分布式任务调度XXL-JOB初体验
简介
XXL-JOB是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
官方文档很完善,不多赘述。本文主要是搭建XXL-JOB和简单使用的记录。
搭建xxl-job-admin管理端
运行环境
- Ubuntu 16.04 64位
- Mysql 5.7
安装Mysql
$ sudo apt-get update
$ sudo apt-get install mysql-server
## 设置mysql,主要是安全方面的,密码策略等
$ mysql_secure_installation
## 配置远程访问
$ sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
bind-address = 0.0.0.0
$ sudo service mysql restart
$ sudo service mysql status
● mysql.service - MySQL Community Server
Loaded: loaded (/lib/systemd/system/mysql.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2019-06-05 13:23:41 HKT; 45s ago
...
创建数据库
$ mysql -u root -p
mysql> CREATE database if NOT EXISTS `xxl-job` default character set utf8 collate utf8_general_ci;
创建用户
$ mysql -u root -p
mysql> CREATE USER 'xxl-job'@'%' IDENTIFIED BY 'xxlJob2019@';
mysql> GRANT ALL PRIVILEGES ON `xxl-job`.* TO 'xxl-job'@'%';
本地测试xxl-job-admin
拉取最新源码
$ git clone git@github.com:xuxueli/xxl-job.git
$ cd xxl-job
导入项目
我比较熟悉Idea开发工具,所以这里使用Idea的Gradle项目进行演示。
打开xxl-job,项目结构如下
测试项目
打开xxl-job-admin/resources/application.properties,修改mysql连接信息
### xxl-job, datasource
spring.datasource.url=jdbc:mysql://192.168.32.129:3306/xxl-job?Unicode=true&characterEncoding=UTF-8
spring.datasource.username=xxl-job
spring.datasource.password=xxlJob2019@
使用/xxl-job/doc/db/tables_xxl_job.sql初始化数据库,初始化完应该如下图
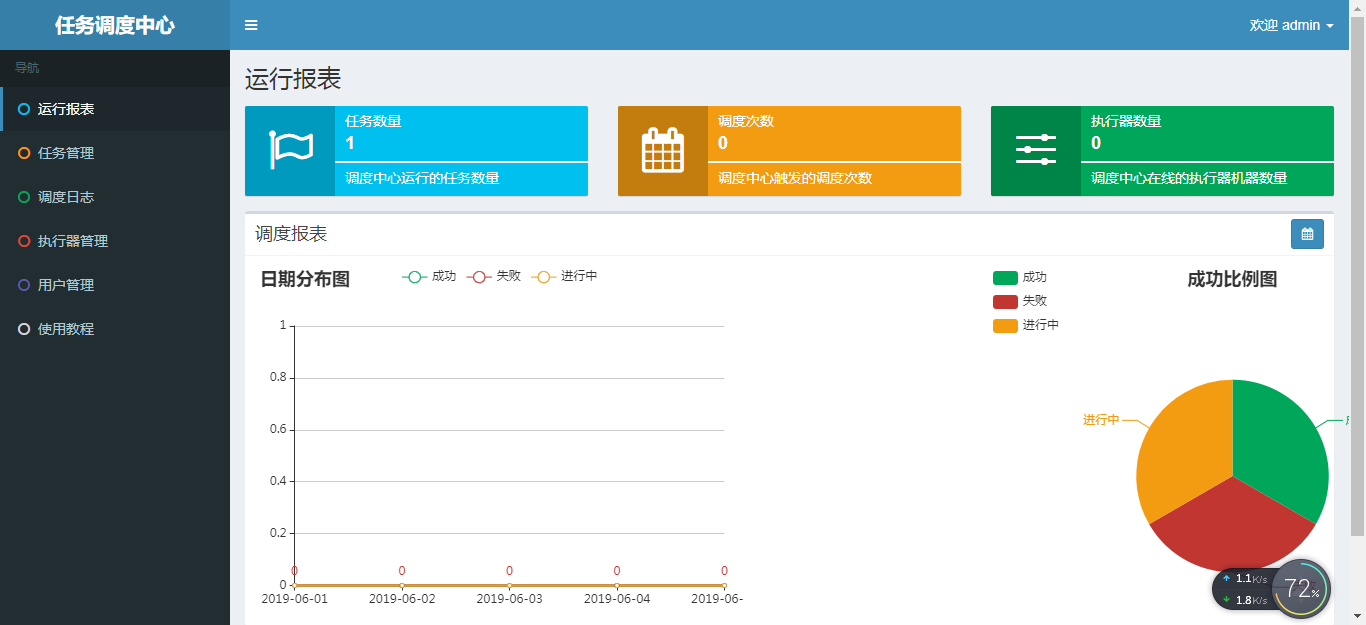
准备就绪后,就可以启动项目了,然后打开地址http://localhost:8080/xxl-job-admin将会看到首页
部署
打包调度中心
$ cd /xxl-job
$ mvn install
...
