基于MHA的MYSQL高可用方案
一、MHA 简介
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
• 自动故障检测和自动故障转移
MHA能够在一个已经存在的复制环境中监控MySQL,当检测到Master故障后能够实现自动故障转移,通过鉴定出最“新”的Salve的relay log,并将其应用到所有的Slave,这样MHA就能够保证各个slave之间的数据一致性,即使有些slave在主库崩溃时还没有收到最新的relay log事件。一个slave节点能否成为候选的主节点可通过在配置文件中配置它的优先级。由于master能够保证各个slave之间的数据一致性,所以所有的slave节点都有希望成为主节点。在通常的replication环境中由于复制中断而极容易产生的数据一致性问题,在MHA中将不会发生。
• 交互式(手动)故障转移
MHA可以手动地实现故障转移,而不必去理会master的状态,即不监控master状态,确认故障发生后可通过MHA手动切换
• 在线切换Master到不同的主机
MHA能够在0.5-2秒内实现切换,0.5-2秒的写阻塞通常是可接受的,所以你甚至能在非维护期间就在线切换master。诸如升级到高版本,升级到更快的服务器之类的工作,将会变得更容易
优势:
• 自动故障转移快
• 主库崩溃不存在数据一致性问题
• 配置不需要对当前mysql环境做重大修改
• 不需要添加额外的服务器(仅一台manager就可管理上百个replication)
• 性能优秀,可工作在半同步复制和异步复制,当监控mysql状态时,仅需要每隔N秒向master发送ping包(默认3秒),所以对性能无影响。你可以理解为MHA的性能和简单的主从复制框架性能一样。
• 只要replication支持的存储引擎,MHA都支持,不会局限于innodb
组成:
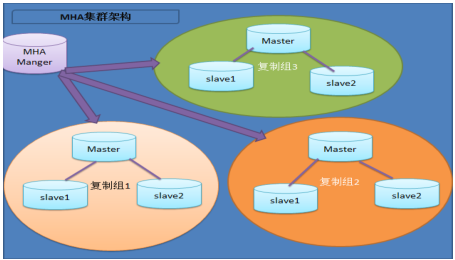
MHA由Manager节点和Node节点组成。
MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明
MHA工作原理:
• 从宕机崩溃的master保存二进制日志事件(binlog events);
• 识别含有最新更新的slave;
• 应用差异的中继日志(relay log)到其他的slave;
• 应用从master保存的二进制日志事件(binlog events);
• 提升一个slave为新的master;
• 使其他的slave连接新的master进行复制;
1.2 、 MHA 工具介绍
MHA 软件由两部分组成,Manager 工具包和 Node 工具包,具体的说明如下。
Manager 工具包主要包括以下几个工具:
➢ masterha_check_ssh 检查 MHA 的 SSH 配置状况
➢ masterha_check_repl 检查 MySQL 复制状况
➢ masterha_manger 启动 MHA
➢ masterha_check_status 检测当前 MHA 运行状态
➢ masterha_master_monitor 检测 master 是否宕机
➢ masterha_master_switch 控制故障转移(自动或者手动)
➢ masterha_conf_host 添加或删除配置的 server 信息
Node 工具包(这些工具通常由 MHA Manager 的脚本触发,无需人为操作)主要包括以下几
个工具:
➢ save_binary_logs 保存和复制 master 的二进制日志
➢ apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的
slave
➢ filter_mysqlbinlog 去除不必要的 ROLLBACK 事件(MHA 已不再使用这个工具)
➢ purge_relay_logs 清除中继日志(不会阻塞 SQL 线程)
注意:为了尽可能的减少主库硬件损坏宕机造成的数据丢失,因此在配置 MHA 的同时建议
成 配置成 MySQL 5.5
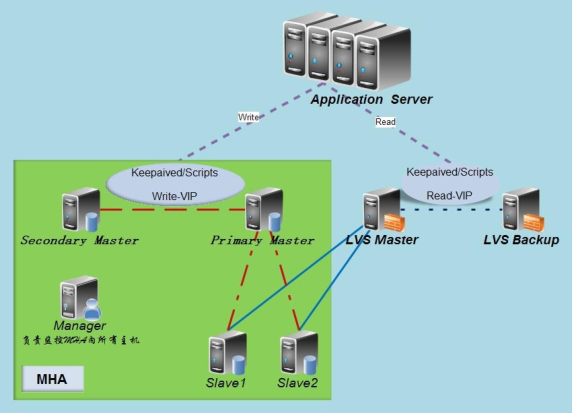
MHA环境图:一主三从模式(通过VIP漂移)
| 角色 | IP地址 | 主机名 | ServerID | 数据库类型 |
| Primary Master | 192.168.200.111 | server01 | 1 | 写入 |
| Slave1 | 192.168.200.112 | server02 | 2 | 读 |
| Slave2 | 192.168.200.113 | server03 | 3 | 读 |
| Slave3 | 192.168.200.114 | server04 | 4 | 读 |
| Manager | 192.168.200.115 | server05 | - | 监控复制组 |
| LVS Matser | 192.168.200.116 | server06 | - | - |
| LVS Backup | 192.168.200.117 | server07 | - | - |
其中 Primary Master 对外提供写服务,备选 Secondary Master (实际的 slave 提供读服务,
slave1和slave2也提供相关的读服务,一旦Primary Master宕机,将会把备选Secondary Master
提升为新的 Primary Master,slave1 和 slave2 指向新的 master。
1.4 实验拓扑环境
二、 前期环境部署
2.1 1 、 配置 所有 主机 名称
master1 主机:
hostname server01
bash
master2 主机:
hostname server02
bash
slave1 主机:
hostname server03
bash
slave2 主机:
hostname server04
bash
manager 主机:
hostname server05
bash
.2.2 2 、 配置 所有 主机名及映射关系
[root@server01~]# vim /etc/hosts
192.168.200.111 server01
192.168.200.112 server02
192.168.200.113 server03
192.168.200.114 server04
192.168.200.115 server05 通过SCP发送hosts映射到另外几台主机
scp /etc/hosts 192.168.200.111:/etc/
scp /etc/hosts 192.168.200.112:/etc/
scp /etc/hosts 192.168.200.113:/etc/
scp /etc/hosts 192.168.200.114:/etc/
2.3 3 、 所有主机 关闭防火墙和安全机制
systemctl stop iptables
systemctl stop firewalld
setenforce
三、安装 MHA node
3.1、 所有 主机装 安装 MHA node 及相关 perl 依赖包
安装 epel 源:
1:导入epel源码包 2:解压rpm -ivh epel-release-latest-.noarch.rpm
安装依赖包
yum install -y perl-DBD-MySQL.x86_64 perl-DBI.x86_64 perl-CPAN perl-ExtUtils-CBuilder perl-ExtUtils-MakeMaker 注意:安装后建议检查一下所需软件包是否全部安装
rpm -q perl-DBD-MySQL.x86_64 perl-DBI.x86_64 perl-CPAN perl-ExtUtils-CBuilder
perl-ExtUtils-MakeMaker
perl-DBD-MySQL-4.023-6.el7.x86_64
perl-DBI-1.627-4.el7.x86_64
perl-CPAN-1.9800-292.el7.noarch
perl-ExtUtils-CBuilder-0.28.2.6-292.el7.noarch
perl-ExtUtils-MakeMaker-6.68-3.el7.noarch
3.2、 所有 主机装 上安装 MHA Node
tar xf mha4mysql-node-0.56.tar.gz
cd mha4mysql-node-0.56/
perl Makefile.PL
make && make install
3.3 、MHA Node 安装完 后会在 /usr/local/bin 生成以下脚本
[root@server04 mha4mysql-node-0.56]# ls -l /usr/local/bin/
总用量 40
-r-xr-xr-x. 1 root root 16346 10月 22 13:27 apply_diff_relay_logs
-r-xr-xr-x. 1 root root 4807 10月 22 13:27 filter_mysqlbinlog
-r-xr-xr-x. 1 root root 7401 10月 22 13:27 purge_relay_logs
-r-xr-xr-x. 1 root root 7395 10月 22 13:27 save_binary_logs
四、192.168.200.115上 安装 MHA Manger以及perl-Config-Tiny-2.14-7.el7.noarch其余四台不需要装
注意:115安装 MHA Manger 之前也需要安装 MHA Node
4.1、首先安装 MHA Manger 依赖的 perl 模块(我这里使用 yum 安装)
192.168.200.115导入如下四个源码包
[root@server05 ~]# ls
perl-Config-Tiny-2.14-7.el7.noarch.rpm mha4mysql-manager-0.56.tar.gz
epel-release-latest-7.noarch.rpm mha4mysql-node-0.56.tar.gz
安装依赖包:
yum install -y perl perl-Log-Dispatch perl-Parallel-ForkManager perl-DBD-MySQL perl-DBI perl-Time-HiRes
yum -y install perl-Config-Tiny-2.14-.el7.noarch.rpm
注意:安装后建议检查一下所需软件包是否全部安装
rpm -q perl cpan perl-Log-Dispatch perl-Parallel-ForkManager perl-DBD-MySQL perl-DBI perl-Time-HiRes perl-Config-Tiny
perl-5.16.3-292.el7.x86_64
perl-Log-Dispatch-2.41-1.el7.1.noarch
perl-Parallel-ForkManager-1.18-2.el7.noarch
perl-DBD-MySQL-4.023-6.el7.x86_64
perl-DBI-1.627-4.el7.x86_64
perl-Time-HiRes-1.9725-3.el7.x86_64
perl-Config-Tiny-2.14-7.el7.noarch
注意:之前时候 perl-Config-Tiny.noarch 没有安装成功,后来用 cpan(cpan install Config::Tiny )
4.2、 安装 MHA Manger
tar xf mha4mysql-manager-0.56.tar.gz
cd mha4mysql-manager-0.56/
perl Makefile.PL
make && make install
4.3、 安装完成后会有以下脚本文件
[root@server05 ~]# ls -l /usr/local/bin/
总用量
-r-xr-xr-x root root 月 : apply_diff_relay_logs
-r-xr-xr-x root root 月 : filter_mysqlbinlog
-r-xr-xr-x root root 月 : masterha_check_repl
