Lucene系列三:Lucene分词器详解、实现自己的一个分词器
一、Lucene分词器详解
1. Lucene-分词器API
(1)org.apache.lucene.analysi.Analyzer
分析器,分词器组件的核心API,它的职责:构建真正对文本进行分词处理的TokenStream(分词处理器)。通过调用它的如下两个方法,得到输入文本的分词处理器。
public final TokenStream tokenStream(String fieldName, Reader reader) public final TokenStream tokenStream(String fieldName, String text)
这两个方法是final方法,不能被覆盖的,在这两个方法中是如何构建分词处理器的呢?
对应源码分析:
public final TokenStream tokenStream(final String fieldName,
final Reader reader) {
TokenStreamComponents components = reuseStrategy.getReusableComponents(this, fieldName);
final Reader r = initReader(fieldName, reader);
if (components == null) {
components = createComponents(fieldName);
reuseStrategy.setReusableComponents(this, fieldName, components);
}
components.setReader(r);
return components.getTokenStream();
}
问题1:从哪里得到了TokenStream?
从components.getTokenStream()得到了TokenStream
问题2:方法传入的字符流Reader 给了谁?
方法传入的字符流Reader 最终给了Tokenizer的inputPending(类型:Reader):initReader(fieldName, reader)-components.setReader(r)-source.setReader(reader)-this.inputPending = input;
问题3: components是什么?components的获取逻辑是怎样?
components是分词处理的组件,components的获取逻辑是有就直接拿来用,没有就新建一个,后面都用新建的这一个
问题4:createComponents(fieldName) 方法是个什么方法?
是创建分词处理组件的方法
问题5:Analyzer能直接创建对象吗?
Analyzer是一个抽象类,不能直接创建对象
问题6:为什么它要这样设计?
使用装饰器模式方便扩展
问题7:请看一下Analyzer的实现子类有哪些?
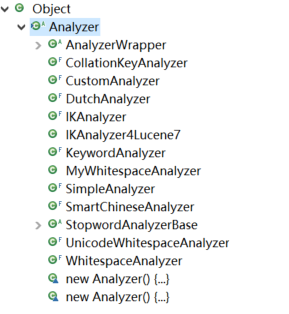
问题8:要实现一个自己的Analyzer,必须实现哪个方法?
必须实现protected abstract TokenStreamComponents createComponents(String fieldName);
(2)TokenStreamComponents createComponents(String fieldName)
是Analizer中唯一的抽象方法,扩展点。通过提供该方法的实现来实现自己的Analyzer。
参数说明:fieldName,如果我们需要为不同的字段创建不同的分词处理器组件,则可根据这个参数来判断。否则,就用不到这个参数。
返回值为 TokenStreamComponents 分词处理器组件。
我们需要在createComponents方法中创建我们想要的分词处理器组件。
(3)TokenStreamComponents 对应源码分析:
分词处理器组件:这个类中封装有供外部使用的TokenStream分词处理器。提供了对source(源)和sink(供外部使用分词处理器)两个属性的访问方法。
问题1:这个类的构造方法有几个?区别是什么?从中能发现什么?
两个构造方法:
public TokenStreamComponents(final Tokenizer source,
final TokenStream result) {
this.source = source;
this.sink = result;
}
public TokenStreamComponents(final Tokenizer source) {
this.source = source;
this.sink = source;
}
区别是参数不一样,可以发现source和sink有继承关系
问题2:source 和 sink属性分别是什么类型?这两个类型有什么关系?
Tokenizer source、TokenStream sink,Tokenizer是TokenStream的子类
问题3:在这个类中没有创建source、sink对象的代码(而是由构造方法传入)。也就是说我们在Analyzer.createComponents方法中创建它的对象前,需先创建什么?
需先创建source、sink
问题4:在Analyzer中tokenStream() 方法中把输入流给了谁?得到的TokenStream对象是谁?TokenStream对象sink中是否必须封装有source对象?
输入流给了source.setReader(reader),得到的TokenStream对象是TokenStream sink
components.getTokenStream()-》
public TokenStream getTokenStream() {
return sink;
}
(4)org.apache.lucene.analysis.TokenStream
分词处理器,负责对输入文本完成分词、处理。
问题1:TokenStream对象sink中是否必须封装有source对象,TokenStream中有没有对应的给入方法?
没有
问题2:TokenStream是一个抽象类,有哪些方法,它的抽象方法有哪些?它的构造方法有什么特点?

