NUMA总结。
vsphere 5.1性能最佳实践http://www.vmware.com/pdf/Perf_Best_Practices_vSphere5.1.pdf
vNUMA
要求:硬件版本8以上。
1.整个cluster中的所有主机具备匹配的NUMA构架的话,启用vNUMA会得到最大的性能提升。
当vm启动的时候它的vNUMA结构会根据底层的NUMA结构设定。而且初始化后不会变化,除非更改了vCPU的数量。
如果vm从一个主机vMotion到另外一个主机上,而该目的主机的NUMA结构和源主机不一致,则VM的vNUMA结构不会是
最优化的。
2.VM的vCPU大小和物理NUMA节点内核数应该匹配。
例如每NUMA节点6core的结构,则VM分配的vCPU应该是6的倍数:6,12,18.。
注意:有些处理器NUMA节点大小不同于core总数/pre socket.
例如有的12核CPU具有2个6core的NUMA节点。
3.建立VM的时候如何选择virtual socket数量和core数量/per virtual socket.
一般建议1 core/per virtual socket.(缺省值,也即是cpuid.coresPerSocket)。这样的话virtual socket数量=vCPU数量。
如果启用了vNUMA的VM上设置core数量/pre virtual socket不是缺省的1或则和底层物理主机的结构不匹配。
性能会有降低。为达到最好性能,应该设置为NUMA node节点数的整倍数或则整除数。以上例为例子,可以设置为2,3,6,12,18
某些情况下,设置为NUMA node数一样会有性能提示。以上例则为6
4.缺省情况下vCPU分配超过8个以上的VM会自动启用vNUMA.
numa.vcpu.maxPerVirtualNode=x (vcpu少于8个的时候可以设置)
where X is the number of vCPUs per vNUMA node
see also:
he diagrams and the bulk of the technical content in this post was borrowed, with permission, from Frank Denneman’s blog. Frank is a Senior Architect for VMware’s Technical Marketing Team and an acknowledged expert in vSphere Resource Management. This post is my effort to consolidate the information from his blog on NUMA and to apply them to a specific use case.
This is also the first of a series of posts I plan to write regarding Business Critical Application design and sizing. Future plans are to cover specific applications such as Oracle, Exchange, and SAP.
Introduction
I’ve had the opportunity to work on multiple projects at VCE, helping customers virtualize their Business Critical Applications, such as Microsoft Exchange, Oracle, and SAP. One of the much neglected considerations, when sizing applications for virtualization, is the impact of Non-Uniform Memory Access (NUMA).
One large customer that I worked with to virtualize their Oracles environment decided to standardize on Linux VMs with 20 vCPUs. Their initial requirements included dedicating Cisco B230 M2 blades to these VMs and host no more than 2 VMs per blade; The B230 is a 2 CPU, 20 core (2×10) server with up to 512 GB RAM. My proposed Vblock design included a section on the impact of NUMA on Oracle sizing, along with the following NUMA-related recommendations:
- Redesign the Oracle database to be hosted on VMs with lower vCPU counts that match the maximum number of cores in a CPU socket.
- Host Oracle on multiple smaller VMs instead of on “monster” VMs. For example (8) 4-way VMs instead of (1) 32-way VM.
- If design constraints necessitate the use of large VMs, try to create VMs with vCPU and vRAM configurations that fit into a NUMA node.
So, how did I arrive at these design recommendations and what did the customer decide? Read on…
What is (NUMA)?
Non-Uniform Memory Access (NUMA) is a computer memory design used in multiprocessing, where the memory access time depends on the memory location relative to a processor. Under NUMA, a processor can access its own local memory faster than non-local memory, that is, memory local to another processor or memory shared between processors. Intel processors, beginning with Nehalem, utilize the NUMA architecture. In this architecture, a server is divided into NUMA nodes, which comprises of a single processor and its cores, along with its locally connected memory. For example, a B200 M3 blade with 3.3 GHz processors and 128 GB of RAM would have 2 NUMA nodes; each node having 1 physical CPU with 4 cores and 64 GB of RAM.
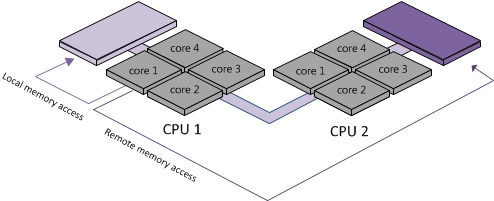
Memory access is designed to be faster when is it localized within a NUMA node compared to remote memory access since the memory access exchange would have to traverse the interconnect between 2 NUMA nodes. As a result, it is preferable to keep remote memory access to a minimum when sizing VMs.
How Does NUMA Affect VM Sizing?
vSphere is NUMA aware and when it detects that it is running on a NUMA system, such as UCS, the NUMA CPU Scheduler will kick in and assign a VM to a NUMA node as a NUMA client. If a VM has multiple vCPUs, the Scheduler will attempt to assign all the vCPUs for that VM to the same NUMA node to maintain memory locality. Best practices dictate that a the total quantity of vCPUs and vRAM for a VM should ideally not exceed the number of cores in the physical processor or the amount of RAM of its assigned NUMA node. For example, a 4-way VM on a B200 M3 with 4 or 8 core processors and 128 GB RAM will reside on a single NUMA node, assuming it has no more than 64 GB of vRAM assigned to it.