[INFO] xxl-job ............................................ SUCCESS [ 0.513 s]
[INFO] xxl-job-core ....................................... SUCCESS [ 4.258 s]
[INFO] xxl-job-admin ...................................... SUCCESS [ 5.525 s]
[INFO] xxl-job-executor-samples ........................... SUCCESS [ 0.016 s]
[INFO] xxl-job-executor-sample-spring ..................... SUCCESS [ 2.188 s]
[INFO] xxl-job-executor-sample-springboot ................. SUCCESS [ 0.892 s]
[INFO] xxl-job-executor-sample-jfinal ..................... SUCCESS [ 1.753 s]
[INFO] xxl-job-executor-sample-nutz ....................... SUCCESS [ 1.316 s]
[INFO] xxl-job-executor-sample-frameless .................. SUCCESS [ 0.358 s]
[INFO] xxl-job-executor-sample-jboot ...................... SUCCESS [ 1.279 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 18.549 s
[INFO] Finished at: 2019-06-05T14:40:25+08:00
[INFO] ------------------------------------------------------------------------
看到以上信息,说明我们打包成功了,在/xxl-job/xxl-job-admin目录下会存在jar文件:xxl-job-admin-2.1.0-SNAPSHOT.jar
部署到服务器
$ sudo apt install openjdk-8-jdk
$ java -version
openjdk version "1.8.0_212"
OpenJDK Runtime Environment (build 1.8.0_212-8u212-b03-0ubuntu1.16.04.1-b03)
OpenJDK 64-Bit Server VM (build 25.212-b03, mixed mode)
$ sudo mkdir -p /data/xxl-job
$ sudo cd /data/xxl-job
## 上传我们打包好的jar至此目录,并添加软连接
$ sudo ln -s xxl-job-admin-2.1.0-SNAPSHOT.jar current.jar
## 注册为system服务,可以达到异常重启,开机自启等目的
$ sudo vim /etc/systemd/system/xxl-job.service
[Unit]
Description=xxl-job Service Daemon
After=mysql.service
[Service]
Environment="JAVA_OPTS= -Xmx1024m -Xms1024m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:NewRatio=3 -Dserver.port=8081"
# java要写绝对路径
ExecStart=/usr/local/jdk/bin/java -jar /data/xxl-job/current.jar
Restart=always
WorkingDirectory=/data/xxl-job/
[Install]
WantedBy=multi-user.target
