如何玩转跨库Join?跨数据库实例查询应用实践
背景
随着业务复杂程度的提高、数据规模的增长,越来越多的公司选择对其在线业务数据库进行垂直或水平拆分,甚至选择不同的数据库类型以满足其业务需求。原本在同一数据库实例里就能实现的SQL查询,现在需要跨多个数据库实例才能完成。业务的数据被“散落”在各个地方,如何方便地对这些数据进行汇总关联查询,已经成为困扰用户的一大难题。
针对这类问题,传统的解决方案需要用户提前将所有实例的数据提前汇集到同一处,然后再做离线查询分析。为此,用户需要维护数据迁移链路,购买机器资源存储汇集起来的数据,付出大量的资源和运维成本。不仅如此,数据迁移也意味着数据延迟,刚刚产生的在线业务数据,需要“等一会”甚至“等一天”才能去做分析,无法满足实时性需求。
为了解决跨数据库实例及时查询的难题,阿里云DMS(数据管理)推出了跨实例查询服务。
什么是跨实例查询服务
跨实例查询服务为不同环境下的在线异构数据源,提供及时的关联查询服务。不论数据库是MySQL、SQLServer、PostgreSQL还是Redis,不论数据库实例部署在哪个阿里云region,无需数据汇集,仅通过一条SQL就能实现这些数据库实例之间的关联查询。
不仅如此,数据库实例也可以部署在不同的资源环境中,除了RDS之外,我们也支持ECS上的自建数据库、具有公网ip的自建数据库、用户本地IDC自建数据库、甚至是部署在其他云厂商的数据库。
功能特性
在线数据及时查询
