python3中的RE(正则表达式)
记录大佬的 整理
原文来自:https://blog.csdn.net/weixin_40136018/article/details/81183504
1.引入正则模块(Regular Expression)
要使用python3中的RE则必须引入 re模块
import re #引入正则表达式
2.主要使用的方法 match(), 从左到右进行匹配
#pattern 为要校验的规则
#str 为要进行校验的字符串
result = re.match(pattern, str)
#如果result不为None,则group方法则对result进行数据提取
result.group()
3. 正则表达式
1️⃣单字符匹配规则
字符 功能
. 匹配任意1个字符(除了\n)
[] 匹配[]中列举的字符
\d 匹配数字,也就是0-9
\D 匹配非数字,也就是匹配不是数字的字符
\s 匹配空白符,也就是 空格\tab
\S 匹配非空白符,\s取反
\w 匹配单词字符, a-z, A-Z, 0-9, _
\W 匹配非单词字符, \w取反
2️⃣表示数量的规则
字符 功能
* 匹配前一个字符出现0次多次或者无限次,可有可无,可多可少
+ 匹配前一个字符出现1次多次或则无限次,直到出现一次
? 匹配前一个字符出现1次或者0次,要么有1次,要么没有
{m} 匹配前一个字符出现m次
{m,} 匹配前一个字符至少出现m次
{m,n} 匹配前一个字符出现m到n次
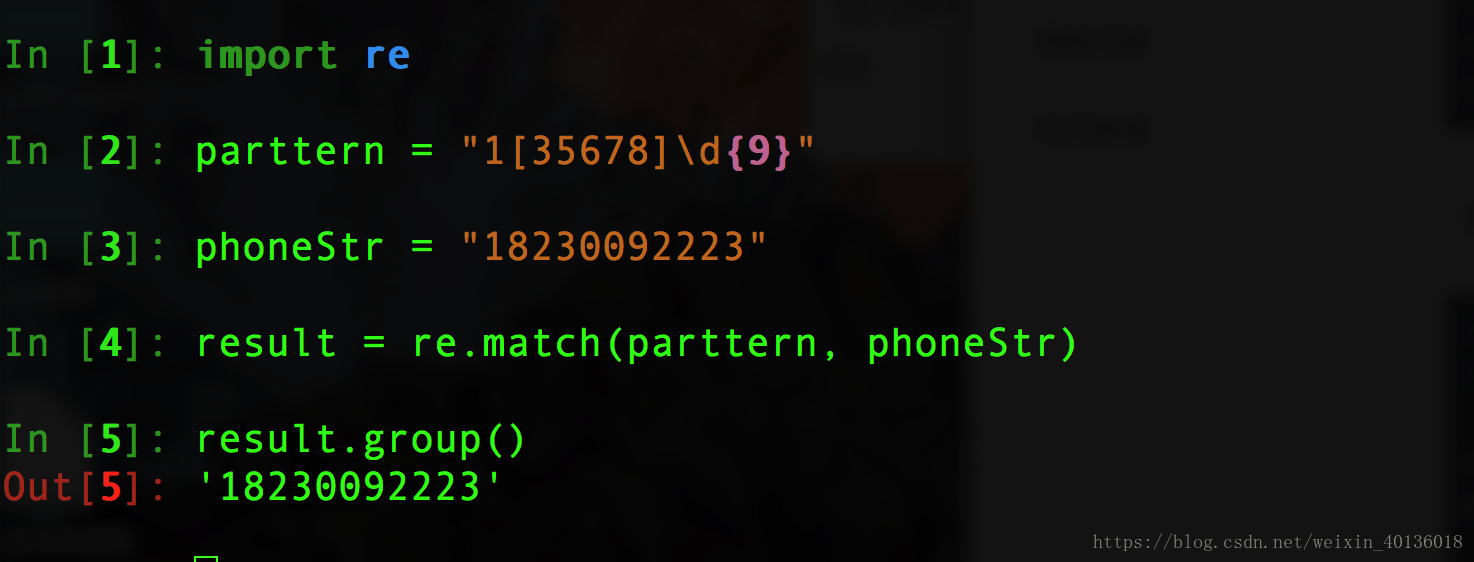
例一: 验证手机号码是否符合规则(不考虑边界问题)
#首先清楚手机号的规则
#1.都是数字 2.长度为11 3.第一位是1 4.第二位是35678中的一位
pattern = "1[35678]\d{9}"
phoneStr = "18230092223"
result = re.match(pattern, phoneStr)
result.group()
#执行结果如下图:
4. 原始字符串raw, 先来看如下实例:
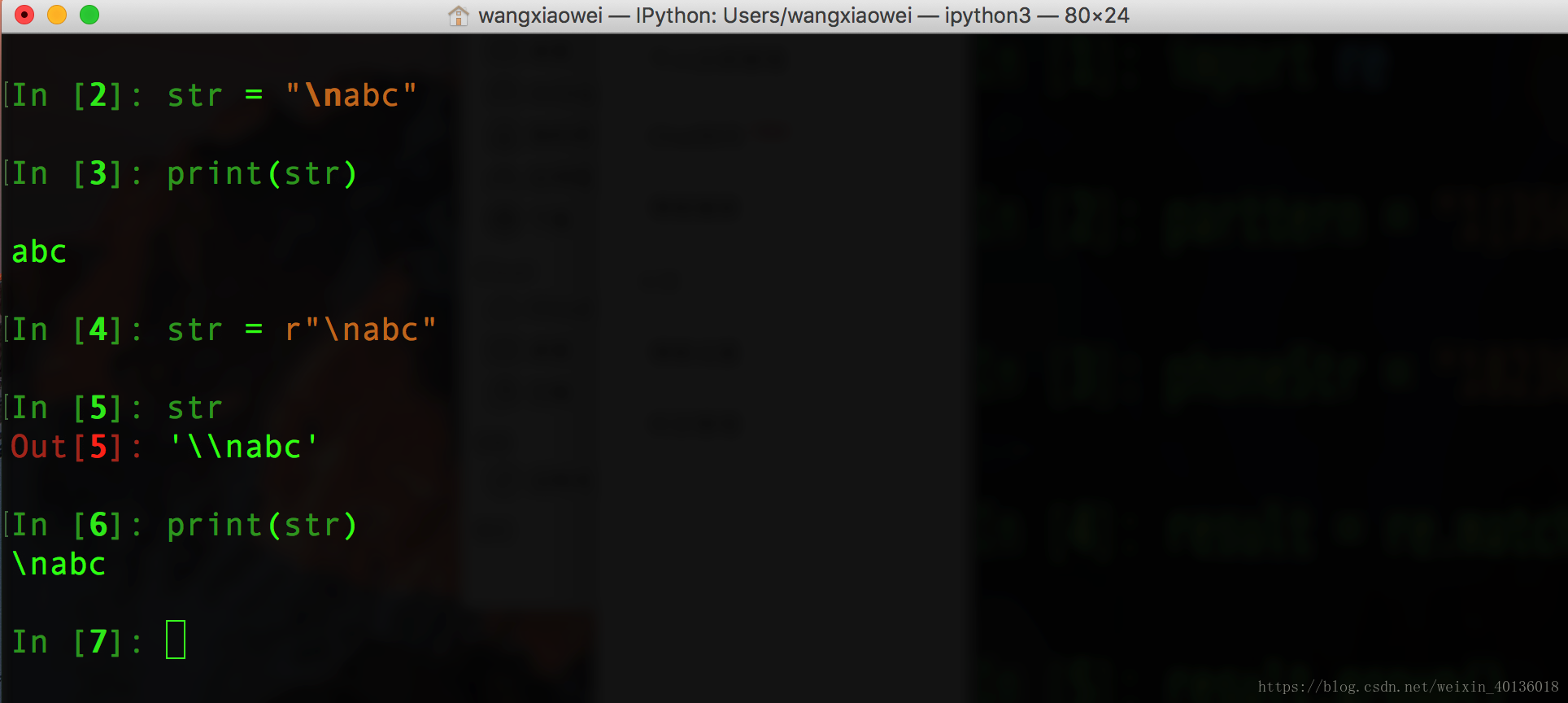
在上图中: 在给str赋值"\nabc"前加上"r"之后,python解释器会自动给str的值"\nabc"在加上一个"\".
使str在被打印的时候,能够保持原始字符串的值"\nabc"打印出来.
