最新2.7版本丨DataPipeline数据融合产品最新版本发布

此次发布的2.7版本在进一步优化产品底层数据处理逻辑的同时更加注重提升用户在数据融合任务的日常管理、运行监控及资源分配等管理方面的功能增强与优化,力求帮助大家更为直观、便捷、稳定地管理数据融合任务,提升系统的易用性与稳定性。
一、新增功能
1. 在待处理列表中查看或配置重要任务、故障任务、待完善任务、性能关注任务
功能背景:
对于大多数数据工程师而言,每天需要配置、管理、监控的任务数以百计,任务的重要程度、时效性要求与性能要求也都千差万别,其中既包括为线上产品提供实时计算数据的任务,也有数据备份等优先级较低的任务。同时,为了应对不停变化的市场与业务需求,新的数据融合任务需求也会连续不断地涌现,数据工程师在保证现有任务稳定运行的同时,还需不断地新增数据任务。
大量不同类型、不同状态的任务平铺在客户端首页,导致重要任务难以得到优先关注,待完善任务可能被遗漏,性能较差的任务无法被发现,查找任务、管理任务、处理问题占用了较多工作时间。
新版本上线后,用户可以对重要任务添加标识,平台也会对任务按照重要程度、配置完成情况及运行状态、运行效率进行评估及管理,用户可以通过待处理列表非常直观地看到所关注的重要任务、运行出现问题的故障任务、配置未完成待完善的任务及性能较低需要关注的任务,帮助数据工程师在日常任务监控与新需求处理中提高效率,同时对运行效率有直观的了解,保障业务连续性。
功能详情:
(1)重要任务
工作事务通常带有自身的优先级属性,数据同步任务亦如此。针对重要任务,DataPipeline提供星标设置,于主页优先展示。用户可实时关注重要任务状态,保证重要任务稳定运行。
(2)故障任务
集中展示出现故障的任务,保障问题不被遗漏,任务故障处理全面有序。
(3)非激活状态
集中展示处于非激活状态的任务,明确列示需要进一步完善配置或需要修改配置的任务,保证数据工程师的任务配置工作全面有序。