目前大多数数据分析的解决方案需要将 OLTP 数据库的数据导出至离线数据系统再进行分析,但这种方案很难满足实时性的要求,同时在数据导出至离线系统时也存在数据丢失的风险。
DMS的跨实例查询服务,无需用户迁移任务,直接编写一条SQL,就能实现多个在线数据库的直接关联分析。由于无需数据同步,降低了业务架构的复杂性,同时也大大节省用户持有离线计算资源的预算和运维成本。
DBLink
熟悉Oracle的人应该知道,我们可以在当前登录的Oracle上,建立一个DBLink指向另一个远程的Oracle数据库表。在跨实例查询服务中,我们重新定义了DBLink的概念,它是一个指向用户的任意数据库实例的虚拟连接,是数据库实例的别名。例如,对于MySQL来说,DBLink和ip/port一一对应。借助DBLink,即可实现对任意数据源的SQL访问。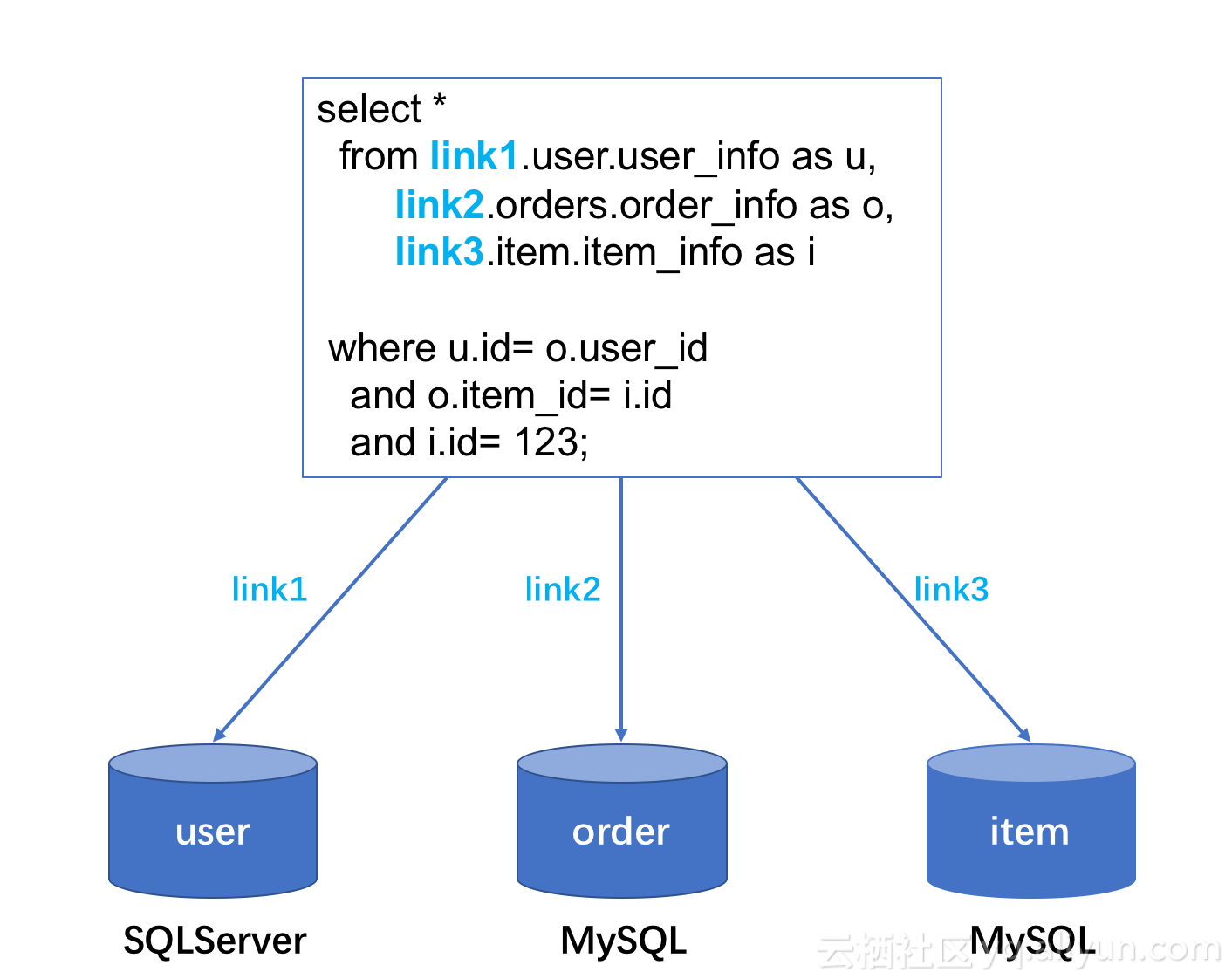
支持多种关系型数据库
目前已支持MySQL、SQLServer、PostgreSQL等多种关系型数据库。
支持SQL方式访问NoSQL
除了关系型数据库之外,跨实例查询还支持以SQL方式访问Redis等NoSQL数据库。由于支持了SQL语法,也可以实现RDBMS和NoSQL之间关联查询。是的,你没看错,一条SQL就能实现MySQL和Redis之间的关联查询。
支持跨地域以及混合云查询
