用Python制作酷炫词云图,原来这么简单!











一、简介
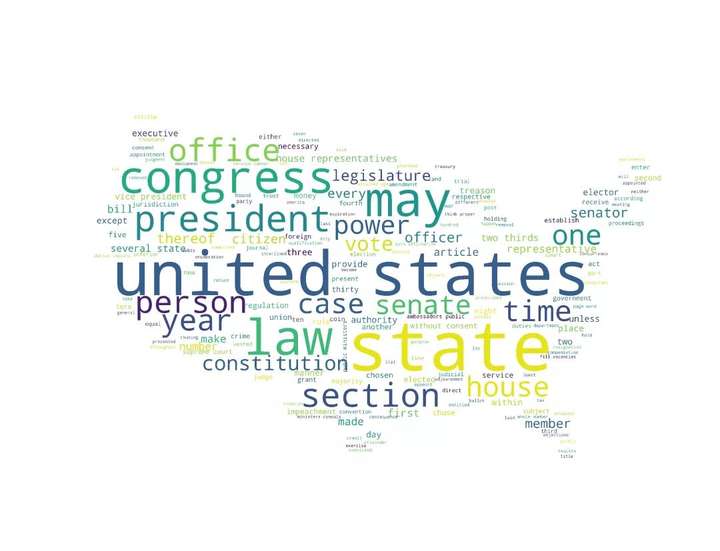
词云图是文本挖掘中用来表征词频的数据可视化图像,通过它可以很直观地展现文本数据中地高频词:
图1 词云图示例
在Python中有很多可视化框架可以用来制作词云图,如pyecharts,但这些框架并不是专门用于制作词云图的,因此并不支持更加个性化的制图需求,要想创作出更加美观个性的词云图,需要用到一些专门绘制词云图的第三方模块,本文就将针对其中较为优秀易用的wordcloud以及stylecloud的用法进行介绍和举例说明。
二、利用wordcloud绘制词云图
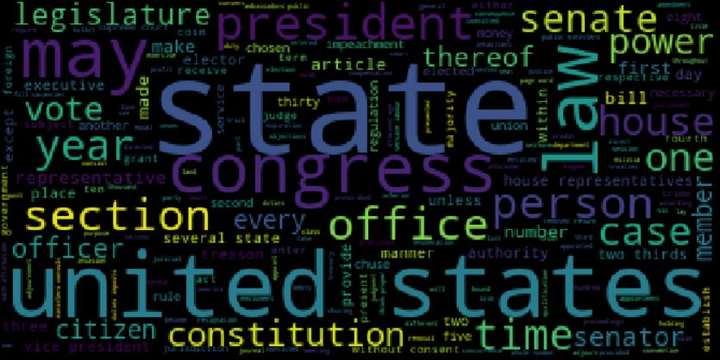
wordcloud是Python中制作词云图比较经典的一个模块,赋予用户高度的自由度来创作词云图:
图2 wordcloud制作词云图示例
2.1 从一个简单的例子开始
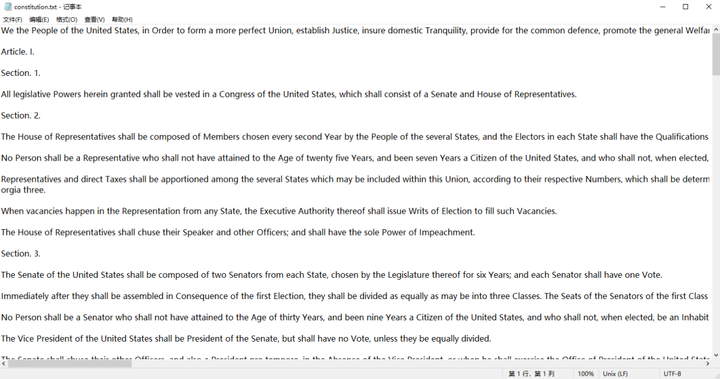
这里我们使用到来自wordcloud官方文档中的constitution.txt来作为可视化的数据素材:
图3 constitution.txt
首先我们读入数据并将数据清洗成空格分隔的长字符串:
import re
with open(‘constitution.txt’) as c: ‘’’抽取文本中的英文部分并小写化,并将空格作为分隔拼接为长字符串’’’ text = ‘ ‘.join([word.group().lower() for word in re.finditer(‘[a-zA-Z]+’, c.read())])
‘’’查看前100个字符’’’text[:500]图4 清洗后的片段文本
接着使用wordcloud中用于生成词云图的类WordCloud配合matplotlib,在默认参数设置下生成一张简单的词云图:
from wordcloud import WordCloudimport matplotlib.pyplot as plt%matplotlib inline
‘’’从文本中生成词云图’’’wordcloud = WordCloud().generate(text)plt.figure(figsize=[12, 10])plt.imshow(wordcloud)plt.axis(‘off’)plt.show()生成的词云图:
图5 默认参数下的词云图
毕竟是在默认参数下生成的词云图,既丑陋又模糊,为了绘制好看的词云图,接下来我们来对wordcloud绘制词云图的细节内容进行介绍,并不断地对图5进行升级改造。
2.2 WordCloud
作为wordcloud绘制词云图最核心的类,WordCloud的主要参数及说明如下:
fontpath:字符型,用于传入本地特定字体文件的路径(ttf或otf文件)从而影响词云图的字体族
width:int型,用于控制词云图画布宽度,默认为400
height:int型,用于控制词云图画布高度,默认为200
prefer_horizontal:float型,控制所有水平显示的文字相对于竖直显示文字的比例,越小则词云图中竖直显示的文字越多
mask:传入蒙版图像矩阵,使得词云的分布与传入的蒙版图像一致
contour:float型,当mask不为None时,contour参数决定了蒙版图像轮廓线的显示宽度,默认为0即不显示轮廓线