(4)性能关注
性能关注部分会根据系统对任务效率评估分别展示传输速率较低的10个批量任务和实时任务,通过查看性能关注,可以及时发现运行状态不良的任务,提前做出处理,防止由于性能问题导致更严重的问题发生。
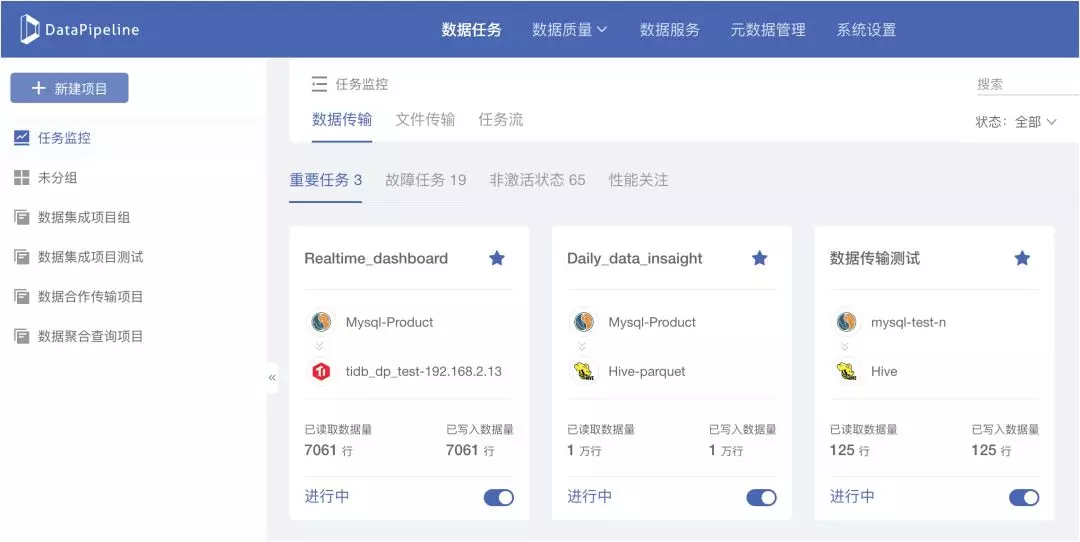
2. 可按照项目对任务进行分组管理
功能背景:
DataPipeline在之前的版本中帮助用户实现了多种来源,不同结构数据的同步处理。但随着产品不断被深度使用,系统用户和数据任务数量的不断增加,多个项目的数据融合任务混杂在一起,导致任务配置、监控及管理有些不便。
我们了解到,一个数据工程师可能同时需要管理多个项目,每个项目可能包含数十个上百个数据融合任务,在不能按照项目对数据融合任务进行分组管理的时候,只能凭借记忆通过名称、数据节点等信息进行搜索,耗时费力。
因此,DataPipeline新增了根据项目进行任务分组的功能,用户可以根据任务所属项目,对上百个任务进行分组管理,大大提高了效率。
功能详情:
(1)支持通过自定义创建项目,对任务进行分组;
(2)支持通过勾选任务,改变多个任务的任务分组。
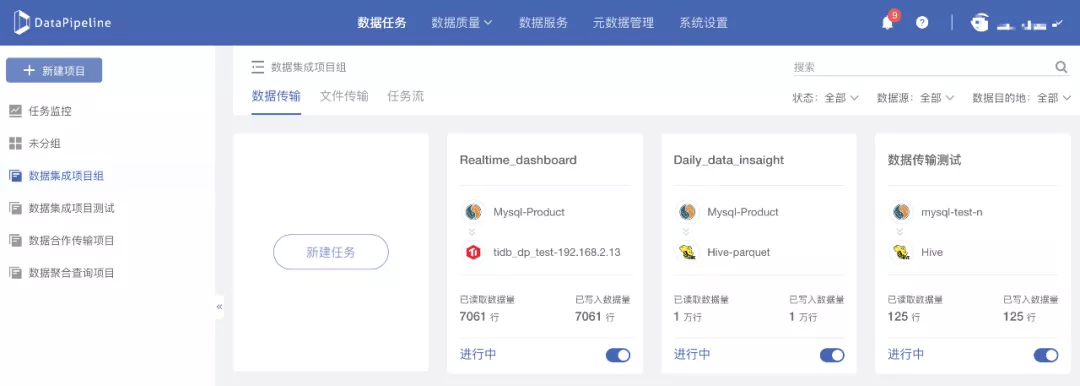
3. 可以为任务配置特定资源组
功能背景:
虽然DataPipeline数据融合产品基于并行计算框架,从基础架构层面支持任务级高可用,但在资源组管理方面一直未对用户开放,用户在使用之前版本的DataPipeline时,所有数据任务均在一个默认资源组中运行,无法根据任务的重要程度来分配任务运行资源。
这就要求用户只能针对重要任务配置单独的集群以保证任务的稳定、高效运行。这种方式在实际操作过程中存在很多客观限制,如系统资源申请困难,成本预算控制等,也给我们的数据工程师用户们造成了很大的困扰。
因此我们决定在新版本中开放系统资源组配置和分配功能,同时计划在未来的版本中开放动态资源调配功能。