$ sudo systemctl enable xxl-job.service
$ sudo service xxl-job start
$ sudo service xxl-job status
● xxl-job.service - xxl-job Service Daemon
Loaded: loaded (/etc/systemd/system/xxl-job.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2019-07-18 18:19:08 CST; 2min 19s ago
Main PID: 27572 (java)
CGroup: /system.slice/xxl-job.service
└─27572 /usr/local/jdk/bin/java -jar /data/xxl-job/current.jar
我们访问一下http://192.168.32.129:8080/xxl-job-admin:
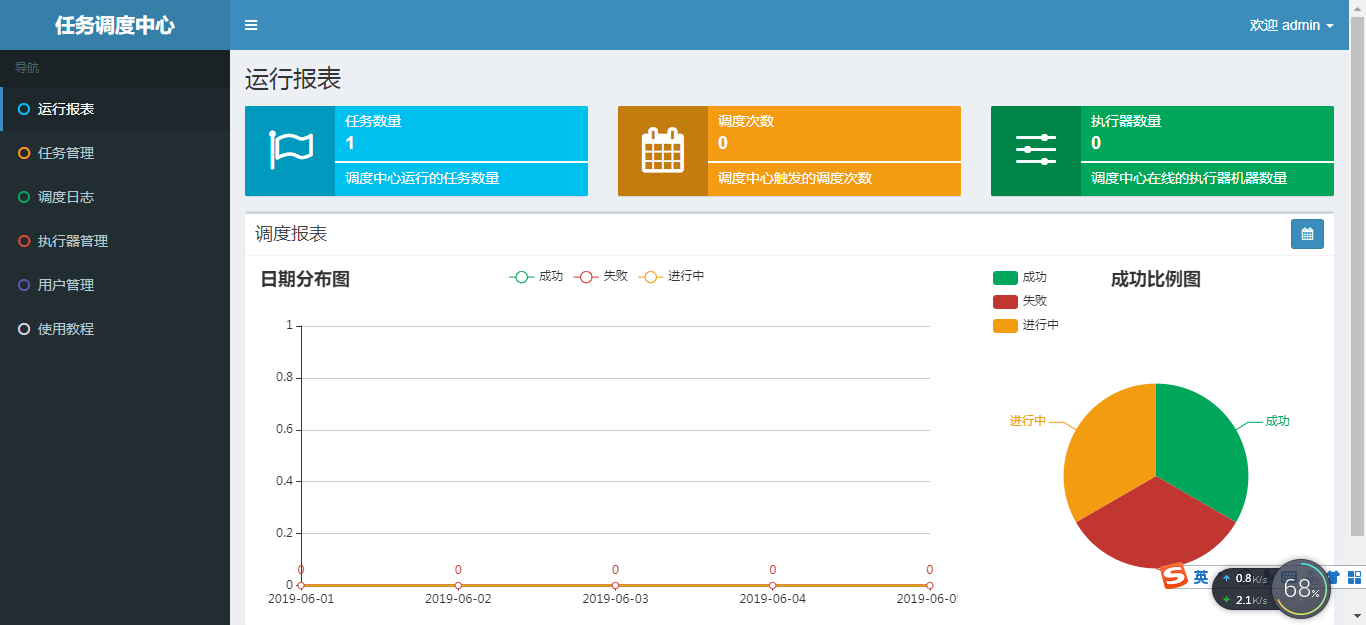
测试任务调度
以上,我们的任务调度管理端已经搭建完成,接下来,让我们测试下任务调度。
直接使用自带的SpringBoot测试项目xxl-job-executor-sample-springboot进行测试,修改配置文件
xxl-job-executor-sample-springboot=http://192.168.32.129:8080/xxl-job-admin
自定义任务
编写一个简单的任务,打印100次当前序列
package com.xxl.job.executor.service.jobhandler;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.IJobHandler;
import com.xxl.job.core.handler.annotation.JobHandler;
import com.xxl.job.core.log.XxlJobLogger;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeUnit;