例二: (原始字符串在正则表达式中的应用)
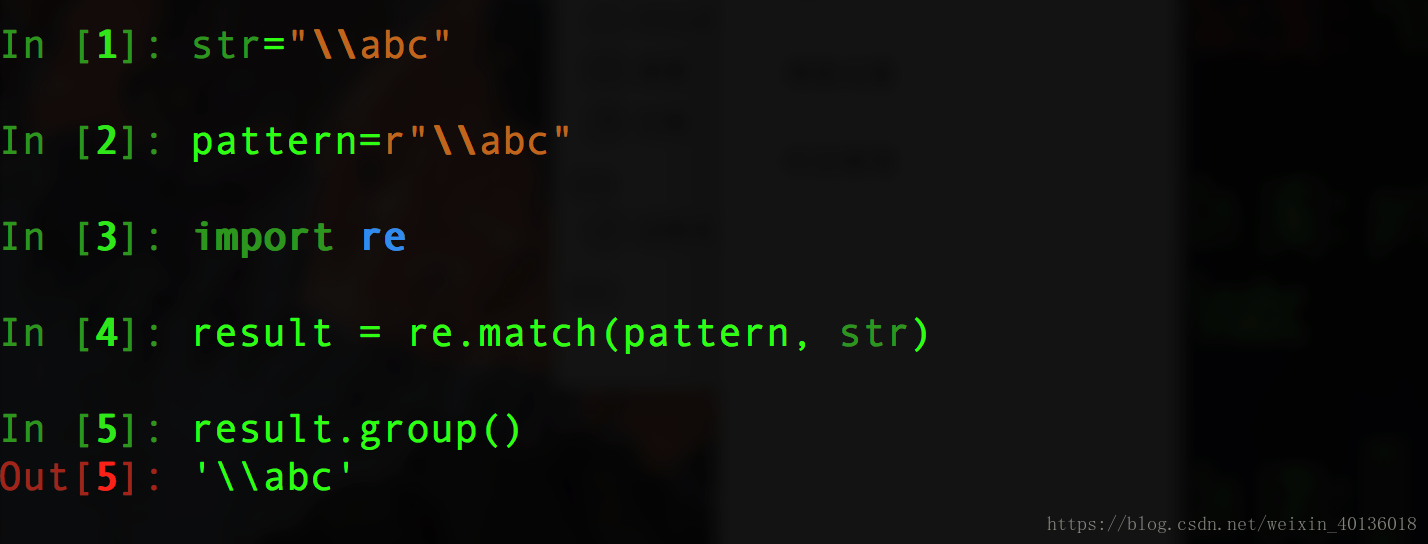
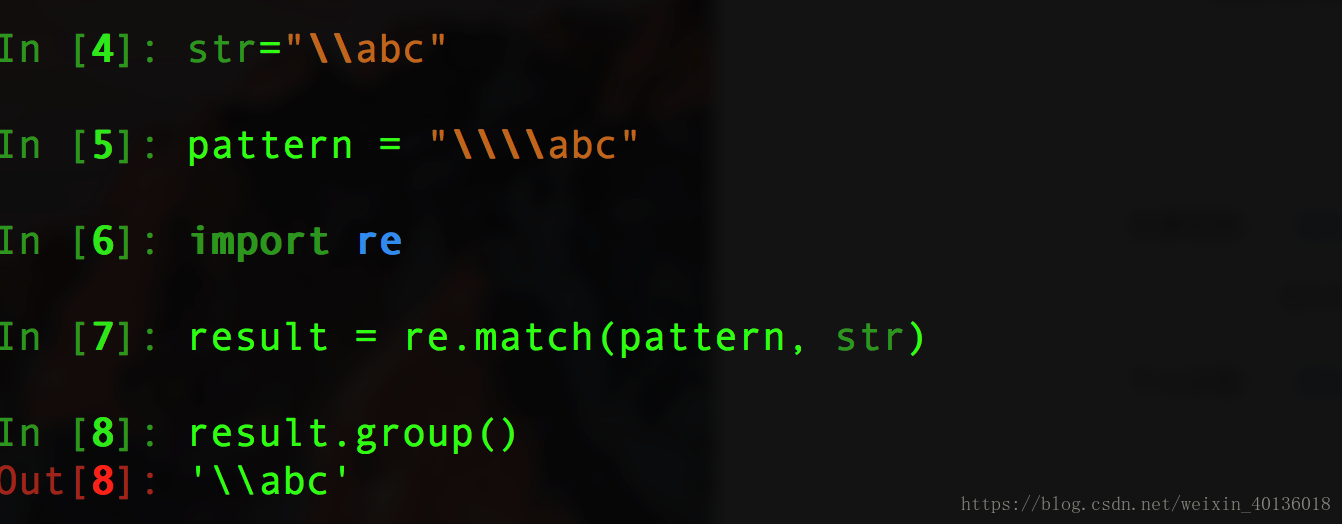
假若没有原始自付出r,则我们就要进行如下的操作: 给pattern加上双倍的"\"以避免转义字符中减少"\".会比较麻烦
当我们使用r原始字符串时,就不必考虑字符串的转移问题,更易集中解决字符匹配问题.
