【Spark 内核】 Spark 内核解析-上
Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制、Spark任务调度机制、Spark内存管理机制、Spark核心功能的运行原理等,熟练掌握Spark内核原理,能够帮助我们更好地完成Spark代码设计,并能够帮助我们准确锁定项目运行过程中出现的问题的症结所在。
Spark 内核概述
Spark 核心组件回顾
Driver
Spark驱动器节点,用于执行Spark任务中的main方法,负责实际代码的执行工作。Driver在Spark作业执行时主要负责:
- 将用户程序转化为作业(job);
- 在Executor之间调度任务(task);
- 跟踪Executor的执行情况;
- 通过UI展示查询运行情况;
Executor
Spark Executor节点是一个JVM进程,负责在 Spark 作业中运行具体任务,任务彼此之间相互独立。Spark 应用启动时,Executor节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。
Executor有两个核心功能:
- 负责运行组成Spark应用的任务,并将结果返回给驱动器进程;
- 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
Spark 通用运行流程概述
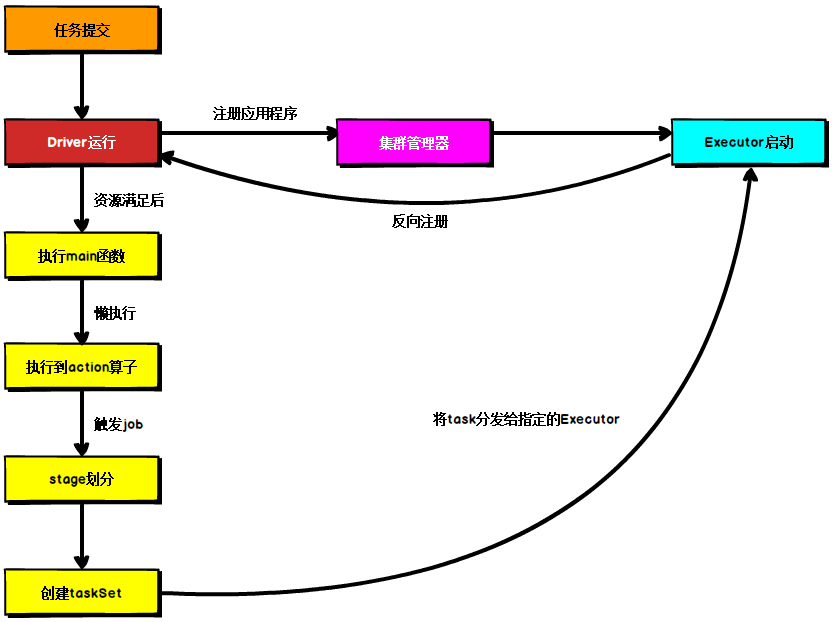
图为Spark通用运行流程,不论Spark以何种模式进行部署,任务提交后,都会先启动Driver进程,随后Driver进程向集群管理器注册应用程序,之后集群管理器根据此任务的配置文件分配Executor并启动,当Driver所需的资源全部满足后,Driver开始执行main函数,Spark查询为懒执行,当执行到action算子时开始反向推算,根据宽依赖进行stage的划分,随后每一个stage对应一个taskset,taskset中有多个task,根据本地化原则,task会被分发到指定的Executor去执行,在任务执行的过程中,Executor也会不断与Driver进行通信,报告任务运行情况。
Spark 部署模式
Spark支持3种集群管理器(Cluster Manager),分别为:
- Standalone:独立模式,Spark原生的简单集群管理器,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统,使用Standalone可以很方便地搭建一个集群;
- Apache Mesos:一个强大的分布式资源管理框架,它允许多种不同的框架部署在其上,包括yarn;
- Hadoop YARN:统一的资源管理机制,在上面可以运行多套计算框架,如map reduce、storm等,根据driver在集群中的位置不同,分为yarn client和yarn cluster。
实际上,除了上述这些通用的集群管理器外,Spark内部也提供了一些方便用户测试和学习的简单集群部署模式。由于在实际工厂环境下使用的绝大多数的集群管理器是Hadoop YARN,因此我们关注的重点是Hadoop YARN模式下的Spark集群部署。
Spark的运行模式取决于传递给SparkContext的MASTER环境变量的值,个别模式还需要辅助的程序接口来配合使用,目前支持的Master字符串及URL包括:
| Master URL | Meaning |
|---|---|
| local | 在本地运行,只有一个工作进程,无并行计算能力。 |
| local[K] | 在本地运行,有K个工作进程,通常设置K为机器的CPU核心数量。 |
| local[*] | 在本地运行,工作进程数量等于机器的CPU核心数量。 |
| spark://HOST:PORT | 以Standalone模式运行,这是Spark自身提供的集群运行模式,默认端口号: 7077。详细文档见:Spark standalone cluster。 |
| mesos://HOST:PORT | 在Mesos集群上运行,Driver进程和Worker进程运行在Mesos集群上,部署模式必须使用固定值:--deploy-mode cluster。详细文档见:MesosClusterDispatcher. |
| yarn-client | 在Yarn集群上运行,Driver进程在本地,Executor进程在Yarn集群上,部署模式必须使用固定值:--deploy-mode client。Yarn集群地址必须在HADOOP_CONF_DIR or YARN_CONF_DIR变量里定义。 |