-r-xr-xr-x root root 月 : masterha_check_ssh
-r-xr-xr-x root root 月 : masterha_check_status
-r-xr-xr-x root root 月 : masterha_conf_host
-r-xr-xr-x root root 月 : masterha_manager
-r-xr-xr-x root root 月 : masterha_master_monitor
-r-xr-xr-x root root 月 : masterha_master_switch
-r-xr-xr-x root root 月 : masterha_secondary_check
-r-xr-xr-x root root 月 : masterha_stop
-r-xr-xr-x root root 月 : purge_relay_logs
-r-xr-xr-x root root 月 : save_binary_logs
五、置 配置 SSH 密钥对 验证
服务器之间需要实现密钥对验证。关于配置密钥对验证可看下面步骤。但是有一点需要
注意:不能禁止 password 登陆,否则会出现错误
1. 服务器先生成一个密钥对
2. 把自己的公钥传给对方
5.1 、Server05(192.168.200.115) 上操作:
[root@server05 ~]# ssh-keygen -t rsa
[root@server05 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.200.111
[root@server05 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.200.112
[root@server05 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.200.113
[root@server05 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.200.114 注意:Server05 需要 连接 每个主机测试,因为第一次 连接入 的时候需要输入 yes ,影响后期故
障切换时,对于每的 个主机的 SSH 控制。 检测秘钥对是否可以连接: [root@server05 ~]# ssh server01
[root@server01 ~]# exit
登出
Connection to server01 closed.
[root@server05 ~]# ssh server02
[root@server05 ~]# ssh server03
[root@server05 ~]# ssh server04
5.2 、Primary Master(192.168.200.111)上操作:
[root@server01 ~]# ssh-keygen -t rsa
[root@server01 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.200.112
[root@server01 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.200.113
[root@server01 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.200.114
5.3 、Secondary Master(192.168.200.112)上操作:
[root@server02 ~]# ssh-keygen -t rsa
[root@server02 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.200.111
[root@server02 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.200.113
[root@server02 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.200.114
5.4 、slave1(192.168.200.113)上操作:
[root@server03 ~]# ssh-keygen -t rsa
[root@server03 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.200.111
[root@server03 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.200.112
[root@server03 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.200.114
5.5 、slave2(192.168.200.114)上操作:
[root@server04 ~]# ssh-keygen -t rsa
[root@server04 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.200.111
[root@server04 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.200.112
[root@server04 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.200.113
六、安装 mysql:不做字符集,做字符集后期会报错,安装时,/etc/my.cnf不做任何改动
111-114 所有主机上的操作:
yum -y install mariadb mariadb-server mariadb-devel
systemctl start mariadb
netstat -lnpt | grep :3306 设置数据库初始密码(后续操作中使用)
mysqladmin -u root password
七、 搭建主从复制环境
注意:binlog-do-db 和 replicate-ignore-db 设置必须相同。 MHA 在启动时候会检测过滤规
则,如果过滤规则不同,MHA 将不启动监控和故障转移功能。
7.1 1 、修改 mysql 主机的配置文件
Primary Master(192.168.200.111)上操作:
vim /etc/my.cnf
[mysqld]
server-id =
log-bin=master-bin
log-slave-updates=true
relay_log_purge=0
systemctl restart mariadb
netstat -anpt | grep 3306
Secondary Master(192.168.200.112)上操作:
vim /etc/my.cnf
[mysqld]
server-id=
log-bin=master-bin
log-slave-updates=true
relay_log_purge=0 systemctl restart mariadb
netstat -anpt | grep 3306
slave1(192.168.200.113)上操作:
vim /etc/my.cnf
[mysqld]
server-id=
log-bin=mysql-bin
relay-log=slave-relay-bin
log-slave-updates=true
relay_log_purge=0 systemctl restart mariadb
netstat -anpt | grep 3306
slave2(192.168.200.114)上操作:
vim /etc/my.cnf
[mysqld]
server-id=
log-bin=mysql-bin
relay-log=slave-relay-bin
log-slave-updates=true
relay_log_purge=0 systemctl restart mariadb
netstat -anpt | grep 3306
7.2 、在 Primary Master( 192.168 .200.111) ) 上 对旧 数据 进行 备份
mysqldump --master-data=2 --single-transaction -R --triggers -A > all.sql
参数解释:
--master-data=2 录 备份时刻记录 master 的 的 Binlog 位置和 Position
--single-transaction 获取一致性快照
-R 备份存储过程和函数
-triggres 备份触发器
-A 备份所有的库。
没有旧数据就不用了执行本次7.2的操作
7.3、4 、mysql服务器 创建复制授权 用户及 查看主库备份时的 binlog 名称和位置:192.168.200.111上操作
[root@server01 ~]# mysql -uroot -p123123
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 2
Server version: 5.5.60-MariaDB MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> grant replication slave on *.* to 'repl'@'192.168.200.%' identified by '123123';
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> flush privileges;
Query OK, 0 rows affected (0.01 sec)
MariaDB [(none)]> show master status;
+-------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+------------------+
| master-bin.000001 | 474 | | |
+-------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
7.5 、 把 数据 备份复制 其他主机
scp all.sql 192.168.200.112:/tmp/
scp all.sql 192.168.200.113:/tmp/
scp all.sql 192.168.200.114:/tmp/
7.6 、 导入旧数据备份 数据到 到 112-114 主机上 、并且112-114执行复制相关命令
mysql -uroot -p123456< /tmp/all.sql #旧数据备份、没有旧数据就不用执行这一段代码
MariaDB [(none)]> stop slave;
Query OK, 0 rows affected, 1 warning (0.01 sec)
MariaDB [(none)]> CHANGE MASTER TO
-> MASTER_HOST='192.168.200.111',
-> MASTER_USER='repl',
-> MASTER_PASSWORD='123123',
-> MASTER_LOG_FILE='master-bin.000001',
-> MASTER_LOG_POS=474;
Query OK, 0 rows affected (0.03 sec)
MariaDB [(none)]> start slave;
Query OK, 0 rows affected (0.01 sec)
MariaDB [(none)]> show slave status\G
# 检查 IO 和 和 SQL 线程是否为:yes
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
7. 7 、 主从同步故障处理:如果7、6报错误就执行这段代码,没报错忽略
Slave_IO_Running: No
Slave_SQL_Running: Yes
----------------------------------- 忽略部分信息-----------------------------------
Last_IO_Errno:
