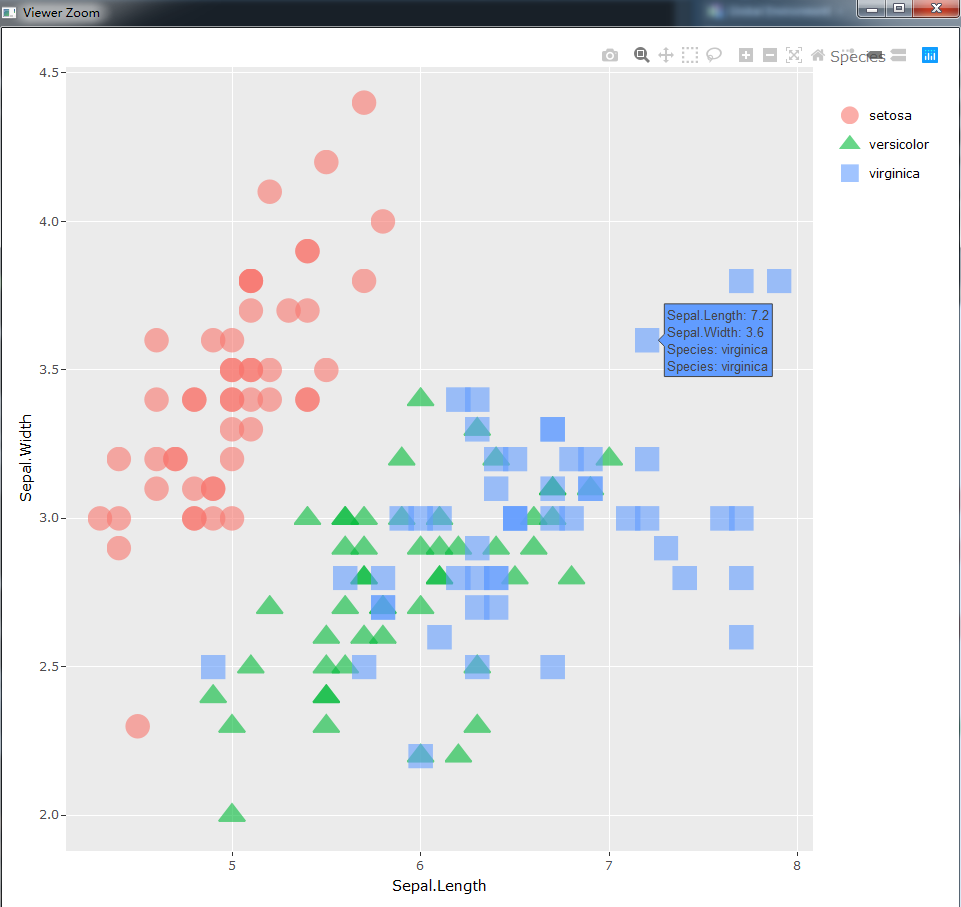
可以看到图例并没有得到改变,因此在实际应用中使用ggplotly()还需慎重考虑。
以上就是本文的全部内容,如有笔误望指出。
参考资料:https://www.r-bloggers.com/get-the-best-from-ggplotly/
(数据科学学习手札57)用ggplotly()美化ggplot2图像的更多相关文章
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
- (数据科学学习手札36)tensorflow实现MLP
一.简介 我们在前面的数据科学学习手札34中也介绍过,作为最典型的神经网络,多层感知机(MLP)结构简单且规则,并且在隐层设计的足够完善时,可以拟合任意连续函数,而除了利用前面介绍的sklearn.n ...
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
随机推荐
- Java内部类类型
可以在类中的任何位置定义内部类,并在其中编写Java语句.有三种类型的内部类. 内部类的类型取决于位置和声明的方式. 成员内部类 局部内部类 匿名内部类 成员内部类 成员内部类在类中声明的方式与声明成 ...
- export的用法
定义环境变量并且赋值 # export MYENV= //定义环境变量并赋值 # export -p declare -x HOME=“/root“ declare -x LANG=“zh_CN.UT ...
- 神奇,教你用随机数打印hello world
下面是一段随机数程序. public static void main(String[] args) { System.out.println(randomString(-229985452) + & ...
- Neo4J空间数据存储
1.Neo4j Spatial 简介 1.1Neo4j Spatial概念 Neo4j Spatial项目是图数据库Neo4j的一个插件,它通过将空间数据映射到图模型(graph model),它将对 ...
- Python之Tab键自动补全
首先备份一下Tab键自动补全代码: # python start file import sys import readline import rlcompleter import atexit im ...
- JavaScript 中 reduce去重方法
过去有很长一段时间,我一直很难理解 reduce() 这个方法的具体用法,平时也很少用到它.事实上,如果你能真正了解它的话,其实在很多地方我们都可以用得上,那么今天我们就来简单聊聊 JS 中 redu ...
- vue 点击切换图标
<div @click="showImg" class="showSearch"> <img class="header_img&q ...
- python小项目(-)图片转字符画
# -*- coding: utf-8 -*- from PIL import Image codeLib = '''@B%8&WM#*oahkbdpqwmZO0QLCJUYXzcvunxrj ...
- leetcode-第14周双周赛-1271-十六进制魔术数字
自己的提交: class Solution: def toHexspeak(self, num: str) -> str: num = hex(int(num)) num = str(num)[ ...
- Java/sql找出oracle数据库有空格的列
1.java方式 String table_sql = "select table_name from user_tables";//所有用户表 List<String> ...