企业发展到一定阶段,用户量、业务量不断攀升,原来的单机房容量已经不能满足业务发展的需求,再结合容灾、高可用等因素,通常会选择跨region部署,也叫单元化部署。同时,不少企业也需要将业务拓展到海外,通过本地就近部署,为国外用户提供更好的体验。类似这种水平拆分带来的问题就是,如何对全局的业务数据进行统一的汇总关联查询。
借助DMS跨实例查询服务,无论您的数据库实例部署在阿里云的哪个region,无需跨region的数据迁移,即可实现所有region数据的统一查询。
除了阿里云RDS,我们也支持用户部署在阿里云ECS上的各种数据库。不仅如此,如果您的数据库部署在本地IDC机房,甚至其他云厂商,都可以通过跨实例查询服务,实现这些混合云场景的跨实例关联查询。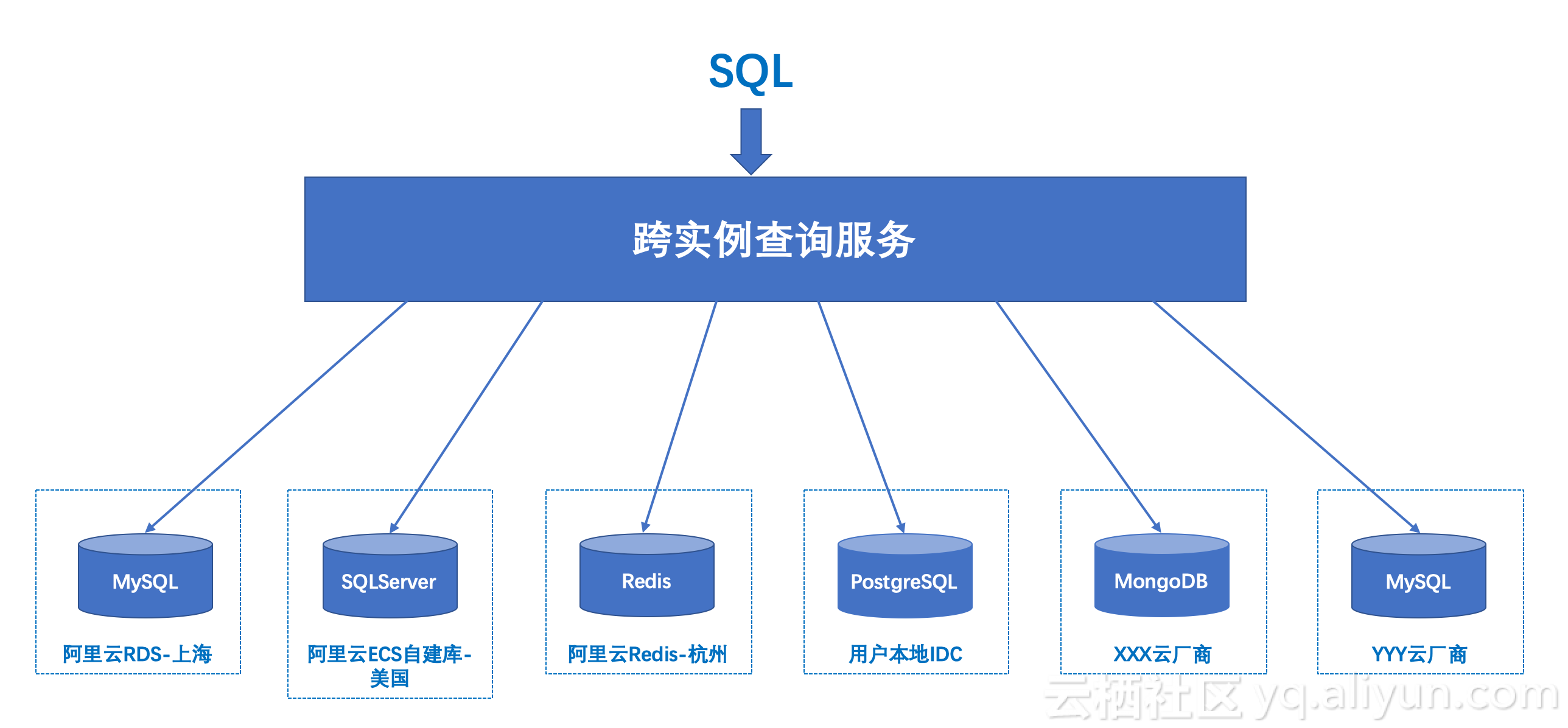
跨实例数据导入导出
insert into b select * from a;
众所周知,这条SQL语句可以将表a的数据导出到表b中,但如果a表和b表不在同一个数据库实例上,那这条sql就无能为力了。
跨实例查询服务的出现,打破了实例与实例之间数据导入导出的边界。它可以将数据从一个MySQL实例的表导出到另外一个MySQL实例的表中;也可以将SQLServer表和PostgreSQL表关联查询的结果,导出到MySQL实例的表中,就是这么灵活。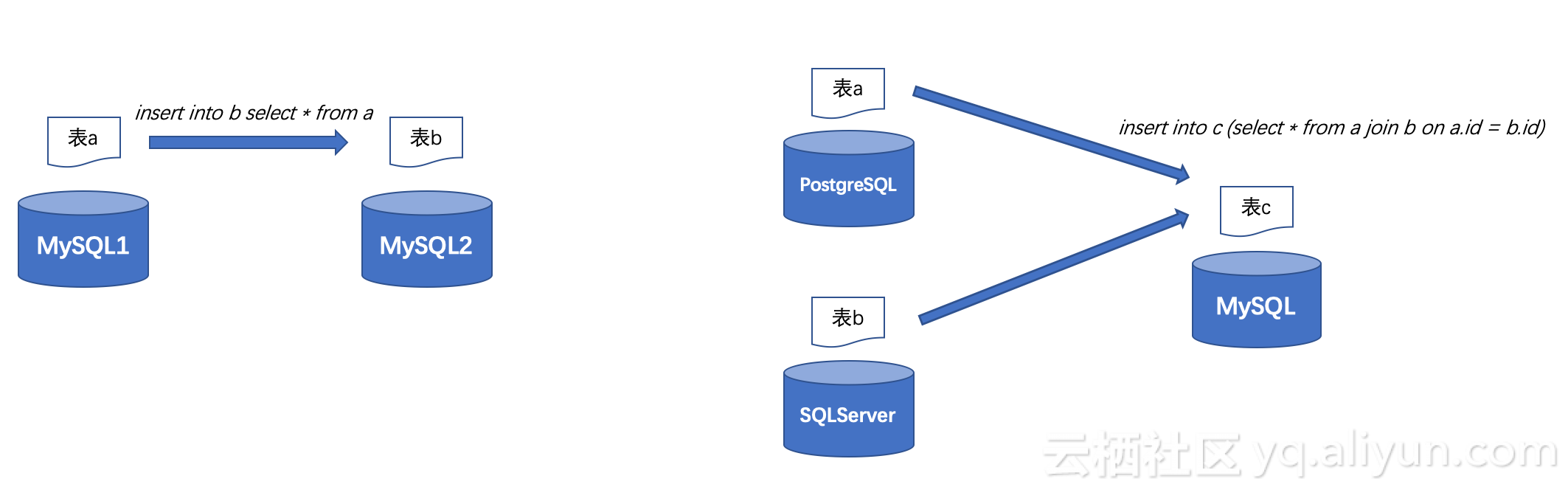
兼容标准SQL