/**
* TODO
*
* @author gaochen
* @date 2019/6/5
*/
@JobHandler(value="gcddJobHandler")
@Component
public class GcddJobHandler extends IJobHandler {
@Override
public ReturnT<String> execute(String param) throws Exception {
for (int i = 0; i < 100; i++) {
XxlJobLogger.log("XXL-JOB, print " + i);
TimeUnit.SECONDS.sleep(1);
}
return SUCCESS;
}
}
启动执行器
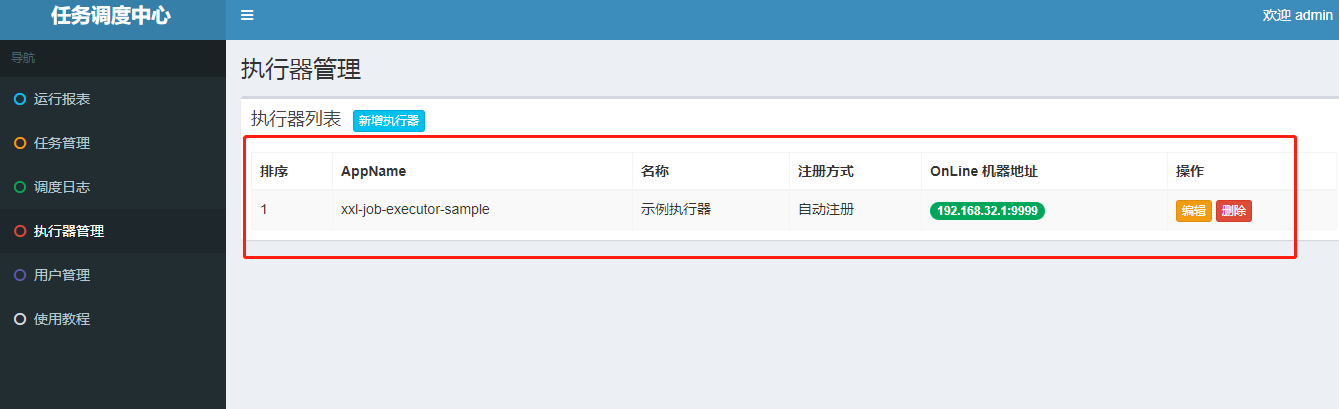
然后启动执行器,启动完成后,我们会发现管理页面的执行器列表会多出我们刚才启动的执行器
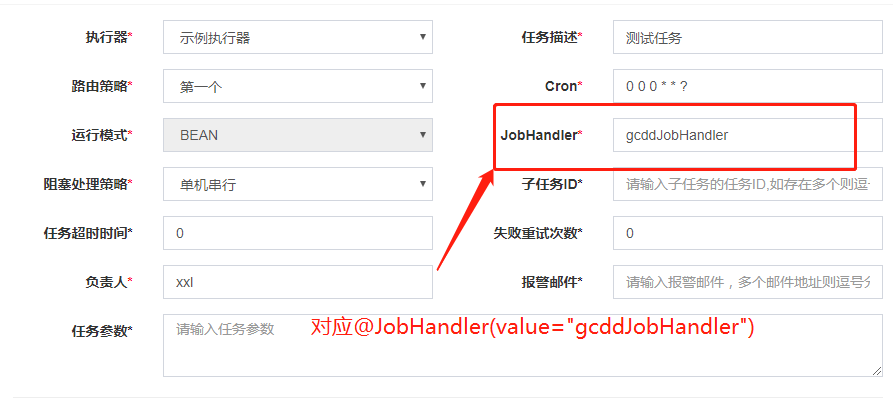
添加任务
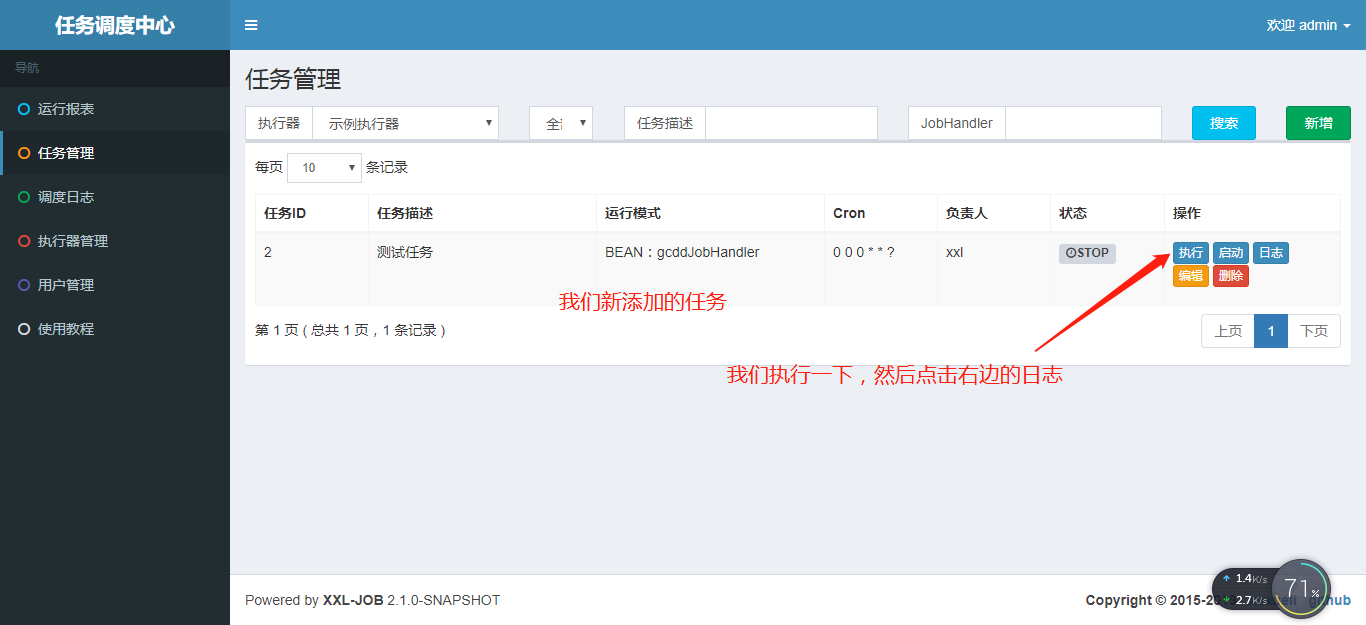
查看任务执行日志
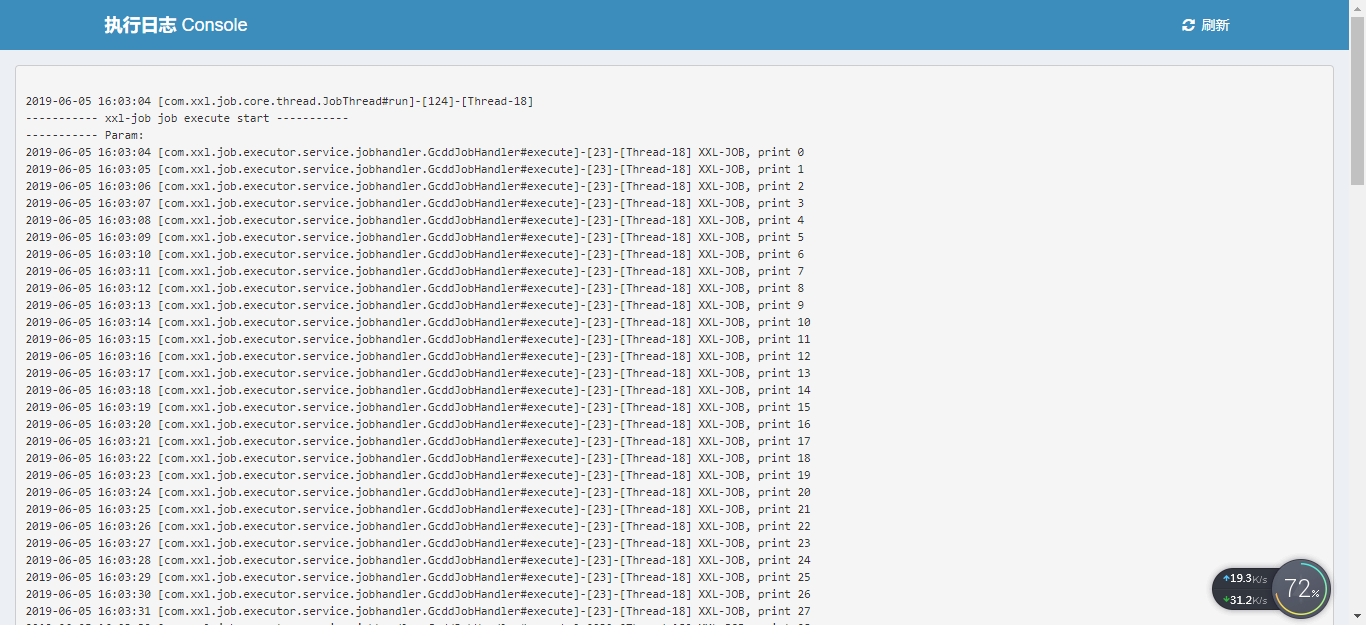
可以看到,任务已经按照我们的规划执行成功了,非常的方便。
结语
想要了解更详细的内容,请访问xxl-job官网
分布式任务调度XXL-JOB初体验的更多相关文章
- 分布式NoSQL数据库MongoDB初体验-v5.0.5
概述 定义 MongoDB官网 https://www.mongodb.com/ 社区版最新版本5.0,其中5.2版本很快也要面世了 MongoDB GitHub源码 https://github.c ...
- 全分布式的Hadoop初体验
背景 之前的时间里对 Hadoop 的使用都是基于学长所搭建起的实验环境的,没有完整的自己部署和维护过,最近抽时间初体验了在集群环境下装机.配置.运行的全过程,梳理总结到本文中. 配置 内存:8G C ...
