Go第三篇之大话容器
Go语言数组
数组(Array)是一段固定长度的连续内存区域
在 Go 语言中,数组从声明时就确定,使用时可以修改数组成员,但是数组大小不可变化
Go 语言数组的声明
数组的写法如下:
var 数组变量名 [元素数量]T
其中:
- 数组变量名:数组声明及使用时的变量名。
- 元素数量:数组的元素数量。可以是一个表达式,但最终通过编译期计算的结果必须是整型数值。也就是说,元素数量不能含有到运行时才能确认大小的数值。
- T 可以是任意基本类型,包括 T 为数组本身。但类型为数组本身时,可以实现多维数组。
下面是一段数组的演示例子:
var team [3]string
team[0] = "hammer"
team[1] = "soldier"
team[2] = "mum"
fmt.Println(team)
输出结果:
[hammer soldier mum]
代码说明如下:
- 第 1 行,将 team 声明为包含 3 个元素的字符串数组。
- 第 2~4 行,为 team 的元素赋值。
Go语言数组的初始化
数组可以在声明时使用初始化列表进行元素设置,参考下面的代码:
var team = [3]string{"hammer", "soldier", "mum"}
这种方式编写时,需要保证大括号后面的元素数量与数组的大小一致。但一般情况下,这个过程可以交给编译器,让编译器在编译时,根据元素个数确定数组大小。
var team = [...]string{"hammer", "soldier", "mum"}
...表示让编译器确定数组大小。上面例子中,编译器会自动为这个数组设置元素个数为 3。
遍历数组(访问每一个数组元素)
遍历数组也和遍历切片类似,看下面代码:
var team [3]string
team[0] = "hammer"
team[1] = "soldier"
team[2] = "mum"
for k, v := range team {
fmt.Println(k, v)
}
代码输出结果:
hammer
soldier
mum
代码说明如下:
- 第 6 行,使用 for 循环,遍历 team 数组,遍历出的键 k 为数组的索引,值 v 为数组的每个元素值。
- 第 7 行,将每个键值打印出来。
Go语言切片
切片(Slice)是一个拥有相同类型元素的可变长度的序列。Go 语言切片的内部结构包含地址、大小和容量。切片一般用于快速地操作一块数据集合。如果将数据集合比作切糕的话,切片就是你要的“那一块”。切的过程包含从哪里开始(这个就是切片的地址)及切多大(这个就是切片的大小)。容量可以理解为装切片的口袋大小,如下图所示。
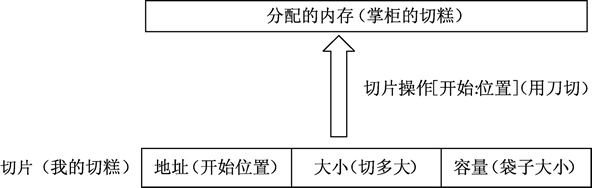
图:切片结构和内存分配
从数组或切片生成新的切片
切片默认指向一段连续内存区域,可以是数组,也可以是切片本身。
从连续内存区域生成切片是常见的操作,格式如下:
slice [开始位置:结束位置]
- slice 表示目标切片对象。
- 开始位置对应目标切片对象的索引。
- 结束位置对应目标切片的结束索引。
从数组生成切片,代码如下:
var a = [3]int{1, 2, 3}
fmt.Println(a, a[1:2])
a 是一个拥有 3 个整型元素的数组,被初始化数值 1 到 3。使用 a[1:2] 可以生成一个新的切片。代码运行结果如下:
[1 2 3] [2]
[2] 就是 a[1:2] 切片操作的结果。
从数组或切片生成新的切片拥有如下特性:
- 取出的元素数量为:结束位置-开始位置。
- 取出元素不包含结束位置对应的索引,切片最后一个元素使用 slice[len(slice)] 获取。
- 当缺省开始位置时,表示从连续区域开头到结束位置。
- 当缺省结束位置时,表示从开始位置到整个连续区域末尾。
- 两者同时缺省时,与切片本身等效。
- 两者同时为0时,等效于空切片,一般用于切片复位。
根据索引位置取切片 slice 元素值时,取值范围是(0~len(slice)-1),超界会报运行时错误。生成切片时,结束位置可以填写 len(slice) 但不会报错。
下面在具体的例子中熟悉切片的特性。
1) 从指定范围中生成切片
切片和数组密不可分。如果将数组理解为一栋办公楼,那么切片就是把不同的连续楼层出租给使用者。出租的过程需要选择开始楼层和结束楼层,这个过程就会生成切片。示例代码如下:
var highRiseBuilding [30]int
for i := 0; i < 30; i++ {
highRiseBuilding[i] = i + 1
}
// 区间
fmt.Println(highRiseBuilding[10:15])
// 中间到尾部的所有元素
fmt.Println(highRiseBuilding[20:])
// 开头到中间的所有元素
fmt.Println(highRiseBuilding[:2])
代码输出如下:
[11 12 13 14 15]
[21 22 23 24 25 26 27 28 29 30]
[1 2]
代码中构建了一个 30 层的高层建筑。数组的元素值从 1 到 30,分别代表不同的独立楼层。输出的结果是不同租售方案。
代码说明如下:
- 第 8 行,尝试出租一个区间楼层。
- 第 11 行,出租 20 层以上。
- 第 14 行,出租 2 层以下,一般是商用铺面。
切片有点像C语言里的指针。指针可以做运算,但代价是内存操作越界。切片在指针的基础上增加了大小,约束了切片对应的内存区域,切片使用中无法对切片内部的地址和大小进行手动调整,因此切片比指针更安全、强大。