| yarn-cluster | 在Yarn集群上运行,Driver进程在Yarn集群上,Work进程也在Yarn集群上,部署模式必须使用固定值:--deploy-mode cluster。Yarn集群地址必须在HADOOP_CONF_DIR or YARN_CONF_DIR变量里定义。 |
用户在提交任务给Spark处理时,以下两个参数共同决定了Spark的运行方式。
· –master MASTER_URL :决定了Spark任务提交给哪种集群处理。
· –deploy-mode DEPLOY_MODE:决定了Driver的运行方式,可选值为Client或者Cluster。
Standalone 模式运行机制
Standalone集群有四个重要组成部分,分别是:
1) Driver:是一个进程,我们编写的Spark应用程序就运行在Driver上,由Driver进程执行;
2) Master(RM):是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责;
3) Worker(NM):是一个进程,一个Worker运行在集群中的一台服务器上,主要负责两个职责,一个是用自己的内存存储RDD的某个或某些partition;另一个是启动其他进程和线程(Executor),对RDD上的partition进行并行的处理和计算。
4) Executor:是一个进程,一个Worker上可以运行多个Executor,Executor通过启动多个线程(task)来执行对RDD的partition进行并行计算,也就是执行我们对RDD定义的例如map、flatMap、reduce等算子操作。
Standalone Client 模式
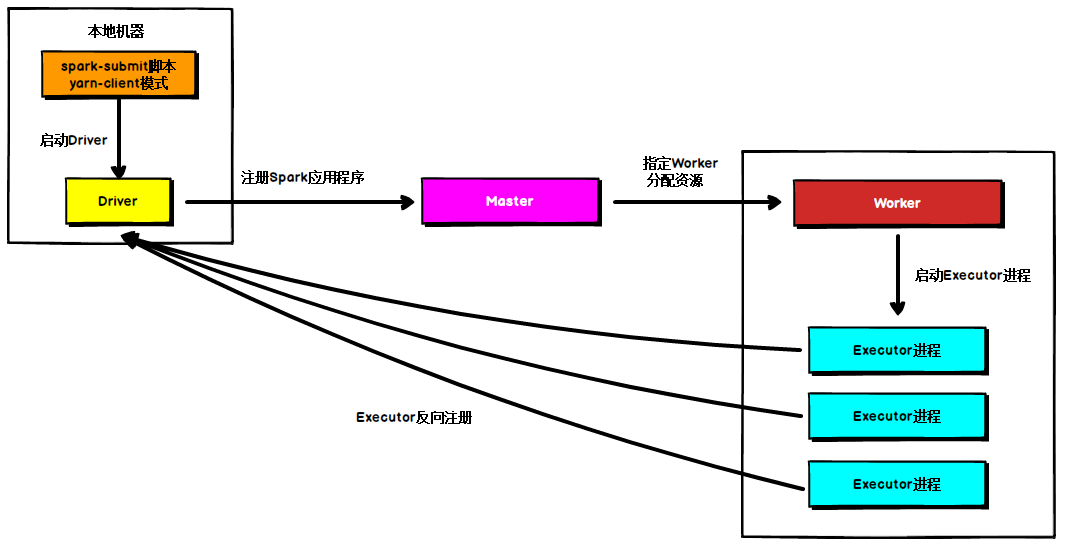
在Standalone Client模式下,Driver在任务提交的本地机器上运行,Driver启动后向Master注册应用程序,Master根据submit脚本的资源需求找到内部资源至少可以启动一个Executor的所有Worker,然后在这些Worker之间分配Executor,Worker上的Executor启动后会向Driver反向注册,所有的Executor注册完成后,Driver开始执行main函数,之后执行到Action算子时,开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
Standalone Cluster模式
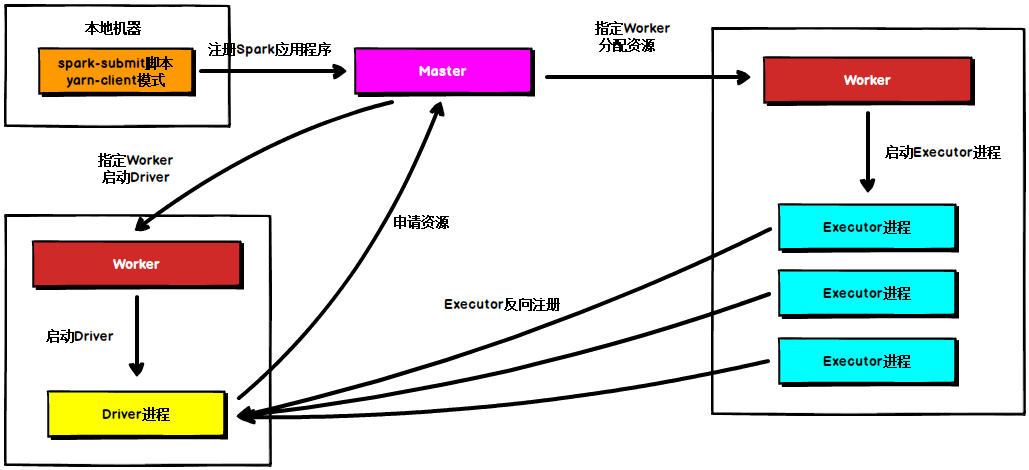
在Standalone Cluster模式下,任务提交后,Master会找到一个Worker启动Driver进程, Driver启动后向Master注册应用程序,Master根据submit脚本的资源需求找到内部资源至少可以启动一个Executor的所有Worker,然后在这些Worker之间分配Executor,Worker上的Executor启动后会向Driver反向注册,所有的Executor注册完成后,Driver开始执行main函数,之后执行到Action算子时,开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
注意
Standalone的两种模式下(client/Cluster),Master在接到Driver注册Spark应用程序的请求后,会获取其所管理的剩余资源能够启动一个Executor的所有Worker,然后在这些Worker之间分发Executor,此时的分发只考虑Worker上的资源是否足够使用,直到当前应用程序所需的所有Executor都分配完毕,Executor反向注册完毕后,Driver开始执行main程序。
Yarn 模式运行机制
Yarn Client 模式
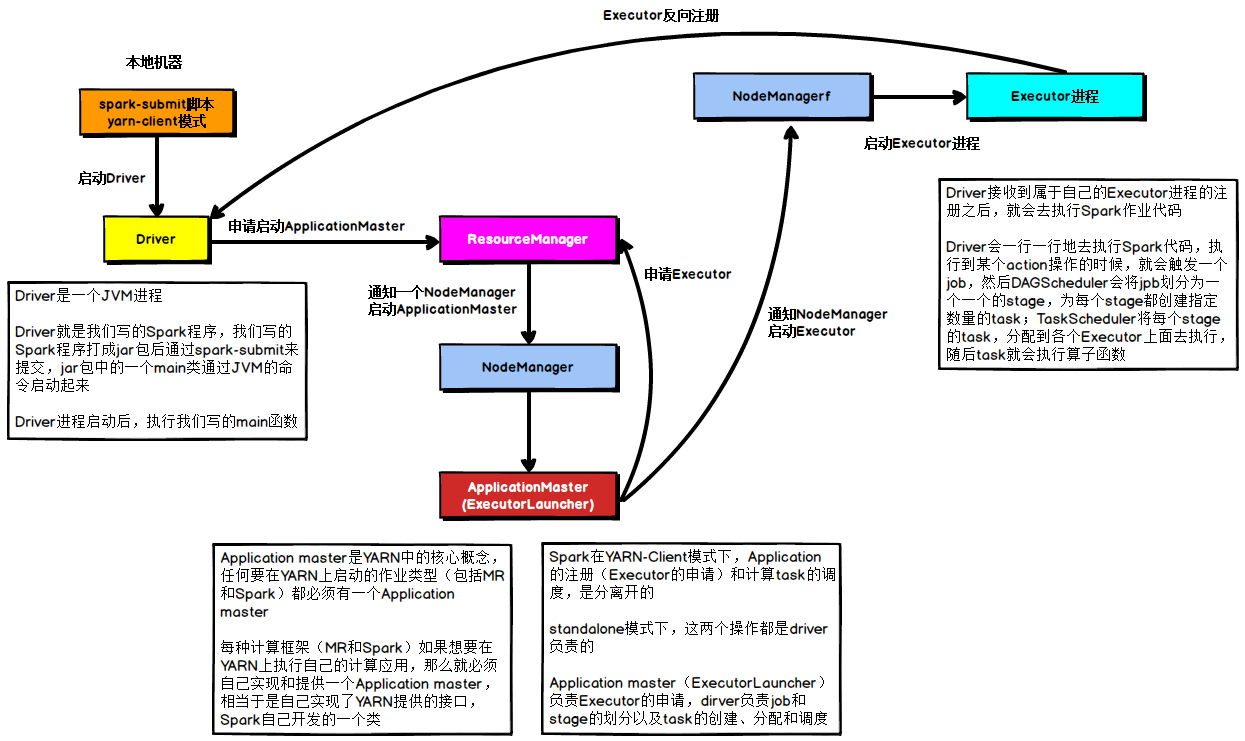
在YARN Client模式下,Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存。
ResourceManager接到ApplicationMaster的资源申请后会分配container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程,Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
Yarn Cluster 模式