- 【Python3爬虫】爬取美女图新姿势--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- 【Python3爬虫】学习分布式爬虫第一步--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- 【docker Elasticsearch】Rest风格的分布式开源搜索和分析引擎Elasticsearch初体验
概述: Elasticsearch 是一个分布式.可扩展.实时的搜索与数据分析引擎. 它能从项目一开始就赋予你的数据以搜索.分析和探索的能力,这是通常没有预料到的. 它存在还因为原始数据如果只是躺在磁 ...
- .NET平台开源项目速览(15)文档数据库RavenDB-介绍与初体验
不知不觉,“.NET平台开源项目速览“系列文章已经15篇了,每一篇都非常受欢迎,可能技术水平不高,但足够入门了.虽然工作很忙,但还是会抽空把自己知道的,已经平时遇到的好的开源项目分享出来.今天就给大家 ...
- 文档数据库RavenDB-介绍与初体验
文档数据库RavenDB-介绍与初体验 阅读目录 1.RavenDB概述与特性 2.RavenDB安装 3.C#开发初体验 4.RavenDB资源 不知不觉,“.NET平台开源项目速览“系列文章已经1 ...
- 分布式任务调度平台XXL-JOB
<分布式任务调度平台XXL-JOB> 一.简介 1.1 概述 XXL-JOB是一个轻量级分布式任务调度框架,其核心设计目标是开发迅速.学习简单.轻量级.易扩展.现已开放源代码并 ...
- 分布式任务调度系统:xxl-job
任务调度,通俗来说实际上就是"定时任务",分布式任务调度系统,翻译一下就是"分布式环境下定时任务系统". xxl-job一个分布式任务调度平台,其核心设计目标是 ...
随机推荐
- Kafka动态配置实现原理解析
问题导读 Apache Kafka在全球各个领域各大公司获得广泛使用,得益于它强大的功能和不断完善的生态.其中Kafka动态配置是一个比较高频好用的功能,下面我们就来一探究竟. 动态配置是如何设计的? ...
- 超链接a标签的伪类选择器问题,Link标签与visited标签的失效问题(问题介绍与解决方法)。
<!DOCTYPE html>< html>< head> <meta charset="utf-8" /> < ...
- js实现表单的提交
<form action="" method="post" name="form"> <tr> ...
- 最好用的web端代码文本编辑器ACE
使用足够简单,功能足够强大,体验足够优秀 之前有一个系列文章介绍我在运维系统开发过程中用到的那些顺手的前端插件,总共发了四篇文章介绍了三个非常棒的插件,分别是bootstrap-duallistbox ...
- 设计模式-05建造者模式(Builder Pattern)
1.模式动机 比如我们要组装一台电脑,都知道电脑是由 CPU.主板.内存.硬盘.显卡.机箱.显示器.键盘和鼠标组成,其中非常重要的一点就是这些硬件都是可以灵活选择,但是组装步骤都是大同小异(可以组一个 ...
- Java的变量与常量
常量: 在程序运行期间,固定不变得量. 常量的分类: 字符串常量:凡是用双引号引起来的部分,叫做字符串常量.例如:“abc”.“Hello”.“123”. 整数常量:直接写上的数字,没有小数点.例如: ...
- C语言I作业1
1 你对软件工程专业或计算机科学与技术专业了解是怎样的? 软件工程顾名思义就是工程化的方法生产软件的一门学科.涉及到程序设计语言,数据库,软件开发工具,系统平台,标准,设计模式等方面. 2 你了解c语 ...
- 场景6:具有OpenvSwitch的提供商网络
此场景描述了使用带有Open vSwitch(OVS)的ML2插件的OpenStack网络服务的提供者网络实现. 在OpenStack网络引入分布式虚拟路由器之前,所有网络通信都通过一个或多个专门的网 ...
- 用tensorflow构建神经网络学习简单函数
目标是学习\(y=2x+3\) 建立一个5层的神经网络,用平方误差作为损失函数. 代码如下: import tensorflow as tf import numpy as np import tim ...
- Kafka系列2:深入理解Kafka消费者
Kafka系列2:深入理解Kafka消费者 上篇聊了Kafka概况,包含了Kafka的基本概念.设计原理,以及设计核心.本篇单独聊聊Kafka的消费者,包括如下内容: 生产者是如何生产消息 如何创建生 ...