Rabbit MQ 客户端 API 进阶
之前说了一些基础的概念及使用方法,比如创建交换器、队列和绑定关系等。现在我们再来补充一下细节性的东西。
备份交换器
通过声明交换器的时候添加 alternate-exchange 参数来实现。
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
Map<String, Object> argsParam = new HashMap<>(16);
argsParam.put("alternate-exchange", "myAe");
// 声明两个交换器 normalExchange、myAe,同时将 myAe 设置为备份交换器(argsParam)
channel.exchangeDeclare("normalExchange", "direct", false, true, argsParam);
channel.exchangeDeclare("myAe", "fanout", false, true, null);
// normalExchange 绑定 normalExchange 队列、myAe 绑定 unroutedQueue 队列
channel.queueDeclare("normalQueue", false, false, true, null);
channel.queueBind("normalQueue", "normalExchange", "normalKey");
channel.queueDeclare("unroutedQueue", false, false, true, null);
channel.queueBind("unroutedQueue", "myAe", "");
上图声明了两个交换器 normalExchange、myAe 分别绑定了两个队列。如果此时发送一条消息到 nonnalExchange 上,当路由键等于"nonnalKey"的时候,消息能正确路由到 nonnalQueue 这个队列中。如果路由键设为其他值,比如"errorKey"即消息不能被正确地路由到与 normalExchange 绑定的任何队列上,此时就会发送给 myAe ,进而发送到 unroutedQueue 这个队列。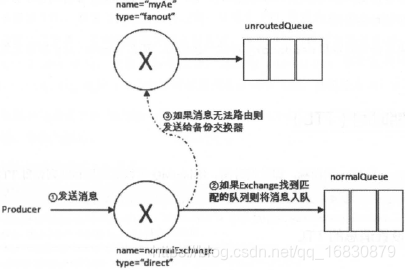
备份交换机的注意事项:
1.如果设置的备份交换器不存在,客户端和 RabbitMQ 服务端都不会有异常出现,此时消息会丢失。
2.如果备份交换器没有绑定任何队列,客户端和 RabbitMQ 服务端都不会有异常出现,此时消息会丢失。
3.如果备份交换器没有任何匹配的队列,客户端和 RabbitMQ 服务端都不会有异常出现,此时消息会丢失。
4.如果备份交换器和 mandatory 参数一起使用,那么 mandatory 参数无效。
过期时间
目前有两种方法可以设置消息的 TTL。第一种方法是通过队列属性设置,队列中所有消息都有相同的过期时间。第二种方法是对消息本身进行单独设置,每条消息的 TTL 可以不同。如果两种方法一起使用,则消息的 TTL 以两者之间较小的那个数值为准。
通过队列属性设置消息 TTL 的方法是在 channel.queueDeclare 方法中加入 x-message -ttl 参数实现的,这个参数的单位是毫秒。如果不设置 TTL.则表示此消息不会过期;如果将 TTL 设置为 0 ,则表示除非此时可以直接将消息投递到消费者,否则该消息会被立即丢弃。
// 设置队列中消息 TTL
Map<String, Object> argsParam = new HashMap<>(16);
argsParam.put("x-message-ttl", 6_000);
channel.queueDeclare("queueName", false, false, true, argsParam);
针对每条消息的设置 TTL 的方法是在 channel.basicPublish 方法中加入 expiration 的属性参数,单位为毫秒。
// 设置每一条消息 TTL
AMQP.BasicProperties properties = new AMQP.BasicProperties().builder().deliveryMode(2).expiration("6000").build();
channel.basicPublish("exchangeName", "routingKey", false, properties, "message".getBytes());
设置队列的 TTL 通过 channel.queueDeclare 方法中的 x-expires 参数(毫秒为单位)可以控制队列被自动删除前处于未使用状态的时间。
// 设置队列 TTL
Map<String, Object> argsParam = new HashMap<>(16);
argsParam.put("x-expires", 6_000);
channel.queueDeclare("queueName", false, false, true, argsParam);
死信队列
DLX,全称为 Dead-Letter-Exchange 。当消息在一个队列中变成死信(dead message)之后,它能被重新被发送到另一个交换器中,这个交换器就是 DLX ,绑定 DLX 的队列就称之为死信队列。
消息变成死信一般是由于以下几种情况:
1.消息被拒绝(Basic.Reject/Basic.Nack) ,井且设置 requeue 参数为 false;
2.消息过期;
3.队列达到最大长度。
通过在 channel.queueDeclare 方法中设置 x-dead-letter-exchange 参数来为这个队列添加 DLX。
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 创建死信交换器和正常交换器
channel.exchangeDeclare("exchange.dlx", "direct", false);