2) 表示原有的切片
生成切片的格式中,当开始和结束都范围都被忽略,则生成的切片将表示和原切片一致的切片,并且生成的切片与原切片在数据内容上是一致的,代码如下:
a := []int{1, 2, 3}
fmt.Println(a[:])
a 是一个拥有 3 个元素的切片。将 a 切片使用 a[:] 进行操作后,得到的切片与 a 切片一致,代码输出如下:
[1 2 3]
3) 重置切片,清空拥有的元素
把切片的开始和结束位置都设为 0 时,生成的切片将变空,代码如下:
a := []int{1, 2, 3}
fmt.Println(a[0:0])
代码输出如下:
[]
直接声明新的切片
除了可以从原有的数组或者切片中生成切片,你也可以声明一个新的切片。每一种类型都可以拥有其切片类型,表示多个类型元素的连续集合。因此切片类型也可以被声明。切片类型声明格式如下:
var name []T
- name 表示切片类型的变量名。
- T 表示切片类型对应的元素类型。
下面代码展示了切片声明的使用过程:
// 声明字符串切片
var strList []string
// 声明整型切片
var numList []int
// 声明一个空切片
var numListEmpty = []int{}
// 输出3个切片
fmt.Println(strList, numList, numListEmpty)
// 输出3个切片大小
fmt.Println(len(strList), len(numList), len(numListEmpty))
// 切片判定空的结果
fmt.Println(strList == nil)
fmt.Println(numList == nil)
fmt.Println(numListEmpty == nil)
代码输出结果:
[] [] []
0 0 0
true
true
false
代码说明如下:
- 第 2 行,声明一个字符串切片,切片中拥有多个字符串。
- 第 5 行,声明一个整型切片,切片中拥有多个整型数值。
- 第 8 行,将 numListEmpty 声明为一个整型切片。本来会在
{}中填充切片的初始化元素,这里没有填充,所以切片是空的。但此时 numListEmpty 已经被分配了内存,但没有元素。 - 第 11 行,切片均没有任何元素,3 个切片输出元素内容均为空。
- 第 14 行,没有对切片进行任何操作,strList 和 numList 没有指向任何数组或者其他切片。
- 第 17 行和第 18 行,声明但未使用的切片的默认值是 nil。strList 和 numList 也是 nil,所以和 nil 比较的结果是 true。
- 第 19 行,numListEmpty 已经被分配到了内存,但没有元素,因此和 nil 比较时是 false。
切片是动态结构,只能与nil判定相等,不能互相判等时。
声明新的切片后,可以使用 append() 函数来添加元素。
使用 make() 函数构造切片
如果需要动态地创建一个切片,可以使用 make() 内建函数,格式如下:
make( []T, size, cap )
- T:切片的元素类型。
- size:就是为这个类型分配多少个元素。
- cap:预分配的元素数量,这个值设定后不影响 size,只是能提前分配空间,降低多次分配空间造成的性能问题。
示例如下:
a := make([]int, 2)
b := make([]int, 2, 10)
fmt.Println(a, b)
fmt.Println(len(a), len(b))
代码输出如下:
[0 0] [0 0]
2 2
a 和 b 均是预分配 2 个元素的切片,只是 b 的内部存储空间已经分配了 10 个,但实际使用了 2 个元素。
容量不会影响当前的元素个数,因此 a 和 b 取 len 都是 2。
温馨提示
使用 make() 函数生成的切片一定发生了内存分配操作。但给定开始与结束位置(包括切片复位)的切片只是将新的切片结构指向已经分配好的内存区域,设定开始与结束位置,不会发生内存分配操作。
切片不一定必须经过 make() 函数才能使用。生成切片、声明后使用 append() 函数均可以正常使用切片。
使用append()为切片添加元素
Go 语言的内建函数 append() 可以为切片动态添加元素。每个切片会指向一片内存空间,这片空间能容纳一定数量的元素。当空间不能容纳足够多的元素时,切片就会进行“扩容”。“扩容”操作往往发生在 append() 函数调用时。
切片在扩容时,容量的扩展规律按容量的 2 倍数扩充,例如 1、2、4、8、16……,代码如下:
var numbers []int
for i := 0; i < 10; i++ {
numbers = append(numbers, i)
fmt.Printf("len: %d cap: %d pointer: %p\n", len(numbers), cap(numbers), numbers)
}
代码输出如下:
len: 1 cap: 1 pointer: 0xc0420080e8
len: 2 cap: 2 pointer: 0xc042008150
len: 3 cap: 4 pointer: 0xc04200e320
len: 4 cap: 4 pointer: 0xc04200e320
len: 5 cap: 8 pointer: 0xc04200c200
len: 6 cap: 8 pointer: 0xc04200c200
len: 7 cap: 8 pointer: 0xc04200c200
len: 8 cap: 8 pointer: 0xc04200c200