Last_IO_Error: Got fatal error from master when reading data from
binary log: 'Could not find first log file name in binary log index file'
----------------------------------- 忽略部分信息-----------------------------------
处理方式:
stop slave;
reset slave;
set global sql_slave_skip_counter = ;
start slave;
7.8 、 三台 slave(112-114) 服务置 器设置 read_y only 状态
从库对外 只进 提供读服务,只所以没有写进 mysql 配置文件,是因为时 随时 server02 会提升为master
方法一:在主页面输入 [root@server02 ~]# mysql -uroot -p123123 -e 'set global read_only=1'
[root@server03 ~]# mysql -uroot -p123123 -e 'set global read_only=1'
[root@server04 ~]# mysql -uroot -p123123 -e 'set global read_only=1' 方法二:三台slave都在数据库内输入
MariaDB [(none)]> set global read_only=1;
7.9 、 创建监控用户 (111-114 主机上的操作 ) :做监控主要为了给115更加方便的监控master(111)主机有没有Down,一旦111主机down了就通过VIP漂移把VIP给112主机
,112主机从slave变成master
grant all privileges on *.* to 'root'@'192.168.200.%' identified by '';
flush privileges; 每个主机为自己的主机名授权在111-114上执行: #此处跳过不写一旦后期报错时再执行,以免影响服务
grant all privileges on *.* to 'root'@'server号(01-04)' identified by '';
flush privileges;
**到这里整个 mysql 主从集群环境已经搭建完毕**
八、配置 MHA 环境:都在192.168.200.115下操作
8.1 、 创建 MHA 的工作目录 及 相关配置文件
Server05(192.168.200.115): 在软件包解压后的目录里面有样例配置文件
[root@server05 ~]# mkdir /etc/masterha
[root@server05 ~]# cp mha4mysql-manager-0.56/samples/conf/app1.cnf /etc/masterha
8.2 、修改 app1.cnf 配置文件
/usr/local/bin/master_ip_failover 脚本需要根据自己环境修改 ip 和网卡名称等。
vim /etc/masterha/app1.cnf
[server default]
# 设置 manager 的工作日志
manager_workdir=/var/log/masterha/app1
# 设置 manager 的日志, 这两条都是默认存在的
manager_log=/var/log/masterha/app1/manager.log
# 设置 master 默认保存 binlog 的位置, 以便 MHA 可以找到 master 日志
master_binlog_dir=/var/lib/mysql
# 设置自动 failover 时候的切换脚本
master_ip_failover_script= /usr/local/bin/master_ip_failover
# 设置 mysql 中root 用户的密码
password=123123
user=root
#ping 包的时间间隔
ping_interval=1
# 设置远端 mysql 在发生切换时保存 binlog 的具体位置
remote_workdir=/tmp
# 设置复制用户的密码和用户名
repl_password=123123
repl_user=repl
[server1]
hostname=server01
port=
[server2]
hostname=server02
candidate_master=
port=
check_repl_delay=
[server3]
hostname=server03
port=
[server4]
hostname=server04
port=
8.3 、 配置故障转移脚本
[root@server05 ~]# vim /usr/local/bin/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port,
);
my $vip = '192.168.200.100'; # 写入 VIP
my $key = "1"; #非keepalived 方式切换脚本使用的
my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig ens33:$key down"; # 那么这里写服务的开关命令
$ssh_user = "root";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
# $orig_master_host, $orig_master_ip, $orig_master_port are passed.
# If you manage master ip address at global catalog database,
# invalidate orig_master_ip here.
my $exit_code = ;
#eval {
# print "Disabling the VIP on old master: $orig_master_host \n";
# &stop_vip();
# $exit_code = ;
#};
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
#my $ping=`ping -c 10.0.0.13 | grep "packet loss" | awk -F',' '{print $3}' | awk '{print $1}'`;
#if ( $ping le "90.0%"&& $ping gt "0.0%" ){
#$exit_code = ;
#}
#else {
&stop_vip();
# updating global catalog, etc
$exit_code = ;
#}
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
# all arguments are passed.
# If you manage master ip address at global catalog database,
# activate new_master_ip here.
# You can also grant write access (create user, set read_only=, etc) here.
my $exit_code = ;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = ;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
`ssh $ssh_user\@$orig_master_ip \" $ssh_start_vip \"`;
exit ;
}
else {
&usage();
exit ;
}
}
# A simple system call that enable the VIP on the new master
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host
--orig_master_ip=ip --orig_master_port=port --
new_master_host=host --new_master_ip=ip --new_master_port=port\n"; }
[root@server05 ~]# chmod +x /usr/local/bin/master_ip_failover
8.4 、 设置从库 relay log 的清除方式( 112- - 114 ) : 如果8、7报错时在112-114上执行这条命令
mysql -uroot -p123123 -e 'set global relay_log_purge=0;'
注意:
MHA 在故障切换的过程中,从库的恢复过程依赖于 relay log 的相关信息,所以这里要
将 relay log 的自动清除设置为 OFF,采用手动清除 relay log 的方式。在默认情况下,从服务
器上的中继日志会在 SQL 线程执行完毕后被自动删除。但是在 MHA 环境中,这些中继日志
在恢复其他从服务器时可能会被用到,因此需要禁用中继日志的自动清除功能。定期清除中
继日志需要考虑到复制延时的问题。在 ext3 的文件系统下,删除大的文件需要一定的时间,
会导致严重的复制延时。为了避免复制延时,需要暂时为中继日志创建硬链接,因为在 linux
系统中通过硬链接删除大文件速度会很快。(在 mysql 数据库中,删除大表时,通常也采用
建立硬链接的方式)
8.5 、 配置从库 ( 112- - 114 )relay_log 清除脚本加入计划任务 个人实验时可以不做这条操作
MHA 节点中包含了 pure_relay_logs 命令工具,它可以为中继日志创建硬链接,执行 SET
GLOBAL relay_log_purge=1,等待几秒钟以便 SQL 线程切换到新的中继日志,再执行 SET
GLOBAL relay_log_purge=0。
vim purge_relay_log.sh
#!/bin/bash
user=root
passwd= # 注意:数据库要有 密码, 填自己所设置的密码就可以 ,前面设置过
port=
log_dir='/tmp'
work_dir='/tmp'
purge='/usr/local/bin/purge_relay_logs'
if [ ! -d $log_dir ]
then
mkdir $log_dir -p
fi
$purge --user=$user --password=$passwd --disable_relay_log_purge --port=$port
--workdir=$work_dir >> $log_dir/purge_relay_logs.log >&
chmod +x purge_relay_log.sh
crontab -e
* * * /bin/bash /root/purge_relay_log.sh
pure_relay_logs 脚本参数如下所示:
--user mysql 用户名
--password mysql 密码
--port 端口号
--workdir 指定创建 relay log 的硬链接的位置,默认是/var/tmp,由于系统不同
分区创建硬链接文件会失败,故需要执行硬链接具体位置,成功执行脚本后,硬链接的中继
日志文件被删除
--disable_relay_log_purge 默认情况下,如果 relay_log_purge=1,脚本会什么都不清理,自
动退出,通过设定这个参数,当 relay_log_purge=1 的情况下会将 relay_log_purge 设置为 0。
清理 relay log 之后,最后将参数设置为 OFF。
8.6 、手动清除 中继 日志 可以不做这条操作
purge_relay_logs --user=root --password=123456 --disable_relay_log_purge --port=3306
--workdir=/tmp
2017-08-31 21:33:52: purge_relay_logs script started.