contour_color:设置蒙版轮廓线的颜色,默认为’black’
scale:当画布长宽固定时,按照比例进行放大画布,如scale设置为1.5,则长和宽都是原来画布的1.5倍
min_font_size:int型,控制词云图中最小的词对应的字体大小,默认为4
max_font_size:int型,控制词云图中最大的词对应的字体大小,默认为200
max_words:int型,控制一张画布中最多绘制的词个数,默认为200
stopwords:控制绘图时忽略的停用词,即不绘制停用词中提及的词,默认为None,即调用自带的停用词表(仅限英文,中文需自己提供并传入)
background_color:控制词云图背景色,默认为’black’
mode:当设置为’RGBA’且background_color设置为None时,背景色变为透明,默认为’RGB’
relative_scaling:float型,控制词云图绘制字的字体大小与对应字词频的一致相关性,当设置为1时完全相关,当为0时完全不相关,默认为0.5
color_func:传入自定义调色盘函数,默认为None
colormap:对应
matplotlib中的colormap调色盘,默认为viridis,这个参数与参数color_func互斥,当color_func有函数传入时本参数失效repeat:bool型,控制是否允许一张词云图中出现重复词,默认为False即不允许重复词
random_state:控制随机数水平,传入某个固定的数字之后每一次绘图文字布局将不会改变
了解了上述参数的意义之后,首先我们修改背景色为白色,增大图床的长和宽,加大scale以提升图片的精细程度,并使得水平显示的文字尽可能多:
‘’’从文本中生成词云图’’’wordcloud = WordCloud(background_color=‘white’, # 背景色为白色 height=400, # 高度设置为400 width=800, # 宽度设置为800 scale=20, # 长宽拉伸程度设置为20 prefer_horizontal=0.9999).generate(text)plt.figure(figsize=[8, 4])plt.imshow(wordcloud)plt.axis(‘off’)‘’’保存到本地’’’plt.savefig(‘图6.jpg’, dpi=600, bbox_inches=‘tight’, quality=95)plt.show()
图6
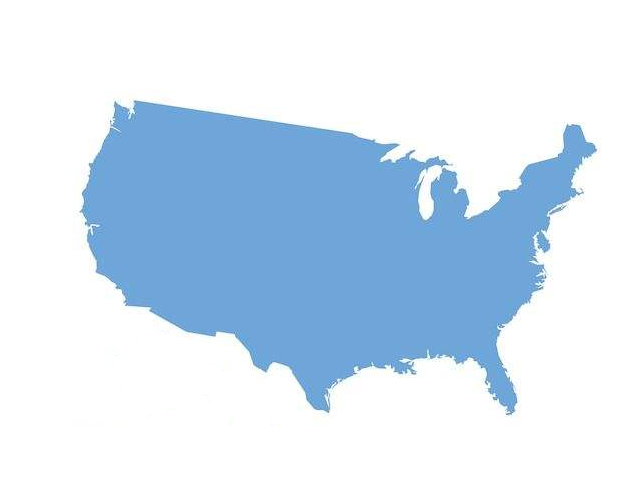
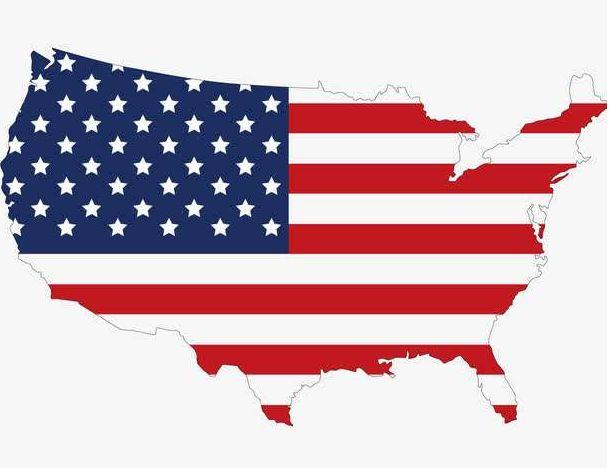
可以看到相较于图5,在美观程度上有了很大的进步,接下来,我们在图6的基础上添加美国本土地图蒙版:
图7 美国本土地图蒙版
利用PIL模块读取我们的美国本土地图蒙版.png文件并转换为numpy数组,作为WordCloud的mask参数传入:
from PIL import Imageimport numpy as np
usa_mask = np.array(Image.open(‘美国本土地图蒙版.png’))