len: 9 cap: 16 pointer: 0xc042074000
len: 10 cap: 16 pointer: 0xc042074000
代码说明如下:
- 第 1 行,声明一个整型切片。
- 第 4 行,循环向 numbers 切片添加10个数。
- 第 5 行中,打印输出切片的长度、容量和指针变化。使用 len() 函数查看切片拥有的元素个数,使用 cap() 函数查看切片的容量情况。
通过查看代码输出,有一个有意思的规律:len() 函数并不等于 cap。
往一个切片中不断添加元素的过程,类似于公司搬家。公司发展初期,资金紧张,人员很少,所以只需要很小的房间即可容纳所有的员工。随着业务的拓展和收入的增加就需要扩充工位,但是办公地的大小是固定的,无法改变。因此公司选择搬家,每次搬家就需要将所有的人员转移到新的办公点。
- 员工和工位就是切片中的元素。
- 办公地就是分配好的内存。
- 搬家就是重新分配内存。
- 无论搬多少次家,公司名称始终不会变,代表外部使用切片的变量名不会修改。
- 因为搬家后地址发生变化,因此内存“地址”也会有修改。
append() 函数除了添加一个元素外,也可以一次性添加很多元素
var car []string
// 添加1个元素
car = append(car, "OldDriver")
// 添加多个元素
car = append(car, "Ice", "Sniper", "Monk")
// 添加切片
team := []string{"Pig", "Flyingcake", "Chicken"}
car = append(car, team...)
fmt.Println(car)
代码输出如下:
[OldDriver Ice Sniper Monk Pig Flyingcake Chicken]
代码说明如下:
- 第 1 行,声明一个字符串切片。
- 第 4 行,往切片中添加一个元素。
- 第 7 行,使用 append() 函数向切片中添加多个元素。
- 第 10 行,声明另外一个字符串切片
- 第 11 行,在team后面加上了
...,表示将 team 整个添加到 car 的后面。
Go语言切片复制
使用 Go 语言内建的 copy() 函数,可以迅速地将一个切片的数据复制到另外一个切片空间中,copy() 函数的使用格式如下:
copy( destSlice, srcSlice []T) int
- srcSlice 为数据来源切片。
- destSlice 为复制的目标。目标切片必须分配过空间且足够承载复制的元素个数。来源和目标的类型一致,copy 的返回值表示实际发生复制的元素个数。
下面的代码将演示对切片的引用和复制操作后对切片元素的影响
package main
import "fmt"
func main() {
// 设置元素数量为1000
const elementCount = 1000
// 预分配足够多的元素切片
srcData := make([]int, elementCount)
// 将切片赋值
for i := 0; i < elementCount; i++ {
srcData[i] = i
}
// 引用切片数据
refData := srcData
// 预分配足够多的元素切片
copyData := make([]int, elementCount)
// 将数据复制到新的切片空间中
copy(copyData, srcData)
// 修改原始数据的第一个元素
srcData[0] = 999
// 打印引用切片的第一个元素
fmt.Println(refData[0])
// 打印复制切片的第一个和最后一个元素
fmt.Println(copyData[0], copyData[elementCount-1])
// 复制原始数据从4到6(不包含)
copy(copyData, srcData[4:6])
for i := 0; i < 5; i++ {
fmt.Printf("%d ", copyData[i])
}
}
代码说明如下:
- 第 8 行,定义元素总量为 1000。
- 第 11 行,预分配拥有 1000 个元素的整型切片,这个切片将作为原始数据。
- 第 14~16 行,将 srcData 填充 0~999 的整型值。
- 第 19 行,将 refData 引用 srcData,切片不会因为等号操作进行元素的复制。
- 第 22 行,预分配与 srcData 等大(大小相等)、同类型的切片 copyData。
- 第 24 行,使用 copy() 函数将原始数据复制到 copyData 切片空间中。
- 第 27 行,修改原始数据的第一个元素为 999。
- 第 30 行,引用数据的第一个元素将会发生变化。
- 第 33 行,打印复制数据的首位数据,由于数据是复制的,因此不会发生变化。
- 第 36 行,将 srcData 的局部数据复制到 copyData 中。
- 第 38~40 行,打印复制局部数据后的 copyData 元素。
Go语言从切片中删除元素
Go 语言并没有对删除切片元素提供专用的语法或者接口,需要使用切片本身的特性来删除元素。示例代码如下
seq := []string{"a", "b", "c", "d", "e"}
// 指定删除位置
index := 2
// 查看删除位置之前的元素和之后的元素
fmt.Println(seq[:index], seq[index+1:])
// 将删除点前后的元素连接起来
seq = append(seq[:index], seq[index+1:]...)