抽象方法:
public abstract boolean incrementToken() throws IOException;
构造方法有两个:
protected TokenStream(AttributeSource input) {
super(input);
assert assertFinal();
}
protected TokenStream(AttributeFactory factory) {
super(factory);
assert assertFinal();
}
概念说明:Token: 分项,从字符流中分出一个一个的项
问题3:TokenStream的具体子类分为哪两类?有什么区别?
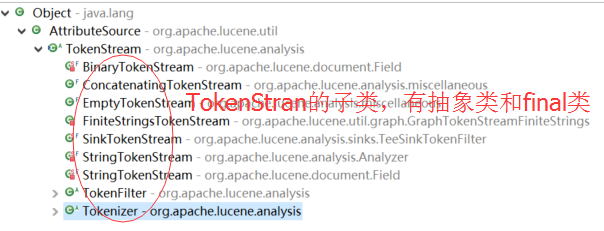
问题4:TokenStream继承了谁?它是干什么用的?
继承了AttributeSource,TokenStream进行分词处理的
概念说明:Token Attribute: 分项属性(分项的信息):如 包含的词、位置等
(5)TokenStream 的两类子类
Tokenizer:分词器,输入是Reader字符流的TokenStream,完成从流中分出分项
TokenFilter:分项过滤器,它的输入是另一个TokenStream,完成对从上一个TokenStream中流出的token的特殊处理。
问题1:请查看Tokenizer类的源码及注释,这个类该如何使用?要实现自己的Tokenizer只需要做什么?
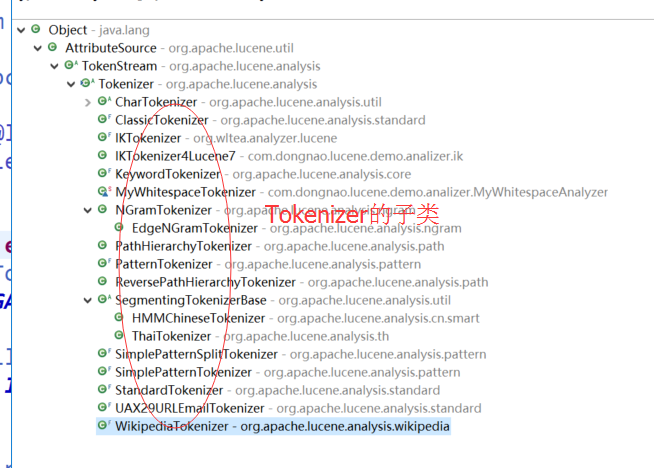
要实现自己的Tokenizer只需要继承Tokenizer复写incrementToken()方法
问题2:请查看TokenFilter类的源码及注释,如何实现自己的TokenFilter?
要实现自己的TokenFilter只需要继承TokenFilter复写incrementToken()方法
问题3:TokenFilter的子类有哪些?
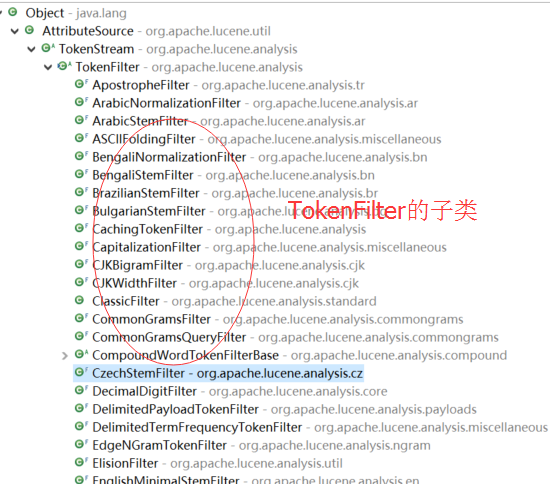
问题4:TokenFilter是不是一个典型的装饰器模式?如果我们需要对分词进行各种处理,只需要按我们的处理顺序一层层包裹即可(每一层完成特定的处理)。不同的处理需要,只需不同的包裹顺序、层数。
是
(6)TokenStream 继承了 AttributeSource
问题1:我们在TokenStream及它的两个子类中是否有看到关于分项信息的存储,如该分项的词是什么、这个词的位置索引?
概念说明:Attribute 属性 Token Attribute 分项属性(分项信息),如 分项的词、词的索引位置等等。这些属性通过不同的Tokenizer /TokenFilter处理统计得出。不同的Tokenizer/TokenFilter组合,就会有不同的分项信息。它是会动态变化的,你不知道有多少,是什么。那该如何实现分项信息的存储呢?