‘’’从文本中生成词云图’’’wordcloud = WordCloud(background_color=‘white’, # 背景色为白色 height=4000, # 高度设置为400 width=8000, # 宽度设置为800 scale=20, # 长宽拉伸程度程度设置为20 prefer_horizontal=0.9999, mask=usa_mask # 添加蒙版 ).generate(text)plt.figure(figsize=[8, 4])plt.imshow(wordcloud)plt.axis(‘off’)‘’’保存到本地’’’plt.savefig(‘图8.jpg’, dpi=600, bbox_inches=‘tight’, quality=95)plt.show()图8
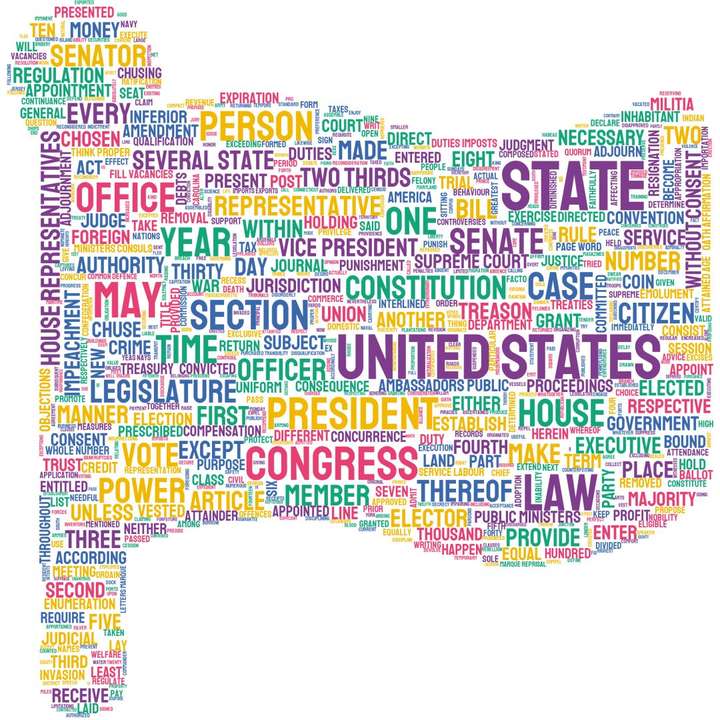
可以看到图8在图6的基础上进一步提升了美观程度,接下来我们利用wordcloud中用于从图片中提取调色方案的类ImageColorGenerator来从下面的星条旗美国地图蒙版中提取色彩方案,进而反馈到词云图上:
图9 美国地图蒙版星条旗色
from PIL import Imageimport numpy as npfrom wordcloud import ImageColorGenerator
usamask = np.array(Image.open(‘美国地图蒙版星条旗色.png’))image_colors = ImageColorGenerator(usa_mask)
‘’’从文本中生成词云图’’’wordcloud = WordCloud(background_color=‘white’, # 背景色为白色 height=400, # 高度设置为400 width=800, # 宽度设置为800 scale=20, # 长宽拉伸程度程度设置为20 prefer_horizontal=0.2, # 调整水平显示倾向程度为0.2 mask=usa_mask, # 添加蒙版 max_words=1000, # 设置最大显示字数为1000 relative_scaling=0.3, # 设置字体大小与词频的关联程度为0.3 max_font_size=80 # 缩小最大字体为80 ).generate(text)
plt.figure(figsize=[8, 4])plt.imshow(wordcloud.recolor(color_func=image_colors), alpha=1)plt.axis(‘off’)‘’’保存到本地’’’plt.savefig(‘图10.jpg’, dpi=600, bbox_inches=‘tight’, quality=95)plt.show()图10
2.3 中文词云图
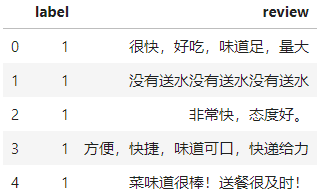
相较于英文文本语料,中文语料处理起来要麻烦一些,我们需要先进行分词等预处理才能进行下一步的处理,这里我们使用某外卖平台用户评论数据,先读取进来看看:
import pandas as pdimport jieba
‘’’读入原始数据’’’raw_comments = pd.read_csv(‘waimai_10k.csv’);raw_comments.head()图11
接下来我们利用re、jieba以及pandas中的apply对评论列进行快速清洗:
‘’’导入停用词表’’’with open(‘stopwords.txt’) as s: stopwords = set([line.replace(‘\n’, ‘’) for line in s])
‘’’传入apply的预处理函数,完成中文提取、分词以及多余空格剔除’’’def preprocessing(c):