5. 表示边界
字符 功能
^ 匹配字符串开头
$ 匹配字符串结尾
\b 匹配一个单词的边界
\B 匹配非单词边界
例三: 边界(制定规则来匹配str="ho ve r")
import re
#定义规则匹配str="ho ve r"
#1. 以字母开始
#2. 中间有空字符
#3. ve两边分别限定匹配单词边界
pattern = r"^\w+\s\bve\b\sr"
str = "ho ve r"
result = re.match(pattern, str)
result.group()
6. 匹配分组
字符 功能
| 匹配左右任意一个表达式
(ab) 将括号中字符作为一个分组
\num 引用分组num匹配到的字符串
(?P<name>) 分组起别名
(?P=name) 引用别名为name分组匹配到的字符串
例四: 匹配出0-100之间的数字
import re
#匹配出0-100之间的数字
#首先:正则是从左往又开始匹配
#经过分析: 可以将0-100分为三部分
#1. 0 "0$"
#2. 100 "100$"
#3. 1-99 "[1-9]\d{0,1}$"
#所以整合如下
pattern = r"0$|100$|[1-9]\d{0,1}$"
#测试数据为0,3,27,100,123
result = re.match(pattern, "27")
result.group()
#将0考虑到1-99上,上述pattern还可以简写为:pattern=r"100$|[1-9]?\d{0,1}$"
#测试结果如下图: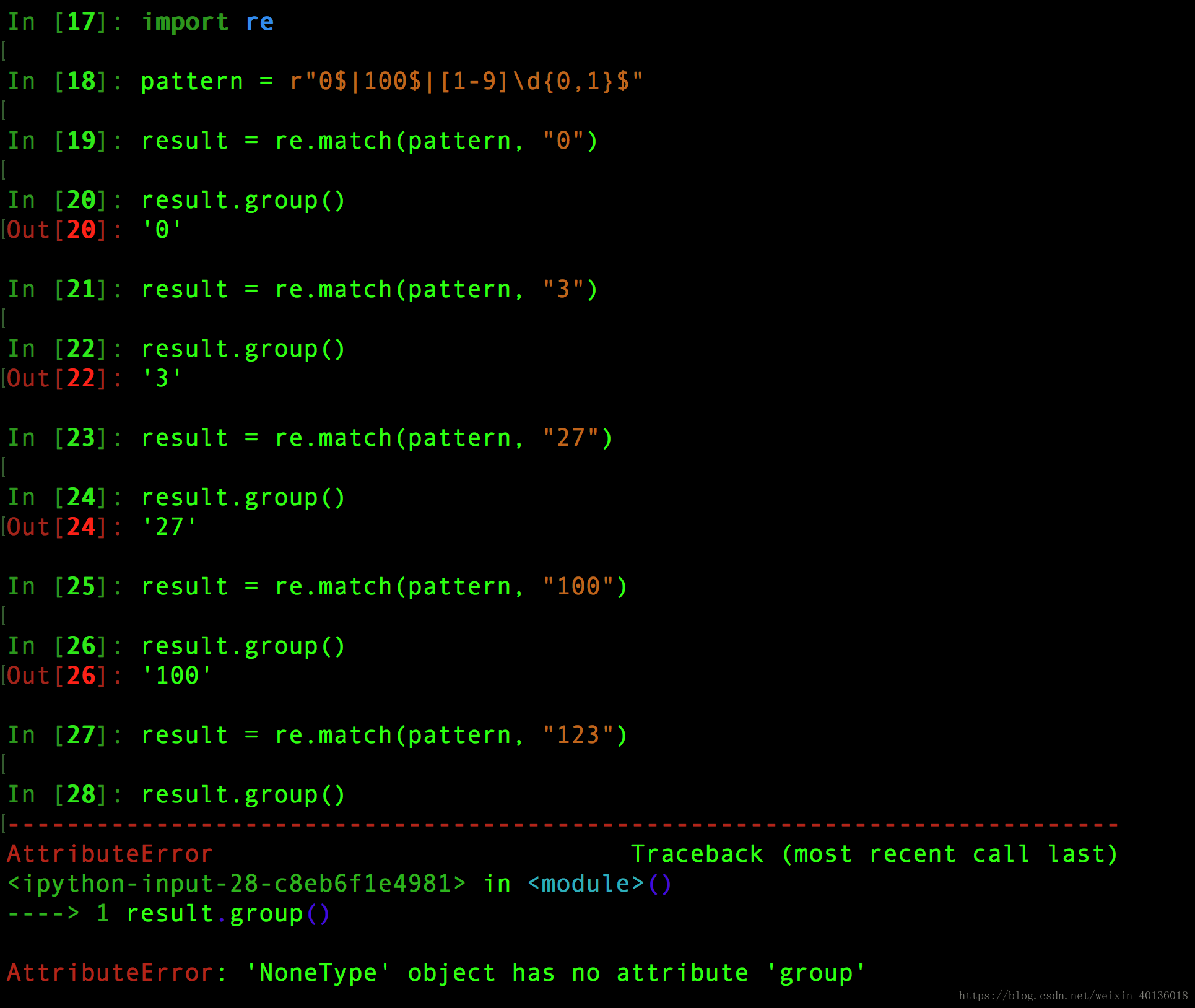