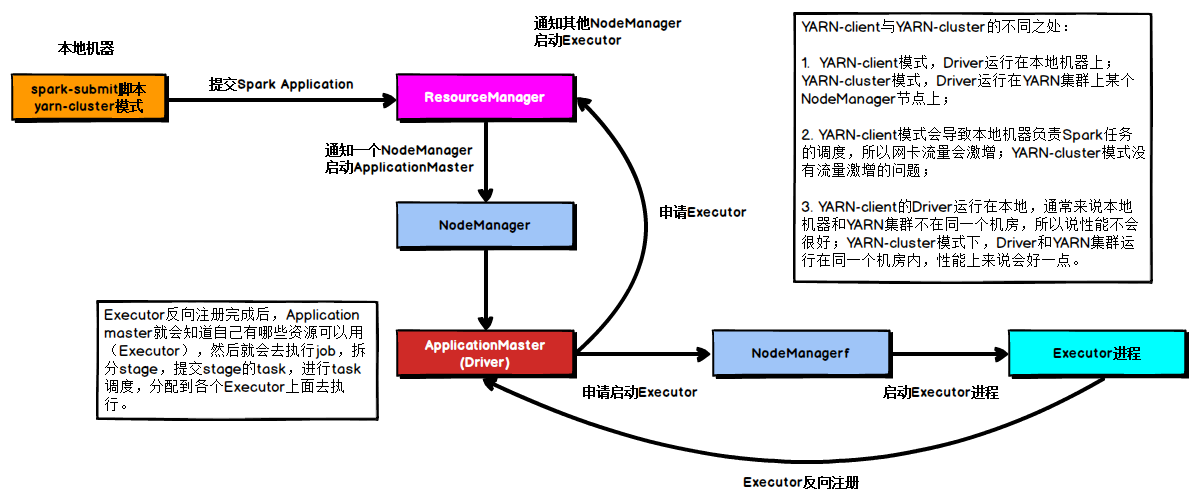
在YARN Cluster模式下,任务提交后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver。
Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请后会分配container,然后在合适的NodeManager上启动Executor进程,Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
Spark 通讯架构
Spark 通信架构概述
Spark2.x版本使用Netty通讯框架作为内部通讯组件。spark 基于netty新的rpc框架借鉴了Akka的中的设计,它是基于Actor模型,如下图所示:
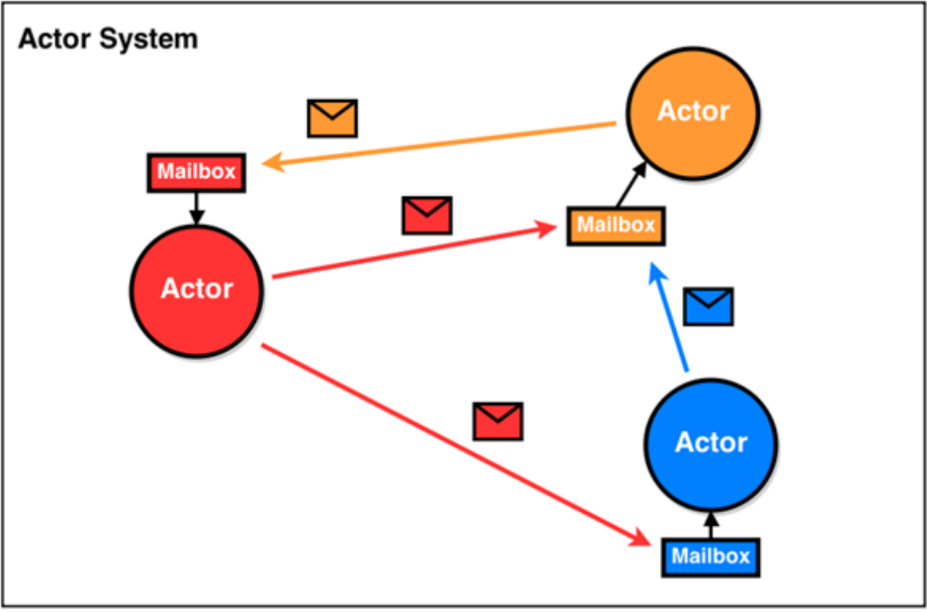
Spark通讯框架中各个组件(Client/Master/Worker)可以认为是一个个独立的实体,各个实体之间通过消息来进行通信。具体各个组件之间的关系图如下:
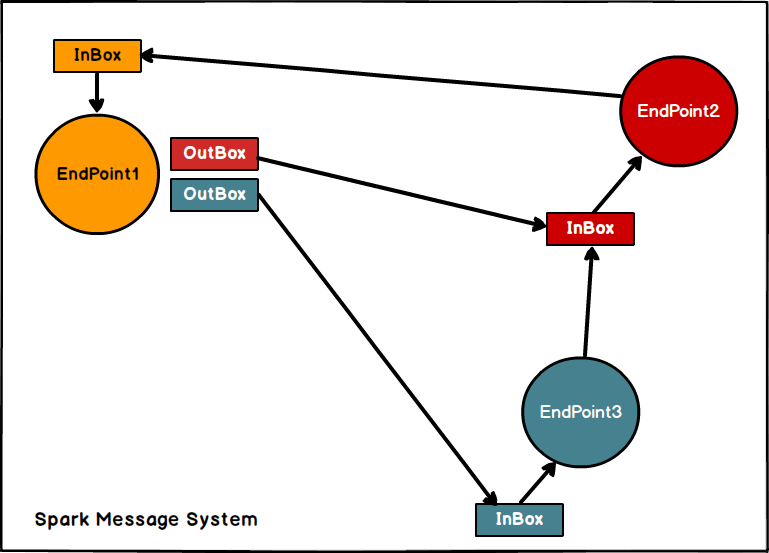
Endpoint(Client/Master/Worker)有1个InBox和N个OutBox(N>=1,N取决于当前Endpoint与多少其他的Endpoint进行通信,一个与其通讯的其他Endpoint对应一个OutBox),Endpoint接收到的消息被写入InBox,发送出去的消息写入OutBox并被发送到其他Endpoint的InBox中。
Spark 通讯架构解析
Spark通信架构如下图所示:
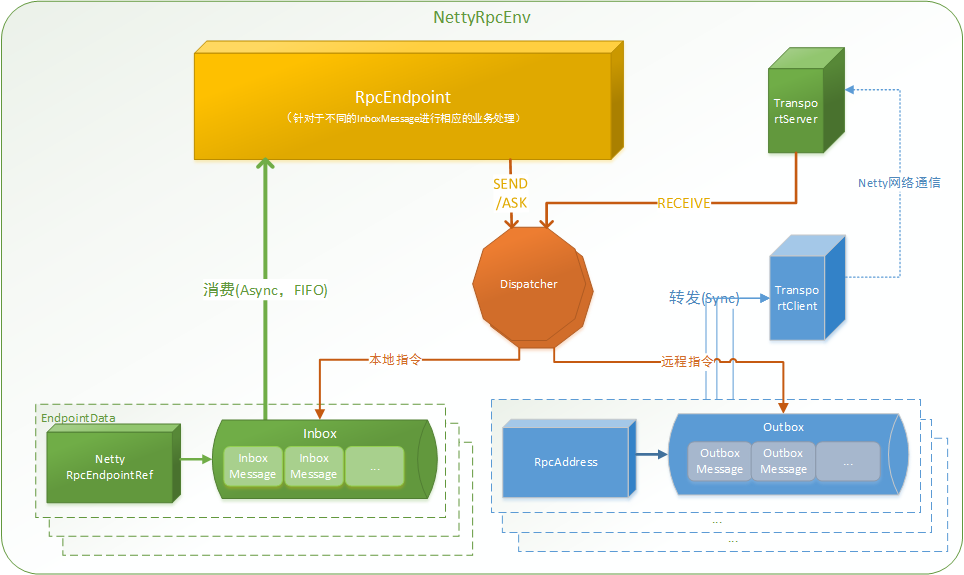
1) RpcEndpoint:RPC端点,Spark针对每个节点(Client/Master/Worker)都称之为一个Rpc端点,且都实现RpcEndpoint接口,内部根据不同端点的需求,设计不同的消息和不同的业务处理,如果需要发送(询问)则调用Dispatcher;
2) RpcEnv:RPC上下文环境,每个RPC端点运行时依赖的上下文环境称为RpcEnv;
3) Dispatcher:消息分发器,针对于RPC端点需要发送消息或者从远程RPC接收到的消息,分发至对应的指令收件箱/发件箱。如果指令接收方是自己则存入收件箱,如果指令接收方不是自己,则放入发件箱;
4) Inbox:指令消息收件箱,一个本地RpcEndpoint对应一个收件箱,Dispatcher在每次向Inbox存入消息时,都将对应EndpointData加入内部ReceiverQueue中,另外Dispatcher创建时会启动一个单独线程进行轮询ReceiverQueue,进行收件箱消息消费;
5) RpcEndpointRef:RpcEndpointRef是对远程RpcEndpoint的一个引用。当我们需要向一个具体的RpcEndpoint发送消息时,一般我们需要获取到该RpcEndpoint的引用,然后通过该应用发送消息。
6) OutBox:指令消息发件箱,对于当前RpcEndpoint来说,一个目标RpcEndpoint对应一个发件箱,如果向多个目标RpcEndpoint发送信息,则有多个OutBox。当消息放入Outbox后,紧接着通过TransportClient将消息发送出去。消息放入发件箱以及发送过程是在同一个线程中进行;
7) RpcAddress:表示远程的RpcEndpointRef的地址,Host + Port。
8) TransportClient:Netty通信客户端,一个OutBox对应一个TransportClient,TransportClient不断轮询OutBox,根据OutBox消息的receiver信息,请求对应的远程TransportServer;
9) TransportServer:Netty通信服务端,一个RpcEndpoint对应一个TransportServer,接受远程消息后调用Dispatcher分发消息至对应收发件箱;
根据上面的分析,Spark通信架构的高层视图如下图所示:

Spark 任务调度机制
在工厂环境下,Spark集群的部署方式一般为YARN-Cluster模式,之后的内核分析内容中我们默认集群的部署方式为YARN-Cluster模式。
Spark 任务提交流程
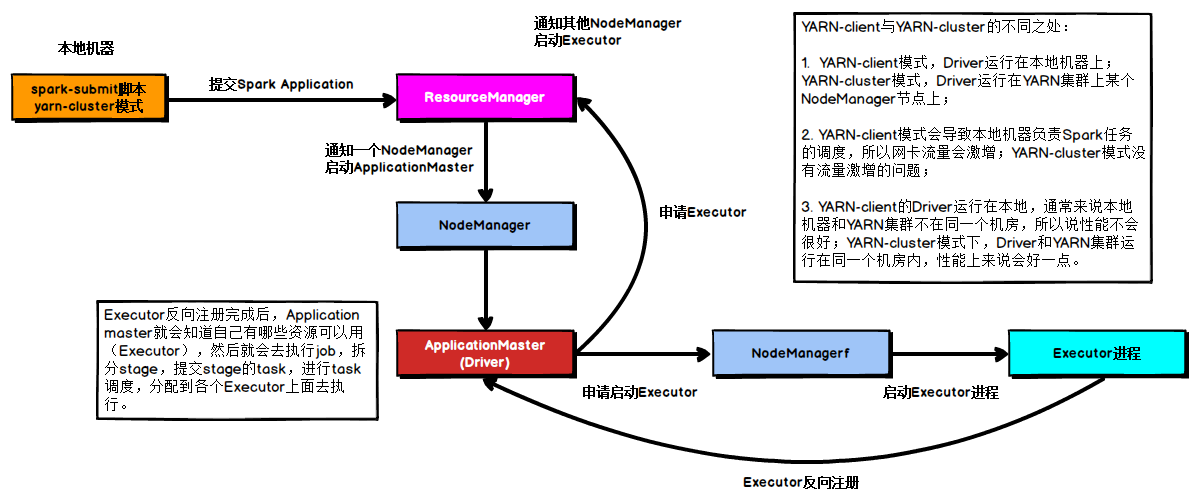
下面的时序图清晰地说明了一个Spark应用程序从提交到运行的完整流程:
