pytorch adam 源码 关于优化函数的调整 optimizer 调参 重点
关于优化函数的调整
拆下包:https://ptorch.com/docs/1/optim
class torch.optim.Optimizer(params, defaults)
所有优化的基类.
参数:
params (iterable) —— 可迭代的Variable 或者 dict。指定应优化哪些变量。
defaults-(dict):包含优化选项的默认值的dict(一个参数组没有指定的参数选项将会使用默认值)。
load_state_dict(state_dict)
加载optimizer状态
参数:
state_dict (dict) —— optimizer的状态。应该是state_dict()调用返回的对象。
state_dict()
将优化器的状态返回为一个dict。
它包含两个内容:
state - 持有当前optimization状态的dict。它包含了 优化器类之间的不同。
param_groups - 一个包含了所有参数组的dict。
step(closure)
执行单个优化步骤(参数更新)。
不同的优化算子
参考:莫烦大神视频,传送门不给直接百度搜就好;
首先给出基本的四种更换优化算子的代码:
SGD 就是随机梯度下降
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
momentum 动量加速,在SGD函数里指定momentum的值即可
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
RMSprop 指定参数alpha
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
Adam 参数betas=(0.9, 0.99)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
#再看下官方文档
class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)[source]
实现Adam算法。
它在Adam: A Method for Stochastic Optimization中被提出。
#参数:
params (iterable) – 用于优化的可以迭代参数或定义参数组
lr (float, 可选) – 学习率(默认:1e-3)
betas (Tuple[float, float], 可选) – 用于计算梯度运行平均值及其平方的系数(默认:0.9, 0.999)
eps (float, 可选) – 增加分母的数值以提高数值稳定性(默认:1e-8)
weight_decay (float, 可选) – 权重衰减(L2范数)(默认: 0)
step(closure) #执行单个优化步骤。
#参数:
closure (callable,可选) – 重新评估模型并返回损失的闭包。
注意:momentum是梯度下降法中一种常用的加速技术。对于一般的SGD,其表达式为,沿负梯度方向下降。而带momentum项的SGD则写生如下形式:
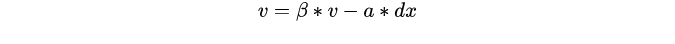
其中即momentum系数,通俗的理解上面式子就是,如果上一次的momentum(即)与这一次的负梯度方向是相同的,那这次下降的幅度就会加大,所以这样做能够达到加速收敛的过程。
关于学习率的调整
首先在一开始的时候我们可以给我们的神经网络附一个“经验性”的学习率:
lr=1e-3 #SGD
lr=1e-3 #Adam一般要求学习率比较小
接着,假设对于不同层想给予不同的学习率怎么办呢?
参考:https://www.cnblogs.com/hellcat/p/8496727.html
# 直接对不同的网络模块制定不同学习率 classifiter的学习率设置为1e-2,所有的momentum=0.9
optimizer = optim.SGD([{‘params’: net.features.parameters()}, # 默认lr是1e-5
{‘params’: net.classifiter.parameters(), ‘lr’: 1e-2}], lr=1e-5,momentum=0.9)
##=======================以层为单位,为不同层指定不同的学习率
## 提取指定层对象为classifiter模块的第0个和第3个
special_layers = t.nn.ModuleList([net.classifiter[0], net.classifiter[3]])
## 获取指定层参数id
special_layers_params = list(map(id, special_layers.parameters()))
print(special_layers_params)
## 获取非指定层的参数id
base_params = filter(lambda p: id§ not in special_layers_params, net.parameters())
optimizer = t.optim.SGD([{‘params’: base_params},
{‘params’: special_layers.parameters(), ‘lr’: 0.01}], lr=0.001)
当你发现你的loss在训练过程中居然还上升了,那么一般来讲,是你此时的学习率设置过大了。这时候我们需要动态调整我们的学习率:
def adjust_learning_rate(optimizer, epoch, t=10):
“”“Sets the learning rate to the initial LR decayed by 10 every t epochs,default=10"”"
new_lr = lr * (0.1 ** (epoch // t))
for param_group in optimizer.param_groups:
param_group[‘lr’] = new_lr
官方文档中还给出用
torch.optim.lr_scheduler 基于循环的次数提供了一些方法来调节学习率.
torch.optim.lr_scheduler.ReduceLROnPlateau 基于验证测量结果来设置不同的学习率.