例如,当前系统资源为一台16C64G的服务器,在无法分配资源组时任务运行状态如下:

资源组配置开放以后,用户可以配置一个重要任务资源组和一个一般任务资源组,任务运行状态如下:
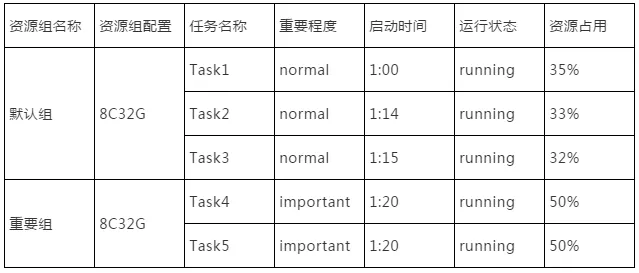
重要任务相较于其他普通任务虽然启动时间较晚。但由于被分配在独立的资源组中,仍然可以保证有足够的资源保障任务平稳运行。
功能详情:
(1)资源组配置
在部署DataPipeline时,通过修改配置文件,可以将数据源端/目的地端的服务器资源划分为多个资源组,实现业务资源组解耦。
资源组配置文件路径:
/data/datapipeline/dpconfig/resource_group_config.json
源端与目的地端均有两个资源组的配置文件,资源组配置文件样例如下:
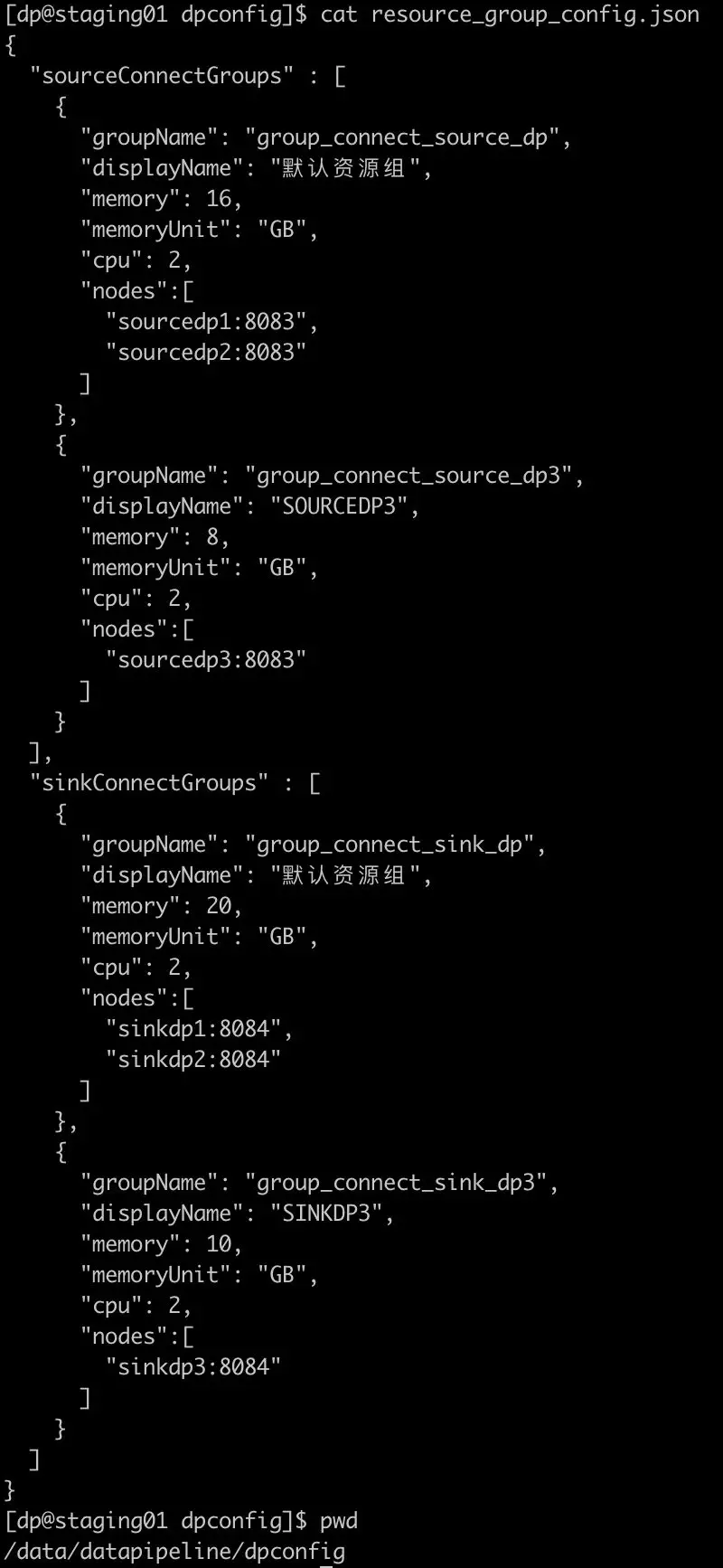
配置详细说明如下:
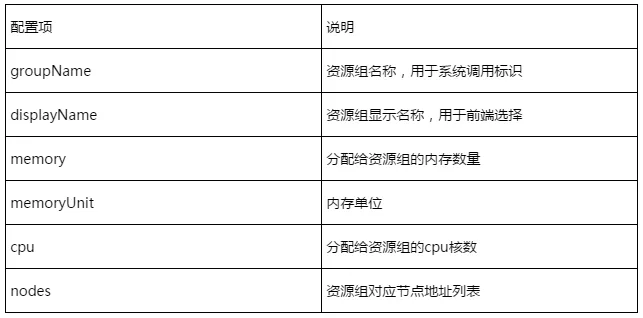
注:修改配置文件后需要重启服务使资源组配置生效
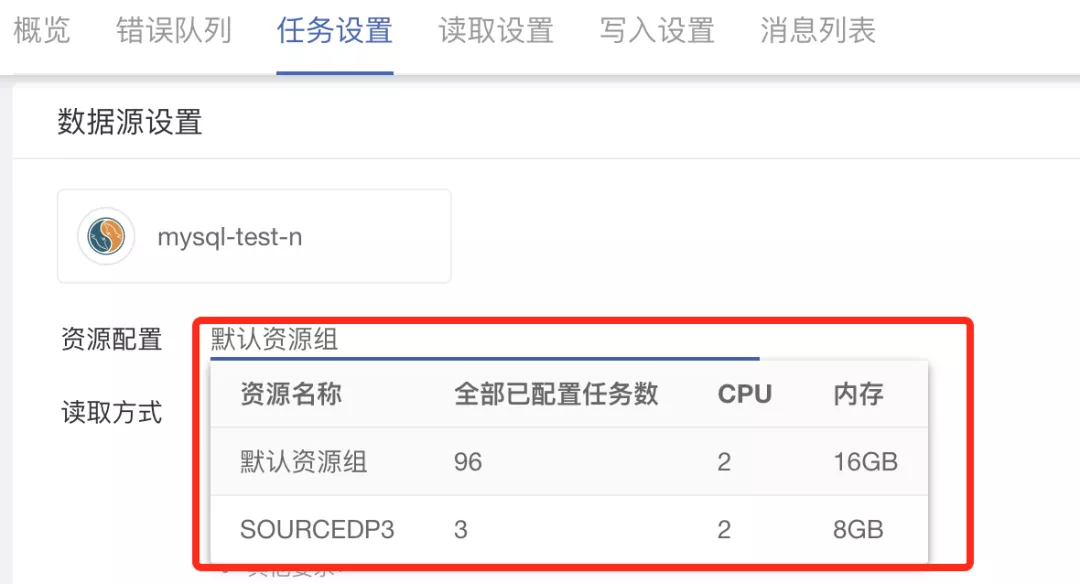
(2)为任务的读取与写入分配资源组
用户在任务设置过程中可以针对每个任务的数据读取和数据写入分别选择支撑任务运行的资源组。
二、优化功能
1. 数据传输消息队列粒度拆分优化
功能背景:
DataPipeline为更好地支持高效数据融合任务,对数据传输消息队列粒度进行了进一步的拆分优化。
功能详情:
首先,我们来看一下数据在DataPipeline是如何流转的:

在此需求的用户场景中,源端数据节点为DB1,DB1中包含三张数据表分别为T1、T2和T3。目的地端数据节点为DB2,DB2中包含三张数据表分别为T4、T5和T6。 数据融合要求为,将T1、T2、T3中的数据进行合并后写入到T4中,将T2中的数据同步到T5中,将T3中的数据同步到T6中。