c = [word for word in jieba.cut(‘ ‘.join(re.findall(‘[\u4e00-\u9fa5]+’, c))) if word != ‘ ‘ and word not in stopwords]
return ‘ ‘.join(c)
‘’’将所有语料按空格拼接为一整段文字’’’comments = ‘ ‘.join(raw_comments[‘review’].apply(preprocessing));comments[:500]得到的结果如图12:
图12
这时我们就得到所需的文本数据,接下来我们用美团外卖的logo图片作为蒙版绘制词云图:
图13 美团外卖logo蒙版
from PIL import Imageimport numpy as npfrom wordcloud import ImageColorGenerator
waimai_mask = np.array(Image.open(‘美团外卖logo蒙版.png’))image_colors = ImageColorGenerator(waimai_mask)
‘’’从文本中生成词云图’’’wordcloud = WordCloud(background_color=‘white’, # 背景色为白色 height=400, # 高度设置为400 width=800, # 宽度设置为800 scale=20, # 长宽拉伸程度程度设置为20 prefer_horizontal=0.2, # 调整水平显示倾向程度为0.2 mask=waimai_mask, # 添加蒙版 max_words=1000, # 设置最大显示字数为1000 relative_scaling=0.3, # 设置字体大小与词频的关联程度为0.3 max_font_size=80 # 缩小最大字体为80 ).generate(comments)
plt.figure(figsize=[8, 4])plt.imshow(wordcloud.recolor(color_func=image_colors), alpha=1)plt.axis(‘off’)‘’’保存到本地’’’plt.savefig(‘图14.jpg’, dpi=600, bbox_inches=‘tight’, quality=95)plt.show() 这时我们会发现词云图上绘制出的全是乱码,这是因为matplotlib默认字体是不包含中文的:
图14 中文乱码问题
这时我们只需要为WordCloud传入font_path参数即可,这里我们选择SimHei字体:
from PIL import Imageimport numpy as npfrom wordcloud import ImageColorGenerator
waimai_mask = np.array(Image.open(‘美团外卖logo蒙版.png’))image_colors = ImageColorGenerator(waimai_mask)
‘’’从文本中生成词云图’’’wordcloud = WordCloud(font_path=‘SimHei.ttf’, # 定义SimHei字体文件 background_color=‘white’, # 背景色为白色 height=400, # 高度设置为400 width=800, # 宽度设置为800 scale=20, # 长宽拉伸程度程度设置为20 prefer_horizontal=0.2, # 调整水平显示倾向程度为0.2 mask=waimai_mask, # 添加蒙版 max_words=1000, # 设置最大显示字数为1000 relative_scaling=0.3, # 设置字体大小与词频的关联程度为0.3 max_font_size=80 # 缩小最大字体为80 ).generate(comments)
