MNIST机器学习入门【学习笔记】
平台信息:
PC:ubuntu18.04、i5、anaconda2、cuda9.0、cudnn7.0.5、tensorflow1.10、GTX1060
作者:庄泽彬(欢迎转载,请注明作者)
说明:本文是在tensorflow社区的学习笔记,MNIST 手写数据入门demo
一、MNIST数据的下载,使用代码的方式:
input_data.py文件内容:
# Copyright 2015 Google Inc. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Functions for downloading and reading MNIST data."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import gzip
import os
import numpy
from six.moves import urllib
from six.moves import xrange # pylint: disable=redefined-builtin
SOURCE_URL = 'http://yann.lecun.com/exdb/mnist/'
def maybe_download(filename, work_directory):
"""Download the data from Yann's website, unless it's already here."""
if not os.path.exists(work_directory):
os.mkdir(work_directory)
filepath = os.path.join(work_directory, filename)
if not os.path.exists(filepath):
filepath, _ = urllib.request.urlretrieve(SOURCE_URL + filename, filepath)
statinfo = os.stat(filepath)
print('Successfully downloaded', filename, statinfo.st_size, 'bytes.')
return filepath
def _read32(bytestream):
dt = numpy.dtype(numpy.uint32).newbyteorder('>')
return numpy.frombuffer(bytestream.read(4), dtype=dt)[0]
def extract_images(filename):
"""Extract the images into a 4D uint8 numpy array [index, y, x, depth]."""
print('Extracting', filename)
with gzip.open(filename) as bytestream:
magic = _read32(bytestream)
if magic != 2051:
raise ValueError(
'Invalid magic number %d in MNIST image file: %s' %
(magic, filename))
num_images = _read32(bytestream)
rows = _read32(bytestream)
cols = _read32(bytestream)
buf = bytestream.read(rows * cols * num_images)
data = numpy.frombuffer(buf, dtype=numpy.uint8)
data = data.reshape(num_images, rows, cols, 1)
return data
def dense_to_one_hot(labels_dense, num_classes=10):
"""Convert class labels from scalars to one-hot vectors."""
num_labels = labels_dense.shape[0]
index_offset = numpy.arange(num_labels) * num_classes
labels_one_hot = numpy.zeros((num_labels, num_classes))
labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1
return labels_one_hot
def extract_labels(filename, one_hot=False):
"""Extract the labels into a 1D uint8 numpy array [index]."""
print('Extracting', filename)
with gzip.open(filename) as bytestream:
magic = _read32(bytestream)
if magic != 2049:
raise ValueError(
'Invalid magic number %d in MNIST label file: %s' %
(magic, filename))
num_items = _read32(bytestream)
buf = bytestream.read(num_items)
labels = numpy.frombuffer(buf, dtype=numpy.uint8)
if one_hot:
return dense_to_one_hot(labels)
return labels
class DataSet(object):
def __init__(self, images, labels, fake_data=False):
if fake_data:
self._num_examples = 10000
else:
assert images.shape[0] == labels.shape[0], (
"images.shape: %s labels.shape: %s" % (images.shape,
labels.shape))
self._num_examples = images.shape[0]
# Convert shape from [num examples, rows, columns, depth]
# to [num examples, rows*columns] (assuming depth == 1)
assert images.shape[3] == 1
images = images.reshape(images.shape[0],
images.shape[1] * images.shape[2])
# Convert from [0, 255] -> [0.0, 1.0].
images = images.astype(numpy.float32)
images = numpy.multiply(images, 1.0 / 255.0)
self._images = images
self._labels = labels
self._epochs_completed = 0
self._index_in_epoch = 0
@property
def images(self):
return self._images
@property
def labels(self):
return self._labels
@property
def num_examples(self):
return self._num_examples
@property
def epochs_completed(self):
return self._epochs_completed
def next_batch(self, batch_size, fake_data=False):
"""Return the next `batch_size` examples from this data set."""