通过标准的SQL语句,即可实现跨实例查询。同时跨实例查询服务高度兼容MySQL,支持MySQL协议,以及各种常用函数和语法。您可通过JDBC/ODBC驱动连接到跨实例查询服务;也可以使用各种MySQL GUI工具来管理各种数据源;当然,您也可以在DMS跨实例查询控制台上直接使用。
Serverless架构
跨实例查询是无服务器化的在线数据库关联查询服务。用户无需预购计算资源、无需维护资源、没有运维和升级成本,随时随地使用。
高性能低延迟
跨实例查询服务底层基于强大的MPP计算引擎,持续不断地对SQL查询进行优化,包括pushdown、join算法、执行计划缓存、Meta缓存、本地调度、连接池等技术。目前单表查询以及跨实例的多表关联查询,都能在毫秒级完成。
技术架构
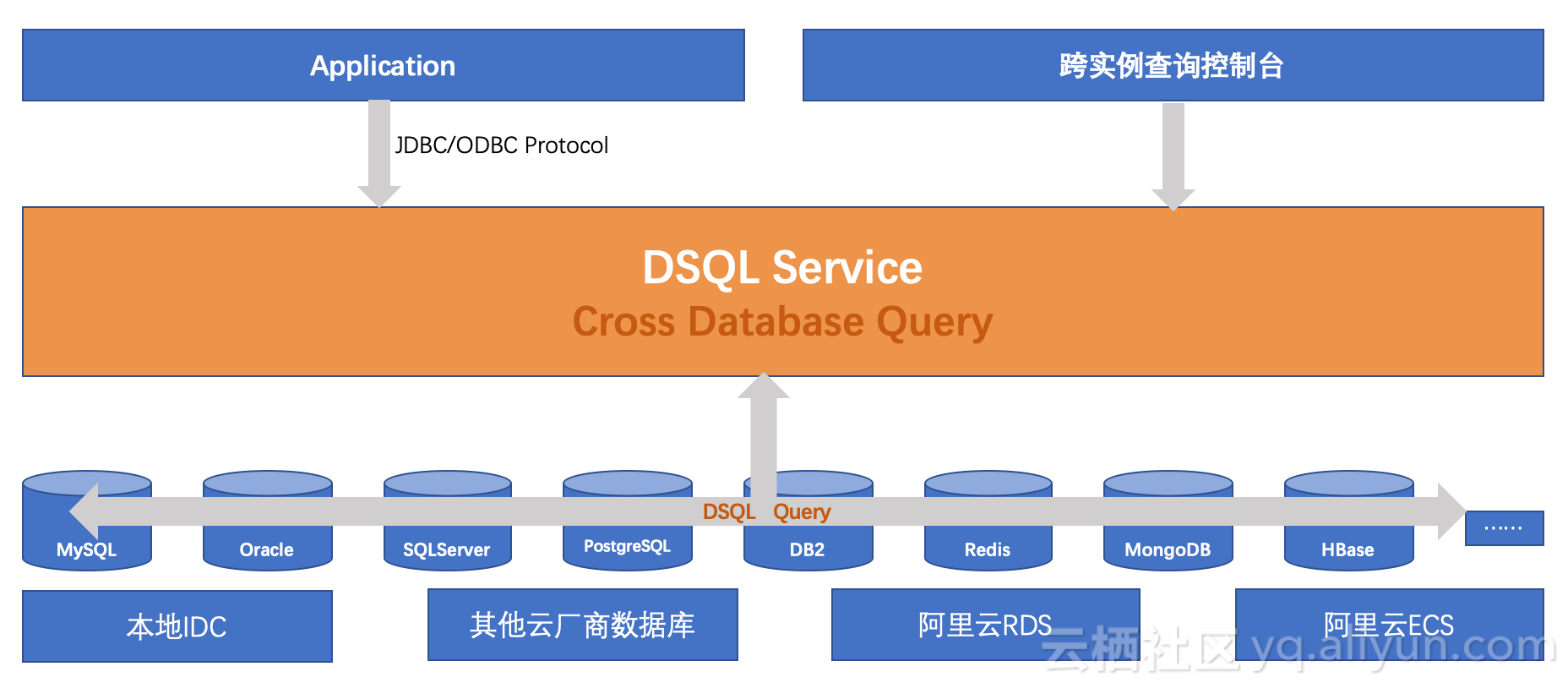
用户可以在应用程序中,直接使用MySQL JDBC驱动连接跨实例查询服务,进行跨实例查询。当然,我们也提供了控制台页面,直接输入SQL即可执行。
应用场景
垂直拆分后的跨数据库查询
某电商公司原先将会员、订单、商品等数据都存放在一个数据库实例中,但业务发展迅猛,访问量极速增长,导致数据库容量及性能遭遇瓶颈,因此用户决定对架构进行垂直拆分,将会员、商品、订单数据垂直拆分至三个数据库实例中。此时业务上需要展示某个品类商品的售卖订单量,原本在同一数据库里的查询,要变成跨两个数据库实例的查询。业务上要怎么进行关联查询?