Found relay_log.info: /usr/local/mysql/data/relay-log.info
Removing hard linked relay log files slave-relay-bin* under /tmp.. done.
Current relay log file: /usr/local/mysql/data/slave-relay-bin.000002
Archiving unused relay log files (up to /usr/local/mysql/data/slave-relay-bin.000001) ...
Creating hard link for /usr/local/mysql/data/slave-relay-bin.000001 under
/tmp/slave-relay-bin.000001 .. ok.
Creating hard links for unused relay log files completed.
Executing SET GLOBAL relay_log_purge=1; FLUSH LOGS; sleeping a few seconds so that SQL
thread can delete older relay log files (if i
t keeps up); SET GLOBAL relay_log_purge=0; .. ok. Removing hard linked relay log files
slave-relay-bin* under /tmp.. done.
2017-08-31 21:33:56: All relay log purging operations succeeded.
8.7 、 检查 MHA ssh 通信状态 必须执行的操作
[root@server05 ~]# masterha_check_ssh --conf=/etc/masterha/app1.cnf Sat Dec :: - [warning] Global configuration file /etc/masterha_default.cnf not
found. Skipping.
Sat Dec :: - [info] Reading application default configurations from
/etc/masterha/app1.cnf..
Sat Dec :: - [info] Reading server configurations from /etc/masterha/app1.cnf..
Sat Dec :: - [info] Starting SSH connection tests..
Sat Dec :: - [debug]
Sat Dec :: - [debug] Connecting via SSH from
root@server02(192.168.200.112:) to root@server01(192.168.200.111:)..
Sat Dec :: - [debug] ok.
----------------
---------------------
Sat Dec :: - [debug] Connecting via SSH from
root@server04(192.168.200.114:) to root@server03(192.168.200.113:)..
Sat Dec :: - [debug] ok.
Sat Dec 29 16:04:02 2018 - [info] All SSH connection tests passed successfully. #有这段话表示暂时也没有问题
8.9 、 检查整个主从复制集群的状态
[root@server05 ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf Tue Oct :: - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue Oct :: - [info] Reading application default configurations from /etc/masterha/app1.cnf..
Tue Oct :: - [info] Reading server configurations from /etc/masterha/app1.cnf..
Tue Oct :: - [info] MHA::MasterMonitor version 0.56.
Tue Oct :: - [info] Dead Servers:
Tue Oct :: - [info] Alive Servers:
Tue Oct 22 17:28:44 2019 - [info] server01(192.168.200.111:3306)
Tue Oct 22 17:28:44 2019 - [info] server02(192.168.200.112:3306)
Tue Oct 22 17:28:44 2019 - [info] server03(192.168.200.113:3306) #有四个活着的主机
Tue Oct 22 17:28:44 2019 - [info] server04(192.168.200.114:3306)
Tue Oct :: - [info] Alive Slaves:
Tue Oct :: - [info] server02(192.168.200.112:) Version=5.5.-MariaDB (oldest major version between slaves) log-bin:enabled
Tue Oct :: - [info] Replicating from 192.168.200.111(192.168.200.111:)
Tue Oct :: - [info] Primary candidate for the new Master (candidate_master is set)
Tue Oct :: - [info] server03(192.168.200.113:) Version=5.5.-MariaDB (oldest major version between slaves) log-bin:enabled
Tue Oct :: - [info] Replicating from 192.168.200.111(192.168.200.111:)
Tue Oct :: - [info] server04(192.168.200.114:) Version=5.5.-MariaDB (oldest major version between slaves) log-bin:enabled
Tue Oct :: - [info] Replicating from 192.168.200.111(192.168.200.111:)
Tue Oct :: - [info] Current Alive Master: server01(192.168.200.111:)
Tue Oct :: - [info] Checking slave configurations..
Tue Oct 22 17:28:44 2019 - [warning] relay_log_purge=0 is not set on slave server02(192.168.200.112:3306).
Tue Oct 22 17:28:44 2019 - [warning] relay_log_purge=0 is not set on slave server03(192.168.200.113:3306). #报错点三处
Tue Oct 22 17:28:44 2019 - [warning] relay_log_purge=0 is not set on slave server04(192.168.200.114:3306).
Tue Oct :: - [info] Checking replication filtering settings..
Tue Oct :: - [info] binlog_do_db= , binlog_ignore_db=
Tue Oct :: - [info] Replication filtering check ok.
Tue Oct 22 17:28:44 2019 - [error][/usr/local/share/perl5/MHA/Server.pm, ln383] server04(192.168.200.114:3306): #报server04上没有主从复制的用户
User repl does not exist or does not have REPLICATION SLAVE privilege! Other slaves can not start replication from this host.
Tue Oct :: - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln401] Error happend on checking configurations.
at /usr/local/share/perl5/MHA/ServerManager.pm line .
Tue Oct :: - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln500] Error happened on monitoring servers.
Tue Oct :: - [info] Got exit code (Not master dead). MySQL Replication Health is NOT OK!
如果出现四个活主机三个报错点这种报错就执行8、4清除中继日志在(112-114)上执行:
[root@server02 ~]# mysql -uroot -p123123 -e 'set global relay_log_purge=0;'
[root@server03 ~]# mysql -uroot -p123123 -e 'set global relay_log_purge=0;'
[root@server04~]# mysql -uroot -p123123 -e 'set global relay_log_purge=0;'
115主机再次查看日志:
[root@server05 ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf
Tue Oct :: - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue Oct :: - [info] Reading application default configurations from /etc/masterha/app1.cnf..
Tue Oct :: - [info] Reading server configurations from /etc/masterha/app1.cnf..
Tue Oct :: - [info] MHA::MasterMonitor version 0.56.
Tue Oct :: - [info] Dead Servers:
Tue Oct :: - [info] Alive Servers:
Tue Oct 22 19:18:58 2019 - [info] server01(192.168.200.111:3306)
Tue Oct 22 19:18:58 2019 - [info] server02(192.168.200.112:3306)
Tue Oct 22 19:18:58 2019 - [info] server03(192.168.200.113:3306)
Tue Oct 22 19:18:58 2019 - [info] server04(192.168.200.114:3306)
Tue Oct :: - [info] Alive Slaves:
Tue Oct :: - [info] server02(192.168.200.112:) Version=5.5.-MariaDB (oldest major version between slaves) log-bin:enabled
Tue Oct :: - [info] Replicating from 192.168.200.111(192.168.200.111:)
Tue Oct :: - [info] Primary candidate for the new Master (candidate_master is set)
Tue Oct :: - [info] server03(192.168.200.113:) Version=5.5.-MariaDB (oldest major version between slaves) log-bin:enabled
Tue Oct :: - [info] Replicating from 192.168.200.111(192.168.200.111:)
Tue Oct :: - [info] server04(192.168.200.114:) Version=5.5.-MariaDB (oldest major version between slaves) log-bin:enabled
Tue Oct :: - [info] Replicating from 192.168.200.111(192.168.200.111:)
Tue Oct :: - [info] Current Alive Master: server01(192.168.200.111:)
Tue Oct :: - [info] Checking slave configurations..