if fake_data:
fake_image = [1.0 for _ in xrange(784)]
fake_label = 0
return [fake_image for _ in xrange(batch_size)], [
fake_label for _ in xrange(batch_size)]
start = self._index_in_epoch
self._index_in_epoch += batch_size
if self._index_in_epoch > self._num_examples:
# Finished epoch
self._epochs_completed += 1
# Shuffle the data
perm = numpy.arange(self._num_examples)
numpy.random.shuffle(perm)
self._images = self._images[perm]
self._labels = self._labels[perm]
# Start next epoch
start = 0
self._index_in_epoch = batch_size
assert batch_size <= self._num_examples
end = self._index_in_epoch
return self._images[start:end], self._labels[start:end]
def read_data_sets(train_dir, fake_data=False, one_hot=False):
class DataSets(object):
pass
data_sets = DataSets()
if fake_data:
data_sets.train = DataSet([], [], fake_data=True)
data_sets.validation = DataSet([], [], fake_data=True)
data_sets.test = DataSet([], [], fake_data=True)
return data_sets
TRAIN_IMAGES = 'train-images-idx3-ubyte.gz'
TRAIN_LABELS = 'train-labels-idx1-ubyte.gz'
TEST_IMAGES = 't10k-images-idx3-ubyte.gz'
TEST_LABELS = 't10k-labels-idx1-ubyte.gz'
VALIDATION_SIZE = 5000
local_file = maybe_download(TRAIN_IMAGES, train_dir)
train_images = extract_images(local_file)
local_file = maybe_download(TRAIN_LABELS, train_dir)
train_labels = extract_labels(local_file, one_hot=one_hot)
local_file = maybe_download(TEST_IMAGES, train_dir)
test_images = extract_images(local_file)
local_file = maybe_download(TEST_LABELS, train_dir)
test_labels = extract_labels(local_file, one_hot=one_hot)
validation_images = train_images[:VALIDATION_SIZE]
validation_labels = train_labels[:VALIDATION_SIZE]
train_images = train_images[VALIDATION_SIZE:]
train_labels = train_labels[VALIDATION_SIZE:]
data_sets.train = DataSet(train_images, train_labels)
data_sets.validation = DataSet(validation_images, validation_labels)
data_sets.test = DataSet(test_images, test_labels)
return data_sets
新建test.py调用input_data.py进行下载手写识别的数据
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
"""
Created on Thu Oct 11 23:10:15 2018 @author: zhuang
""" import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
注意test.py与input_data.py要放在同一个目录下,运行test.py之后会在当前目录生成MNIST_data/ 存放下载的数据,下载的内容如下图

二、使用tensorflow构建模型进行训练
新建mnist-test.py内容如下:
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 12 11:43:37 2018 @author: zhuang
"""
import input_data
import tensorflow as tf mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) x = tf.placeholder("float",[None,784]) w = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10])) y = tf.nn.softmax(tf.matmul(x,w)+b) # 计算交叉熵
y_ = tf.placeholder("float",[None,10])
cross_entropy = -tf.reduce_sum(y_*tf.log(y)) #梯度下降算法,以0.01的学习率更新参数
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
init = tf.initialize_all_variables() sess = tf.Session()
sess.run(init) #训练模型1000次
for i in range(1000):
batch_xs,batch_ys = mnist.train.next_batch(100)
sess.run(train_step,feed_dict={x:batch_xs,y_:batch_ys}) #评估模型
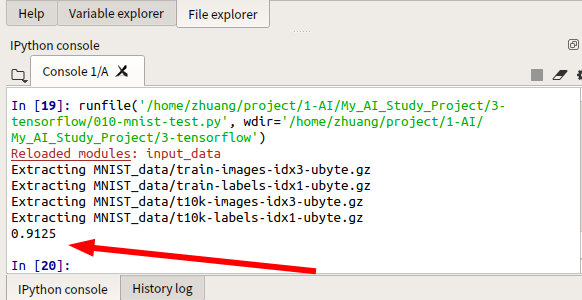
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction,"float")) print sess.run(accuracy,feed_dict={x:mnist.test.images,y_:mnist.test.labels})
我们构建的模型手写识别的准确率在91%z左右
MNIST机器学习入门【学习笔记】的更多相关文章
- 机器学习入门学习笔记:(一)BP神经网络原理推导及程序实现
机器学习中,神经网络算法可以说是当下使用的最广泛的算法.神经网络的结构模仿自生物神经网络,生物神经网络中的每个神经元与其他神经元相连,当它“兴奋”时,想下一级相连的神经元发送化学物质,改变这些神经元的 ...
- [转]MNIST机器学习入门
MNIST机器学习入门 转自:http://wiki.jikexueyuan.com/project/tensorflow-zh/tutorials/mnist_beginners.html?plg_ ...
- tensorfllow MNIST机器学习入门
MNIST机器学习入门 这个教程的目标读者是对机器学习和TensorFlow都不太了解的新手.如果你已经了解MNIST和softmax回归(softmax regression)的相关知识,你可以阅读 ...
