深入浅出 Java Concurrency (16): 并发容器 part 1 ConcurrentMap (1)[转]
从这一节开始正式进入并发容器的部分,来看看JDK 6带来了哪些并发容器。
在JDK 1.4以下只有Vector和Hashtable是线程安全的集合(也称并发容器,Collections.synchronized*系列也可以看作是线程安全的实现)。从JDK 5开始增加了线程安全的Map接口ConcurrentMap和线程安全的队列BlockingQueue(尽管Queue也是同时期引入的新的集合,但是规范并没有规定一定是线程安全的,事实上一些实现也不是线程安全的,比如PriorityQueue、ArrayDeque、LinkedList等,在Queue章节中会具体讨论这些队列的结构图和实现)。
在介绍ConcurrencyMap之前先来回顾下Map的体系结构。下图描述了Map的体系结构,其中蓝色字体的是JDK 5以后新增的并发容器。
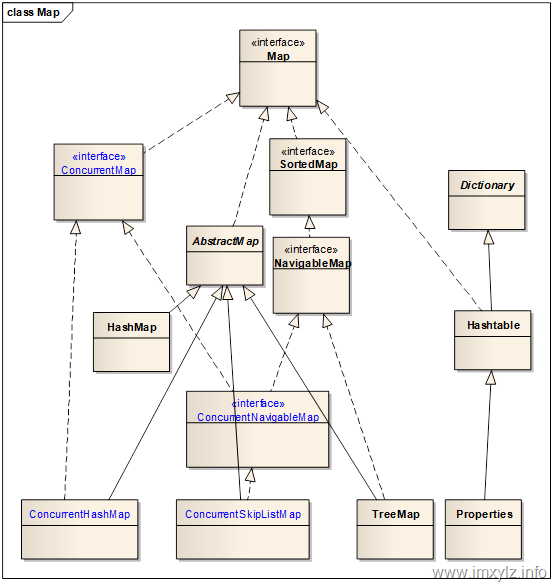
针对上图有以下几点说明:
- Hashtable是JDK 5之前Map唯一线程安全的内置实现(Collections.synchronizedMap不算)。特别说明的是Hashtable的t是小写的(不知道为啥),Hashtable继承的是Dictionary(Hashtable是其唯一公开的子类),并不继承AbstractMap或者HashMap。尽管Hashtable和HashMap的结构非常类似,但是他们之间并没有多大联系。
- ConcurrentHashMap是HashMap的线程安全版本,ConcurrentSkipListMap是TreeMap的线程安全版本。
- 最终可用的线程安全版本Map实现是ConcurrentHashMap/ConcurrentSkipListMap/Hashtable/Properties四个,但是Hashtable是过时的类库,因此如果可以的应该尽可能的使用ConcurrentHashMap和ConcurrentSkipListMap。
回到正题来,这个小节主要介绍ConcurrentHashMap的API以及应用,下一节才开始将原理和分析。

除了实现Map接口里面对象的方法外,ConcurrentHashMap还实现了ConcurrentMap里面的四个方法。
V putIfAbsent(K key,V value)
如果不存在key对应的值,则将value以key加入Map,否则返回key对应的旧值。这个等价于清单1 的操作:
清单1 putIfAbsent的等价操作
if (!map.containsKey(key))
return map.put(key, value);
else
return map.get(key);
在前面的章节中提到过,连续两个或多个原子操作的序列并不一定是原子操作。比如上面的操作即使在Hashtable中也不是原子操作。而putIfAbsent就是一个线程安全版本的操作的。
有些人喜欢用这种功能来实现单例模式,例如清单2。
清单2 一种单例模式的实现
package xylz.study.concurrency;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;public class ConcurrentDemo1 {
private static final ConcurrentMap<String, ConcurrentDemo1> map = new ConcurrentHashMap<String, ConcurrentDemo1>();
private static ConcurrentDemo1 instance;
public static ConcurrentDemo1 getInstance() {
if (instance == null) {map.putIfAbsent("INSTANCE", new ConcurrentDemo1());
instance = map.get("INSTANCE");
}
return instance;
}private ConcurrentDemo1() {
}}
当然这里只是一个操作的例子,实际上在单例模式文章中有很多的实现和比较。清单2 在存在大量单例的情况下可能有用,实际情况下很少用于单例模式。但是这个方法避免了向Map中的同一个Key提交多个结果的可能,有时候在去掉重复记录上很有用(如果记录的格式比较固定的话)。
boolean remove(Object key,Object value)
只有目前将键的条目映射到给定值时,才移除该键的条目。这等价于清单3 的操作。
清单3 remove(Object,Object)的等价操作
if (map.containsKey(key) && map.get(key).equals(value)) {