Tue Oct :: - [info] Checking replication filtering settings..
Tue Oct :: - [info] binlog_do_db= , binlog_ignore_db=
Tue Oct :: - [info] Replication filtering check ok.
Tue Oct 22 19:18:58 2019 - [error][/usr/local/share/perl5/MHA/Server.pm, ln383] server04(192.168.200.114:3306): #报server04上没有主从复制的用户
User repl does not exist or does not have REPLICATION SLAVE privilege! Other slaves can not start replication from this host.
Tue Oct :: - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln401] Error happend on checking configurations.
at /usr/local/share/perl5/MHA/ServerManager.pm line .
Tue Oct :: - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln500] Error happened on monitoring servers.
Tue Oct :: - [info] Got exit code (Not master dead). MySQL Replication Health is NOT OK!
报server04上的错误就再次在114上执行用户权限配置:
MariaDB [(none)]> grant replication slave on *.* to 'repl'@'192.168.200.%' identified by '123123';
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> flush privileges;
Query OK, 0 rows affected (0.00 sec)
115主机再次查看日志:
[root@server05 ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf
Tue Oct :: - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue Oct :: - [info] Reading application default configurations from /etc/masterha/app1.cnf..
Tue Oct :: - [info] Reading server configurations from /etc/masterha/app1.cnf..
Tue Oct :: - [info] MHA::MasterMonitor version 0.56.
Tue Oct :: - [info] Dead Servers:
Tue Oct :: - [info] Alive Servers:
Tue Oct :: - [info] server01(192.168.200.111:)
Tue Oct :: - [info] server02(192.168.200.112:)
Tue Oct :: - [info] server03(192.168.200.113:)
Tue Oct :: - [info] server04(192.168.200.114:)
Tue Oct :: - [info] Alive Slaves:
Tue Oct :: - [info] server02(192.168.200.112:) Version=5.5.-MariaDB (oldest major version between slaves) log-bin:enabled
Tue Oct :: - [info] Replicating from 192.168.200.111(192.168.200.111:)
Tue Oct :: - [info] Primary candidate for the new Master (candidate_master is set)
Tue Oct :: - [info] server03(192.168.200.113:) Version=5.5.-MariaDB (oldest major version between slaves) log-bin:enabled
Tue Oct :: - [info] Replicating from 192.168.200.111(192.168.200.111:)
Tue Oct :: - [info] server04(192.168.200.114:) Version=5.5.-MariaDB (oldest major version between slaves) log-bin:enabled
Tue Oct :: - [info] Replicating from 192.168.200.111(192.168.200.111:)
Tue Oct :: - [info] Current Alive Master: server01(192.168.200.111:)
Tue Oct :: - [info] Checking slave configurations..
Tue Oct :: - [info] Checking replication filtering settings..
Tue Oct :: - [info] binlog_do_db= , binlog_ignore_db=
Tue Oct :: - [info] Replication filtering check ok.
Tue Oct :: - [info] Starting SSH connection tests..
Tue Oct :: - [info] All SSH connection tests passed successfully.
Tue Oct :: - [info] Checking MHA Node version..
Tue Oct :: - [info] Version check ok.
Tue Oct :: - [info] Checking SSH publickey authentication settings on the current master..
Tue Oct :: - [info] HealthCheck: SSH to server01 is reachable.
Tue Oct :: - [info] Master MHA Node version is 0.56.
Tue Oct :: - [info] Checking recovery script configurations on the current master..
Tue Oct :: - [info] Executing command: save_binary_logs --command=test --start_pos= --binlog_dir=/var/lib/mysql
--output_file=/tmp/save_binary_logs_test
--manager_version=0.56 --start_file=master-bin.
Tue Oct :: - [info] Connecting to root@server01(server01)..
Creating /tmp if not exists.. ok.
Checking output directory is accessible or not..
ok.
Binlog found at /var/lib/mysql, up to master-bin.
Tue Oct :: - [info] Master setting check done.
Tue Oct :: - [info] Checking SSH publickey authentication and checking recovery script configurations on all alive slave servers..
Tue Oct :: - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='root' --slave_host=server02
--slave_ip=192.168.200.112 --slave_port=
--workdir=/tmp --target_version=5.5.-MariaDB --manager_version=0.56 --relay_log_info=/var/lib/mysql/relay-log.info
--relay_dir=/var/lib/mysql/ --slave_pass=xxx
Tue Oct 22 19:30:42 2019 - [info] Connecting to root@192.168.200.112(server02:22).. #server02报授权错误
mysqlbinlog: unknown variable 'default-character-set=utf8'
mysqlbinlog version command failed with rc :, please verify PATH, LD_LIBRARY_PATH, and client options
at /usr/local/bin/apply_diff_relay_logs line .
Tue Oct :: - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln201] Slaves settings check failed!
Tue Oct :: - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln390] Slave configuration failed.
Tue Oct :: - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln401] Error happend on checking configurations.
at /usr/local/bin/masterha_check_repl line .
Tue Oct :: - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln500] Error happened on monitoring servers.
Tue Oct :: - [info] Got exit code (Not master dead).
报授权错误时每个主机为自己的主机名授权:在111-114上执行:
grant all privileges on *.* to 'root'@'server号(01-04)' identified by '123123';
flush privileges;
115主机再次执行日志:
[root@server05 ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf
Tue Oct :: - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue Oct :: - [info] Reading application default configurations from /etc/masterha/app1.cnf..
Tue Oct :: - [info] Reading server configurations from /etc/masterha/app1.cnf..
Tue Oct :: - [info] MHA::MasterMonitor version 0.56.
Tue Oct :: - [info] Dead Servers:
Tue Oct :: - [info] Alive Servers:
Tue Oct :: - [info] server01(192.168.200.111:)
Tue Oct :: - [info] server02(192.168.200.112:)
Tue Oct :: - [info] server03(192.168.200.113:)
Tue Oct :: - [info] server04(192.168.200.114:)
Tue Oct :: - [info] Alive Slaves:
Tue Oct :: - [info] server02(192.168.200.112:) Version=5.5.-MariaDB (oldest major version between slaves) log-bin:enabled
Tue Oct :: - [info] Replicating from 192.168.200.111(192.168.200.111:)
Tue Oct :: - [info] Primary candidate for the new Master (candidate_master is set)
Tue Oct :: - [info] server03(192.168.200.113:) Version=5.5.-MariaDB (oldest major version between slaves) log-bin:enabled
Tue Oct :: - [info] Replicating from 192.168.200.111(192.168.200.111:)
Tue Oct :: - [info] server04(192.168.200.114:) Version=5.5.-MariaDB (oldest major version between slaves) log-bin:enabled
Tue Oct :: - [info] Replicating from 192.168.200.111(192.168.200.111:)
Tue Oct :: - [info] Current Alive Master: server01(192.168.200.111:)
Tue Oct :: - [info] Checking slave configurations..
Tue Oct :: - [info] read_only= is not set on slave server02(192.168.200.112:).
Tue Oct :: - [info] read_only= is not set on slave server03(192.168.200.113:).
Tue Oct :: - [info] read_only= is not set on slave server04(192.168.200.114:).
Tue Oct :: - [info] Checking replication filtering settings..
Tue Oct :: - [info] binlog_do_db= , binlog_ignore_db=
Tue Oct :: - [info] Replication filtering check ok.