- Hadoop入门学习笔记---part4
紧接着<Hadoop入门学习笔记---part3>中的继续了解如何用java在程序中操作HDFS. 众所周知,对文件的操作无非是创建,查看,下载,删除.下面我们就开始应用java程序进行操 ...
- Hadoop入门学习笔记---part3
2015年元旦,好好学习,天天向上.良好的开端是成功的一半,任何学习都不能中断,只有坚持才会出结果.继续学习Hadoop.冰冻三尺,非一日之寒! 经过Hadoop的伪分布集群环境的搭建,基本对Hado ...
- PyQt4入门学习笔记(三)
# PyQt4入门学习笔记(三) PyQt4内的布局 布局方式是我们控制我们的GUI页面内各个控件的排放位置的.我们可以通过两种基本方式来控制: 1.绝对位置 2.layout类 绝对位置 这种方式要 ...
- PyQt4入门学习笔记(一)
PyQt4入门学习笔记(一) 一直没有找到什么好的pyqt4的教程,偶然在google上搜到一篇不错的入门文档,翻译过来,留以后再复习. 原始链接如下: http://zetcode.com/gui/ ...
- Hadoop入门学习笔记---part2
在<Hadoop入门学习笔记---part1>中感觉自己虽然总结的比较详细,但是始终感觉有点凌乱.不够系统化,不够简洁.经过自己的推敲和总结,现在在此处概括性的总结一下,认为在准备搭建ha ...
- Hadoop入门学习笔记---part1
随着毕业设计的进行,大学四年正式进入尾声.任你玩四年的大学的最后一次作业最后在激烈的选题中尘埃落定.无论选择了怎样的选题,无论最后的结果是怎样的,对于大学里面的这最后一份作业,也希望自己能够尽心尽力, ...
- Scala入门学习笔记三--数组使用
前言 本篇主要讲Scala的Array.BufferArray.List,更多教程请参考:Scala教程 本篇知识点概括 若长度固定则使用Array,若长度可能有 变化则使用ArrayBuffer 提 ...
随机推荐
- 新建虚拟机_XP系统(二)
准备工作:按照<新建虚拟机_XP系统(一)>中操作步骤创建好虚拟机 1.启动虚拟机进入如下界面.新建分区.选择[6]运行DiskGenius工具 2.选择快速分区.可以自定义 3.新建分区 ...
- python修饰器各种实用方法
This page is meant to be a central repository of decorator code pieces, whether useful or not <wi ...
- less语言特性(一) —— 变量
近两年移动市场不断扩大,HTML5也逐渐升温,为了使我们前端工作更有效率,各种框架层出不穷,本章将介绍LESSCSS框架.LESSCSS是一种动态样式语言,属于CSS预处理语言的一种,它使用类似CSS ...
- mac chrome 驱动配置
将解压后的chromedriver移动到/usr/local/bin目录下
- oracle(七)索引
一.B-Tree索引 (1). 选择索引字段的原则: 在WHERE子句中最频繁使用的字段 联接语句中的联接字段 选择高选择性的字段(如果很少的字段拥有相同值,即有很多独特值,则选择性很好) Oracl ...
- 迁移到 Linux :入门介绍 | Linux 中国
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/F8qG7f9YD02Pe/article/details/79001952 这个新文章系列将帮你从其 ...
- CSS表格(未完成)
CSS 表格 使用 CSS 可以使 HTML 表格更美观. 表格边框 指定CSS表格边框,使用border属性. 下面的例子指定了一个表格的Th和TD元素的黑色边框:
- Python中使用中文正则表达式匹配指定的中文字符串
业务场景: 从中文字句中匹配出指定的中文子字符串 .这样的情况我在工作中遇到非常多, 特梳理总结如下. 难点: 处理GBK和utf8之类的字符编码, 同时正则匹配Pattern中包含汉字,要汉字正常发 ...
- 尝试.Net Core—使用.Net Core + Entity FrameWork Core构建WebAPI(一)
想尝试.Net Core很久了,一直没有时间,今天回家,抛开一切,先搭建一个.Net Core的Demo出来玩玩. 废话少说,咱直奔主题: 一.开发环境 VS2015 Update3 Microsof ...
- Qt5
最简单的分割窗体 #include <QApplication> #include <QLabel> #include <QSplitter> int main(i ...