map.remove(key);
return true;
}
return false;
由于集合类通常比较的hashCode和equals方法,而这两个方法是在Object对象里面,因此两个对象如果hashCode一致,并且覆盖了equals方法后也一致,那么这两个对象在集合类里面就是“相同”的,不管是否是同一个对象或者同一类型的对象。也就是说只要key1.hashCode()==key2.hashCode() && key1.equals(key2),那么key1和key2在集合类里面就认为是一致,哪怕他们的Class类型不一致也没关系,所以在很多集合类里面允许通过Object来类型来比较(或者定位)。比如说Map尽管添加的时候只能通过制定的类型<K,V>,但是删除的时候却允许通过一个Object来操作,而不必是K类型。
既然Map里面有一个remove(Object)方法,为什么ConcurrentMap还需要remove(Object,Object)方法呢?这是因为尽管Map里面的key没有变化,但是value可能已经被其他线程修改了,如果修改后的值是我们期望的,那么我们就不能拿一个key来删除此值,尽管我们的期望值是删除此key对于的旧值。
这种特性在原子操作章节的AtomicMarkableReference和AtomicStampedReference里面介绍过。
boolean replace(K key,V oldValue,V newValue)
只有目前将键的条目映射到给定值时,才替换该键的条目。这等价于清单4 的操作。
清单4 replace(K,V,V)的等价操作
if (map.containsKey(key) && map.get(key).equals(oldValue)) {
map.put(key, newValue);
return true;
}
return false;
V replace(K key,V value)
只有当前键存在的时候更新此键对于的值。这等价于清单5 的操作。
清单5 replace(K,V)的等价操作
if (map.containsKey(key)) {
return map.put(key, value);
}
return null;
replace(K,V,V)相比replace(K,V)而言,就是增加了匹配oldValue的操作。
其实这4个扩展方法,是ConcurrentMap附送的四个操作,其实我们更关心的是Map本身的操作。当然如果没有这4个方法,要完成类似的功能我们可能需要额外的锁,所以有总比没有要好。比如清单6,如果没有putIfAbsent内置的方法,我们如果要完成此操作就需要完全锁住整个Map,这样就大大降低了ConcurrentMap的并发性。这在下一节中有详细的分析和讨论。
清单6 putIfAbsent的外部实现
public V putIfAbsent(K key, V value) {
synchronized (map) {
if (!map.containsKey(key)) return map.put(key, value);
return map.get(key);
}
}
参考资料:
深入浅出 Java Concurrency (16): 并发容器 part 1 ConcurrentMap (1)[转]的更多相关文章
- 深入浅出 Java Concurrency (17): 并发容器 part 2 ConcurrentMap (2)[转]
本来想比较全面和深入的谈谈ConcurrentHashMap的,发现网上有很多对HashMap和ConcurrentHashMap分析的文章,因此本小节尽可能的分析其中的细节,少一点理论的东西,多谈谈 ...
- 深入浅出 Java Concurrency (18): 并发容器 part 3 ConcurrentMap (3)[转]
在上一篇中介绍了HashMap的原理,这一节是ConcurrentMap的最后一节,所以会完整的介绍ConcurrentHashMap的实现. ConcurrentHashMap原理 在读写锁章节部分 ...
- 《深入浅出 Java Concurrency》—并发容器 ConcurrentMap
(转自:http://blog.csdn.net/fg2006/article/details/6404226) 在JDK 1.4以下只有Vector和Hashtable是线程安全的集合(也称并发容器 ...
- 深入浅出 Java Concurrency (21): 并发容器 part 6 可阻塞的BlockingQueue (1)[转]
在<并发容器 part 4 并发队列与Queue简介>节中的类图中可以看到,对于Queue来说,BlockingQueue是主要的线程安全版本.这是一个可阻塞的版本,也就是允许添加/删除元 ...
