集合框架—HashMap
HashMap提供了三个构造函数:
HashMap():构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap。
HashMap(int initialCapacity):构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap。
HashMap(int initialCapacity, float loadFactor):构造一个带指定初始容量和加载因子的空 HashMap。
在这里提到了两个参数:初始容量,加载因子。这两个参数是影响HashMap性能的重要参数,其中容量表示哈希表中桶的数量 [哈希桶(Hash Bucket):哈希表中同一个位置可能存有多个元素,多个key,以应对哈希冲突问题。这样,哈希表中的每个位置表示一个哈希桶。],初始容量是创建哈希表时的容量,加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度,它衡量的是一个散列表的空间的使用程度,负载因子越大表示散列表的装填程度越高,反之愈小。对于使用链表法的散列表来说,查找一个元素的平均时间是O(1+a),因此如果负载因子越大,对空间的利用更充分,然而后果是查找效率的降低;如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重浪费。系统默认负载因子为0.75,一般情况下我们是无需修改的。
数据结构
我们知道在Java中最常用的两种结构是数组和模拟指针(引用),几乎所有的数据结构都可以利用这两种来组合实现,HashMap也是如此。实际上HashMap是一个"链表散列",如下是它数据结构:
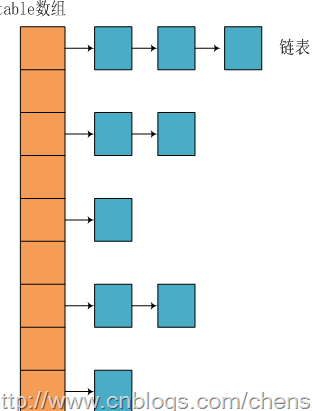
从上图我们可以看出HashMap底层实现还是数组,只是数组的每一项都是一条链。其中参数initialCapacity就代表了该数组的长度。下面为HashMap构造函数的源码:

public HashMap(int initialCapacity, float loadFactor) { //初始容量不能<0
if (initialCapacity < 0) throw
new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); //初始容量不能 > 最大容量值,HashMap的最大容量值为2^30
if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; //负载因子不能 < 0
if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw
new IllegalArgumentException("Illegal load factor: " + loadFactor); // 计算出大于 initialCapacity 的最小的 2 的 n 次方值。
int capacity = 1; while (capacity < initialCapacity) capacity <<= 1; this.loadFactor = loadFactor; //设置HashMap的容量极限,当HashMap的容量达到该极限时就会进行扩容操作 threshold = (int) (capacity * loadFactor); //初始化table数组 table = new Entry[capacity]; init(); }
从源码中可以看出,每次新建一个HashMap时,都会初始化一个table数组。table数组的元素为Entry节点。

 static
static
class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; final
int hash; /** * Creates new entry. */ Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } ....... }
其中Entry为HashMap的内部类,它包含了键key、值value、下一个节点next,以及hash值,这是非常重要的,正是由于Entry才构成了table数组的项为链表。
上面简单分析了HashMap的数据结构,下面将探讨HashMap是如何实现快速存取的。
四、存储实现:put(key,vlaue)
首先我们先看源码

public V put(K key, V value) { //当key为null,调用putForNullKey方法,保存null与table第一个位置中,这是HashMap允许为null的原因
if (key == null) return putForNullKey(value); //计算key的hash值
int hash = hash(key.hashCode()); ------(1) //计算key hash 值在 table 数组中的位置
int i = indexFor(hash, table.length); ------(2) //从i出开始迭代 e,找到 key 保存的位置
for (Entry<K, V> e = table[i]; e != null; e = e.next) { Object k; //判断该条链上是否有hash值相同的(key相同) //若存在相同,则直接覆盖value,返回旧value
modCount++; //将key、value添加至i位置处 addEntry(hash, key, value, i); return
null; }
通过源码我们可以清晰看到HashMap保存数据的过程为:首先判断key是否为null,若为null,则直接调用putForNullKey方法。若不为空则先用hashCode()方法计算key的hash值,然后根据hash值搜索在table数组中的索引位置,如果table数组在该位置处有元素,哈希表中同一个位置可能存有多个元素,多个key,则通过equals()方法比较是否存在相同的key,若存在则覆盖原来key的value,否则将该元素保存在链头(最先保存的元素放在链尾)。若table在该处没有元素,则直接保存。所以:
(1)如果o1.equals(o2),那么o1.hashCode() == o2.hashCode()总是为true的。
(2)如果o1.hashCode() == o2.hashCode(),并不意味着o1.equals(o2)会为true。
这个过程看似比较简单,其实深有内幕。有如下几点:
1、
先看迭代处。此处迭代原因就是为了防止存在相同的key值,若发现两个hash值(key)相同时,HashMap的处理方式是用新value替换旧value,这里并没有处理key,这就解释了HashMap中没有两个相同的key。
2、
在看(1)、(2)处。这里是HashMap的精华所在。首先是hash方法,该方法为一个纯粹的数学计算,就是计算h的hash值。
static
int hash(int h) { h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }
我们知道对于HashMap的table而言,数据分布需要均匀(最好每项都只有一个元素,这样就可以直接找到),不能太紧也不能太松,太紧会导致查询速度慢,太松则浪费空间。计算hash值后,怎么才能保证table元素分布均与呢?我们会想到取模,但是由于取模的消耗较大,HashMap是这样处理的:调用indexFor方法。
static
int indexFor(int h, int length) { return h & (length-1); }
的n次方,在构造函数中存在:capacity <<= 1;这样做总是能够保证HashMap的底层数组长度为2的n次方。当length为2的n次方时,h&(length - 1)就相当于对length取模,而且速度比直接取模快得多,这是HashMap在速度上的一个优化。至于为什么是2的n次方下面解释。
我们回到indexFor方法,该方法仅有一条语句:h&(length - 1),这句话除了上面的取模运算外还有一个非常重要的责任:均匀分布table数据和充分利用空间。
所以说,当数组长度为2的n次幂的时候,不同的key算得得index相同的几率较小,
,h为5、6、7。