例五: 匹配分组,获取页面中的<h1>标签中的内容
import re
#匹配分组,获取页面<h1>标签中的内容, 爬虫的时候会用到
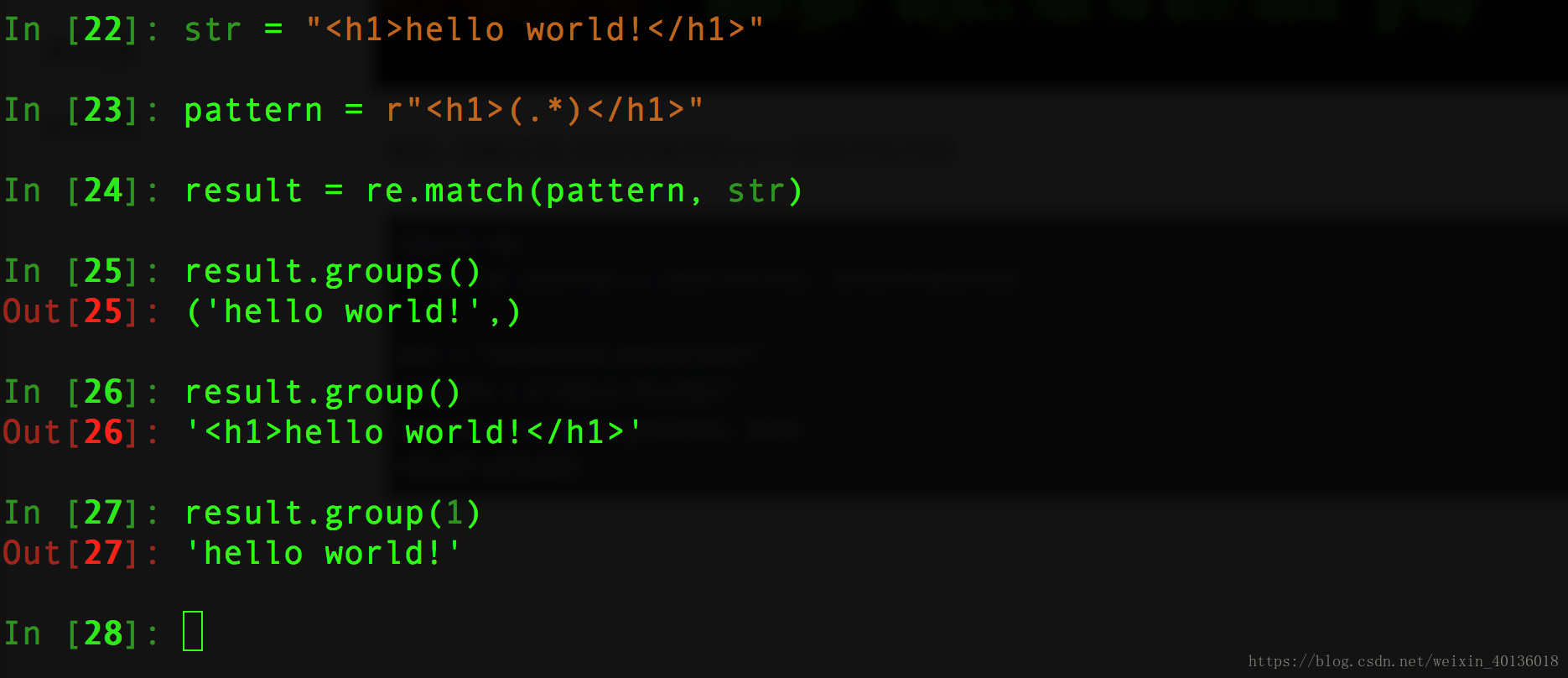
str = "<h1>hello world!<h1>"
pattern = r"<h1>(.*)</h1>"
result = re.match(pattern, str)
result.group()
#执行如下图
例六: 分组引用, 精确获取多个标签内的内容
import re
#引用分组,精确获取多个标签内的内容
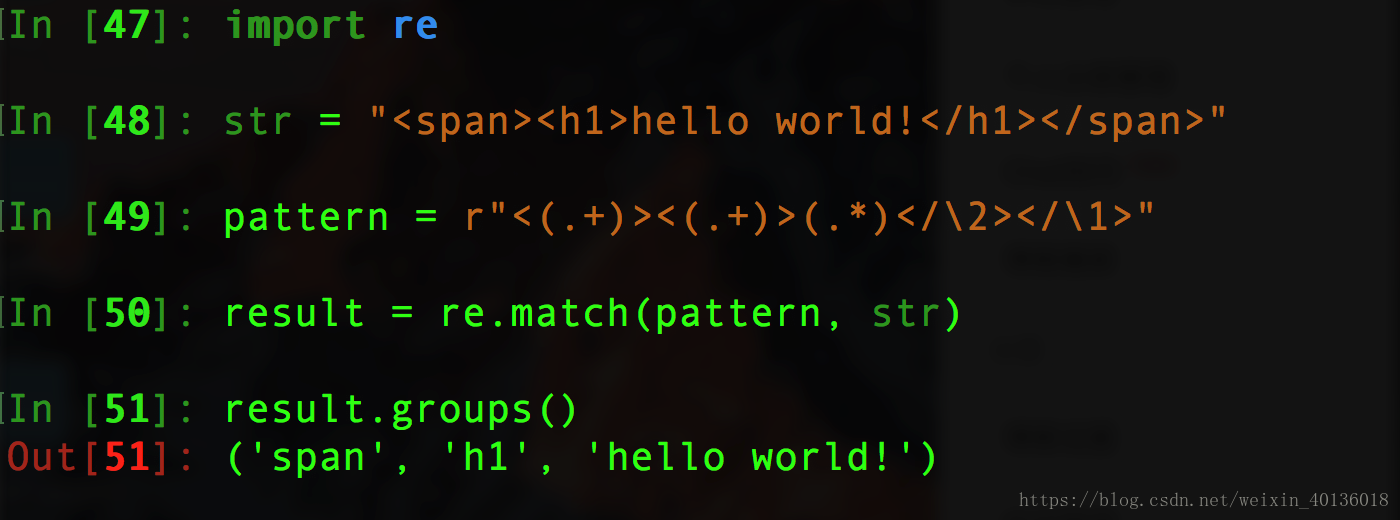
#"\1"是对第一个分组的引用,同理......