参考:https://ptorch.com/docs/1/optim
其他调参的策略
1.L2-正则化防止过拟合
weight decay(权值衰减),其最终目的是防止过拟合。在机器学习或者模式识别中,会出现overfitting,而当网络逐渐overfitting时网络权值逐渐变大,因此,为了避免出现overfitting,会给误差函数添加一个惩罚项,常用的惩罚项是所有权重的平方乘以一个衰减常量之和。其用来惩罚大的权值。在损失函数中,weight decay是放在正则项(regularization)前面的一个系数,正则项一般指示模型的复杂度,所以weight decay的作用是调节模型复杂度对损失函数的影响,若weight decay很大,则复杂的模型损失函数的值也就大。
这个在定义优化器的时候可以通过参数 【weight_decay,一般建议0.0005】来设置:
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99), eps=1e-06, weight_decay=0.0005)
2、batch normalization。batch normalization的是指在神经网络中激活函数的前面,将按照特征进行normalization,这样做的好处有三点:
提高梯度在网络中的流动。Normalization能够使特征全部缩放到[0,1],这样在反向传播时候的梯度都是在1左右,避免了梯度消失现象。
提升学习速率。归一化后的数据能够快速的达到收敛。
减少模型训练对初始化的依赖。
减少参数选择的依赖
一些通常的解释:https://blog.csdn.net/hjimce/article/details/50866313
3、加入dropout层:dropout一般设置为0.5
4、集成方法
最后,在训练过程中关于loss的一些说明:
参考:https://blog.csdn.net/LIYUAN123ZHOUHUI/article/details/74453980
1 train loss 不断下降,test loss 不断下降,说明网络正在学习
2 train loss 不断下降,test loss 趋于不变,说明网络过拟合
3 train loss 趋于不变,test loss 趋于不变,说明学习遇到瓶颈,需要减小学习率或者批处理大小
4 train loss 趋于不变,test loss 不断下降,说明数据集100%有问题
5 train loss 不断上升,test loss 不断上升(最终变为NaN),可能是网络结构设计不当,训练超参数设置不当,程序bug等某个问题引起
作者:angnuan123
来源:CSDN
原文:https://blog.csdn.net/angnuan123/article/details/81604727
版权声明:本文为博主原创文章,转载请附上博文链接!
相关文章
pytorch adam 源码 关于优化函数的调整 optimizer 调参 重点的更多相关文章
- 梯度下降优化算法综述与PyTorch实现源码剖析
现代的机器学习系统均利用大量的数据,利用梯度下降算法或者相关的变体进行训练.传统上,最早出现的优化算法是SGD,之后又陆续出现了AdaGrad.RMSprop.ADAM等变体,那么这些算法之间又有哪些 ...
- pytorch bert 源码解读
https://daiwk.github.io/posts/nlp-bert.html 目录 概述 BERT 模型架构 Input Representation Pre-training Tasks ...
- [源码解析] PyTorch分布式优化器(1)----基石篇
[源码解析] PyTorch分布式优化器(1)----基石篇 目录 [源码解析] PyTorch分布式优化器(1)----基石篇 0x00 摘要 0x01 从问题出发 1.1 示例 1.2 问题点 0 ...
- [源码解析] PyTorch分布式优化器(2)----数据并行优化器
[源码解析] PyTorch分布式优化器(2)----数据并行优化器 目录 [源码解析] PyTorch分布式优化器(2)----数据并行优化器 0x00 摘要 0x01 前文回顾 0x02 DP 之 ...