fmt.Println(seq)
代码输出结果:
[a b] [d e]
[a b d e]
- 第 1 行,声明一个整型切片,保存含有从 a 到 e 的字符串。
- 第 4 行,为了演示和讲解方便,使用 index 变量保存需要删除的元素位置。
- 第 7 行中:seq[:index] 表示的就是被删除元素的前半部分,值为:
[1 2]
seq[index+1:] 表示的是被删除元素的后半部分,值为:
[4 5] - 第 10 行使用 append() 函数将两个切片连接起来。
- 第 12 行,输出连接好的新切片。此时,索引为 2 的元素已经被删除。
代码的删除过程可以使用下图来描述。
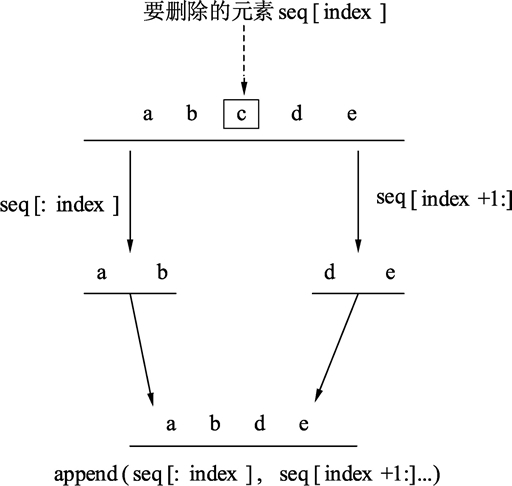
图:切片删除元素的操作过程
Go 语言中切片删除元素的本质是:以被删除元素为分界点,将前后两个部分的内存重新连接起来。
提示
Go 语言中切片元素的删除过程并没有提供任何的语法糖或者方法封装,无论是初学者学习,还是实际使用都是极为麻烦的。
连续容器的元素删除无论是在任何语言中,都要将删除点前后的元素移动到新的位置。随着元素的增加,这个过程将会变得极为耗时。因此,当业务需要大量、频繁地从一个切片中删除元素时,如果对性能要求较高,就需要反思是否需要更换其他的容器(如双链表等能快速从删除点删除元素)
Go语言map(映射)
在业务和算法中需要使用任意类型的关联关系时,就需要使用到映射,如学号和学生的对应、名字与档案的对应等。
Go 语言提供的映射关系容器为 map,map使用散列表(hash)实现。
提示
大多数语言中映射关系容器使用两种算法:散列表和平衡树。
散列表可以简单描述为一个数组(俗称“桶”),数组的每个元素是一个列表。根据散列函数获得每个元素的特征值,将特征值作为映射的键。如果特征值重复,表示元素发生碰撞。碰撞的元素将被放在同一个特征值的列表中进行保存。散列表查找复杂度为 O(1),和数组一致。最坏的情况为 O(n),n 为元素总数。散列需要尽量避免元素碰撞以提高查找效率,这样就需要对“桶”进行扩容,每次扩容,元素需要重新放入桶中,较为耗时。
平衡树类似于有父子关系的一棵数据树,每个元素在放入树时,都要与一些节点进行比较。平衡树的查找复杂度始终为 O(log n)。
添加关联到 map 并访问关联和数据
Go 语言中 map 的定义是这样的:
map[KeyType]ValueType
- KeyType为键类型。
- ValueType是键对应的值类型。
一个 map 里,符合 KeyType 和 ValueType 的映射总是成对出现。
下面代码展示了 map 的基本使用环境
scene := make(map[string]int)
scene["route"] = 66
fmt.Println(scene["route"])
v := scene["route2"]
fmt.Println(v)
代码输出如下:
66
0
代码说明如下:
- 第 1 行 map 是一个内部实现的类型,使用时,需要手动使用 make 创建。如果不创建使用 map 类型,会触发宕机错误。
- 第 3 行向 map 中加入映射关系。写法与使用数组一样,key 可以使用除函数以外的任意类型。
- 第 5 行查找 map 中的值。
- 第 7 行中,尝试查找一个不存在的键,那么返回的将是 ValueType 的默认值。
某些情况下,需要明确知道查询中某个键是否在 map 中存在,可以使用一种特殊的写法来实现,看下面的代码:
v, ok := scene["route"]
在默认获取键值的基础上,多取了一个变量 ok,可以判断键 route 是否存在于 map 中。
map 还有一种在声明时填充内容的方式,代码如下:
m := map[string]string{
"W": "forward",
"A": "left",
"D": "right",
"S": "backward",
}
例子中并没有使用 make,而是使用大括号进行内容定义,就像 JSON 格式一样,冒号的左边是 key,右边是值,键值对之间使用逗号分隔。
Go语言遍历map
map 的遍历过程使用 for range 循环完成,代码如下
scene := make(map[string]int)
scene["route"] = 66
scene["brazil"] = 4
scene["china"] = 960
for k, v := range scene {
fmt.Println(k, v)
}
遍历对于 Go 语言的很多对象来说都是差不多的,直接使用 for range 语法。遍历时,可以同时获得键和值。如只遍历值,可以使用下面的形式:
- for _, v := range scene {
将不需要的键改为匿名变量形式。
只遍历键时,使用下面的形式:
- for k := range scene {
无须将值改为匿名变量形式,忽略值即可。
注意:遍历输出元素的顺序与填充顺序无关。不能期望 map 在遍历时返回某种期望顺序的结果。
如果需要特定顺序的遍历结果,正确的做法是排序,代码如下
scene := make(map[string]int)
// 准备map数据
scene["route"] = 66
scene["brazil"] = 4
scene["china"] = 960
// 声明一个切片保存map数据
var sceneList []string
// 将map数据遍历复制到切片中
for k := range scene {
sceneList = append(sceneList, k)
}
// 对切片进行排序
sort.Strings(sceneList)
// 输出
fmt.Println(sceneList)
代码输出如下:
[brazil china route]
代码说明如下:
- 第 1 行,创建一个 map 实例,键为字符串,值为整型。
- 第 4~6 行,将 3 个键值对写入 map 中。
- 第 9 行,声明 sceneList 为字符串切片,以缓冲和排序 map 中的所有元素。
- 第 12 行,将 map 中元素的键遍历出来,并放入切片中。
- 第 17 行,对 sceneList 字符串切片进行排序。排序时,sceneList 会被修改。
- 第 20 行,输出排好序的 map 的键。
sort.Strings 的作用是对传入的字符串切片进行字符串字符的升序排列。排序接口的使用将在后面的章节中介绍。
map元素的删除和清空
使用 delete() 函数从 map 中删除键值对
使用 delete() 内建函数从 map 中删除一组键值对,delete() 函数的格式如下:
delete(map, 键)
- map 为要删除的 map 实例。
- 键为要删除的 map 键值对中的键。
从 map 中删除一组键值对可以通过下面的代码来完成
scene := make(map[string]int)
// 准备map数据
scene["route"] = 66
scene["brazil"] = 4
scene["china"] = 960
delete(scene, "brazil")
for k, v := range scene {
fmt.Println(k, v)
}
代码输出如下:
route 66
china 960
这个例子中使用 delete() 函数将 brazil 从 scene 这个 map 中删除了。
清空 map 中的所有元素
有意思的是,Go 语言中并没有为 map 提供任何清空所有元素的函数、方法。清空 map 的唯一办法就是重新 make 一个新的 map。不用担心垃圾回收的效率,Go 语言中的并行垃圾回收效率比写一个清空函数高效多了。
Go语言sync.Map
Go 语言中的 map 在并发情况下,只读是线程安全的,同时读写线程不安全。
下面来看下并发情况下读写 map 时会出现的问题,代码如下
// 创建一个int到int的映射
m := make(map[int]int)
// 开启一段并发代码
go func() {
// 不停地对map进行写入
for {
m[1] = 1
}
}()
// 开启一段并发代码
go func() {
// 不停地对map进行读取
for {
_ = m[1]
}
}()
// 无限循环, 让并发程序在后台执行
for {
}
运行代码会报错,输出如下:
fatal error: concurrent map read and map write
运行时输出提示:并发的 map 读写。也就是说使用了两个并发函数不断地对 map 进行读和写而发生了竞态问题。map 内部会对这种并发操作进行检查并提前发现。
需要并发读写时,一般的做法是加锁,但这样性能并不高。Go 语言在 1.9 版本中提供了一种效率较高的并发安全的 sync.Map。sync.Map 和 map 不同,不是以语言原生形态提供,而是在 sync 包下的特殊结构。
sync.Map有以下特性:
- 无须初始化,直接声明即可。
- sync.Map 不能使用 map 的方式进行取值和设置等操作,而是使用 sync.Map 的方法进行调用。Store 表示存储,Load 表示获取,Delete 表示删除。
- 使用 Range 配合一个回调函数进行遍历操作,通过回调函数返回内部遍历出来的值。Range 参数中的回调函数的返回值功能是:需要继续迭代遍历时,返回 true;终止迭代遍历时,返回 false。