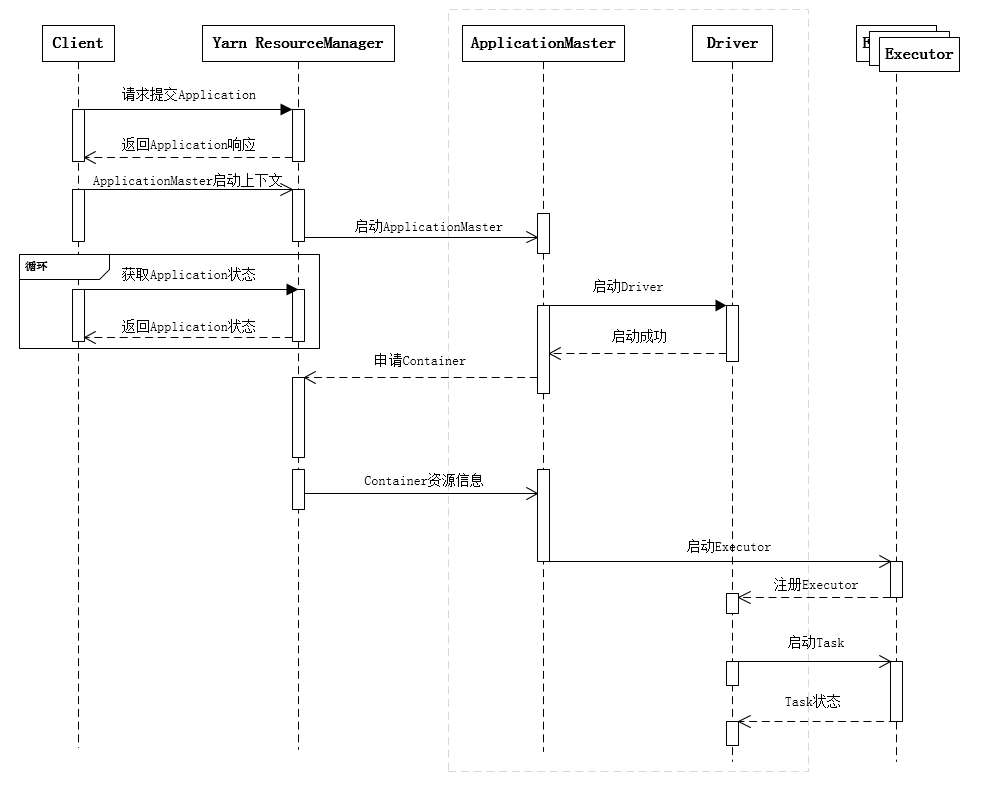
提交一个Spark应用程序,首先通过Client向ResourceManager请求启动一个Application,同时检查是否有足够的资源满足Application的需求,如果资源条件满足,则准备ApplicationMaster的启动上下文,交给ResourceManager,并循环监控Application状态。
当提交的资源队列中有资源时,ResourceManager会在某个NodeManager上启动ApplicationMaster进程,ApplicationMaster会单独启动Driver后台线程,当Driver启动后,ApplicationMaster会通过本地的RPC连接Driver,并开始向ResourceManager申请Container资源运行Executor进程(一个Executor对应与一个Container),当ResourceManager返回Container资源,ApplicationMaster则在对应的Container上启动Executor。
Driver线程主要是初始化SparkContext对象,准备运行所需的上下文,然后一方面保持与ApplicationMaster的RPC连接,通过ApplicationMaster申请资源,另一方面根据用户业务逻辑开始调度任务,将任务下发到已有的空闲Executor上。
当ResourceManager向ApplicationMaster返回Container资源时,ApplicationMaster就尝试在对应的Container上启动Executor进程,Executor进程起来后,会向Driver反向注册,注册成功后保持与Driver的心跳,同时等待Driver分发任务,当分发的任务执行完毕后,将任务状态上报给Driver。
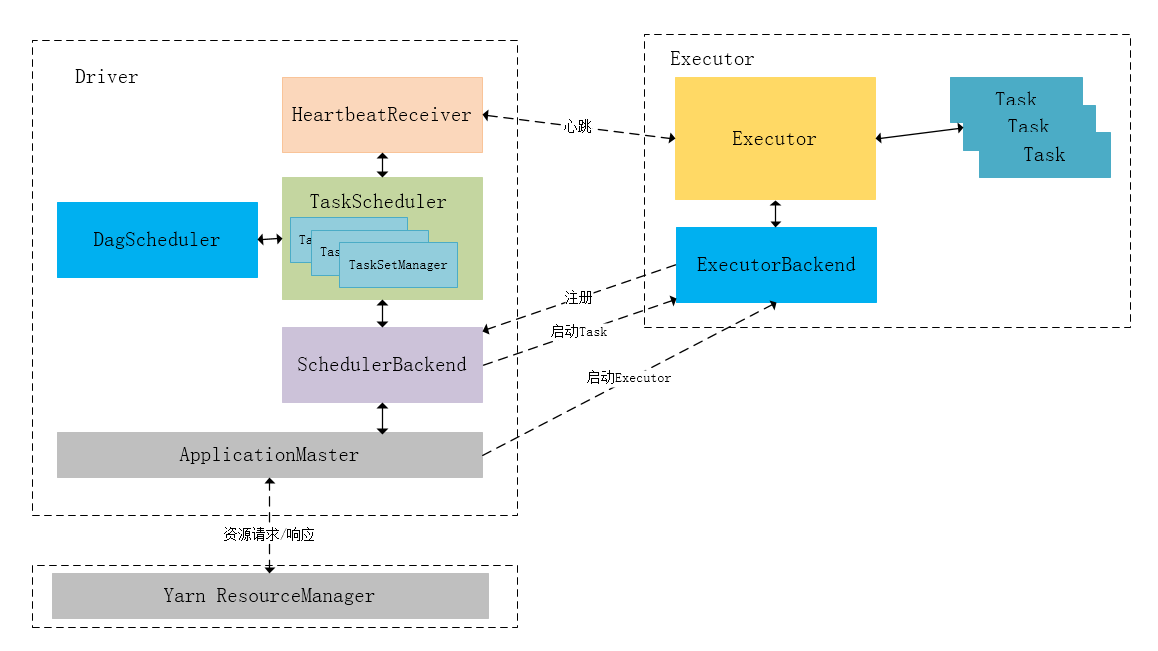
从上述时序图可知,Client只负责提交Application并监控Application的状态。对于Spark的任务调度主要是集中在两个方面: 资源申请和任务分发,其主要是通过ApplicationMaster、Driver以及Executor之间来完成。
Spark 任务调度概述
当Driver起来后,Driver则会根据用户程序逻辑准备任务,并根据Executor资源情况逐步分发任务。在详细阐述任务调度前,首先说明下Spark里的几个概念。一个Spark应用程序包括Job、Stage以及Task三个概念:
Job是以Action方法为界,遇到一个Action方法则触发一个Job;
Stage是Job的子集,以RDD宽依赖(即Shuffle)为界,遇到Shuffle做一次划分;
Task是Stage的子集,以并行度(分区数)来衡量,分区数是多少,则有多少个task。
Spark的任务调度总体来说分两路进行,一路是Stage级的调度,一路是Task级的调度,总体调度流程如下图所示:
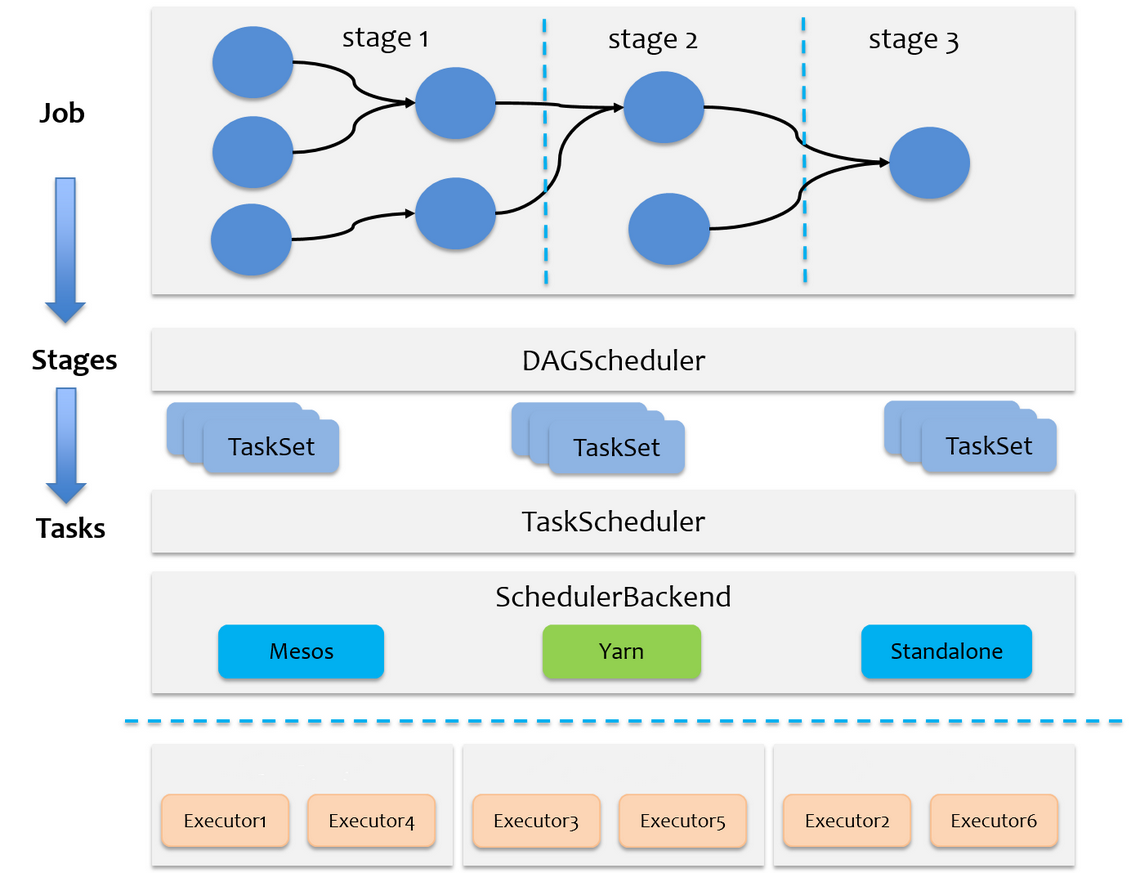
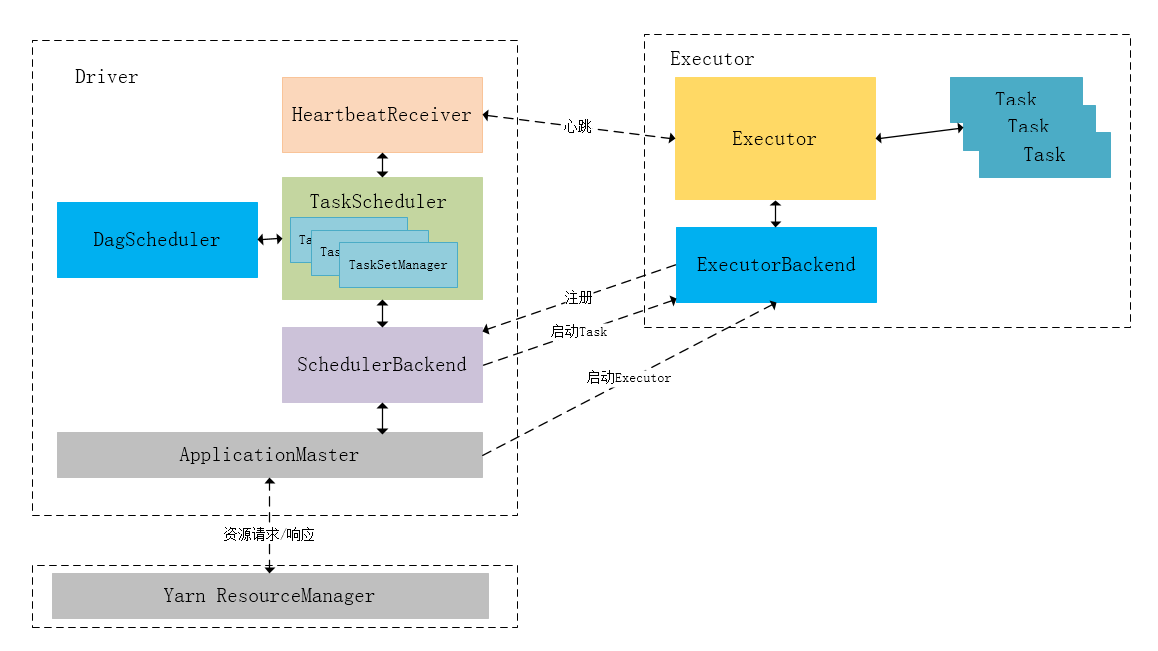
Spark RDD通过其Transactions操作,形成了RDD血缘关系图,即DAG,最后通过Action的调用,触发Job并调度执行。DAGScheduler负责Stage级的调度,主要是将job切分成若干Stages,并将每个Stage打包成TaskSet交给TaskScheduler调度。TaskScheduler负责Task级的调度,将DAGScheduler给过来的TaskSet按照指定的调度策略分发到Executor上执行,调度过程中SchedulerBackend负责提供可用资源,其中SchedulerBackend有多种实现,分别对接不同的资源管理系统。有了上述感性的认识后,下面这张图描述了Spark-On-Yarn模式下在任务调度期间,ApplicationMaster、Driver以及Executor内部模块的交互过程:
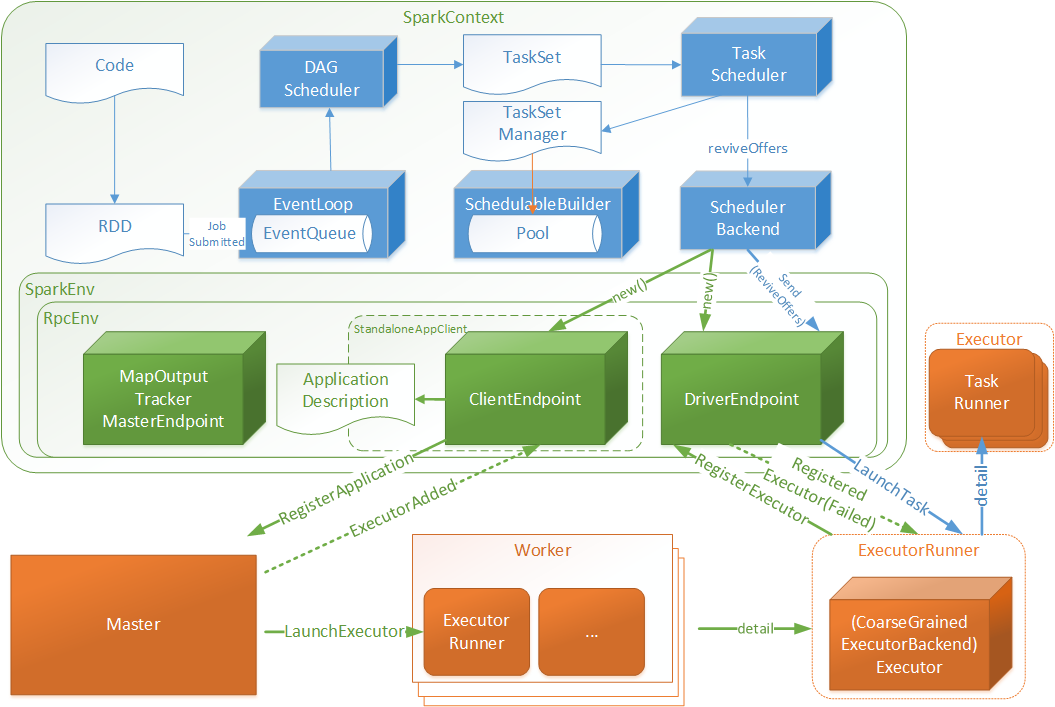
Driver初始化SparkContext过程中,会分别初始化DAGScheduler、TaskScheduler、SchedulerBackend以及HeartbeatReceiver,并启动SchedulerBackend以及HeartbeatReceiver。SchedulerBackend通过ApplicationMaster申请资源,并不断从TaskScheduler中拿到合适的Task分发到Executor执行。HeartbeatReceiver负责接收Executor的心跳信息,监控Executor的存活状况,并通知到TaskScheduler。