在之前的处理逻辑中(如图1),按照目的地写入要求的粒度来建立消息队列,即将T1、T2、T3的数据写入1个消息队列进行缓存,也就是图1中的消息队列1。
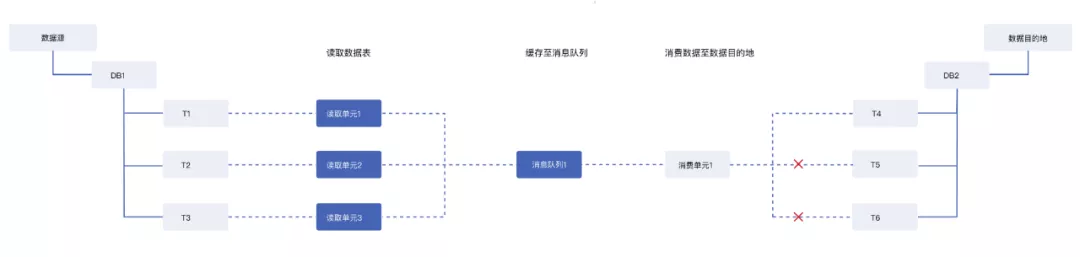
图1
该缓存机制可以很好地支持T4的数据同步,由于数据进入了1个消息队列,所以在同步T5、T6的数据时需要将缓存中的T1、T2、T3数据进行拆分,处理效率较低。
DataPipeline针对数据传输中消息队列缓存粒度进行了拆分优化(如图2),按照数据源数据表的粒度,进行消息队列拆分,即将数据源T1、T2、T3的数据分别写入三个消息队列进行缓存。
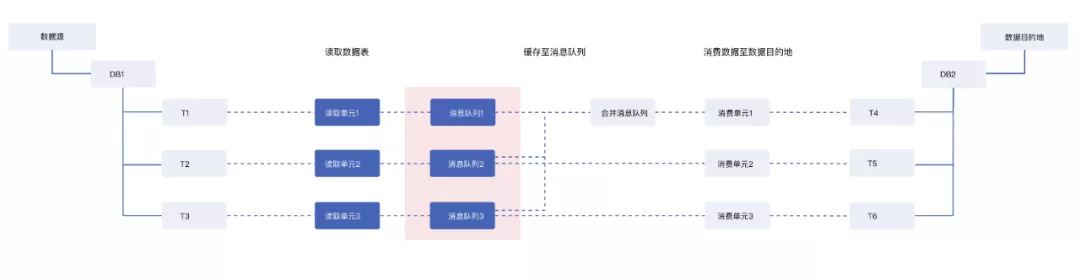
图2
同步至T4的数据会读取T1、T2、T3分别对应的消息队列,进行合并后写入合并消息队列,再供T4对应的消费单元进行消费,同步至T5、T6的任务可以分别读取T2与T3对应的消息队列进行数据写入。
这样,我们便可同时支持源端多表合一同步与其中一张表的单独同步。由于拆分多个并发来读取数据,T2至T5、T3至T6的数据同步速率会明显提升。而对于将T1、T2、T3的数据进行合并同步至T4的流程,虽然添加了一步消息队列内部的合并操作,但速率影响较小,可以较好地支持上述场景。
2. 支持在任一数据同步任务中灵活修改数据源/目的地配置信息
通过支持在任一数据同步任务中灵活修改数据源/目的地配置信息,可使数据节点配置在全局生效,提升任务配置效率。
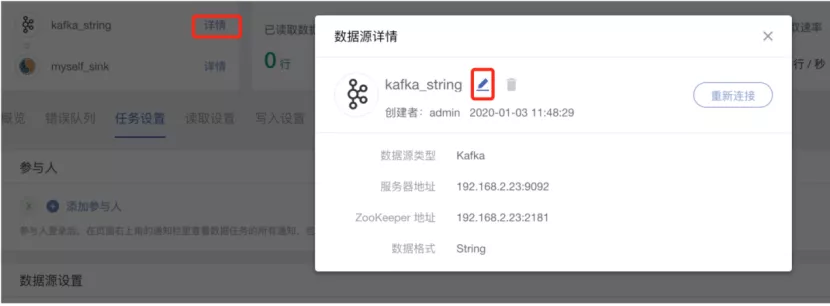
除数据源/目的地类型之外均可修改,当数据源有其他任务正在运行时不允许修改,修改后数据源/目的地节点的配置即全局生效。
三、其他功能增强与问题修复
除上述功能之外,DataPipeline还分别从以下几方面对产品进行了功能增强与问题修复:
1. 支持对用户注册信息中邮箱的修改