plt.figure(figsize=[8, 4])plt.imshow(wordcloud.recolor(color_func=image_colors), alpha=1)plt.axis(‘off’)‘’’保存到本地’’’plt.savefig(‘图15.jpg’, dpi=600, bbox_inches=‘tight’, quality=95)plt.show()图15
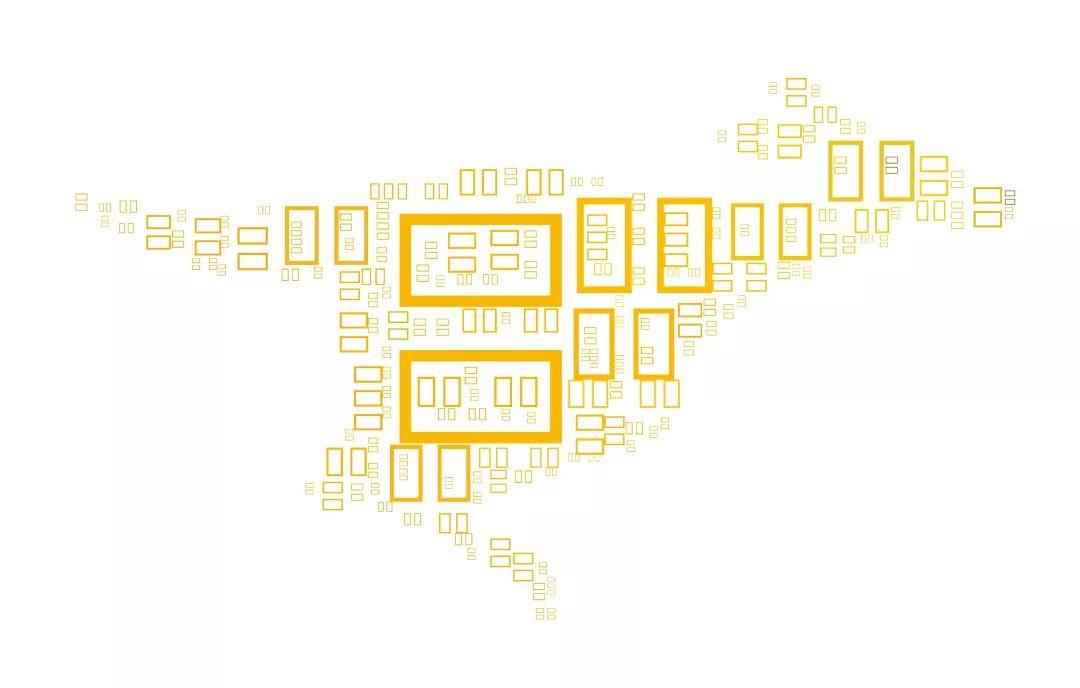
三、利用stylecloud绘制词云图
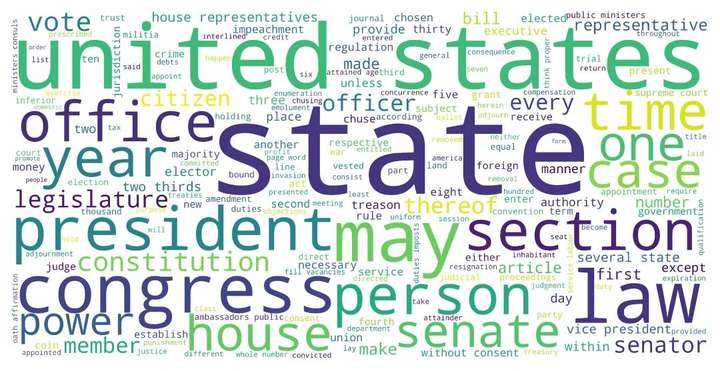
stylecloud是一个较为崭新的模块,它基于wordcloud,添加了一系列的崭新特性譬如渐变颜色等,可以支持更为个性化的词云图创作:
图16 styleword制作词云图示例
3.1 从一个简单的例子开始
这里我们沿用上一章节中使用过的处理好的text来绘制词云图:
import stylecloudfrom IPython.display import Image # 用于在jupyter lab中显示本地图片
‘’’生成词云图’’’stylecloud.gen_stylecloud(text=text, size=512, output_name=‘图17.png’)
‘’’显示本地图片’’’Image(filename=‘图17.png’)图17
可以看出,styleword生成词云图的方式跟wordcloud不同,它直接就将原始文本转换成本地词云图片文件,下面我们针对其绘制词云图的细节内容进行介绍。
3.2 gen_stylecloud
在stylecloud中绘制词云图只需要gen_stylecloud这一个函数即可,其主要参数及说明如下:
text:字符串,格式同
WordCloud中的generate()方法中传入的textgradient:控制词云图颜色渐变的方向,’horizontal’表示水平方向上渐变,’vertical’表示竖直方向上渐变,默认为’horizontal’
size:控制输出图像文件的分辨率(因为stylecloud默认输出方形图片,所以size传入的单个整数代表长和宽),默认为512
icon_name:这是stylecloud中的特殊参数,通过传递对应icon的名称,你可以使用多达1544个免费图标来作为词云图的蒙版,点击这里查看你可以免费使用的图标蒙版样式,默认为’fas fa-flag’
palette:控制调色方案,stylecloud的调色方案调用了palettable,这是一个非常实用的模块,其内部收集了数量惊人的大量的经典调色方案,默认为’cartocolors.qualitative.Bold_5’
background_color:字符串,控制词云图底色,可传入颜色名称或16进制色彩,默认为’white’
max_font_size:同
wordcloudmax_words:同
wordcloudstopwords:bool型,控制是否开启去停用词功能,默认为True,调用自带的英文停用词表