Spark Stage级调度
Spark的任务调度是从DAG切割开始,主要是由DAGScheduler来完成。当遇到一个Action操作后就会触发一个Job的计算,并交给DAGScheduler来提交,下图是涉及到Job提交的相关方法调用流程图。
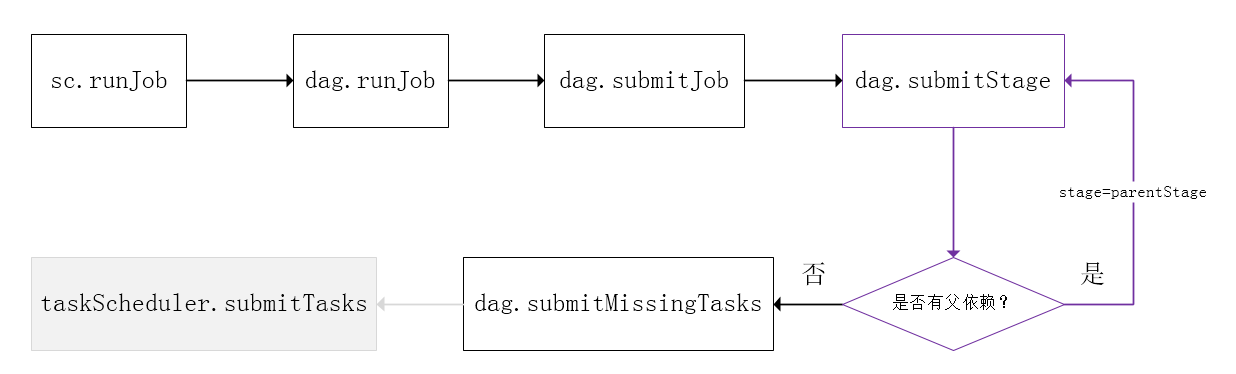
Job由最终的RDD和Action方法封装而成,SparkContext将Job交给DAGScheduler提交,它会根据RDD的血缘关系构成的DAG进行切分,将一个Job划分为若干Stages,具体划分策略是,由最终的RDD不断通过依赖回溯判断父依赖是否是宽依赖,即以Shuffle为界,划分Stage,窄依赖的RDD之间被划分到同一个Stage中,可以进行pipeline式的计算,如上图紫色流程部分。划分的Stages分两类,一类叫做ResultStage,为DAG最下游的Stage,由Action方法决定,另一类叫做ShuffleMapStage,为下游Stage准备数据,下面看一个简单的例子WordCount。
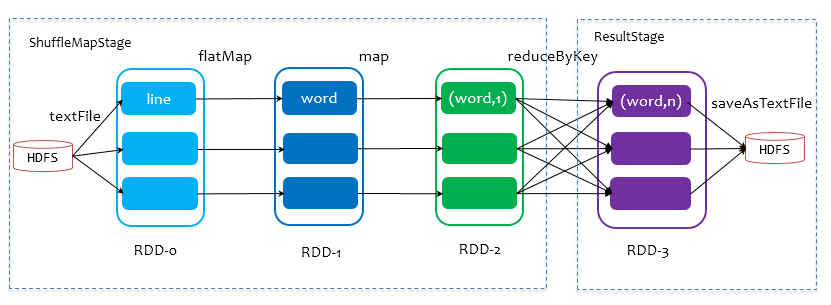
Job由saveAsTextFile触发,该Job由RDD-3和saveAsTextFile方法组成,根据RDD之间的依赖关系从RDD-3开始回溯搜索,直到没有依赖的RDD-0,在回溯搜索过程中,RDD-3依赖RDD-2,并且是宽依赖,所以在RDD-2和RDD-3之间划分Stage,RDD-3被划到最后一个Stage,即ResultStage中,RDD-2依赖RDD-1,RDD-1依赖RDD-0,这些依赖都是窄依赖,所以将RDD-0、RDD-1和RDD-2划分到同一个Stage,即ShuffleMapStage中,实际执行的时候,数据记录会一气呵成地执行RDD-0到RDD-2的转化。不难看出,其本质上是一个深度优先搜索算法。
一个Stage是否被提交,需要判断它的父Stage是否执行,只有在父Stage执行完毕才能提交当前Stage,如果一个Stage没有父Stage,那么从该Stage开始提交。Stage提交时会将Task信息(分区信息以及方法等)序列化并被打包成TaskSet交给TaskScheduler,一个Partition对应一个Task,另一方面TaskScheduler会监控Stage的运行状态,只有Executor丢失或者Task由于Fetch失败才需要重新提交失败的Stage以调度运行失败的任务,其他类型的Task失败会在TaskScheduler的调度过程中重试。
相对来说DAGScheduler做的事情较为简单,仅仅是在Stage层面上划分DAG,提交Stage并监控相关状态信息。TaskScheduler则相对较为复杂,下面详细阐述其细节。
Spark Task 级调度
Spark Task的调度是由TaskScheduler来完成,由前文可知,DAGScheduler将Stage打包到TaskSet交给TaskScheduler,TaskScheduler会将TaskSet封装为TaskSetManager加入到调度队列中,TaskSetManager结构如下图所示。
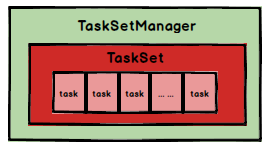
TaskSetManager负责监控管理同一个Stage中的Tasks,TaskScheduler就是以TaskSetManager为单元来调度任务。
前面也提到,TaskScheduler初始化后会启动SchedulerBackend,它负责跟外界打交道,接收Executor的注册信息,并维护Executor的状态,所以说SchedulerBackend是管“粮食”的,同时它在启动后会定期地去“询问”TaskScheduler有没有任务要运行,也就是说,它会定期地“问”TaskScheduler“我有这么余量,你要不要啊”,TaskScheduler在SchedulerBackend“问”它的时候,会从调度队列中按照指定的调度策略选择TaskSetManager去调度运行,大致方法调用流程如下图所示:
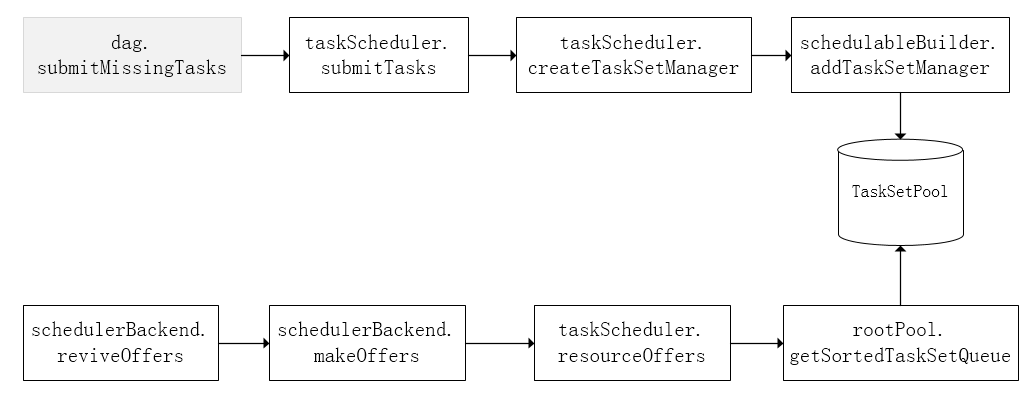