和7的结果一样,这样表示他们在table存储的位置是相同的,也就是产生了碰撞,6、7就会在一个位置形成链表,这样就会导致查询速度降低。诚然这里只分析三个数字不是很多,那么我们就看0-15。

此碰撞,同时发现浪费的空间非常大,有1、3、5、7、9、11、13、15处没有记录,也就是没有存放数据。这是因为他们在与14进行&运算时,得到的结果最后一位永远都是0,即0001、0011、0101、0111、1001、1011、1101、1111位置处是不可能存储数据的,空间减少,进一步增加碰撞几率,这样就会导致查询速度慢。而当length = 16时,length – 1 = 15 即1111,那么进行低位&运算时,值总是与原来hash值相同,而进行高位运算时,其值等于其低位值。所以说当length = 2^n时,不同的hash值发生碰撞的概率比较小,这样就会使得数据在table数组中分布较均匀,查询速度也较快。
这里我们再来复习put的流程:当我们想一个HashMap中添加一对key-value时,系统首先会计算key的hash值,然后根据hash值确认在table中存储的位置。若该位置没有元素,则直接插入。否则迭代该处元素链表并依此比较其key的hash值。如果两个hash值相等且key值相等(e.hash == hash && ((k = e.key) == key || key.equals(k))),则用新的Entry的value覆盖原来节点的value。如果两个hash值相等但key值不等
,则将该节点插入该链表的链头。具体的实现过程见addEntry方法,如下:


void addEntry(int hash, K key, V value, int bucketIndex) { //获取bucketIndex处的Entry Entry<K, V> e = table[bucketIndex]; //将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry table[bucketIndex] = new Entry<K, V>(hash, key, value, e); //若HashMap中元素的个数超过极限了,则容量扩大两倍
if (size++ >= threshold) resize(2 * table.length); }