Tue Oct :: - [info] Starting SSH connection tests..
Tue Oct :: - [info] All SSH connection tests passed successfully.
Tue Oct :: - [info] Checking MHA Node version..
Tue Oct :: - [info] Version check ok.
Tue Oct :: - [info] Checking SSH publickey authentication settings on the current master..
Tue Oct :: - [info] HealthCheck: SSH to server01 is reachable.
Tue Oct :: - [info] Master MHA Node version is 0.56.
Tue Oct :: - [info] Checking recovery script configurations on the current master..
Tue Oct :: - [info] Executing command: save_binary_logs --command=test --start_pos= --binlog_dir=/var/lib/mysql --output_file=/tmp/save_binary_logs_test --manager_version=0.56 --start_file=master-bin.
Tue Oct :: - [info] Connecting to root@server01(server01)..
Creating /tmp if not exists.. ok.
Checking output directory is accessible or not..
ok.
Binlog found at /var/lib/mysql, up to master-bin.
Tue Oct :: - [info] Master setting check done.
Tue Oct :: - [info] Checking SSH publickey authentication and checking recovery script configurations on all alive slave servers..
Tue Oct :: - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='root' --slave_host=server02 --slave_ip=192.168.200.112 --slave_port= --workdir=/tmp --target_version=5.5.-MariaDB --manager_version=0.56 --relay_log_info=/var/lib/mysql/relay-log.info --relay_dir=/var/lib/mysql/ --slave_pass=xxx
Tue Oct :: - [info] Connecting to root@192.168.200.112(server02:)..
Checking slave recovery environment settings..
Opening /var/lib/mysql/relay-log.info ... ok.
Relay log found at /var/lib/mysql, up to mariadb-relay-bin.
Temporary relay log file is /var/lib/mysql/mariadb-relay-bin.
Testing mysql connection and privileges.. done.
Testing mysqlbinlog output.. done.
Cleaning up test file(s).. done.
Tue Oct :: - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='root' --slave_host=server03 --slave_ip=192.168.200.113 --slave_port= --workdir=/tmp --target_version=5.5.-MariaDB --manager_version=0.56 --relay_log_info=/var/lib/mysql/relay-log.info --relay_dir=/var/lib/mysql/ --slave_pass=xxx
Tue Oct :: - [info] Connecting to root@192.168.200.113(server03:)..
Checking slave recovery environment settings..
Opening /var/lib/mysql/relay-log.info ... ok.
server01 (current master)
+--server02
+--server03
+--server04
--------
--------------
MySQL Replication Health is OK. ** 返回 OK 表示没有问题**
九、VIP 配置 管理
Master vip 配置有两种方式,一种是通过 keepalived 或者 heartbeat 类似的软件的方式管
理 VIP 的漂移,另一种为通过命令方式管理。
通过命令方式管理 VIP 地址:
打开115在前面编辑过的文件/etc/masterha/app1.cnf,检查如下行是否正确,再检查集群状态。
Server05(192.168.200.115)修改故障转移脚本
[root@server05 ~]# grep -n 'master_ip_failover_script' /etc/masterha/app1.cnf
master_ip_failover_script= /usr/local/bin/master_ip_failover #用于存放脚本的位置
Server05(192.168.200.115)修改故障转移脚本
[root@server05 ~]# head -13 /usr/local/bin/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port,
);
my $vip = '192.168.200.100'; # 写入 VIP
my $key = ""; #非 非 keepalived 方式切换脚本使用的
my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip"; # 若是使用 keepalived
my $ssh_stop_vip = "/sbin/ifconfig ens33:$key down"; # 那么这里写服务的 开关命令
/usr/local/bin/master_ip_failover 文件的内容意思是当主库发生故障时,会触发 MHA 切
换,MHA manager 会停掉主库上的 ens32:1 接口,触发虚拟 ip 漂移到备选从库,从而完成
切换。
Server05(192.168.200.115) 检查 manager 状态
[root@server05 ~]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 is stopped(2:NOT_RUNNING).
注意:如果正常会显示"PING_OK",否则会显示"NOT_RUNNING",代表 MHA 监控没有开启。
Server05(192.168.200.115) 开启 manager 监控
[root@server05 ~]# nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dea
d_master_conf --ignore_last_failover< /dev/null >/var/log/masterha/app1/manager.log >&&
[]
启动参数介绍:
--remove_dead_master_conf 该参数代表当发生主从切换后,老的主库的 ip 将会从配置
文件中移除。
--manger_log 日志存放位置
--ignore_last_failover 在缺省情况下,如果 MHA 检测到连续发生宕机,且两次宕
机间隔不足 8 小时的话,则不会进行 Failover,之所以这样限制是为了避免 ping-pong 效应。
该参数代表忽略上次 MHA 触发切换产生的文件,默认情况下,MHA 发生切换后会在日志目
录,也就是上面我设置的/data 产生 app1.failover.complete 文件,下次再次切换的时候如果
发现该目录下存在该文件将不允许触发切换,除非在第一次切换后收到删除该文件,为了方
便,这里设置为--ignore_last_failover。
Server05(192.168.200.115)再次查看 Server05 监控是否正常:
[root@monitor ~]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:) is running(:PING_OK), master:server01 有PING_OK、表示已经在监控了
Primary Master(192.168.200.111)上操作:
[root@server01 ~]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.200.111/24 brd 192.168.200.255 scope global noprefixroute ens33
inet 192.168.200.100/24 brd 192.168.200.255 scope global secondary ens33:1
此时111作为master有了192.168.200.100的VIP
Server05(192.168.200.115)查看启动日志
[root@server05 ~]# cat /var/log/masterha/app1/manager.log
Wed Oct 23 09:31:46 2019 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Wed Oct 23 09:31:46 2019 - [info] Reading application default configurations from /etc/masterha/app1.cnf..
Wed Oct 23 09:31:46 2019 - [info] Reading server configurations from /etc/masterha/app1.cnf..
Wed Oct 23 09:31:46 2019 - [info] MHA::MasterMonitor version 0.56.
Wed Oct 23 09:31:47 2019 - [info] Dead Servers:
Wed Oct 23 09:31:47 2019 - [info] Alive Servers:
Wed Oct 23 09:31:47 2019 - [info] server01(192.168.200.111:3306)
Wed Oct 23 09:31:47 2019 - [info] server02(192.168.200.112:3306)
Wed Oct 23 09:31:47 2019 - [info] server03(192.168.200.113:3306)
Wed Oct 23 09:31:47 2019 - [info] server04(192.168.200.114:3306)
-------
-------------
Wed Oct 23 09:31:59 2019 - [info]
server01 (current master)
+--server02
+--server03
+--server04
Wed Oct 23 09:32:00 2019 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond..
**注意:其中"Ping(SELECT) succeeded, waiting until MySQL doesn't respond.."说明整个系统已经开始监控了**
Primary Master(192.168.200.111) 模拟主库故障
[root@server01 ~]# systemctl stop mariadb
[root@server01 ~]# netstat -lnpt | grep :3306
[root@server01 ~]# ip a | grep ens32
: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu qdisc pfifo_fast state UP group
default qlen
inet 192.168.200.111/ brd 192.168.200.255 scope global ens32
在113、114上都查看状态:
****如果当down了111时在113-114上看不到Master_Host: 192.168.200.112 且为111时并且报IO线程问题,就查看一下115能否通过ssh server02秘钥连接到112上
如果要输入密码就输入yes才能进入,就反复重启111-114的mariadb服务([root@server03 ~]# systemctl restart mariadb)***
像这样就是IO线程的ssh秘钥没问题
步骤:
[root@server03 ~]# systemctl restart mariadb #111-114都要重启
root@server05 ~]# ssh server02
Last login: Wed Oct 23 13:42:18 2019 from 192.168.200.2
[root@server05 ~]# nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover< /dev/null >/var/log/masterha/app1/manager.log 2>&1&
[6] 20465
[root@server05 ~]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:20465) is running(0:PING_OK), master:server01
[root@server02 ~]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.200.112/24 brd 192.168.200.255 scope global noprefixroute ens33
inet 192.168.200.100/24 brd 192.168.200.255 scope global secondary ens33:1
slave1(192.168.200.113、192.168.200.114)查看状态:
MariaDB [(none)]> show slave status\G
*************************** . row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.200.112 #发现此时VIP已经漂移到192.168.200.112上,112成为了master
Master_User: repl
Master_Port:
Connect_Retry:
Master_Log_File: master-bin.