custom_stopwords:传入自定义的停用词List,配合stopwords共同使用
output_name:控制输出词云图文件的文件名,默认为
stylecloud.pngfont_path:传入自定义字体
*.ttf文件的路径random_state:同
wordcloud
对上述参数有所了解之后,下面我们在图17的基础上进行改良,首先我们将图标形状换成炸弹的样子,接着将配色方案修改为scientific.diverging.Broc_3:
‘’’生成词云图’’’stylecloud.gen_stylecloud(text=text, size=1024, output_name=‘图18.png’, palette=‘scientific.diverging.Broc_3’, # 设置配色方案 icon_name=‘fas fa-bomb’ # 设置图标样式 )
‘’’显示本地图片’’’Image(filename=‘图18.png’)图18
3.3 绘制中文词云图
在wordcloud中绘制中文词云图类似wordcloud只需要注意传入支持中文的字体文件即可,下面我们使用一个微博语料数据weibo_senti_100k.csv来举例:
weibo = pd.read_csv(‘weibo_senti_100k.csv’)weibo_text = [word for word in jieba.cut(‘ ‘.join(re.findall(‘[\u4e00-\u9fa5]+’, ‘ ‘.join(weibo[‘review’].tolist())))) if word != ‘ ‘ and word not in stopwords]weibo_text[:10]图19
接着我们将蒙版图标样式换成新浪微博,将色彩方案换成colorbrewer.sequential.Reds_3:
‘’’生成词云图’’’‘’’生成词云图’’’stylecloud.gen_stylecloud(text=‘ ‘.join(weibo_text), size=1024, output_name=‘图20.png’, palette=‘colorbrewer.sequential.Reds_3’, # 设置配色方案为https://jiffyclub.github.io/palettable/colorbrewer/sequential/#reds_3 icon_name=‘fab fa-weibo’, # 设置图标样式 gradient=‘horizontal’, # 设置颜色渐变方向为水平 font_path=‘SimHei.ttf’, collocations=False )
‘’’显示本地图片’’’Image(filename=‘图20.png’)图20
以上就是本文的全部内容,如有笔误望指出!
用Python制作酷炫词云图,原来这么简单!的更多相关文章
- 教你使用Python制作酷炫二维码
这篇文章讲的是如何利用python制作狂拽酷炫吊炸天的二维码,非常有趣哦! 可能你见过的二维码大多长这样: 普普通通,平平凡凡,没什么特色... 但,如果二维码长这样呢! 或者 这样! 是不是炒鸡好看 ...
- python根据文本生成词云图
python根据文本生成词云图 效果 代码 from wordcloud import WordCloud import codecs import jieba #import jieba.analy ...