将TaskSetManager加入rootPool调度池中之后,调用SchedulerBackend的riviveOffers方法给driverEndpoint发送ReviveOffer消息;driverEndpoint收到ReviveOffer消息后调用makeOffers方法,过滤出活跃状态的Executor(这些Executor都是任务启动时反向注册到Driver的Executor),然后将Executor封装成WorkerOffer对象;准备好计算资源(WorkerOffer)后,taskScheduler基于这些资源调用resourceOffer在Executor上分配task。
调度策略
前面讲到,TaskScheduler会先把DAGScheduler给过来的TaskSet封装成TaskSetManager扔到任务队列里,然后再从任务队列里按照一定的规则把它们取出来在SchedulerBackend给过来的Executor上运行。这个调度过程实际上还是比较粗粒度的,是面向TaskSetManager的。
TaskScheduler是以树的方式来管理任务队列,树中的节点类型为Schdulable,叶子节点为TaskSetManager,非叶子节点为Pool,下图是它们之间的继承关系。

TaskScheduler支持两种调度策略,一种是FIFO,也是默认的调度策略,另一种是FAIR。在TaskScheduler初始化过程中会实例化rootPool,表示树的根节点,是Pool类型。
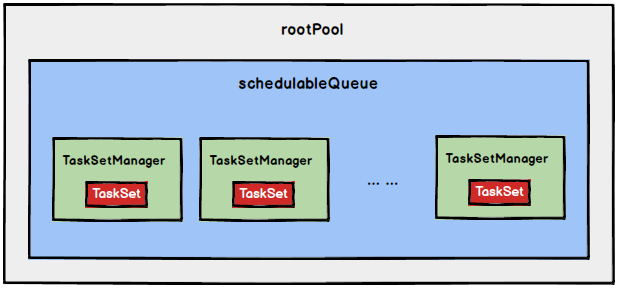
FIFO调度策略
如果是采用FIFO调度策略,则直接简单地将TaskSetManager按照先来先到的方式入队,出队时直接拿出最先进队的TaskSetManager,其树结构如下图所示,TaskSetManager保存在一个FIFO队列中。
FAIR 调度策略
FAIR调度策略的树结构如下图所示:
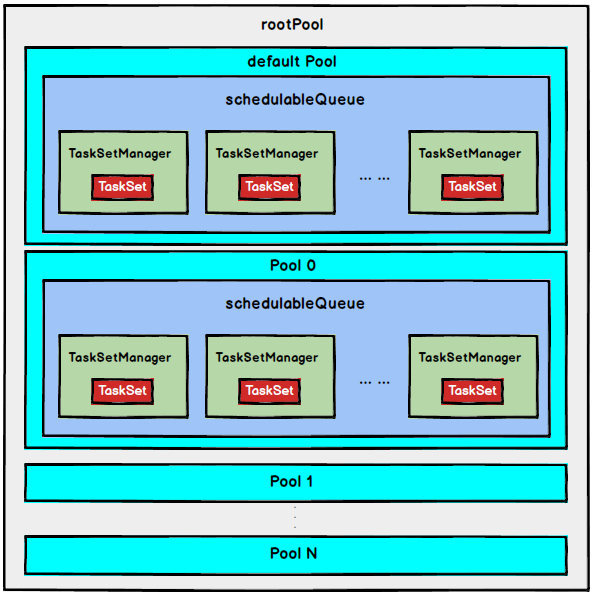
FAIR模式中有一个rootPool和多个子Pool,各个子Pool中存储着所有待分配的TaskSetMagager。
在FAIR模式中,需要先对子Pool进行排序,再对子Pool里面的TaskSetMagager进行排序,因为Pool和TaskSetMagager都继承了Schedulable特质,因此使用相同的排序算法。
排序过程的比较是基于Fair-share来比较的,每个要排序的对象包含三个属性: runningTasks值(正在运行的Task数)、minShare值、weight值,比较时会综合考量runningTasks值,minShare值以及weight值。
注意,minShare、weight的值均在公平调度配置文件fairscheduler.xml中被指定,调度池在构建阶段会读取此文件的相关配置。
1) 如果A对象的runningTasks大于它的minShare,B对象的runningTasks小于它的minShare,那么B排在A前面;(runningTasks比minShare小的先执行)
2) 如果A、B对象的runningTasks都小于它们的minShare,那么就比较runningTasks与minShare的比值(minShare使用率),谁小谁排前面;(minShare使用率低的先执行)
3) 如果A、B对象的runningTasks都大于它们的minShare,那么就比较runningTasks与weight的比值(权重使用率),谁小谁排前面。(权重使用率低的先执行)
4) 如果上述比较均相等,则比较名字。
整体上来说就是通过minShare和weight这两个参数控制比较过程,可以做到让minShare使用率和权重使用率少(实际运行task比例较少)的先运行。
FAIR模式排序完成后,所有的TaskSetManager被放入一个ArrayBuffer里,之后依次被取出并发送给Executor执行。
从调度队列中拿到TaskSetManager后,由于TaskSetManager封装了一个Stage的所有Task,并负责管理调度这些Task,那么接下来的工作就是TaskSetManager按照一定的规则一个个取出Task给TaskScheduler,TaskScheduler再交给SchedulerBackend去发到Executor上执行。
本地化调度
DAGScheduler切割Job,划分Stage, 通过调用submitStage来提交一个Stage对应的tasks,submitStage会调用submitMissingTasks,submitMissingTasks 确定每个需要计算的 task 的preferredLocations,通过调用getPreferrdeLocations()得到partition 的优先位置,由于一个partition对应一个task,此partition的优先位置就是task的优先位置,对于要提交到TaskScheduler的TaskSet中的每一个task,该task优先位置与其对应的partition对应的优先位置一致。