用户首先想到的方法是,对现有业务代码进行重构,分别从两个数据库查询数据,然后在业务代码中进行join关联。那么问题来了,如果采用这个解决方案,业务上那么多查询改造起来,拆分难度极大,操作起来过于复杂。跨库join操作又没有非常高效的办法,需要从各个业务库迭代查询,查询效率也会有一定影响。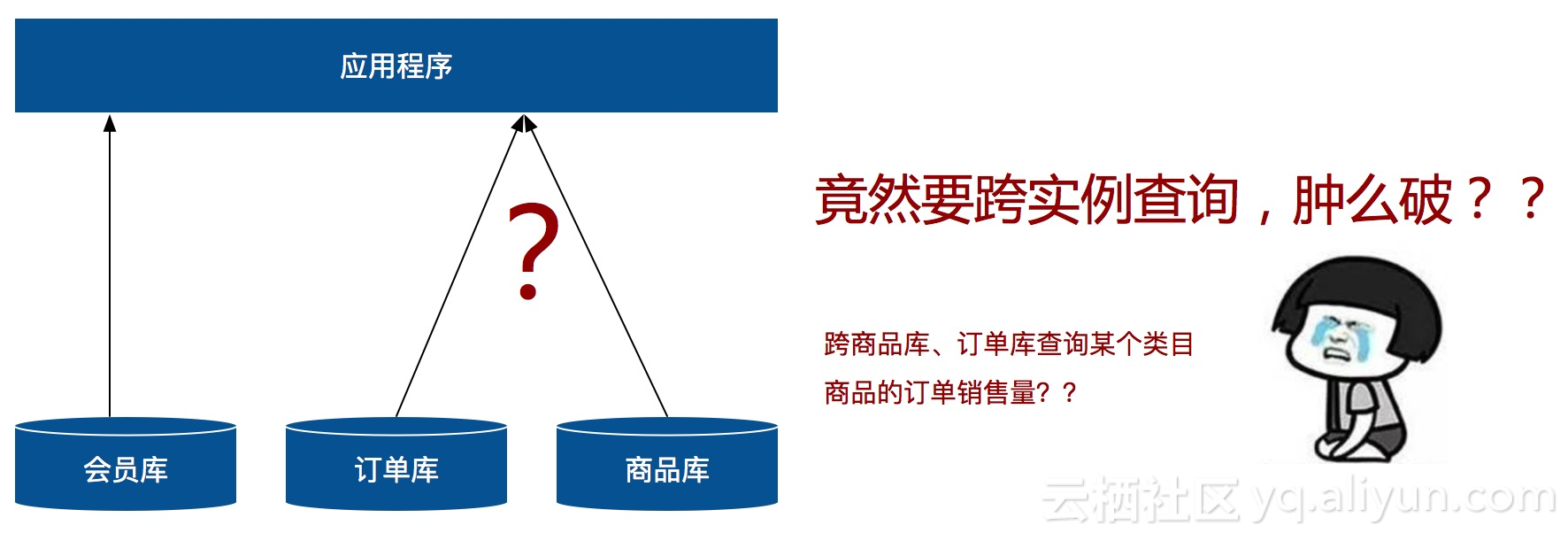
我们发现用户遇到的其实就是典型的跨实例查询问题。目前,阿里云DMS跨实例查询服务已经支持跨多个数据库实例的SQL查询的能力,用户利用一条SQL即可解决上述难题。不仅能够满足“跨库Join”这一核心诉求,还能极大地简化用户的技术方案。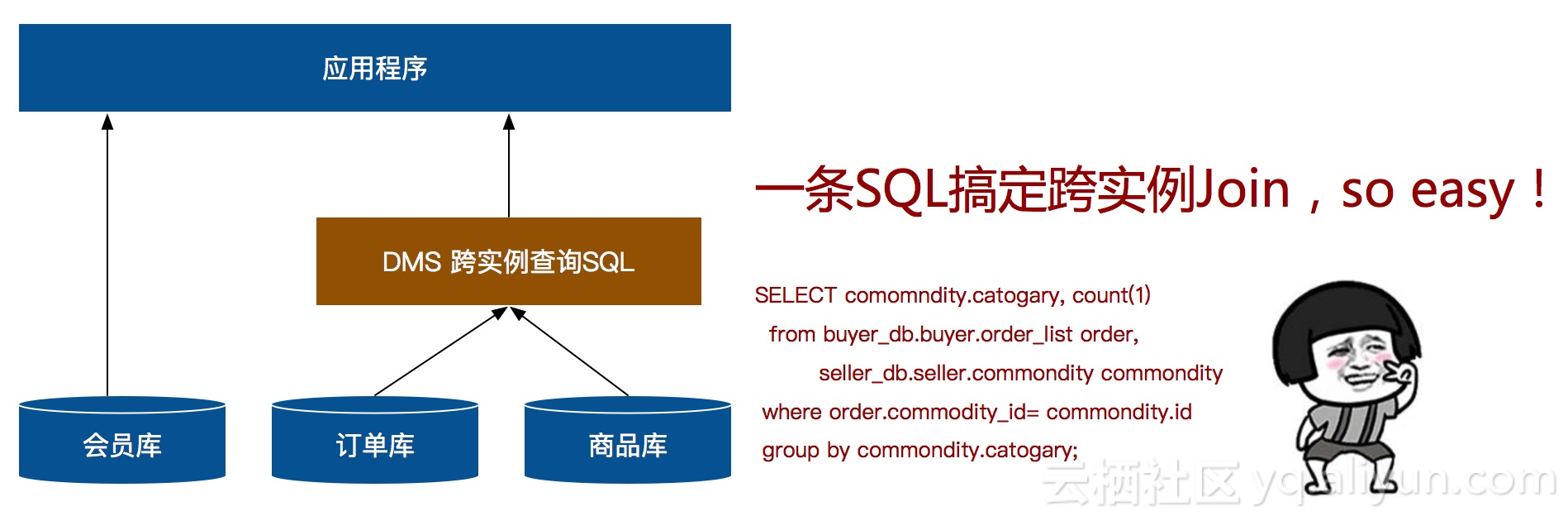
水平拆分后的跨数据库查询
某酒店在多个城市都有对应的门店,其数据库在每个城市也会单独部署一套,业务上有对多个城市全局数据查询的诉求。同样,现在越来越多的互联网行业开始引入单元化架构,在每个城市会单独部署机房和数据库,进行多单元数据汇总查询的需求也越来越强。