channel.exchangeDeclare("exchange.normal", "fanout", false);
// 绑定正常队列
Map<String, Object> argsParam = new HashMap<>(16);
argsParam.put("x-message-ttl", 10_000);
argsParam.put("x-dead-letter-exchange", "exchange.dlx");
argsParam.put("x-dead-letter-routing-key", "routingKey");
channel.queueDeclare("queue.normal", false, false, true, argsParam);
channel.queueBind("queue.normal", "exchange.normal", "");
// 绑定死信队列
channel.queueDeclare("queue.dlx", false, false, true, null);
channel.queueBind("queue.dlx", "exchange.dlx", "routingKey");
channel.basicPublish("exchange.normal", "rk", MessageProperties.TEXT_PLAIN, "dlx".getBytes());
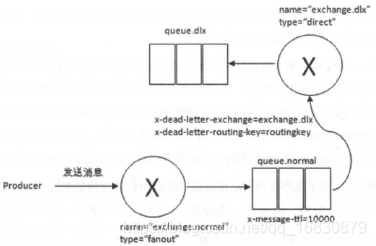
生产者首先发送一条携带路由键为 “rk” 的消息,然后经过交换器 exchange.normal 顺利地存储到队列 queue.normal 中。由于队列 queue.normal 设置了过期时间为 10s ,在这 10s 内没有消费者消费这条消息,那么判定这条消息为过期。由于设置了DLX ,过期之时,消息被丢给交换器 exchange.dlx 中,这时找到与 exchange.dlx 匹配的队列 queue.dlx ,最后消息被存储在 queue.dlx 这个死信队列中。

延迟队列
延迟队列存储的对象是对应的延迟消息,所谓"延迟消息"是指当消息被发送以后,并不想让消费者立刻拿到消息,而是等待特定时间后,消费者才能拿到这个消息进行消费。
使用场景:
1.订单系统中,一个用户下单之后通常有 30 分钟的时间进行支付,如果 30 分钟之内没有支付成功,那么这个订单将进行异常处理。这个时候就可以使用延迟队列来处理。
2.用户希望通过手机远程遥控家里的智能设备在指定的时间进行工作。这时候就可以将用户指令发送到延迟队列,当指令设定的时间到了再将指令推送到智能设备。
在 AMQP 协议中,或者 RabbitMQ 本身没有直接支持延迟队列的功能,但是可以通过前面所介绍的 DLX 和 TTL 模拟出延迟队列的功能。假设每条消息都设置为 10 秒的延迟,生产者通过 exchange.normal 这个交换器将发送的消息存储在 queue.normal 这个队列中。消费者订阅的并非是 queue.normal 这个队列,而是 queue.dlx 这个队列。当消息从 queue.normal 这个队列中过期之后被存入 queue.dlx 这个队列中,消费者就恰巧消费到了延迟 10 秒的这条消息。代码和上面实现延迟队列一样,加一个延迟队列的消费者即可就不再演示。
优先级别队列
具有高优先级的队列具有高的优先权,优先级高的消息具备优先被消费的特权。通过设置队列的 x-max-priority 参数来实现。
// 设置优先队列
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
Map<String, Object> argsParam = new HashMap<>(16);
argsParam.put("x-max-priority", 10);
channel.queueDeclare("queue.priority", false, false, true, argsParam);
上面代码声明了一个最大优先级的队列,下面我们需要在发送消息的时候设置消息的优先级,优先级默认 0 最高 10。
// 设置消息优先级
AMQP.BasicProperties properties = new AMQP.BasicProperties().builder().priority(5).build();
channel.basicPublish("exchange.priority", "routingkey", properties, "message".getBytes());
如果在消费者的消费速度大于生产者的速度且 Broker 中没有消息堆积的情况下,对发送的消息设置优先级也就没有什么实际意义。因为生产者刚发送完一条消息就被消费者消费了,那么就相当于 Broker 中至多只有一条消息,对于单条消息来说优先级是没有什么意义的。
RPC 实现
如果我们需要在远程计算机上运行一个函数并等待结果呢?嗯,这是一个不同的故事。此模式通常称为远程过程调用或 RPC。一般都不会选用消息服务来做 RPC 框架可以当作扩展知识学一学。
客户端代码
public class RabbitMqRpcClient implements AutoCloseable {
private Connection connection;
private Channel channel;
private String requestExchangeName = "exchange.rpc";
public RabbitMqRpcClient() throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setUsername("userName");
factory.setPassword("password");
factory.setHost("host");
factory.setVirtualHost("vhost");