从调度队列中拿到TaskSetManager后,那么接下来的工作就是TaskSetManager按照一定的规则一个个取出task给TaskScheduler,TaskScheduler再交给SchedulerBackend去发到Executor上执行。前面也提到,TaskSetManager封装了一个Stage的所有task,并负责管理调度这些task。
根据每个task的优先位置,确定task的Locality级别,Locality一共有五种,优先级由高到低顺序:
| 名称 | 解析 |
|---|---|
| PROCESS_LOCAL | 进程本地化,task和数据在同一个Executor中,性能最好。 |
| NODE_LOCAL | 节点本地化,task和数据在同一个节点中,但是task和数据不在同一个Executor中,数据需要在进程间进行传输。 |
| RACK_LOCAL | 机架本地化,task和数据在同一个机架的两个节点上,数据需要通过网络在节点之间进行传输。 |
| NO_PREF | 对于task来说,从哪里获取都一样,没有好坏之分。 |
| ANY | task和数据可以在集群的任何地方,而且不在一个机架中,性能最差。 |
在调度执行时,Spark调度总是会尽量让每个task以最高的本地性级别来启动,当一个task以X本地性级别启动,但是该本地性级别对应的所有节点都没有空闲资源而启动失败,此时并不会马上降低本地性级别启动而是在某个时间长度内再次以X本地性级别来启动该task,若超过限时时间则降级启动,去尝试下一个本地性级别,依次类推。
可以通过调大每个类别的最大容忍延迟时间,在等待阶段对应的Executor可能就会有相应的资源去执行此task,这就在在一定程度上提到了运行性能。
失败重试与黑名单机制
除了选择合适的Task调度运行外,还需要监控Task的执行状态,前面也提到,与外部打交道的是SchedulerBackend,Task被提交到Executor启动执行后,Executor会将执行状态上报给SchedulerBackend,SchedulerBackend则告诉TaskScheduler,TaskScheduler找到该Task对应的TaskSetManager,并通知到该TaskSetManager,这样TaskSetManager就知道Task的失败与成功状态,对于失败的Task,会记录它失败的次数,如果失败次数还没有超过最大重试次数,那么就把它放回待调度的Task池子中,否则整个Application失败。
在记录Task失败次数过程中,会记录它上一次失败所在的Executor Id和Host,这样下次再调度这个Task时,会使用黑名单机制,避免它被调度到上一次失败的节点上,起到一定的容错作用。黑名单记录Task上一次失败所在的Executor Id和Host,以及其对应的“拉黑”时间,“拉黑”时间是指这段时间内不要再往这个节点上调度这个Task了。
【Spark 内核】 Spark 内核解析-上的更多相关文章
- Linux内核:sk_buff解析
sk_buff 目录 1 sk_buff介绍 2 sk_buff组成 3 struct sk_buff 结构体 4 sk_buff成员变量 4.1 Layout布局 4.2 General通用 4.3 ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- 大数据技术之_19_Spark学习_05_Spark GraphX 应用解析 + Spark GraphX 概述、解析 + 计算模式 + Pregel API + 图算法参考代码 + PageRank 实例
第1章 Spark GraphX 概述1.1 什么是 Spark GraphX1.2 弹性分布式属性图1.3 运行图计算程序第2章 Spark GraphX 解析2.1 存储模式2.1.1 图存储模式 ...
- 【转载】linux2.6内核initrd机制解析
题记 很久之前就分析过这部分内容,但是那个时候不够深入,姑且知道这么个东西存在,到底怎么用,来龙去脉咋回事就不知道了.前段时间工作上遇到了一个initrd的问题,没办法只能再去研究研究,还好,有点眉目 ...
- Spark MLlib LDA 源代码解析