答案就是 AttributeSource、Attribute 、AttributeImpl、AttributeFactory
1、AttribureSource 负责存放Attribute对象,它提供对应的存、取方法
2、Attribute对象中则可以存储一个或多个属性信息
3、AttributeFactory 则是负责创建Attributre对象的工厂,在TokenStream中默认使用了AttributeFactory.getStaticImplementation 我们不需要提供,遵守它的规则即可。
(7)AttributeSource使用规则说明
1、某个TokenStream实现中如要存储分项属性,通过AttributeSource的两个add方法之一,往AttributeSource中加入属性对象。
<T extends Attribute> T addAttribute(Class<T> attClass) 该方法要求传人你需要添加的属性的接口类(继承Attribute),返回对应的实现类实例给你。从接口到实例,这就是为什么需要AttributeFactory的原因。这个方法是我们常用的方法
void addAttributeImpl(AttributeImpl att)
2、加入的每一个Attribute实现类在AttributeSource中只会有一个实例,分词过程中,分项是重复使用这一实例来存放分项的属性信息。重复调用add方法添加它返回已存储的实例对象。
3、要获取分项的某属性信息,则需持有某属性的实例对象,通过addAttribute方法或getAttribure方法获得Attribute对象,再调用实例的方法来获取、设置值
4、在TokenStream中,我们用自己实现的Attribute,默认的工厂。当我们调用这个add方法时,它怎么知道实现类是哪个?这里有一定规则要遵守:
1、自定义的属性接口 MyAttribute 继承 Attribute
2、自定义的属性实现类必须继承 Attribute,实现自定义的接口MyAttribute
3、自定义的属性实现类必须提供无参构造方法
4、为了让默认工厂能根据自定义接口找到实现类,实现类名需为:接口名+Impl 。
(8)TokenStream 的使用步骤。
我们在应用中并不直接使用分词器,只需为索引引擎和搜索引擎创建我们想要的分词器对象。但我们在选择分词器时,会需要测试分词器的效果,就需要知道如何使用得到的分词处理器TokenStream,使用步骤:
1、从tokenStream获得你想要获得分项属性对象(信息是存放在属性对象中的)
2、调用 tokenStream 的 reset() 方法,进行重置。因为tokenStream是重复利用的。
3、循环调用tokenStream的incrementToken(),一个一个分词,直到它返回false
4、在循环中取出每个分项你想要的属性值。
5、调用tokenStream的end(),执行任务需要的结束处理。
6、调用tokenStream的close()方法,释放占有的资源。
二、实现自己的一个分词器
通过前面的源码分析下面我们来实现自己的的一个英文分词器
Tokenizer: 实现对英文按空白字符进行分词。 需要记录的属性信息有: 词
TokenFilter: 要进行的处理:转为小写
说明:Tokenizer分词时,是从字符流中一个一个字符读取,判断是否是空白字符来进行分词。
1. 新建一个maven项目CustomizeTokenStreamByLucene

2. 在pom.xml里面引入lucene 核心模块
<!-- lucene 核心模块 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>7.3.0</version>
</dependency>
3.建立自己的Attribute接口MyCharAttribute
package com.study.lucene.myattribute; import org.apache.lucene.util.Attribute; /**
* 1.建立自己的Attribute接口MyCharAttribute
* @author THINKPAD
*
*/
public interface MyCharAttribute extends Attribute {
void setChars(char[] buffer, int length); char[] getChars(); int getLength(); String getString();
}
4.建立自定义attribute接口MyCharAttribute的实现类MyCharAttributeImpl
package com.study.lucene.myattribute; import org.apache.lucene.util.AttributeImpl;
import org.apache.lucene.util.AttributeReflector; /**
* 2.建立自定义attribute接口MyCharAttribute的实现类MyCharAttributeImpl
* 注意:MyCharAttributeImpl一定要和MyCharAttribute放在一个包下,否则会出现没有MyCharAttribute的实现类,
* 这是由org.apache.lucene.util.AttributeFactory.DefaultAttributeFactory.findImplClass(Class<? extends Attribute>)这个方法决定的
* @author THINKPAD
*
*/
public class MyCharAttributeImpl extends AttributeImpl implements MyCharAttribute {
private char[] chatTerm = new char[255];
private int length = 0; @Override
public void setChars(char[] buffer, int length) {
this.length = length;
if (length > 0) {
System.arraycopy(buffer, 0, this.chatTerm, 0, length);
}
} public char[] getChars() {
return this.chatTerm;
} public int getLength() {
return this.length;
} @Override
public String getString() {
if (this.length > 0) {
return new String(this.chatTerm, 0, length);
}
return null;
} @Override
public void clear() {
this.length = 0;
} @Override
public void reflectWith(AttributeReflector reflector) { } @Override
public void copyTo(AttributeImpl target) { }
}
5. 建立分词器MyWhitespaceTokenizer:实现对英文按空白字符进行分词