factory.setPort(5672);
this.connection = factory.newConnection();
this.channel = connection.createChannel();
}
public String call(String message) throws Exception {
// 生成一个唯一的correlationId
String corrId = UUID.randomUUID().toString();
String queueName = this.channel.queueDeclare().getQueue();
System.out.println("+++++++++++++++++++++ 临时队列是: " + queueName);
// 发布请求消息,其中包含两个属性: replyTo和correlationId
AMQP.BasicProperties properties = new AMQP.BasicProperties().builder().correlationId(corrId).replyTo(queueName).build();
this.channel.exchangeDeclare(requestExchangeName, "direct");
this.channel.basicPublish(requestExchangeName, "rpc", properties, message.getBytes());
// 创建了 ArrayBlockingQueue,容量设置为1,因为我们只需要等待一个响应。
BlockingQueue<String> queue = new ArrayBlockingQueue<>(1);
// 为回复创建一个专用的独占队列并订阅它
String ctag = this.channel.basicConsume(queueName, true, new DeliverCallback() {
@Override public void handle(String consumerTag, Delivery delivery) throws IOException {
// 检查 correlationId 是否是我们正在寻找的那个。如果是这样,它会将响应置于 BlockingQueue
if (delivery.getProperties().getCorrelationId().equals(corrId)) {
queue.offer(new String(delivery.getBody()));
}
}
}, new CancelCallback() {
@Override public void handle(String consumerTag) throws IOException {
System.out.println("+++++++++++++++++++ consumerTag +++++++++++++++++++++++" + consumerTag);
}
});
// 在这一点上,我们可以坐下来等待正确的响应到来
String result = queue.take();
this.channel.basicCancel(ctag);
// 最后,我们将响应返回给用户
return result;
}
@Override public void close() throws Exception {
if (null != this.channel) {
this.channel.close();
}
if (null != this.connection) {
connection.close();
}
}
public static void main(String[] args) {
// 建立了一个连接和渠道。
try (RabbitMqRpcClient clinet = new RabbitMqRpcClient()) {
// 调用方法生成实际的 RPC 请求
String call = clinet.call("1");
System.out.println("++++++++++++++++++++++++++ 服务端的返回是: " + call);
} catch (Exception e) {
e.printStackTrace();
}
}
}
服务端代码
public class RabbitMqRpcServer {
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setUsername("userName");
factory.setPassword("password");
factory.setHost("host");
factory.setVirtualHost("vhost");
factory.setPort(5672);
// 建立连接,通道和声明队列
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare("exchange.rpc", "direct");
channel.queueDeclare("queue.rpc", false, false, true, null);
channel.queueBind("queue.rpc", "exchange.rpc", "rpc", null);
channel.basicQos(1);
// 我们使用 basicConsume 来访问队列,我们以对象(DeliverCallback)的形式提供回调,它将完成工作并发回响应。
DeliverCallback deliverCallback = new DeliverCallback() {
@Override public void handle(String consumerTag, Delivery delivery) throws IOException {