str = "<span><h1>hello world!</h1></span>"
pattern = r"<(.+)><(.+)>.*</\2></\1>"
result = re.match(pattern, str)
result.groups()
#执行如下图:
例六-2:分组起别名
import re
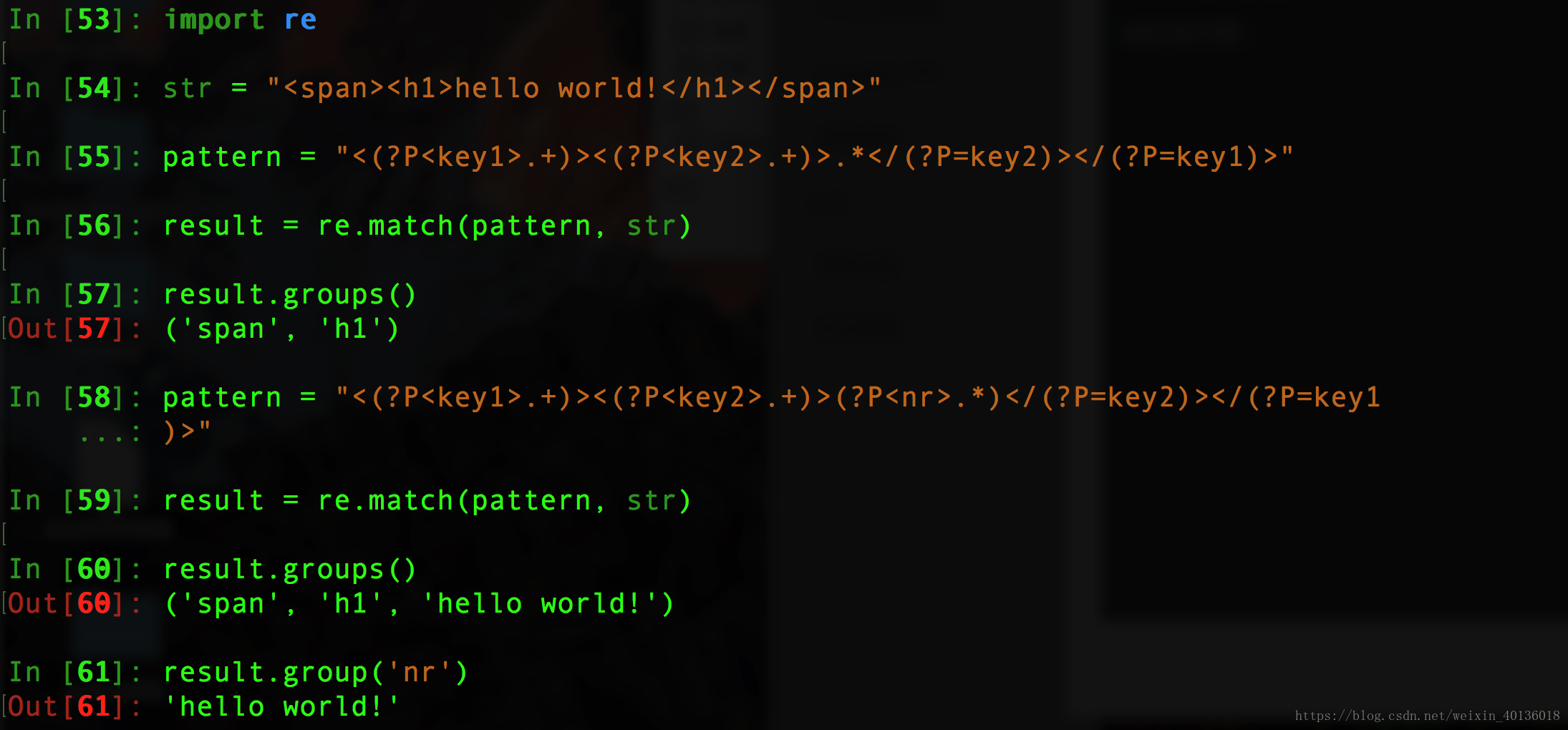
#分组起别名
str = "<span><h1>hello world!</h1></span>"
pattern = "<(?P<key1>.+)><(?P<key2>.+)>(?P<nr>.*)</(?P=key2)></(?P=key1)>"
result = re.match(pattern, str)
result.groups()
#执行如下图:
python3中的RE(正则表达式)的更多相关文章
- 正则表达式:Python3中的应用简介
正则表达式:Python3中的应用简介 一.正则表达式 1,概述 正则表达式,又称规则表达式.(英语:Regular Expression,在代码中常简写为regex.regexp或RE),计算机科学 ...
- Python3中Urllib库基本使用
什么是Urllib? Python内置的HTTP请求库 urllib.request 请求模块 urllib.error 异常处理模块 urllib.par ...
- Python3中正则模块re.compile、re.match及re.search函数用法详解
Python3中正则模块re.compile.re.match及re.search函数用法 re模块 re.compile.re.match. re.search 正则匹配的时候,第一个字符是 r,表 ...