package com.study.lucene.mytokenizer; import java.io.IOException; import org.apache.lucene.analysis.Tokenizer; import com.study.lucene.myattribute.MyCharAttribute; /**
* 3. 建立分词器MyWhitespaceTokenizer:实现对英文按空白字符进行分词
* @author THINKPAD
*
*/
public class MyWhitespaceTokenizer extends Tokenizer { // 需要记录的属性
// 词
MyCharAttribute charAttr = this.addAttribute(MyCharAttribute.class); // 存词的出现位置 // 存放词的偏移 //
char[] buffer = new char[255];
int length = 0;
int c; @Override
public boolean incrementToken() throws IOException {
// 清除所有的词项属性
clearAttributes();
length = 0;
while (true) {
c = this.input.read(); if (c == -1) {
if (length > 0) {
// 复制到charAttr
this.charAttr.setChars(buffer, length);
return true;
} else {
return false;
}
} if (Character.isWhitespace(c)) {
if (length > 0) {
// 复制到charAttr
this.charAttr.setChars(buffer, length);
return true;
}
} buffer[length++] = (char) c;
}
} }
6.建立分项过滤器:把大写字母转换为小写字母
package com.study.lucene.mytokenfilter; import java.io.IOException; import org.apache.lucene.analysis.TokenFilter;
import org.apache.lucene.analysis.TokenStream; import com.study.lucene.myattribute.MyCharAttribute; /**
* 4.建立分项过滤器:把大写字母转换为小写字母
* @author THINKPAD
*
*/
public class MyLowerCaseTokenFilter extends TokenFilter { public MyLowerCaseTokenFilter(TokenStream input) {
super(input);
} MyCharAttribute charAttr = this.addAttribute(MyCharAttribute.class); @Override
public boolean incrementToken() throws IOException {
boolean res = this.input.incrementToken();
if (res) {
char[] chars = charAttr.getChars();
int length = charAttr.getLength();
if (length > 0) {
for (int i = 0; i < length; i++) {
chars[i] = Character.toLowerCase(chars[i]);
}
}
}
return res;
}
}
7. 建立分析器MyWhitespaceAnalyzer
package com.study.lucene.myanalyzer; import java.io.IOException; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.Tokenizer; import com.study.lucene.myattribute.MyCharAttribute;
import com.study.lucene.mytokenfilter.MyLowerCaseTokenFilter;
import com.study.lucene.mytokenizer.MyWhitespaceTokenizer; /**
* 5. 建立分析器
* @author THINKPAD
*
*/
public class MyWhitespaceAnalyzer extends Analyzer { @Override
protected TokenStreamComponents createComponents(String fieldName) {
Tokenizer source = new MyWhitespaceTokenizer();
TokenStream filter = new MyLowerCaseTokenFilter(source);
return new TokenStreamComponents(source, filter);
} public static void main(String[] args) { String text = "An AttributeSource contains a list of different AttributeImpls, and methods to add and get them. "; try {
Analyzer ana = new MyWhitespaceAnalyzer();
TokenStream ts = ana.tokenStream("aa", text);
MyCharAttribute ca = ts.getAttribute(MyCharAttribute.class);
ts.reset();
while (ts.incrementToken()) {
System.out.print(ca.getString() + "|");
}
ts.end();
ana.close();
System.out.println();
} catch (IOException e) {
e.printStackTrace();
} }
}
8、运行分析器MyWhitespaceAnalyzer主程序得到结果
an|attributesource|contains|a|list|of|different|attributeimpls,|and|methods|to|add|and|get|them.|
9. 源码获取地址https://github.com/leeSmall/SearchEngineDemo
Lucene系列三:Lucene分词器详解、实现自己的一个分词器的更多相关文章
- Solr系列三:solr索引详解(Schema介绍、字段定义详解、Schema API 介绍)
一.Schema介绍 1. Schema 是什么? Schema:模式,是集合/内核中字段的定义,让solr知道集合/内核包含哪些字段.字段的数据类型.字段该索引存储. 2. Schema 的定义方式 ...