Read_Master_Log_Pos:
Relay_Log_File: slave-relay-bin.
Relay_Log_Pos:
Relay_Master_Log_File: master-bin.
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Server05(192.168.200.115) 查看监控配置文件已经发生了变化([server01] 的配置已被删除):
[root@server05 ~]# cat /etc/masterha/app1.cnf
[server default]
manager_log=/var/log/masterha/app1/manager.log
manager_workdir=/var/log/masterha/app1
master_binlog_dir=/var/lib/mysql
master_ip_failover_script=/usr/local/bin/master_ip_failover
password=123123
ping_interval=1
remote_workdir=/tmp
repl_password=123123
repl_user=repl
user=root
[server2]
candidate_master=1
check_repl_delay=0
hostname=server02
port=3306
[server3]
hostname=server03
port=3306
[server4]
hostname=server04
port=3306
Server05(192.168.200.115) 故障切换过程中的日志文件内容如下:
[root@server05 ~]# tail -f /var/log/masterha/app1/manager.log
Selected server02 as a new master.
server02: OK: Applying all logs succeeded.
server02: OK: Activated master IP address.
server04: This host has the latest relay log events.
server03: This host has the latest relay log events.
Generating relay diff files from the latest slave succeeded.
server04: OK: Applying all logs succeeded. Slave started, replicating from server02.
server03: OK: Applying all logs succeeded. Slave started, replicating from server02.
server02: Resetting slave info succeeded.
Master failover to server02(192.168.200.112:) completed successfully.
故障 主库修复及 及 VIP 切回 测试
Primary Master(192.168.200.111)上操作 :
[root@server01 ~]# systemctl start mariadb
[root@server01 ~]# netstat -lnpt | grep :
tcp 0.0.0.0: 0.0.0.0:* LISTEN
/mysqld
Primary Master(192.168.200.111) 指向新的master库
[root@server01 ~]# mysql -u root -p123123
MariaDB [(none)]> start slave;
MariaDB [(none)]>CHANGE MASTER TO
>MASTER_HOST='192.168.200.112',
>MASTER_USER='repl',
>MASTER_PASSWORD='123123';
MariaDB [(none)]> start slave;
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.200.112
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: master-bin.000001
Read_Master_Log_Pos: 1372
Relay_Log_File: mariadb-relay-bin.000002
Relay_Log_Pos: 1208
Relay_Master_Log_File: master-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Server05(192.168.200.115) 修改监控配置文件重新添加 server1 配置:
[root@server05 ~]# vim /etc/masterha/app1.cnf
[server01]
hostname=server01
port=
Server05(192.168.200.115) 检查集群状态:
[root@server05 ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf
----------------------------------- 忽略部分信息-----------------------------------
Thu Aug :: - [info] Alive Servers:
Thu Aug :: - [info] server01(192.168.200.111:)
Thu Aug :: - [info] server02(192.168.200.112:)
Thu Aug :: - [info] server03(192.168.200.113:)
Thu Aug :: - [info] server04(192.168.200.114:)
----------------------------------- 忽略部分信息-----------------------------------
server02 (current master)
+--server01
+--server03
+--server04
----------------------------------- 忽略部分信息-----------------------------------
MySQL Replication Health is OK.
Server05(192.168.200.115) 开启监控
[root@server05 ~]# nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover< /dev/null >/var/log/masterha/app1/manager.log 2>&1&
[7] 22551
Secondary Master(192.168.200.112) 关闭现有主库 mysql
[root@server02 ~]# systemctl stop mariadb
[root@server02 ~]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.200.112/24 brd 192.168.200.255 scope global noprefixroute ens33
Primary Master(192.168.200.111):查看VIP有没有回来
[root@server01 ~]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.200.111/24 brd 192.168.200.255 scope global noprefixroute ens33
inet 192.168.200.100/24 brd 192.168.200.255 scope global secondary ens33:1
slave1(192.168.200.113、192.168.200.114)查看状态:
MariaDB [(none)]> show slave status\G
*************************** . row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.200.111
Master_User: repl
Master_Port:
Connect_Retry:
Master_Log_File: master-bin.
Read_Master_Log_Pos:
Relay_Log_File: slave-relay-bin.
Relay_Log_Pos:
Relay_Master_Log_File: master-bin.
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Server05(192.168.200.115) 配置文件变化(已经移除故障机 server2 配置):
[root@server05 ~]# cat /etc/masterha/app1.cnf
[server default]
manager_log=/var/log/masterha/app1/manager.log
manager_workdir=/var/log/masterha/app1
master_binlog_dir=/var/lib/mysql
master_ip_failover_script=/usr/local/bin/master_ip_failover
password=
ping_interval=
remote_workdir=/tmp
repl_password=
repl_user=repl
user=root
[server1]
hostname=server01
port=
[server3]
hostname=server03
port=
[server4]
hostname=server04
port=
十、 配置读请求负载均衡
10.1 、 安装 LVS 和 Keepalived
192.168.200.116 和 192.168.200.117 主机:
yum -y install ipvsadm kernel-devel openssl-devel keepalived
10.2、 master 主机设置
192.168.200.116 lvs master 主机配置:
[root@server06 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
route_id 192.168.200.116
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval
vrrp_gna_interval
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id
priority
advert_int
authentication {
auth_type PASS
auth_pass
}
virtual_ipaddress {
192.168.200.200
}
}
virtual_server 192.168.200.200 {
delay_loop
lb_algo wrr
lb_kind DR
protocol TCP
real_server 192.168.200.113 {
weight
TCP_CHECK {
connect_timeout
nb_get_retry
delay_before_retry
connect_port
}
}
real_server 192.168.200.114 {
weight
TCP_CHECK {
connect_timeout
nb_get_retry
delay_before_retry
connect_port
}
}
}
[root@server06 ~]# systemctl restart keepalived
检查VIP地址:
[root@server06 ~]# ip a | grep ens33
: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu qdisc pfifo_fast state UP group default qlen
inet 192.168.200.116/ brd 192.168.200.255 scope global noprefixroute ens33
inet 192.168.200.200/ scope global ens33
查看负载策略:
[root@server06 ~]# ipvsadm -Ln
IP Virtual Server version 1.2. (size=)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.200.200: wrr
