浅析word2vec(一)
1 word2vec
在自然语言处理的大部分任务中,需要将大量文本数据传入计算机中,用以信息发掘以便后续工作。但是目前计算机所能处理的只能是数值,无法直接分析文本,因此,将原有的文本数据转换为数值数据成为了自然语言处理任务的关键一环。
Word2vec,为一群用来产生词向量的相关模型。这些模型为浅层双层的神经网络,用来训练以重新建构语言学之词文本。 ————维基百科
简单来说,word2vec的系列模型可以将文字(此处特指中文字符)转换成向量,比如“我爱中国”这句话,经过模型处理后,可能会变为以下4个向量:
(0.12,0.45,-0.3,0.44),(0.2,0.6,0.7,0.9),(-0.76,0.53,0.88,-0.31),(0.47,0.92,0.66,0.89),
这种向量称为词向量(对中文而言也可以称作字向量),后续对"我爱中国"的处理便可以转为对以上4个词向量的处理。
那么这种转换是如何完成的,这就要谈及word2vec中的两个经典模型:skip-grams和CBOW,CBOW下次再讲,本文主要介绍skip-grams.
关于skip-grams的详细说明,诸位可以参考网页:https://becominghuman.ai/how-does-word2vecs-skip-gram-work-f92e0525def4
2 模型特点
skip-grams的工作方法与其它模型略有差别,词向量的获取并不是通过输入一个字到skip-grams中再从模型中输出一个向量。相反,只要将skip-grams模型训练完成后,所有参与训练的字就已经获得了自己的词向量;换句话说,所有的词向量已经作为模型的可训参数储存在模型自身,想要得到某个字的词向量,只需依照某种规则从模型参数中提取即可,所以模型的训练阶段至关重要。
3 训练过程
3.1 获取训练样本
模型的训练思路大体如下:初始先给每个字随机分配一个词向量,然后选定一字作为中心字,取一个固定的长度,在原始语料中获得训练样本,如下图所示:
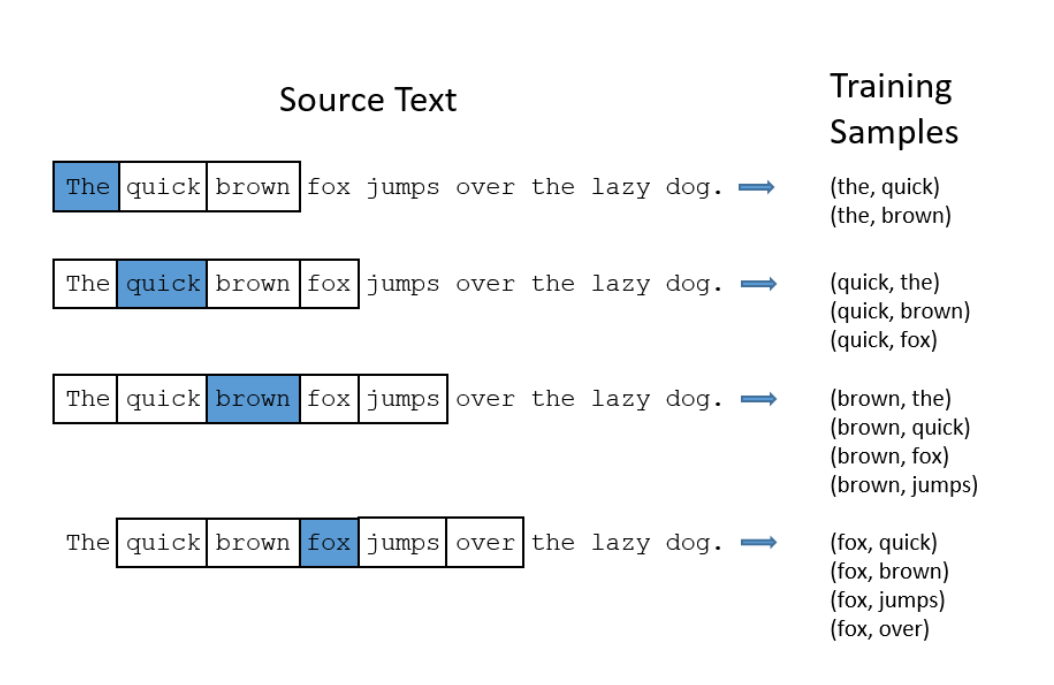
3.2 统计频率
统计上下文字出现在中心字周围的频率,作为该字与中心字共存的概率。
3.3 模型参数调整
在给定的词向量的基础上,依次计算每个字与中心字共存的概率大小。多数情况下,这与上一步实际统计出来的有所差异,所以要调整模型参数,使得概率分布更符合实际情况,对参数的调整就是对词向量的调整。如此进行若干次后,以至于每个字都有机会作为中心字参与训练。参数训练完成后,则每个字对应的词向量已经得到。
4 备注
模型训练完成后,每个字通常会有两个词向量与之对应,一个是该字作为中心字时的词向量,一个是该字作为其它字的上下文字时的词向量,一般选取前者代表该字最终的词向量。
浅析word2vec(一)的更多相关文章
- word2vec 原理浅析 及高效训练方法
1. https://www.cnblogs.com/cymx66688/p/11185824.html (word2vec中的CBOW 和skip-gram 模型 浅析) 2. https://ww ...