- 深入浅出 Java Concurrency (27): 并发容器 part 12 线程安全的List/Set[转]
本小节是<并发容器>的最后一部分,这一个小节描述的是针对List/Set接口的一个线程版本. 在<并发队列与Queue简介>中介绍了并发容器的一个概括,主要描述的是Queue的 ...
- 深入浅出 Java Concurrency (25): 并发容器 part 10 双向并发阻塞队列 BlockingDeque[转]
这个小节介绍Queue的最后一个工具,也是最强大的一个工具.从名称上就可以看到此工具的特点:双向并发阻塞队列.所谓双向是指可以从队列的头和尾同时操作,并发只是线程安全的实现,阻塞允许在入队出队不满足条 ...
- 深入浅出 Java Concurrency (23): 并发容器 part 8 可阻塞的BlockingQueue (3)[转]
在Set中有一个排序的集合SortedSet,用来保存按照自然顺序排列的对象.Queue中同样引入了一个支持排序的FIFO模型. 并发队列与Queue简介 中介绍了,PriorityQueue和Pri ...
- 深入浅出 Java Concurrency (26): 并发容器 part 11 Exchanger[转]
可以在对中对元素进行配对和交换的线程的同步点.每个线程将条目上的某个方法呈现给 exchange 方法,与伙伴线程进行匹配,并且在返回时接收其伙伴的对象.Exchanger 可能被视为 Synchro ...
- 深入浅出 Java Concurrency (20): 并发容器 part 5 ConcurrentLinkedQueue[转]
ConcurrentLinkedQueue是Queue的一个线程安全实现.先来看一段文档说明. 一个基于链接节点的无界线程安全队列.此队列按照 FIFO(先进先出)原则对元素进行排序.队列的头部 是队 ...
随机推荐
- c++与js脚本交互,C++调用JS函数JS调用C++函数
一.javascript调用c++,方法有两种 方案1: 1.html编写 <html><head></head><body><h1>TES ...
- BZOJ 1010 (HNOI 2008) 玩具装箱
1010: [HNOI2008]玩具装箱toy Time Limit: 1 Sec Memory Limit: 162 MB Submit: 12665 Solved: 5540 [Submit][S ...
- 什么是存根类 Stub
转:http://www.cnblogs.com/cy163/archive/2009/08/04/1539077.html 存根类是一个类,它实现了一个接口,但是实现后的每个方法都是空的. ...
- Socket.EndReceive 方法 (IAsyncResult)
.NET Framework (current version) 其他版本 .NET Framework 4 .NET Framework 3.5 .NET Framework 3.0 . ...
- 样本方差的抽样分布 χ2(n) 卡方分布_样本方差 卡方分布
样本方差的抽样分布 χ2(n) 卡方分布_样本方差 卡方分布 样本方差的抽样分布 χ2(n) 卡方分布 t分布.卡方分布.f分布均要求总体服从正态分布. 若n个相互独立的随机变量ξ1,ξ2,-,ξn ...
- 分类算法之朴素贝叶斯分类(Naive Bayesian classification)
分类算法之朴素贝叶斯分类(Naive Bayesian classification) 0.写在前面的话 我个人一直很喜欢算法一类的东西,在我看来算法是人类智慧的精华,其中蕴含着无与伦比的美感.而每次 ...
- POJ 1269 /// 判断两条直线的位置关系
题目大意: t个测试用例 每次给出一对直线的两点 判断直线的相对关系 平行输出NODE 重合输出LINE 相交输出POINT和交点坐标 1.直线平行 两向量叉积为0 2.求两直线ab与cd交点 设直线 ...
- 小程序swiper-item内容过多显示不全的解决方案
最近在项目遇到swiper高度不能自适应,导致swiper-item 里面的内容过多时只能显示一部分,最终解决方案:<swiper current="{{currentTab}}&qu ...
- Johnson–Lindenstrauss 定理-Johnson–Lindenstrauss lemma
Johnson–Lindenstrauss 定理是这样的:一个一百万维空间里的随便一万个点,一定可以几乎被装进一个几十维的子空间里! 严格说来是这样:在 M 维空间中的 N 个点,几乎总是被包含在一个 ...
- 异常处理记录: Unable to compile class for JSP
出错信息截图: 经过搜索引擎的帮助, 发现这些引发异常的可能原因: 1. tomcat的版本必须大于等于JDK的版本 2. maven中的jar与tomcat中jar冲突 看看pom.xml, 果然j ...