并发安全的 sync.Map 演示代码如下
package main
import (
"fmt"
"sync"
)
func main() {
var scene sync.Map
// 将键值对保存到sync.Map
scene.Store("greece", 97)
scene.Store("london", 100)
scene.Store("egypt", 200)
// 从sync.Map中根据键取值
fmt.Println(scene.Load("london"))
// 根据键删除对应的键值对
scene.Delete("london")
// 遍历所有sync.Map中的键值对
scene.Range(func(k, v interface{}) bool {
fmt.Println("iterate:", k, v)
return true
})
}
代码输出如下:
100 true
iterate: egypt 200
iterate: greece 97
代码说明如下:
- 第 10 行,声明 scene,类型为 sync.Map。注意,sync.Map 不能使用 make 创建。
- 第 13~15 行,将一系列键值对保存到 sync.Map 中,sync.Map 将键和值以 interface{} 类型进行保存。
- 第 18 行,提供一个 sync.Map 的键给 scene.Load() 方法后将查询到键对应的值返回。
- 第 21 行,sync.Map 的 Delete 可以使用指定的键将对应的键值对删除。
- 第 24 行,Range() 方法可以遍历 sync.Map,遍历需要提供一个匿名函数,参数为 k、v,类型为 interface{},每次 Range() 在遍历一个元素时,都会调用这个匿名函数把结果返回。
sync.Map 没有提供获取 map 数量的方法,替代方法是获取时遍历自行计算数量。sync.Map 为了保证并发安全有一些性能损失,因此在非并发情况下,使用 map 相比使用 sync.Map 会有更好的性能。
Go语言list(列表)
列表是一种非连续存储的容器,由多个节点组成,节点通过一些变量记录彼此之间的关系。列表有多种实现方法,如单链表、双链表等。
列表的原理可以这样理解:假设 A、B、C 三个人都有电话号码,如果 A 把号码告诉给 B,B 把号码告诉给 C,这个过程就建立了一个单链表结构,如下图所示。
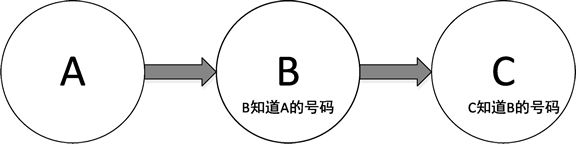
图:三人单向通知电话号码形成单链表结构
如果在这个基础上,再从 C 开始将自己的号码给自己知道号码的人,这样就形成了双链表结构,如下图所示。
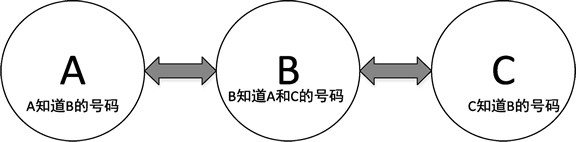
图:三人相互通知电话号码形成双链表结构
那么如果需要获得所有人的号码,只需要从 A 或者 C 开始,要求他们将自己的号码发出来,然后再通知下一个人如此循环。这个过程就是列表遍历。
如果 B 换号码了,他需要通知 A 和 C,将自己的号码移除。这个过程就是列表元素的删除操作,如下图所示。
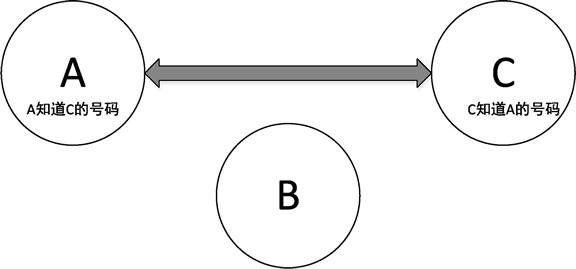
图:从双链表中删除一人的电话号码
在 Go 语言中,将列表使用 container/list 包来实现,内部的实现原理是双链表。列表能够高效地进行任意位置的元素插入和删除操作。
初始化列表
list 的初始化有两种方法:New 和声明。两种方法的初始化效果都是一致的。
1) 通过 container/list 包的 New 方法初始化 list
变量名 := list.New()
2) 通过声明初始化list
var 变量名 list.List
列表与切片和 map 不同的是,列表并没有具体元素类型的限制。因此,列表的元素可以是任意类型。这既带来遍历,也会引来一些问题。给一个列表放入了非期望类型的值,在取出值后,将 interface{} 转换为期望类型时将会发生宕机。
在列表中插入元素
双链表支持从队列前方或后方插入元素,分别对应的方法是 PushFront 和 PushBack。
提示
这两个方法都会返回一个 *list.Element 结构。如果在以后的使用中需要删除插入的元素,则只能通过 *list.Element 配合 Remove() 方法进行删除,这种方法可以让删除更加效率化,也是双链表特性之一。
下面代码展示如何给list添加元素
l := list.New()
l.PushBack("fist")
l.PushFront(67)
代码说明如下:
- 第 1 行,创建一个列表实例。