为了满足云上这些跨单元、跨region的数据库查询需求,跨实例查询服务打通region之间的屏障,用户通过一条SQL就能实现这些需求。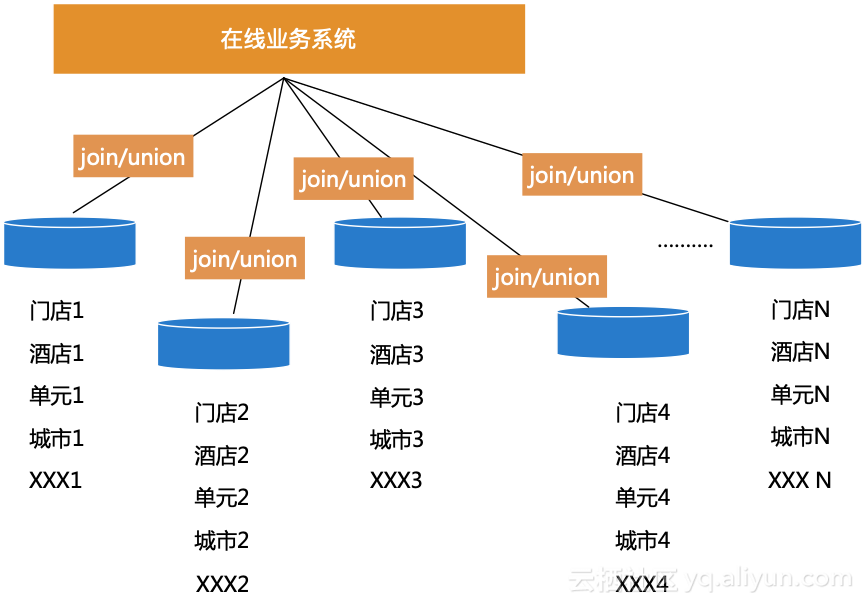
异构数据库的关联查询
某公司考虑成本和未来可扩展性,正在将业务数据从SQLServer迁移到MySQL上。在这期间,必然存在某些业务子系统仍然在SQLServer上,另外一些业务子系统已经全部迁移到MySQL上,这时两个子系统之间的联合查询,就可以借助阿里云的跨实例查询服务实现。不仅如此,在迁移过程中,还可以通过跨实例查询服务,来校验SQLServer和MySQL上的数据是否一致。
混合云场景的关联查询
某游戏公司,由于各种原因,同时保有阿里云、腾讯、UCloud、AWS等环境的数据库实例,同时在自己自建的IDC也部署了部分数据库。业务的数据如此分散,单是统计一下当前游戏在线用户数,都要分别到各个环境去查询一遍再做汇总。借助阿里云跨实例查询服务,一条SQL就能实现跨云厂商和IDC之间的关联查询。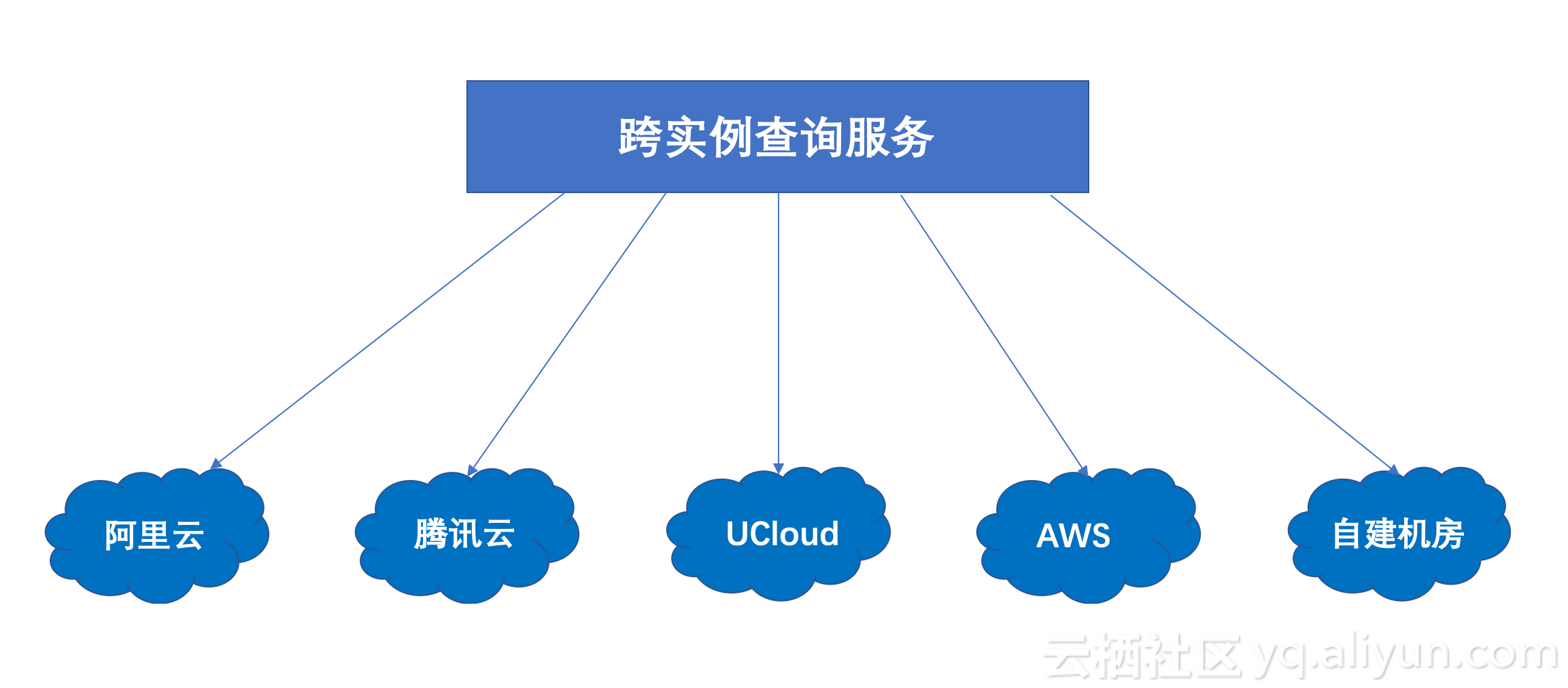
小结
阿里云DMS(数据管理)跨实例查询服务,不仅覆盖了异构数据源关联查询的场景,还解决了跨region、跨云的数据库关联查询的难题。不仅如此,我们对查询性能进行了大幅优化,使得大部分查询能在毫秒级完成。用户无需通过数据汇集,即可通过标准的SQL实现跨实例的交叉查询。
如何玩转跨库Join?跨数据库实例查询应用实践的更多相关文章
- 实现数据库的跨库join
功能需求 首先要理解原始需求是什么,为什么要跨库join.举个简单的例子,在日志数据库log_db有一份充值记录表pay_log,里面的用户信息只有一个userid:而用户的详细信息放在主库main_ ...
- 2020-07-07:mysql如何实现跨库join查询?
福哥答案2020-07-07: 1.同服务跨库.表名称带上库名.SELECT * FROM 数据库名称1.表名称 JOIN 数据库名称2.表名称 ON 数据库名称1.表名称.tid = 数据库名称2. ...