- struts2系列(三):struts2配置详解
原文链接:http://www.cnblogs.com/fmricky/archive/2010/05/20/1740479.html 1.<include> 利用include标签,可以 ...
- Netty4.x中文教程系列(三) Hello World !详解
Netty 中文教程 (二) Hello World !详解 上一篇文章,笔者提供了一个Hello World 的Netty示例. 时间过去了这么久,准备解释一下示例代码. 1.HelloServer ...
- centos性能监控系列三:监控工具atop详解
引言 Linux以其稳定性,越来越多地被用作服务器的操作系统(当然,有人会较真地说一句:Linux只是操作系统内核:).但使用了Linux作为底层的操作系统,是否我们就能保证我们的服务做到7*24地稳 ...
- 深入理解JAVA I/O系列三:字符流详解
字符流为何存在 既然字节流提供了能够处理任何类型的输入/输出操作的功能,那为什么还要存在字符流呢?容我慢慢道来,字节流不能直接操作Unicode字符,因为一个字符有两个字节,字节流一次只能操作一个字节 ...
- Solr系列五:solr搜索详解(solr搜索流程介绍、查询语法及解析器详解)
一.solr搜索流程介绍 1. 前面我们已经学习过Lucene搜索的流程,让我们再来回顾一下 流程说明: 首先获取用户输入的查询串,使用查询解析器QueryParser解析查询串生成查询对象Query ...
- lucene、lucene.NET详细使用与优化详解
lucene.lucene.NET详细使用与优化详解 2010-02-01 13:51:11 分类: Linux 1 lucene简介1.1 什么是luceneLucene是一个全文搜索框架,而不是应 ...
- lucene.NET详细使用与优化详解
lucene.NET详细使用与优化详解 http://www.cnblogs.com/qq4004229/archive/2010/05/21/1741025.html http://www.shan ...
- python设计模式之装饰器详解(三)
python的装饰器使用是python语言一个非常重要的部分,装饰器是程序设计模式中装饰模式的具体化,python提供了特殊的语法糖可以非常方便的实现装饰模式. 系列文章 python设计模式之单例模 ...
随机推荐
- 深入云存储系统Swift核心组件:Ring实现原理剖析
http://www.cnblogs.com/yuxc/archive/2012/06/22/2558312.html 简介 OpenStack是一个美国国家航空航天局和Rackspace合作研发的开 ...
- .NET+MVC+Alipay的Sdk版单笔转账到支付宝账户接口
public class AliPayController : Controller { // GET: AliPay public ActionResult Index() { return Red ...
- 每日英语:Three Shows That Changed The Way Networks Think About Viewership
As we continue examining this season’s DVR success stories in The Blacklist and Sleepy Hollow it mak ...
- sql 基础练习 计算7天各个时间点的总和 group by order mysql一次查询多个表
SQL 基础练习 -- 创建数据库 CREATE DATABASE school CHARACTER SET UTF8; -- 使用数据库 USE school; -- id: 学生的id -- na ...
- FastText算法原理解析
1. 前言 自然语言处理(NLP)是机器学习,人工智能中的一个重要领域.文本表达是 NLP中的基础技术,文本分类则是 NLP 的重要应用.fasttext是facebook开源的一个词向量与文本分类工 ...
- 基于jQuery弹出层图片动画查看代码
分享一款基于jQuery弹出层图片动画查看代码是一款鼠标单击文字或图片内容放大显示且含圆角投影效果.效果图如下: 在线预览 源码下载 实现的代码. html代码: <div class=&q ...
- 用Python从零开始实现K近邻算法
KNN算法的定义: KNN通过测量不同样本的特征值之间的距离进行分类.它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别.K通 ...
- Thinkphp CURD中的where方法
今天来给大家讲下查询最常用但也是最复杂的where方法,where方法也属于模型类的连贯操作方法之一,主要用于查询和操作条件的设置.where方法的用法是ThinkPHP查询语言的精髓,也是Think ...
- python 普通方法,@classmethod,@staticmethod
普通方法 实例化一个类,然后通过类的实例化去调用方法: class method1: def __init__(self): self.items = [1,2,3,] def getvalue(se ...
- Install Shield常用函数以及参数
nstall Shield函数库 1 库函数综述InstallShield包含300多个内部库函数,用户可在安装脚本中调用它们来创建程序组,操作文件夹,处理目录,监督安装状态,创建对话框,操作文件及 ...