《爬虫学习》(四)(使用lxml,bs4库以及正则表达式解析数据)
1.XPath:
XPath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历。
工具:扩展商店里搜索:XPath Helper(我是QQ浏览器)

XPath的语法:

使用举例:

2. lxml库:
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据
下载:pip install lxml
基本使用:在lxml中使用xpath语法

3.bs4库的使用:
和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
lxml 只会局部遍历,而Beautiful Soup 是基于HTML DOM(Document Object Model)的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。
BeautifulSoup 用来解析 HTML 比较简单,API非常人性化,支持CSS选择器、Python标准库中的HTML解析器,也支持 lxml 的 XML解析器。
Beautiful Soup 3 目前已经停止开发,推荐现在的项目使用Beautiful Soup 4。
安装:pip install bs4
bs4的简单使用:
from bs4 import BeautifulSoup html = """ 一段HTML代码 """ #创建 Beautiful Soup 对象
# 使用lxml来进行解析
soup = BeautifulSoup(html,"lxml") print(soup.prettify())
举例使用:
# bs4库的使用
# from bs4 import BeautifulSoup
# html = 'xxxx'
# bs4底层由lxml实现
# bs = BeautifulSoup(html, 'lxml')
# .获取所有span标签
# spans = bs.find_all('span')
# for span in spans:
# print(span)
# .获取前二个span标签(limit=)中的第二个span标签([]) 下标:从0开始
# span = bs.find_all('span', limit=)[]
# print(span)
# .获取所有dl中class等于bottom的标签
# dls = bs.find_all('dl', class_='bottom')
# for dl in dls:
# print(dl)
# 或者使用attrs标签(attrs=一个字典)
# dls = bs.find_all('dl', attrs={'class':'bottom'})
# for dl in dls:
# print(dl)
# .获取所有a标签的href属性
# aList = bs.find_all('a')
# for a in aList:
# # .使用下标方法(推荐)
# href = a['href']
# # .使用attrs方式
# href2 = a.attrs['href']
# print(href2)
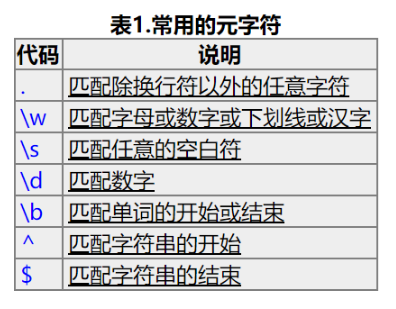
4.还有一种方法解析数据:正则表达式
以下内容从别人博客转载,方便复习



《爬虫学习》(四)(使用lxml,bs4库以及正则表达式解析数据)的更多相关文章
- 爬虫(四):BeautifulSoup库的使用
一:beautifulsoup简介 beautifulsoup是一个非常强大的工具,爬虫利器. beautifulSoup “美味的汤,绿色的浓汤” 一个灵活又方便的网页解析库,处理高效,支持多种解析 ...
- 爬虫学习(十一)——bs4基础学习
ba4的介绍: bs4是第三方提供的库,可以将网页生成一个对象,这个网页对象有一些函数和属性,可以快捷的获取网页中的内容和标签 lxml的介绍 lxml是一个文件的解释器,python自带的解释器是: ...
- Python爬虫学习==>第八章:Requests库详解
学习目的: request库比urllib库使用更加简洁,且更方便. 正式步骤 Step1:什么是requests requests是用Python语言编写,基于urllib,采用Apache2 Li ...
- python之爬虫(四)之 Requests库的基本使用
什么是Requests Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库如果你看过上篇文章关于urllib库的使用,你会发现,其 ...
- python爬虫学习(三):使用re库爬取"淘宝商品",并把结果写进txt文件
第二个例子是使用requests库+re库爬取淘宝搜索商品页面的商品信息 (1)分析网页源码 打开淘宝,输入关键字“python”,然后搜索,显示如下搜索结果 从url连接中可以得到搜索商品的关键字是 ...
- (转)Python爬虫学习笔记(2):Python正则表达式指南
以下内容转自CNBLOG:http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html 1. 正则表达式基础 1.1. 简单介绍 正则表达式并 ...
- 一只简单的网络爬虫(基于linux C/C++)————利用正则表达式解析页面
我们向一个HTTP的服务器发送HTTP的请求后,服务器会返回可能一个HTML页面(当然也可以是其他的资源),我们可以利用返回的HTML页面,在其中寻找其他的Url,例如我们可以这样在浏览器上查看一下H ...
- 一起来开发Android的天气软件(四)——使用Gson解析数据
离上一篇文章过去才4.5天,我们赶紧趁热打铁继续完毕该系列的天气软件的开发. 承接上一章的内容使用Volley实现网络的通信.返回给我们的是这一串Json数据{"weatherinfo&qu ...
- python网络爬虫学习笔记(二)BeautifulSoup库
Beautiful Soup库也称为beautiful4库.bs4库,它可用于解析HTML/XML,并将所有文件.字符串转换为'utf-8'编码.HTML/XML文档是与“标签树一一对应的.具体地说, ...
随机推荐
- vue项目多列导入
用axios.post传一个数组参数使用:JSON.stringify(this.params) <form> <span class="upimg">&l ...
- C# Thread.Join();Thread.Abort();
Join() 等待当前线程运行完成后,才继续执行主线程后续代码: Abort() 结束当前线程,继续执行主线程后续代码: Thread.Join(); static void Main(string[ ...
- How to output the target message in dotnet build command line
How can I output my target message when I using dotnet build in command line. I use command line to ...
- 2016湖南省赛 I Tree Intersection(线段树合并,树链剖分)
2016湖南省赛 I Tree Intersection(线段树合并,树链剖分) 传送门:https://ac.nowcoder.com/acm/contest/1112/I 题意: 给你一个n个结点 ...
- HDU4609 FFT+组合计数
HDU4609 FFT+组合计数 传送门:http://acm.hdu.edu.cn/showproblem.php?pid=4609 题意: 找出n根木棍中取出三根木棍可以组成三角形的概率 题解: ...
- ES6类的继承
ES6 引入了关键字class来定义一个类,constructor是构造方法,this代表实例对象. constructor相当于python的init 而this 则相当于self 类之间通过ext ...
- Java数据库操作学习
JDBC是java和数据库的连接,是一种规范,提供java程序与数据库的连接接口,使用户不用在意具体的数据库.JDBC类型:类型1-JDBC-ODBC桥类型2-本地API驱动类型3-网络协议驱动类型4 ...
- pycharm 更改创建文件默认路径
1.操作 依次找到以下路径修改为自己想要的路径即可:PyCharm——>Settings——>Appearance&Behavior——>System Setting——&g ...
- Java面向对象程序设计第14章3-8和第15章6
Java面向对象程序设计第14章3-8和第15章6 3.完成下面方法中的代码,要求建立一个缓冲区,将字节输入流中的内容转为字符串. import java.io.*; public class tes ...
- 使用spring boot中的JPA操作数据库
前言 Spring boot中的JPA 使用的同学都会感觉到他的强大,简直就是神器一般,通俗的说,根本不需要你写sql,这就帮你节省了很多时间,那么下面我们来一起来体验下这款神器吧. 一.在pom中添 ...