1.Spark MLlib LDA源代码解析 http://blog.csdn.net/sunbow0 Spark MLlib LDA 应该算是比較难理解的,当中涉及到大量的概率与统计的相关知识,并且 ...
- linux内核驱动module_init解析(2)
本文转载自博客http://blog.csdn.net/u013216061/article/details/72511653 如果了解过Linux操作系统启动流程,那么当bootloader加载完k ...
- Spark in action on Kubernetes - Spark Operator的原理解析
前言 在上篇文章中,向大家介绍了如何使用Spark Operator在kubernetes集群上面提交一个计算作业.今天我们会继续使用上篇文章中搭建的Playground进行调试与解析,帮助大家更深入 ...
- [转]Spark SQL2.X 在100TB上的Adaptive execution(自适应执行)实践
Spark SQL是Apache Spark最广泛使用的一个组件,它提供了非常友好的接口来分布式处理结构化数据,在很多应用领域都有成功的生产实践,但是在超大规模集群和数据集上,Spark SQL仍然遇 ...
- Spark SQL源码解析(三)Analysis阶段分析
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 Spark SQL源码解析(二)Antlr4解析Sql并生成树 Analysis阶段概述 首先 ...
- Spark SQL源码解析(四)Optimization和Physical Planning阶段解析
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 Spark SQL源码解析(二)Antlr4解析Sql并生成树 Spark SQL源码解析(三 ...
随机推荐
- 【转载】.NET中使用Redis
Redis是一个用的比较广泛的Key/Value的内存数据库,新浪微博.Github.StackOverflow 等大型应用中都用其作为缓存,Redis的官网为http://redis.io/. 最近 ...
- 机器学习-RBF高斯核函数处理
机器学习-RBF高斯核函数处理 SVM高斯核函数-RBF优化 重要了解数学的部分: 协方差矩阵,高斯核函数公式. 个人建议具体的求法还是看下面的核心代码吧,更好理解,反正就我个人而言,烦躁的公式,还 ...
- servicemix-3.2.1 部署异常
<jbi-task xmlns="http://java.sun.com/xml/ns/jbi/management-message" version="1.0&q ...
- pytorch中如何处理RNN输入变长序列padding
一.为什么RNN需要处理变长输入 假设我们有情感分析的例子,对每句话进行一个感情级别的分类,主体流程大概是下图所示: 思路比较简单,但是当我们进行batch个训练数据一起计算的时候,我们会遇到多个训练 ...
- H3C ACL规则的匹配顺序
- 判断当前所使用python的版本和来源
import sys print(sys.prefix) print(sys.executable) 怎样判断当前py文件在什么版本的python环境下运行 import sys print(sys. ...
- 【codeforces 761B】Dasha and friends
time limit per test2 seconds memory limit per test256 megabytes inputstandard input outputstandard o ...
- 如何用for..of.. 遍历一个普通的对象?
如何用for..of.. 遍历一个普通的对象? 首先了解一下for..of..: 它是es6新增的一个遍历方法,但只限于迭代器(iterator), 所以普通的对象用for..of遍历 是会报错的.下 ...
- vc得到屏幕的当前分辨率方法
vc得到屏幕的当前分辨率方法:1.Windows API调用int width = GetSystemMetrics ( SM_CXSCREEN ); int height= GetSystemMet ...
- JS 手札记
addEventListener中的事件如果移除(removeEventListener)的话不能在事件中执行bind(this)否则会移除无效! // selectCurrent() // copy ...