- Python模块---Wordcloud生成词云图
wordcloud是Python扩展库中一种将词语用图片表达出来的一种形式,通过词云生成的图片,我们可以更加直观的看出某篇文章的故事梗概. 首先贴出一张词云图(以哈利波特小说为例): 在生成词云图之前 ...
- (数据科学学习手札85)Python+Kepler.gl轻松制作酷炫路径动画
本文示例代码.数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 Kepler.gl相信很多人都听说过,作为 ...
- 40行Python制作超炫酷动态排序图,有了它高逼格PPT再也不愁!
本文首发于量化投资与机器学习 转载于 https://mp.weixin.qq.com/s/KaB_7oXZf0_IV97y0pRPmQ 前言 最近,这种动态排序条形图视频超级火,如下图: ...
- 用canvas制作酷炫射击游戏--part1
好久没写博客了,因为过年后一直在学游戏制作方面的知识.学得差不多后又花了3个月时间做了个作品出来,现在正拿着这个作品找工作. 作品地址:https://betasu.github.io/Crimonl ...
- 使用python制作大数据词云
1 from wordcloud import WordCloud 2 import PIL.Image as image 3 import numpy as np 4 import jieba 5 ...
- 用canvas制作酷炫射击游戏--part3
今天介绍下 游戏中的sprite模块,也就是构建玩家及怪物的模块.有了这个模块,就可以在咱们的游戏里加入人物了. 想必用过css的朋友都知道sprite,一种将需要加载的图片拼接在一张图里以减少请求的 ...
- 用canvas制作酷炫射击游戏--part2
今天这一部分主要讲游戏的实现原理与游戏循环的代码实现. 先说原理,大家都看过动画吧.在我看来,游戏就是玩家能人为控制动画剧情发展方向的动画.所以,我们的游戏引擎其实说白了就是个动画引擎再加上鼠标事件. ...
随机推荐
- Doxygen -- part 2
Documenting the code 这个章节涵盖两个主题: 如何在你的代码中放置注释, 一遍doxygen可以在生成的文档中囊括它们. 如何组织一个注释块的内容, 以使得输出美观. 特殊注释块 ...
- python读取文件使用相对路径的方法
场景描述: python传统的读取文件的方法,通过读取文件所在目录来读取文件,这样出现的问题是,如果文件变更了存储路径,那么就会读取失败导致报错 如下方脚本 def stepb(a):#写入txt f ...
- 线性最长cover(无讲解)
#include<bits/stdc++.h> using namespace std; ; int n,f[maxn],cover[maxn],R[maxn]; char str[max ...
- Can you answer these queries III(线段树)
Can you answer these queries III(luogu) Description 维护一个长度为n的序列A,进行q次询问或操作 0 x y:把Ax改为y 1 x y:询问区间[l ...
- php--->把json传来的stdClass Object类型转array
php把json传来的stdClass Object类型转array 1.Php中stdClass.object.array的概念 stdClass是PHP的一个基类,即一个空白的类,所有的类几乎都继 ...
- PYTHON经典算法-完美平方
问题描述: 给定一个正整数n,找到若干个完全平方数(例如:1,4,9),使得 它们的和等于n,完全平方数的个数最少. 问题示例: 给出n=12,返回3,因为12=4+4+4:给出n=13,返回2,因为 ...
- springIOC源码接口分析(七):ApplicationEventPublisher
一 定义方法 此接口主要是封装事件发布功能的接口,定义了两个方法: /** * 通知应用所有已注册且匹配的监听器此ApplicationEvent */ default void publishEve ...
- Arduino系列之LCD1602模块使用方法(一)
下面我将简单介绍LCD1602模块的使用方法: 1602液晶显示器(1602 Liquid Crystal Display,此后简称1602 LCD)是一种常见的字符液晶显示器,因其能显示16*2个字 ...
- c++中值传递,址传递,引用传递
概念详解 1. 值传递: 形参是实参的拷贝,改变形参的值并不会影响外部实参的值. 从被调用函数的角度来说,值传递是单向的(实参->形参),参数的值只能传入,不能传出: 当函数内部需要修改参数,并 ...
- vue简介,插值表达式,过滤器
目录 VUE框架介绍 what?什么是vue? why?为什么要学习vue? special特点? how如何使用? 下载安装? 导入方式? 挂在点el 插值表达式 delimiters自定义插值表达 ...