AMQP.BasicProperties properties = new AMQP.BasicProperties.Builder()
.correlationId(delivery.getProperties().getCorrelationId()).build();
String response = "";
try {
String message = new String(delivery.getBody());
int n = Integer.parseInt(message);
response = "client param is: " + n + ", server 运行函数返回!";
} catch (Exception e) {
e.printStackTrace();
} finally {
// 完成工作并发回响应。
System.out.println("ReplyTo: " + delivery.getProperties().getReplyTo());
channel.basicPublish("", delivery.getProperties().getReplyTo(), properties, response.getBytes());
}
}
};
channel.basicConsume("queue.rpc", true, deliverCallback, new CancelCallback() {
@Override public void handle(String consumerTag) throws IOException {
}
});
}
}
运行结果
持久化
持久化可以提高 RabbitMQ 的可靠性,以防在异常情况(重启、关闭、右机等)下的数据丢失。
交换器的持久化是通过在声明队列是将 durable 参数置为 true 实现的,如果交换器不设置持久化,那么在 RabbitMQ 服务重启之后,相关的交换器元数据会丢失,不过消息不会丢失,只是不能将消息发送到这个交换器中了。对一个长期使用的交换器来说,建议将其置为持久化的。
队列的持久化是通过在声明队列时将 durable 参数置为 true 实现的。如果队列不设置持久化,那么在 RabbitMQ 服务重启之后,相关队列的元数据会丢失,此时数据也会丢失。队列的持久化能保证其本身的元数据不会因异常情况而丢失,但是并不能保证内部所存储的消息不会丢失。要确保消息不会丢失,需要将其设置为持久化。通过将消息的投递模式(BasicPropert i es 中的 deliveryMode 属性)设置为 2 即可实现消息的持久化。
将所有的消息都设直为持久化,但是这样会严重影响 RabbitMQ 的性能(随机)。写入磁盘的速度比写入内存的速度慢得不只一点点。对于可靠性不是那么高的消息可以不采用持久化处理以提高整体的吞吐量。在选择是否要将消息持久化时,需要在可靠性和吐吞量之间做一个权衡。
生产者确认
仔细想一想我们还会遇到一个问题,当消息的生产者将消息发送出去之后,消息到底有没有正确地到达服务器呢?默认情况下发送消息的操作是不会返回任何信息给生产者的,也就是默认情况下生产者是不知道消息有没有正确地到达服务器。
RabbitMQ 针对这个问题,提供了两种解决方式:
1.事务机制
2.发送方确认(publisher confirm)机制
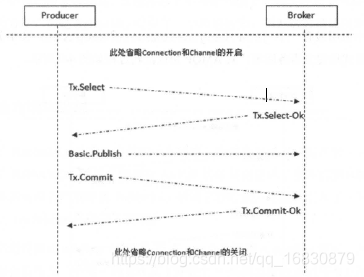
事务机制:RabbitMQ 客户端中与事务机制相关的方法有三个: channel.txSelect、channel.txCommit 和 channel.txRollback。
1.channel.txSelect 将 channel 设置为事务模式
2.channel.txCommit 提交事务
3.channel.txRollback 回滚事务
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
try {
// 开启事务
channel.txSelect();
channel.basicPublish("exchangeName", "routingKey", null, "message".getBytes());
} catch (Exception e) {
// 回滚事务
channel.txRollback();
}
发送方确认机制: 一旦信道进入 confmn 模式,所有在该信道上面发布的消息都会被指派一个唯一的 IDC 从 l 开始),一旦消息被投递到所有匹配的队列之后,RabbitMQ 就会发送一个确认 CBasic.Ack) 给生产者(包含消息的唯一 ID) ,这就使得生产者知晓消息已经正确到达了目的地了。此外 RabbitMQ 也可以设置 channel.basicAck 方法中的 multiple 参数,表示到这个序号之前的所有消息都己经得到了处理。
// 单条发送确认
try {
// 将信道设置为 publisher confirm 模式
channel.confirmSelect();
channel.basicPublish("exchangeName", "routingKey", null, "message".getBytes());
// 普通发送方确认模式;消息到达交换器,就会返回 true
if (!channel.waitForConfirms()) {
System.out.println("发送消息失败!");
}
} catch (Exception e) {
e.printStackTrace();
}
// 批量发送确认
try {
// 将信道设置为 publisher confirm 模式
channel.confirmSelect();
for (int i = 0; i < 100; i++) {
channel.basicPublish("exchangeName", "routingKey", null, "message".getBytes());
}
channel.waitForConfirmsOrDie();