- word2vec浅析
本文是參考神经网络语言模型.word2vec相关论文和网上博客等资料整理的学习笔记.仅记录 自己的学习历程,欢迎拍砖. word2vec是2013年google提出的一种神经网络的语言模型,通过神经网 ...
- word2vec原理浅析
1.word2vec简介 word2vec,即词向量,就是一个词用一个向量来表示.是2013年Google提出的.word2vec工具主要包含两个模型:跳字模型(skip-gram)和连续词袋模型( ...
- SQL Server on Linux 理由浅析
SQL Server on Linux 理由浅析 今天的爆炸性新闻<SQL Server on Linux>基本上在各大科技媒体上刷屏了 大家看到这个新闻都觉得非常震精,而美股,今天微软开 ...
- 【深入浅出jQuery】源码浅析--整体架构
最近一直在研读 jQuery 源码,初看源码一头雾水毫无头绪,真正静下心来细看写的真是精妙,让你感叹代码之美. 其结构明晰,高内聚.低耦合,兼具优秀的性能与便利的扩展性,在浏览器的兼容性(功能缺陷.渐 ...
- 高性能IO模型浅析
高性能IO模型浅析 服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(Blocking IO):即传统的IO模型. (2)同步非阻塞IO(Non-blocking ...
- netty5 HTTP协议栈浅析与实践
一.说在前面的话 前段时间,工作上需要做一个针对视频质量的统计分析系统,各端(PC端.移动端和 WEB端)将视频质量数据放在一个 HTTP 请求中上报到服务器,服务器对数据进行解析.分拣后从不同的 ...
- Jvm 内存浅析 及 GC个人学习总结
从诞生至今,20多年过去,Java至今仍是使用最为广泛的语言.这仰赖于Java提供的各种技术和特性,让开发人员能优雅的编写高效的程序.今天我们就来说说Java的一项基本但非常重要的技术内存管理 了解C ...
- 从源码浅析MVC的MvcRouteHandler、MvcHandler和MvcHttpHandler
熟悉WebForm开发的朋友一定都知道,Page类必须实现一个接口,就是IHttpHandler.HttpHandler是一个HTTP请求的真正处理中心,在HttpHandler容器中,ASP.NET ...
随机推荐
- CTF-Keylead(ASIS CTF 2015)
将keylead下载到本地用7-ZIP打开,发现主要文件 keylead~ 在ubuntu里跑起来,发现是个游戏,按回车后要摇出3,1,3,3,7就能获得flag. 拖进IDA 直接开启远程调试,跑起 ...
- 创建一个区域(Creating an Area) |使用区域 | 高级路由特性 | 精通ASP-NET-MVC-5-弗瑞曼
摘自:http://www.cnblogs.com/chenboyi081/p/4472709.html#tar2015050302 下面的AdminAreaRegistration继承自AreaRe ...
- 【自制操作系统06】终于开始用 C 语言了,第一行内核代码!
一.整理下到目前为止的流程图 写到这,终于才把一些苦力活都干完了,也终于到了我们的内核代码部分,也终于开始第一次用 c 语言写代码了!为了这个阶段性的胜利,以及更好地进入内核部分,下图贴一张到目前为止 ...
- win10打开相机提示我们找不到你的相机
- php7 mongodb 扩展windows 安装
1. 打开phpinfo 查看 nts(非线程) 还是 ts (线程),然后查看操作位数 注: 86 等于 32 位 2. 下载对应的版本的php_mongodb.dll 文件 下载链接: pecl ...
- K8S搭建教程及部署脚本
部署环境: 主机名 IP地址 系统OS 内核 master 10.5.1.10 CentOS7 Linux master 3.10.0-1062 node1 10.5.1.11 CentOS7 Lin ...
- Arduino通信篇系列之print()和write()输出方式的差异
我们都知道,在HardwareSerial类中有print()和write()两种输出方式, 两个都可以输出数据,但其输出方式并不相同. 例子: float FLOAT=1.23456; int IN ...
- abp vnext2.0核心组件之领域实体组件源码解析
接着abp vnext2.0核心组件之模块加载组件源码解析和abp vnext2.0核心组件之.Net Core默认DI组件切换到AutoFac源码解析集合.Net Core3.1,基本环境已经完备, ...
- 《 Java 编程思想》CH02 一切都是对象
用引用操纵对象 尽管Java中一切都看作为对象,但是操纵的标识符实际上对象的一个"引用". String s; // 这里只是创建了一个引用,而不是一个对象 String s = ...
- 引入Activiti配置文件activiti.cfg.xml
前面我们用代码实现了生成25张activiti表,今天我们用Activiti提供的activiti.cfg.xml配置文件来简化实现前面的功能: 官方文档参考地址:http://activiti.or ...