 这个方法中有两点需要注意:
这个方法中有两点需要注意:
一是链的产生。这是一个非常优雅的设计。系统总是将新的Entry对象添加到bucketIndex处。如果bucketIndex处已经有了对象,那么新添加的Entry对象将指向原有的Entry对象,形成一条Entry链,但是若bucketIndex处没有Entry对象,也就是e==null,那么新添加的Entry对象指向null,也就不会产生Entry链了。
二、扩容问题。
随着HashMap中元素的数量越来越多,发生碰撞的概率就越来越大,所产生的链表长度就会越来越长,这样势必会影响HashMap的速度,为了保证HashMap的效率,系统必须要在某个临界点进行扩容处理。该临界点在当HashMap中元素的数量等于table数组长度*加载因子。但是扩容是一个非常耗时的过程,因为它需要重新计算这些数据在新table数组中的位置并进行复制处理。所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
hashmap的resize (扩容,按2的幂次方扩容)
那么hashmap什么时候进行扩容呢?当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面annegu已经说过,即使是1000,hashmap也自动会将其设置为1024。
但是new HashMap(1024)还不是更合适的,因为0.75*1000 < 1000, 也就是说为了让0.75 * size > 1000, 我们必须这样new HashMap(2048)才最合适,既考虑了&的问题,也避免了resize的问题。
HashMap和Hashtable的区别
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
- HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
- HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
- 另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
- 由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
- HashMap不能保证随着时间的推移Map中的元素次序是不变的。
- 仅在你需要完全的线程安全的时候使用Hashtable,而如果你使用Java 5或以上的话,请使用 ConcurrentHashMap吧。
集合框架—HashMap的更多相关文章
- Java自学-集合框架 HashMap
Java集合框架 HashMap 示例 1 : HashMap的键值对 HashMap储存数据的方式是-- 键值对 package collection; import java.util.HashM ...
- java集合框架 hashMap 简单使用
参考文章:http://blog.csdn.net/itm_hadf/article/details/7497462 通常,默认加载因子 (.75) 在时间和空间成本上寻求一种折衷. 加载因 ...
- Java自学-集合框架 HashMap和Hashtable的区别
HashMap和Hashtable之间的区别 步骤 1 : HashMap和Hashtable的区别 HashMap和Hashtable都实现了Map接口,都是键值对保存数据的方式 区别1: Hash ...
- Java8集合框架——HashMap源码分析
java.util.HashMap 本文目录: 一.HashMap 的特点概述和说明 二.HashMap 的内部实现:从内部属性和构造函数说起 三.HashMap 的 put 操作 四.HashMap ...
- 集合框架-HashMap&HashSet&LinkedHshMap
一.HashMap的底层实现 HashMap底层是基于数组和链表实现的.其中最重要的参数:容量和负载因子. 容量的默认大小事16,负载因子是0.75,当HashMap的size>16*0.75的 ...
- day18<集合框架+>
集合框架(Map集合概述和特点) 集合框架(Map集合的功能概述) 集合框架(Map集合的遍历之键找值) 集合框架(Map集合的遍历之键值对对象找键和值) 集合框架(Map集合的遍历之键值对对象找键和 ...
- 阶段01Java基础day18集合框架04
18.01_集合框架(Map集合概述和特点) A:Map接口概述 查看API可以知道: 将键映射到值的对象 一个映射不能包含重复的键 每个键最多只能映射到一个值 B:Map接口和Collection接 ...
- (转)Java集合框架:HashMap
来源:朱小厮 链接:http://blog.csdn.net/u013256816/article/details/50912762 Java集合框架概述 Java集合框架无论是在工作.学习.面试中都 ...
- Java集合框架:HashMap
转载: Java集合框架:HashMap Java集合框架概述 Java集合框架无论是在工作.学习.面试中都会经常涉及到,相信各位也并不陌生,其强大也不用多说,博主最近翻阅java集合框架的源码以 ...
随机推荐
- sencha touch list tpl 监听组件插件(2013-9-15)
插件代码 /* *list tpl模版加入按钮监控 *<div class="x-button-normal x-button x-iconalign-center x-layout- ...
- linux下的一些操作命令
1.切换到root账号下: su root 输入密码: 2.修改root账号密码: sudo passwd root 输入密码: 3.cat用法: 查看文件内容 cat 文件名 创建文件 ...
- 如何防御mimikatz致敬Mimikatz攻防杂谈学习笔记
零.绪论:mimikatz简介 mimikatz是一款出色的内网渗透工具,可以抓取windows主机的明文密码.NTLMhash值或者kerberos对应的缓存凭据.mimikatz的使用在获取权限后 ...
- 【转】详解抓取网站,模拟登陆,抓取动态网页的原理和实现(Python,C#等)
转自:http://www.crifan.com/files/doc/docbook/web_scrape_emulate_login/release/html/web_scrape_emulate_ ...
- Cocoa Touch框架
iOS – Cocoa Touch简介: iOS 应用程序的基础 Cocoa Touch 框架重用了许多 Mac 系统的成熟模式,但是它更加专注于触摸的接口和优化.UIKit 为开发者提供了在 iOS ...
- yii---where该如何使用
简单示例yii 的where使用方法: $where = ['post_id'=>$postId]; //$list = ForumThreadPost::find()->where($w ...
- sublime设置tab键为4个空格
在使用sublime的时候,有时候新建的文件,默认的缩进是2个,那么如何将sublime设置tab键为4个空格呢? 具体方法: 配置: , "translate_tabs_to_spaces ...
- [分布式系统学习]阅读笔记 Distributed systems for fun and profit 之四 Replication 拷贝
阅读http://book.mixu.net/distsys/replication.html的笔记,是本系列的第四章 拷贝其实是一组通信问题,为一些子问题,例如选举,失灵检测,一致性和原子广播提供了 ...
- inline-blcok 之间的空白间隙
前言: inline-blcok 布局时,通常情况下, inline-blocks 之间有空白,尽管通常我们是不想要的,毕竟不像padding或者margin一样好控制,如图: <div cla ...
- C3P0连接池配置(C3P0Utils.java)
配置文件 c3p0-config.xml <?xml version="1.0" encoding="UTF-8"?> <c3p0-confi ...