- 第 3 行,将 fist 字符串插入到列表的尾部,此时列表是空的,插入后只有一个元素。
- 第 4 行,将数值 67 放入列表。此时,列表中已经存在 fist 元素,67 这个元素将被放在 fist 的前面。
列表插入元素的方法如下表所示。
| 方 法 | 功 能 |
|---|---|
| InsertAfter(v interface {}, mark * Element) * Element | 在 mark 点之后插入元素,mark 点由其他插入函数提供 |
| InsertBefore(v interface {}, mark * Element) *Element | 在 mark 点之前插入元素,mark 点由其他插入函数提供 |
| PushBackList(other *List) | 添加 other 列表元素到尾部 |
| PushFrontList(other *List) | 添加 other 列表元素到头部 |
从列表中删除元素
列表的插入函数的返回值会提供一个 *list.Element 结构,这个结构记录着列表元素的值及和其他节点之间的关系等信息。从列表中删除元素时,需要用到这个结构进行快速删除。
列表操作元素
package main
import "container/list"
func main() {
l := list.New()
// 尾部添加
l.PushBack("canon")
// 头部添加
l.PushFront(67)
// 尾部添加后保存元素句柄
element := l.PushBack("fist")
// 在fist之后添加high
l.InsertAfter("high", element)
// 在fist之前添加noon
l.InsertBefore("noon", element)
// 使用
l.Remove(element)
}
代码说明如下:
第 6 行,创建列表实例。
第 9 行,将 canon 字符串插入到列表的尾部。
第 12 行,将 67 数值添加到列表的头部。
第 15 行,将 fist 字符串插入到列表的尾部,并将这个元素的内部结构保存到 element 变量中。
第 18 行,使用 element 变量,在 element 的位置后面插入 high 字符串。
第 21 行,使用 element 变量,在 element 的位置前面插入 noon 字符串。
第 24 行,移除 element 变量对应的元素。
下表中展示了每次操作后列表的实际元素情况。
| 操作内容 | 列表元素 |
|---|---|
| l.PushBack("canon") | canon |
| l.PushFront(67) | 67, canon |
| element := l.PushBack("fist") | 67, canon, fist |
| l.InsertAfter("high", element) | 67, canon, fist, high |
| l.InsertBefore("noon", element) | 67, canon, noon, fist, high |
| l.Remove(element) | 67, canon, noon, high |
遍历列表——访问列表的每一个元素
遍历双链表需要配合 Front() 函数获取头元素,遍历时只要元素不为空就可以继续进行。每一次遍历调用元素的 Next,如代码中第 9 行所示
l := list.New()
// 尾部添加
l.PushBack("canon")
// 头部添加
l.PushFront(67)
for i := l.Front(); i != nil; i = i.Next() {
fmt.Println(i.Value)
}
代码输出如下:
67
canon
代码说明如下:
- 第 1 行,创建一个列表实例。
- 第 4 行,将 canon 放入列表尾部。
- 第 7 行,在队列头部放入 67。
- 第 9 行,使用 for 语句进行遍历,其中 i:=l.Front() 表示初始赋值,只会在一开始执行一次;每次循环会进行一次 i!=nil 语句判断,如果返回 false,表示退出循环,反之则会执行 i=i.Next()。
- 第 10 行,使用遍历返回的 *list.Element 的 Value 成员取得放入列表时的原值。
Go第三篇之大话容器的更多相关文章
- Scala语言笔记 - 第三篇(容器方法篇)
Scala语言笔记 - 第三篇(容器方法篇) 目录 Scala语言笔记 - 第三篇(容器方法篇) map和flapMap方法: 最近研究了下scala语言,这个语言最强大的就是它强大的函数式编程( ...