} catch (Exception e) {
e.printStackTrace();
}
// 回调方式确认
channel.addConfirmListener(new ConfirmListener() {
@Override public void handleNack(long deliveryTag, boolean multiple) throws IOException {
System.out.println("handleNack message: " + deliveryTag + "----" + multiple);
}
@Override public void handleAck(long deliveryTag, boolean multiple) throws IOException {
System.out.println("handleAck message: " + deliveryTag + "----" + multiple);
}
});
可以看上面代码 publisher confmn 模式是每发送一条消息后就调用 channel.waitForConfirms 方法,之后等待服务端的确认,这实际上是一种串行同步等待的方式。事务机制和它一样,发送消息之后等待服务端确认,之后再发送消息。两者的存储确认原理相同。但是 publisher confum 机制发送一条消息需要通信交互的命令是 2 条: Basic.Publish 和 Basic.Ack; 事务机制是 3 条:Basic.Publish 、Tx.Commmit/.Commit-Ok (或者 Tx.Rollback/.Rollback-Ok) ,事务机制多了一个命令帧报文的交互,所以 QPS 会略微下降。
事务机制和 publisher confirm 机制确保的是消息能够正确地发送至 RabbitMQ,这里的"发送至 RabbitMQ" 的含义是指消息被正确地发往至 RabbitMQ 的交换器,如果此交换器没有匹配的队列,那么消息也会丢失。所以在使用这两种机制的时候要确保所涉及的交换器能够有匹配的队列. 发送方要配合 mandatory 参数或者备份交换器一起使用来提高消息传输的可靠性。
消息分发
当 RabbitMQ 队列拥有多个消费者时,队列收到的消息将以轮询(round-robin)的分发方式发送给消费者。默认情况下,如果有 n 个消费者,那么 RabbitMQ 会将第 m 条消息分发给第 m%n (取余的方式) 个消费者,RabbitMQ 不管消费者是否消费并己经确认了消息。如果某些线程消费者任务繁重,来不及消费那么多的消息,而某些其他线程消费者由于某些原因(比如业务逻辑简单、机器性能卓越等)很快地处理完了所分配到的消息,进而进程空闲,这样就会造成整体应用吞吐量的下降。
那么该如何处理这种情况呢?这里就要用到 channel.basicQos(int prefetchCount) 这个方法。 channel.basicQos 方法允许限制信道上的消费者所能保持的最大未确认消息的数量。比如 channel.basicQos(10) 如果给该消费者发送了 10 条消息并且都在处理等待中则 RabbitMQ 则不会再改此消费者发送数据,设置为 0 表示无上限。
channel.basicQos 有三个重载方法。
public void basicQos(int prefetchCount) throws IOException;
public void basicQos(int prefetchCount, boolean global) throws IOException;
public void basicQos(int prefetchSize, int prefetchCount, boolean global) throws IOException;
参数说明:
1.prefetchCount: 当为 0 时表示没有上限,
2.prefetchSize: 当为 0 时表示没有上限,表示消费者所接收未确认消息的的上限。
3.global: true 表示信道上所有的消费者都需要遵从 prefetchCount 的限定值, false 表示信道上新的消费者需要遵从 prefetchCount 的限定值。
消息传输可靠性
消息可靠传输一般是业务系统接入消息中间件时首要考虑的问题,一般消息中间件的消息传输保障分为三个层级。
1.At most once: 最多一次。消息可能会丢失,但绝不会重复传输。
2.At least once: 最少一次。消息绝不会丢失,但可能会重复传输。
3.Exactly once: 恰好一次。每条消息肯定会被传输一次且仅传输一次。
RabbitMQ 支持其中的"最多一次"和"最少一次"。其中"最少一次"该怎么尽可能的保证消息传递的可靠性呢?
1.息生产者需要开启事务机制或者 publisher confirm 机制,以确保消息可以可靠地传输到 RabbitMQ 中。
2.生产者需要配合使用 mandatory 参数或者备份交换器来确保消息能够从交换器路由到队列中,进而能够保存下来而不会被丢弃。
3.消息和队列都需要进行持久化处理,以确保 RabbitMQ 服务器在遇到异常情况时不会造成消息丢失。
4.消费者在消费消息的同时需要将 autoAck 设置为 false ,然后通过手动确认的方式去确认己经正确消费的消息,以避免在消费端引起不必要的消息丢失。
总结
提升数据可靠性:
1.设置 mandatory 参数或者备份交换器。
2.设置 publisher confirm 机制或者事务机制。
3.设置交换器、队列和消息都为持久化。
4.设置消费端对应的 autoAck 参数为 false 井在消费完消息之后再进行消息确认。
Rabbit MQ 客户端 API 进阶的更多相关文章
- Rabbit MQ 客户端 API 开发
项目开始 第一步首先需要引入对应的 jar 包 <!-- https://mvnrepository.com/artifact/com.rabbitmq/amqp-client --> & ...