2. 为数据任务页面复制、编辑、删除等按钮添加文字注释
3. 优化线程实时任务心跳,支撑运维监控
4. 优化元数据查询SQL和相关逻辑,修复索引查询
5. Hive数据源重构优化
6. Hive Kerberos的验证优化
7. 优化由于JDBC连接造成的任务卡顿问题
DataPipeline的每一次版本迭代都凝聚了团队对企业数据管理需求的深入思考和积极探索,希望在这个特殊时期,新版本能够切实帮助大家更敏捷高效地融合数据、使用数据、分析数据。
最新2.7版本丨DataPipeline数据融合产品最新版本发布的更多相关文章
- DataPipeline数据融合重磅功能丨一对多实时分发、批量读取模式
为能更好地服务用户,DataPipeline最新版本支持: 1. 一个数据源数据同时分发(实时或定时)到多个目的地: 2. 提升Hive的使用场景: 写入Hive目的地时,支持选择任意目标表字段作为 ...
- DataPipeline CTO陈肃:构建批流一体数据融合平台的一致性语义保证
文 | 陈肃 DataPipelineCTO 交流微信 | datapipeline2018 本文完整PPT获取 | 关注公众号后,后台回复“陈肃” 首先,本文将从数据融合角度,谈一下DataPipe ...
- DataPipeline丨新型企业数据融合平台的探索与实践
文 |刘瀚林 DataPipeline后端研发负责人 交流微信 | datapipeline2018 一.关于数据融合和企业数据融合平台 数据融合是把不同来源.格式.特点性质的数据在逻辑上或物理上有机 ...
- Atitit 数据融合merge功能v3新特性.docx
Atitit 数据融合merge功能v3新特性.docx 1.1. 版本历史1 1.2. 生成sql结果1 1.3. 使用范例1 1.4. 核心代码1 1.1. 版本历史 V2增加了replace部分 ...