- [源码解析] PyTorch分布式优化器(3)---- 模型并行
[源码解析] PyTorch分布式优化器(3)---- 模型并行 目录 [源码解析] PyTorch分布式优化器(3)---- 模型并行 0x00 摘要 0x01 前文回顾 0x02 单机模型 2.1 ...
- ELMo解读(论文 + PyTorch源码)
ELMo的概念也是很早就出了,应该是18年初的事情了.但我仍然是后知后觉,居然还是等BERT出来很久之后,才知道有这么个东西.这两天才仔细看了下论文和源码,在这里做一些记录,如果有不详实的地方,欢迎指 ...
- [源码解析] PyTorch 流水线并行实现 (1)--基础知识
[源码解析] PyTorch 流水线并行实现 (1)--基础知识 目录 [源码解析] PyTorch 流水线并行实现 (1)--基础知识 0x00 摘要 0x01 历史 1.1 GPipe 1.2 t ...
- [源码解析] PyTorch 分布式之弹性训练(2)---启动&单节点流程
[源码解析] PyTorch 分布式之弹性训练(2)---启动&单节点流程 目录 [源码解析] PyTorch 分布式之弹性训练(2)---启动&单节点流程 0x00 摘要 0x01 ...
- [源码解析] PyTorch 分布式之弹性训练(4)---Rendezvous 架构和逻辑
[源码解析] PyTorch 分布式之弹性训练(4)---Rendezvous 架构和逻辑 目录 [源码解析] PyTorch 分布式之弹性训练(4)---Rendezvous 架构和逻辑 0x00 ...
随机推荐
- ssh连接超时中断问题解决方案
当在终端使用ssh命令连接到服务器时,如果一段时间没有活动连接会被中断,以下有两种方案可以解决: 一.修改ssh客户端配置 编辑客户端 /etc/ssh/ssh_config (或~/.ssh/con ...
- free内存监控
语 法: free [-bkmotV][-s <间隔秒数>] 补充说明:free指令会显示内存的使用情况,包括实体内存,虚拟的交换文件内存,共享内存区段,以及系统核心使用的缓冲区等. 参 ...
- The method getTextContent() is undefined ?
晚上下班的时候,把班上写了半截的代码带了回来.结果回到家后出乎意料的是回来的时候将代码导入eclipse后,下面这行代码就直接报错了,显示 getTextContent()未定义 . ((Elemen ...
- 使用DIV+CSS布局网站的优点和缺陷
随着WEB2.0标准化设计理念的普及,国内很多大型门户网站已经纷纷采用DIV+CSS制作方法,从实际应用情况来看,此种方法绝对好于表格制作页面的方法. 如今大部分网站仍然采用表格嵌套内容的方式来制作网 ...
- BootstrapValidation一些tips
BootstrapValidation一些tips:1. callback的用法 如果你有一些特别的检查需要,比如两个元素必需有一个有值,你可以在两个元素上加上callback,例:sel和cb必需有 ...
- 如何用SPSS分析学业情绪量表数据
如何用SPSS分析学业情绪量表数据 1.数据检验.由于问卷.量表的题目是主观判断和选择,因而难免有些人不认真填,所以,筛选出有效.高质量的数据非常关键.通常需要作如下检查:(1)是否有人回答互相矛盾, ...
- 【转载】遗传算法及matlab实现
摘自https://www.cnblogs.com/LoganChen/p/7509702.html 1.遗传算法介绍 遗传算法,模拟达尔文进化论的自然选择和遗产学机理的生物进化构成的计算模型,一种不 ...
- nodeJs学习-19 个人博客案例-(1)数据字典
智能社视频27.28 数据字典: 定义: url 300字 admin_table 管理员用户表 ID username varchar(32) password varchar(32) banner ...
- TCP/IP 协议栈学习代码
全部代码 直接使用socket 客户端 import java.io.*; import java.net.Inet4Address; import java.net.InetSocketAddres ...
- 2019-8-31-dotnet-方法名-To-和-As-有什么不同
title author date CreateTime categories dotnet 方法名 To 和 As 有什么不同 lindexi 2019-08-31 16:55:58 +0800 2 ...