- Python中re操作正则表达式
在python中使用正则表达式 1.转义符 正则表达式中的转义: '\('表示匹配小括号 [()+*/?&.] 在字符组中一些特殊的字符会现出原形 所有的\s\d\w\S\D\W\n\t都表示 ...
- Python3中的字符串函数学习总结
这篇文章主要介绍了Python3中的字符串函数学习总结,本文讲解了格式化类方法.查找 & 替换类方法.拆分 & 组合类方法等内容,需要的朋友可以参考下. Sequence Types ...
- Python3中使用PyMySQL连接Mysql
Python3中使用PyMySQL连接Mysql 在Python2中连接Mysql数据库用的是MySQLdb,在Python3中连接Mysql数据库用的是PyMySQL,因为MySQLdb不支持Pyt ...
- ORACLE中的支持正则表达式的函数
ORACLE中的支持正则表达式的函数主要有下面四个:1,REGEXP_LIKE :与LIKE的功能相似2,REGEXP_INSTR :与INSTR的功能相似3,REGEXP_SUBSTR :与SUBS ...
- python3 中mlpy模块安装 出现 failed with error code 1的决绝办法(其他模块也可用本方法)
在python3 中安装其它模块时经常出现 failed with error code 1等状况,使的安装无法进行.而解决这个问题又非常麻烦. 接下来以mlpy为例,介绍一种解决此类安装问题的办法. ...
- python3中返回字典的键
我在看<父与子的编程之旅>的时候,有段代码是随机画100个矩形,矩形的大小,线条的粗细,颜色都是随机的,代码如下, import pygame,sys,random from pygame ...
随机推荐
- [vue/no-parsing-error] Parsing error: x-invalid-end-tag.eslint-plugin-vue
[vue/no-parsing-error] Parsing error: x-invalid-end-tag.eslint-plugin-vue 解决方案:vscode里面选择设置->搜索 ...
- Windows 服务安装与卸载 (通过 Sc.exe)
1. 安装 新建文本文件,重命名为 ServiceInstall.bat,将 ServiceInstall.bat 的内容替换为: sc create "Verity Platform De ...
- context:component-scan 和 mvc:annotation-driven
前言 Spring MVC 框架提供了几种不同的配置元素来帮助和指示 Spring 容器管理以及注入 bean . 常用的几个 XML 配置是 context:component-scan mvc:a ...
- 【证明与推广与背诵】Matrix Tree定理和一些推广
[背诵手记]Matrix Tree定理和一些推广 结论 对于一个无向图\(G=(V,E)\),暂时钦定他是简单图,定义以下矩阵: (入)度数矩阵\(D\),其中\(D_{ii}=deg_i\).其他= ...
- ng-zorro-antd中踩过的坑
ng-zorro-antd中踩过的坑 前端项目中,我们经常会使用阿里开源的组件库:ant-design,其提供的组件已经足以满足多数的需求,拿来就能直接用,十分方便,当然了,有些公司会对组件库进行二次 ...
- Lyft Level 5 Challenge 2018 - Final Round (Open Div. 2) (前三题题解)
这场比赛好毒瘤哇,看第四题好像是中国人出的,怕不是dllxl出的. 第四道什么鬼,互动题不说,花了四十五分钟看懂题目,都想砸电脑了.然后发现不会,互动题从来没做过. 不过这次新号上蓝名了(我才不告诉你 ...
- 设置本地上网IP
在局域网中,我们经常需要根据网络连接环境来对本地连接的IP地址进行手动设置,那么如何对IP地址进行设置呢?下面小编就把教程介绍给大家. 1. 右击桌面“网上邻居”->选择“属性”,打开“网络共享 ...
- 10.Python中print函数中中逗号和加号的区别
先看看print中逗号和加号分别打印出来的效果.. 这里以Python3为例 1 print("hello" + "world") helloworld 1 p ...
- 【转】Java Web Services面试问题集锦
Q. 应用集成方式有哪些? A. 应用可以采用以下方式集成: 1. 共享数据库 2. 批量文件传输 3. 远程过程调用(RPC) 4. 通过消息中间件来交换异步信息(MOM) Q. 应用集成可以采用的 ...
- 简单工厂模式(C++)
#include <iostream> using namespace std; class Fruit { public : ; }; class Banana :public Frui ...