- 搭建企业级实时数据融合平台难吗?Tapdata + ES + MongoDB 就能搞定
摘要:如何打造一套企业级的实时数据融合平台?Tapdata 已经找到了最佳实践,下文将以 Tapdata 的零售行业客户为例,与您分享:基于 ES 和 MongoDB 来快速构建一套企业级的实时数 ...
- SqlServer高版本数据本分还原到低版本方法
最近遇见一个问题: 想要将Sqlserver高版本备份的数据还原到低版本SqlServer上去,但是这在SqlServer中是没法直接还原数据库的,所以经过一系列的请教总结出来一下可用方法. 首先.你 ...
- 最新选择Godaddy主机方案美国数据中心教程指导
随着Godaddy官方管理层的变动之后,主营重心已经从当初的域名开始转向到域名和主机产品上.这点我们从其发布域名优惠信息的频率也可以看到,而且我们可以看到常年的主机半价优惠,以及针对主机销售年付方案赠 ...
- reshape2 数据操作 数据融合 (melt)
前面一篇讲了cast,想必已经见识到了reshape2的强大,当然在使用cast时配合上melt这种强大的揉数据能力才能表现的淋漓尽致. 下面我们来看下,melt这个函数以及它的特点. melt(da ...
- SLAM+语音机器人DIY系列:(三)感知与大脑——2.带自校准九轴数据融合IMU惯性传感器
摘要 在我的想象中机器人首先应该能自由的走来走去,然后应该能流利的与主人对话.朝着这个理想,我准备设计一个能自由行走,并且可以与人语音对话的机器人.实现的关键是让机器人能通过传感器感知周围环境,并通过 ...
随机推荐
- 【游记】THUWC2019-2 Bystander
[游记]THUWC2019-2 Bystander Day0/-1 感觉自己怎么样都去不了PKUWC(没错)了,差点放弃模拟面试,在老妈的要求下勉强面试,自我介绍没怎么准备,然后就说 我喜欢唱跳Rap ...
- status100到500http响应对应状态解释
1xx-信息提示 这些状态代码表示临时的响应.客户端在收到常规响应之前,应准备接收一个或多个1xx响应. 100-继续. 101-切换协议. 2xx-成功 这类状态代码表明服务器成功地接受了客户端请求 ...
- html页脚固定在底部的方法
<style type="text/css"> html { height: 100%; } body { height: 100%; margin: 0; paddi ...
- 「CF242E」XOR on Segment 解题报告
题面 长度为\(n\)的数列,现有两种操作: 1.区间异或操作 2.区间求和操作 对于每个查询,输出答案 思路: 线段树+二进制拆位 线段树区间修改一般使用的都是懒标记的方法,但是对于异或,懒标记的方 ...
- linux入门系列2--CentOs图形界面操作及目录结构
上一篇文章"linux入门系列1--环境准备及linux安装"直观演示了虚拟机软件VMware和Centos操作系统的安装,按照文章一步一步操作,一定都可以安装成功.装好系统之后, ...
- 小小知识点(十四)——Adobe photoshop cc 2018中简单抠图的一些基本操作
一 如何抠图 1. 右键弹出选择工具,随后鼠标左键选择快速选择工具 2.通过点击鼠标,选择想要的区域: Alt+鼠标右键 左右拖动鼠标可调整画笔大小 Alt+鼠标滑轮,可放大或缩小画布大小 ctrl ...
- Vue.js项目在apache服务器部署后,刷新404的问题
原因是vue-router 使用了路由的 history 模式,这种模式充分利用 history.pushState API 来完成 URL 跳转而无须重新加载页面. const router = n ...
- 0182 JavaScript执行机制:单线程,同步任务和异步任务,执行栈,消息队列,事件循环
以下代码执行的结果是什么? [结果是1 2 3 ] console.log(1); setTimeout(function () { console.log(3); }, 1000); console ...
- 【转】ArcGIS Server 10.1 动态图层
ArcGISServer将GIS资源以服务的方式发布,能够让更多的人在Web上浏览.使用.不过,诸如气象.环保等方面的信息是实时变化的,按照之前常规的方法,我们先要将最新获得的信息组织成地图文档后再对 ...
- cogs 293. [NOI 2000] 单词查找树 Trie树字典树
293. [NOI 2000] 单词查找树 ★★☆ 输入文件:trie.in 输出文件:trie.out 简单对比时间限制:1 s 内存限制:128 MB 在进行文法分析的时候,通常需 ...