-> 192.168.200.113: Route
-> 192.168.200.114: Route
10.3 、192.168.200.117 backup 主机设置:
[root@server07 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
route_id 192.168.200.122
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval
vrrp_gna_interval
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id
priority
advert_int
authentication {
auth_type PASS
auth_pass
}
virtual_ipaddress {
192.168.200.200
}
}
virtual_server 192.168.200.200 {
delay_loop
lb_algo wrr
lb_kind DR
protocol TCP
real_server 192.168.200.113 {
weight
TCP_CHECK {
connect_timeout
nb_get_retry
delay_before_retry
connect_port
}
}
real_server 192.168.200.114 {
weight
TCP_CHECK {
connect_timeout
nb_get_retry
delay_before_retry
connect_port
}
}
}
10.4 、为数据库节点设置 VIP 地址及配置 ARP 相关参数:
slave1(192.168.200.113)和 slave2(192.168.200.114)主机配置 realserver 脚本:
[root@server03 ~]# vim realserver.sh
#!/bin/bash
SNS_VIP=192.168.200.200
ifconfig lo: $SNS_VIP netmask 255.255.255.255 broadcast $SNS_VIP
/sbin/route add -host $SNS_VIP dev lo:0
echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/all/arp_announce
sysctl -p >/dev/null 2>&1
realserver1(192.168.200.113) 检测 VIP 地址:
[root@server03 ~]# ip a | grep lo
: lo: <LOOPBACK,UP,LOWER_UP> mtu qdisc noqueue state UNKNOWN group default qlen
link/loopback ::::: brd :::::
inet 127.0.0.1/ scope host lo
inet 192.168.200.200/ brd 192.168.200.200 scope global lo:
inet 192.168.200.113/ brd 192.168.200.255 scope global noprefixroute ens33
inet 192.168.122.1/ brd 192.168.122.255 scope global virbr0 远程复制到 realserver2 主机上:192.168.200.114:
[root@server03 ~]# scp realserver.sh 192.168.200.114:/root/
realserver.sh 100% 378 183.1KB/s 00:00
realserver1(192.168.200.113) 检测 VIP 地址:
[root@server04 ~]# bash realserver.sh
[root@server04 ~]# ip a | grep lo
: lo: <LOOPBACK,UP,LOWER_UP> mtu qdisc noqueue state UNKNOWN group default qlen
link/loopback ::::: brd :::::
inet 127.0.0.1/ scope host lo
inet 192.168.200.200/ brd 192.168.200.200 scope global lo:
inet 192.168.200.114/ brd 192.168.200.255 scope global noprefixroute ens33
inet 192.168.122.1/ brd 192.168.122.255 scope global virbr0
10.5 、数据库读请求测试:
Server05(192.168.200.115)担任 client 角色测试,连接 vip
[root@server05 ~]# mysql -uroot -p123123 -h192.168.200.200 -P3306
Enter password: ###密码为123123
ERROR (): Unknown database ''
[root@server05 ~]# mysql -uroot -p123123 -h192.168.200. -P3306
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is
Server version: 5.5.-MariaDB MariaDB Server Copyright (c) , , Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MariaDB [(none)]> exit
Bye 断开后再连接测试一次为了更好的看清请求分流情况。。。。
[root@server05 ~]# mysql -uroot -p123123 -h192.168.200.200 -P3306
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 522
Server version: 5.5.64-MariaDB MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]>
查看分流情况:
[root@server06 ~]# ipvsadm -Lnc
IPVS connection entries
pro expire state source virtual destination
TCP 00:54 FIN_WAIT 192.168.200.115:42558 192.168.200.200:3306 192.168.200.113:3306
TCP 13:56 ESTABLISHED 192.168.200.115:42560 192.168.200.200:3306 192.168.200.114:3306
查看此时111的VIP状态: #可以做一个周期计划用于关闭防火墙机制(111-114-116-117):
[root@server01 ~]# ip a | grep ens33
: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu qdisc pfifo_fast state UP group default qlen
inet 192.168.200.111/ brd 192.168.200.255 scope global noprefixroute ens33
inet 192.168.200.100/ brd 192.168.200.255 scope global secondary ens33:
**MAH高可用MYSQL搭建完成**
基于MHA的MYSQL高可用方案的更多相关文章
- MHA的MySQL高可用方案实战
功能: 1)master的故障切换(keepalived VIP的飘移) 2)主从复制角色的提升和重新转向 其中master 对外提供写服务,备选master2(实际的slave提供读服务,slave ...
- MySQL高可用方案-PXC环境部署记录
之前梳理了Mysql+Keepalived双主热备高可用操作记录,对于mysql高可用方案,经常用到的的主要有下面三种: 一.基于主从复制的高可用方案:双节点主从 + keepalived 一般来说, ...
- mysql高可用方案MHA介绍
mysql高可用方案MHA介绍 概述 MHA是一位日本MySQL大牛用Perl写的一套MySQL故障切换方案,来保证数据库系统的高可用.在宕机的时间内(通常10-30秒内),完成故障切换,部署MHA, ...
- MySQL高可用方案MHA的部署和原理
MHA(Master High Availability)是一套相对成熟的MySQL高可用方案,能做到在0~30s内自动完成数据库的故障切换操作,在master服务器不宕机的情况下,基本能保证数据的一 ...
- MySQL高可用方案MHA自动Failover与手动Failover的实践及原理
集群信息 角色 IP地址 ServerID 类型 Master ...
- MySQL高可用方案--MHA部署及故障转移
架构设计及必要配置 主机环境 IP 主机名 担任角色 192.168.192.128 node_master MySQL-Master| ...
- MySQL高可用方案MHA在线切换的步骤及原理
在日常工作中,会碰到如下的场景,如mysql数据库升级,主服务器硬件升级等,这个时候就需要将写操作切换到另外一台服务器上,那么如何进行在线切换呢?同时,要求切换过程短,对业务的影响比较小. MHA就提 ...
- mysql高可用方案总结性说明
MySQL的各种高可用方案,大多是基于以下几种基础来部署的(也可参考:Mysql优化系列(0)--总结性梳理 该文后面有提到)1)基于主从复制:2)基于Galera协议(PXC):3)基于NDB引 ...
- [转载] MySQL高可用方案选型参考
原文: http://imysql.com/2015/09/14/solutions-of-mysql-ha.shtml?hmsr=toutiao.io&utm_medium=toutiao. ...
随机推荐
- please execute the cleanup command
解决方法: (1)用dos命令进入项目文件夹,运行svn cleanup:不要直接右键点击找cleanup选项 (2)到上一层目录去cleanup试下,或者到.svn文件夹下(隐藏的)找到所有的loc ...
- ubuntu19.04 配置远程连接ssh
安装ssh-server sudo apt install openssh-server 参照:https://baijiahao.baidu.com/s?id=1631505486531979316 ...
- 03-Java基础语法【 流程控制语句】
重要知识记录: 1.流程控制 顺序结构:根据编写的顺序,从上到下进行运行. 2.判断语句 1)判断语句1--if if(判断条件){ 执行语句: } 2)判断语句2--if...else if(判断条 ...
- IntelliJ IDEA 2017.3尚硅谷-----创建的静态 Java Web
- python之路之io多路复用
1.实现io多路复用利用select s1同时接受三个客户端(开启了三个服务器端口) #!/usr/bin/env python # -*- coding: utf-8 -*- import sock ...
- Bootstrap框架学习
Bootstrap框架个人总结 https://blog.csdn.net/To_Front_End/article/details/51142716 Bootstrap 教程 https://www ...
- STM32F103之DMA学习记录
/================翻译STM32F103开发手册DMA章节===========================/ 13 DMA(Direct memory access) 13.1 ...
- torch.cat拼接 stack拼接 分块chunk
torch.cat拼接 stack拼接 分块chunk 待办 https://blog.csdn.net/qq_39709535/article/details/80803003 stack dim理 ...
- Android开发实战——记账本(4)
开发日志(4)——MainActivity 在MainActivity中编写了几个方法.首先,点击账本的一条记录可以选择删除他,然后重写了fab,使之在点击他后能够添加记录.还写了删除全部记录的方法. ...
- 期货、期权tick数据接收
功能: 1.开启之后,7*24自动运行. 2.在共享内存中存放当个交易日的tick数据,方便随时取用. 3.支持多行情源取数据.经过测试一个行情源峰值带宽要求为20M,所以使用时要配合带宽限制. 4. ...