- Postgresql ODBC驱动,用sqlserver添加dblink跨库访问postgresql数据库
在同样是SQLserver数据库跨库访问时,只需要以下方法 declare @rowcount int set @rowcount =(select COUNT(*) from sys.servers ...
- mysql 跨库JOIN
现有两台MYSQL数据库 一台是192.168.1.1 端口3306 上有数据库DB1 有表TABLE1一台是192.168.1.2 端口3307 上有数据库DB2 有表TABLE2192.168.1 ...
- php使用mysql扩展库链接mysql数据库(查询)
php链接数据库可以使用mysql扩展库,mysqli,pdo这几种方式,相比java而言要麻烦一点,因为它不像java那么统一.从代码的难易程度来说php的确要简单许多.步骤大体如下 1.打开数据库 ...
- Python 使用PyMySql 库 连接MySql数据库时 查询中文遇到的乱码问题(实测可行) python 连接 MySql 中文乱码 pymysql库
最近所写的代码中需要用到python去连接MySql数据库,因为是用PyQt5来构建的GUI,原本打算使用PyQt5中的数据库连接方法,后来虽然能够正确连接上发现还是不能提交修改内容,最后在qq交流群 ...
- 一条SQL完成跨数据库实例Join查询
背景 随着业务复杂程度的提高.数据规模的增长,越来越多的公司选择对其在线业务数据库进行垂直或水平拆分,甚至选择不同的数据库类型以满足其业务需求.原本在同一数据库实例里就能实现的SQL查询,现在需要跨多 ...
- 统计分析: 跨库多表join
mysql中如果多个库在一个实例上, 可以进行多表的跨库Join, 但是如果后期数据库分隔到不同的实例机器上,有查询问题 mysql的查询优化器没有其他商业数据库做的好, 用来CRUD还行, 但是做大 ...
- Yii2 跨库orm实现
近期在对公司的Yii2项目进行子系统拆分,过度阶段难免会有一些跨库操作,原生语句还好,加下库名前缀就可以了,可是到了orm问题就来了,特别是用到model做查询的时候,现在来记录一下跳过的坑, 像下面 ...
随机推荐
- HSF简单实现记录(基于 Pandora Boot 开发)
文章目录 声明 注意 安装轻量配置中心 启动轻量配置中心 配置 hosts 结果验证 开发工具准备 在 Maven 中配置 EDAS 的私服地址 验证配置是否成功 开发 demo下载 服务注册与发现 ...
- 2015ACM/ICPC亚洲区沈阳站重现赛-HDU5512-Pagodas-gcd
n pagodas were standing erect in Hong Jue Si between the Niushou Mountain and the Yuntai Mountain, l ...
- Codeforces 1168A Increasing by Modulo
题目链接:http://codeforces.com/problemset/problem/1168/A 题意:给一个数组,数组中元素范围为0~n,每次你可以选择若干元素进行(ai+1)%m的操作,问 ...
- 网络安全系列 之 TLS/SSL基本原理
1. TLS/SSL基本工作方式: TLS/SSL的功能实现主要依赖于三类基本算法(参见"网络安全系列 之 密码算法"): 非对称加密算法:实现身份认证和密钥协商 对称加密算法: ...
- Eclipse代替Oracle接管Java EE
Eclipse Foundation接替Oracle成为Java EE的新东家,Oracle不再管理Java EE. 作为采用的一部分,Java EE可能会更换新名称,Oracle建议在其建议中使用J ...
- eclipse导入别人项目配置tomcat和jdk
1.file--import--General--Existing Projiect into Workspace-- 2.导入项目成功后,项目会有错误,需重新进行tomcat及jdk的配置 项目名右 ...
- 【ARC073F】Many Moves
题目 一个显然的\(dp\),设\(dp_{i,j}\)表示其中一个棋子在\(x_i\)点,另一个棋子在\(j\)点的最小花费 显然\(dp_{i,j}\)有两种转移 第一种是把\(x_i\)上的棋子 ...
- tarjan模板 强联通分量+割点+割边
// https://www.cnblogs.com/stxy-ferryman/p/7779347.html ; struct EDGE { int to, nt; }e[N*N]; int hea ...
- iOS开发系列-打印内存地址
打印内存地址 基本数据类型 定义一个基本数据类型,会根据变量类型分配对应的内存空间.比如定义一个int类型的变量a. int a = 10; 内存如下 输入变量a在内存中内存地址 NSLog(@&qu ...
- sleep()与wait()的区别
①sleep()实现线程阻塞的方法,我们称之为“线程睡眠”,方式是超时等待,怎么理解?就是sleep()通过传入“睡眠时间”作为方法的参数,时间一到就从“睡眠”中“醒来”: ②wait()方法实现线程 ...