- Rabbit MQ 学习参考
网上的教程虽然多,但是提供demo的比较少,或者没有详细的说明,因此,本人就照着网上的教程做了几个demo,并把代码托管在码云,供有需要的参考. 项目地址:https://gitee.com/dhcl ...
- 在 Windows 上安装Rabbit MQ 指南
rabbitMQ是一个在AMQP协议标准基础上完整的,可服用的企业消息系统.他遵循Mozilla Public License开源协议.采用 Erlang 实现的工业级的消息队列(MQ)服务器. Ra ...
- (转)在 Windows 上安装Rabbit MQ 指南
rabbitMQ是一个在AMQP协议标准基础上完整的,可服用的企业消息系统.他遵循Mozilla Public License开源协议.采用 Erlang 实现的工业级的消息队列(MQ)服务器. Ra ...
- celery rabbit mq 详解
Celery介绍和基本使用 Celery 是一个 基于python开发的分布式异步消息任务队列,通过它可以轻松的实现任务的异步处理, 如果你的业务场景中需要用到异步任务,就可以考虑使用celery, ...
- Rabbit MQ 入门指南
rabbitMQ是一个在AMQP协议标准基础上完整的,可服用的企业消息系统.他遵循Mozilla Public License开源协议.采用 Erlang 实现的工业级的消息队列(MQ)服务器. Ra ...
- Spring Boot:使用Rabbit MQ消息队列
综合概述 消息队列 消息队列就是一个消息的链表,可以把消息看作一个记录,具有特定的格式以及特定的优先级.对消息队列有写权限的进程可以向消息队列中按照一定的规则添加新消息,对消息队列有读权限的进程则可以 ...
- Spring boot集成Rabbit MQ使用初体验
Spring boot集成Rabbit MQ使用初体验 1.rabbit mq基本特性 首先介绍一下rabbitMQ的几个特性 Asynchronous Messaging Supports mult ...
- 使用Rabbit MQ消息队列
使用Rabbit MQ消息队列 综合概述 消息队列 消息队列就是一个消息的链表,可以把消息看作一个记录,具有特定的格式以及特定的优先级.对消息队列有写权限的进程可以向消息队列中按照一定的规则添加新消息 ...
随机推荐
- delphi基础篇之数据类型之三:3.结构类型(Struct)
3.结构类型(Struct) 结构类型在内存中存储一组相关的数据项,而不是像简单数据类型那样单一的数值.结构数据类型包括:集合类型.数组类型.记录类型.文件类型.类类型.类引用类型和接口类型等.
- https://blog.csdn.net/rubbertree/article/details/88877262
本文链接:https://blog.csdn.net/rubbertree/article/details/88877262 https://blog.csdn.net/mingtianhaiyouw ...
- Codeforces 1191B Tokitsukaze and Mahjong
题目链接:http://codeforces.com/problemset/problem/1191/B 题意:类似于麻将,三个一样花色一样数字的,或者三个同花顺就赢了,新抽的能当任何类型,问至少几个 ...
- centos_mysql踩坑
1 mysql安装 a: #wget http://dev.mysql.com/get/mysql-community-release-el7-5.noarch.rpm b:rpm -ivh mysq ...
- MySQL数据库(三)—— 表相关操作(二)之约束条件、关联关系、复制表
表相关操作(二)之约束条件.关联关系.复制表 一.约束条件 1.何为约束 除了数据类型以外额外添加的约束 2.约束条件的作用 为了保证数据的合法性,完整性 3.主要的约束条件 NOT NULL # ...
- npm和cnpm的安装(window)
一:安装node.js 1.进入https://nodejs.org/en/中下载自己电脑相对应的node.js. 2.将下载下来的node.js进行安装. 3.利用管理员身份打开cmd,在里面输入n ...
- web项目中实现页面跳转的两种方式
<a href="javascript:"></a>跳转在网页本身,URL不改变 <a href="#"></a> ...
- java-day02
数据类型自动转换 要求:数据范围从小到大 数据类型强制类型转换 格式:范围小的数据类型 范围小的变量名 = (范围小的数据类型)原范围大的数据 注意事项: 1.可以会造成数据溢出或者是精度损失. 2. ...
- JS设置浏览器缓存,以及常用函数整理
//设置缓存 function set_cache(key,value){ if(key=='') return false; localStorage.setItem(key, value); } ...
- css渐变写法 从左到右渐变三种颜色示例;
background:linear-gradient(to right,#7f06a8,#a02bc2,#7f06a8)