- IOC容器特性注入第三篇:Attribute封装
Attribute(特性)=>就是对类,方法,字段的自定义属性的基类.可以利用Attribute对类,方法等进行自定义描述,方便区分. 既然如此,那我们就可以那些需要注入IOC容器和不需要注入I ...
- 从0开始搭建SQL Server AlwaysOn 第三篇(配置AlwaysOn)
从0开始搭建SQL Server AlwaysOn 第三篇(配置AlwaysOn) 第一篇http://www.cnblogs.com/lyhabc/p/4678330.html第二篇http://w ...
- (转) 从0开始搭建SQL Server AlwaysOn 第三篇(配置AlwaysOn)
原文地址: http://www.cnblogs.com/lyhabc/p/4682986.html 这一篇是从0开始搭建SQL Server AlwaysOn 的第三篇,这一篇才真正开始搭建Alwa ...
- Spring第二篇和第三篇的补充【JavaConfig配置、c名称空间、装载集合、JavaConfig与XML组合】
前言 在写完Spring第二和第三篇后,去读了Spring In Action这本书-发现有知识点要补充,知识点跨越了第二和第三篇,因此专门再开一篇博文来写- 通过java代码配置bean 由于Spr ...
- 第三篇 功能实现(2) (Android学习笔记)
第三篇 功能实现(2) ●Activity的四种启动模式 Activity的启动模式有四种,分别是standard.singleTop.singleTask和singleInstance. 在Andr ...
- 第三篇 功能实现(1) (Android学习笔记)
第三篇 功能实现(1) 第8章 Android应用程序组成 ●Android的一些中.底层基础知识 ※ Android Framework 启动过程 Android手机系统本质上是一个基于Linux的 ...
- spring第三篇
在昨天下午更新sprin第二篇中,叙述了将对象交给spring创建和管理,今天在spring第三篇中,主要写两个点一是spring的思想 二是spring中bean元素的属性配置. 1 spring思 ...
- 从0开始搭建SQL Server 2012 AlwaysOn 第三篇(安装数据,配置AlwaysOn)
这一篇是从0开始搭建SQL Server 2012 AlwaysOn 的第三篇,这一篇才真正开始搭建AlwaysOn,前两篇是为搭建AlwaysOn 做准备的 操作步骤: 1.安装SQL server ...
随机推荐
- kerberos (https://en.wikipedia.org/wiki/Kerberos_(protocol))
Protocol[edit] Description[edit] The client authenticates itself to the Authentication Server (AS) w ...
- render, render_to_response, redirect,
自django1.3开始:render()方法是render_to_response的一个崭新的快捷方式,前者会自动使用RequestContext.而后者必须coding出来,这是最明显的区别,当然 ...
- 【find -exec】查找并复制文件
find . -name *run_server* -type f -exec cp {} /tmp/ \;
- 牛客练习赛16D K进制 数论(待理解QAQ)
正解:数论 解题报告: 行吧那就让我一点点推出来趴QAQ
- React-生命周期的相关介绍
1.mounting/组件插入相关 (1)componentWillMount 模板插入前 (2)render 模板插入 (3)componentDidMount 模板插入后 2.Updating/ ...
- java客户端调用ftp上传下载文件
1:java客户端上传,下载文件. package com.li.utils; import java.io.File; import java.io.FileInputStream; import ...
- JS在不同js文件中互相调用
例如有这样一个html,里面有一个按钮,当按下时调用b.js文件中的方法b().而b()中又要调用a.js文件中的方法a().若要实现这个功能,必须注意,将要引入的Js文件代码放在</body& ...
- 自动加载 autoload
自动加载 是什么时候调用的 是实例化某个对象的时候,在当前脚本中没有找到对应类的时候 ,如果当前找到了就不会调用__autoload方法 例如:例子一,找到类 <?php function _ ...
- #C++初学记录(算法3)
C - 不要62 杭州人称那些傻乎乎粘嗒嗒的人为62(音:laoer). 杭州交通管理局经常会扩充一些的士车牌照,新近出来一个好消息,以后上牌照,不再含有不吉利的数字了,这样一来,就可以消除个别的士司 ...
- javascript 判断数据类型
Object.prototype.toString.call(asddfff) //报错asddfff没被定义Object.prototype.toString.call(undefined) //& ...