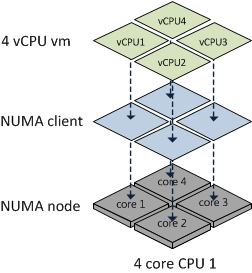
However, if the vCPU count of a VM exceeds the number of cores in its ESXi server’s given NUMA node or the vRAM exceeds the physical RAM of that node, then that VM will NOT be treated as a normal NUMA client.
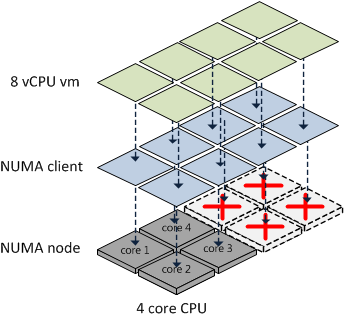
Prior to vSphere 4.1, the ESXi CPU Scheduler would load balance the vCPUs and vRAM for such a VM across all available cores in a round-robin fashion. This is illustrated below.
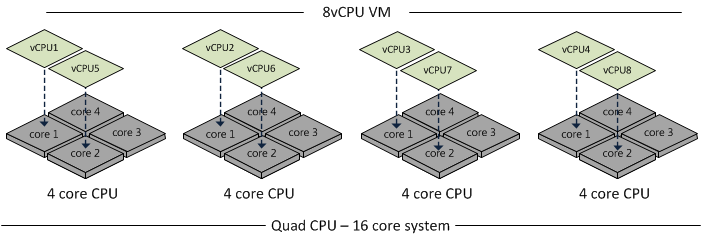
As you can see, this scenario increase the likelihood that memory access will have to cross NUMA node boundaries, adding latency to the system.
Beginning with 4.1, vSphere supports the concept of a Wide-VM. The ESXi CPU Scheduler now splits the VM into multiple NUMA clients so that better memory locality can be maintained. At VM power-up, the Scheduler calculates the number of NUMA clients required so that each client can reside in a NUMA node. For example, if an 8-way 96 GB VM resided on a B200 M3 with 4-core processors and 128 GB RAM, the Scheduler will create 2 NUMA Clients, each assigned to a NUMA node.
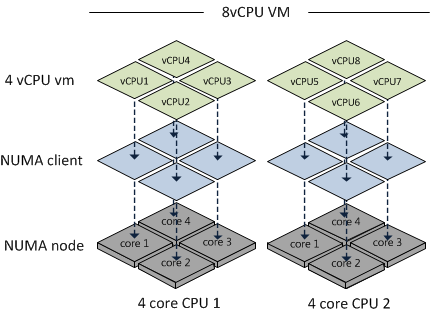
The advantage here is that memory locality is increased, which potentially decreases the amount of high latency remote memory access. However, it does not provide as much performance as a VM which resides on a single NUMA node. Btw, if you create a VM with 6 vCPUs on a 4-core B200 M3, the Scheduler will create 2 NUMA nodes – one with 4 cores and the other with 2 cores. This is due to the fact that the Scheduler attempts to keep as many vCPUs in the same NUMA node as possible.
vNUMA
[This contents of this section is taken from VMware's vSphere Resource ManagementTechnical paper.]
Beginning in vSphere 5.0, VMware introduced support for exposing virtual NUMA topology to guest operating systems, which can improve performance by facilitating guest operating system and application NUMA optimizations.
Virtual NUMA topology is available to hardware version 8 and hardware version 9 virtual machines and is enabled by default when the number of virtual CPUs is greater than eight. You can also manually influence virtual NUMA topology using advanced configuration options.
You can affect the virtual NUMA topology with two settings in the vSphere Client: number of virtual sockets and number of cores per socket for a virtual machine. If the number of cores per socket (cpuid.coresPerSocket) is greater than one, and the number of virtual cores in the virtual machine is greater than 8, the virtual NUMA node size matches the virtual socket size. If the number of cores per socket is less than or equal to one, virtual NUMA nodes are created to match the topology of the first physical host where the virtual machine is powered on.
Recommendations
While the ability to create Wide-VMs do alleviate the issues of memory access latency by reducing the number of memory requests that will likely need to traverse NUMA nodes, there is still a performance impact that could affect Business-Critical Applications (BCA) with stringent performance requirements. For this reason, the following recommendations should be considered when sizing BCAs:
- When possible, create smaller VMs, instead of “Monster” VMs, that fit into a single NUMA node. For example, design VMs with no more than 4 vCPUs and 64 GB of RAM when using a B200 M3 with 4-core processors and 128 GB of RAM.
- When feasible, select blade configurations with NUMA nodes that match or exceed the largest VMs that will be hosted. For example, if a customer will be creating VMs with 8 vCPUs, consider choosing a blade with 8 or 10 cores, assuming the CPU cycles are adequate.
- If a “monster” VM, such as a 32-way host, is required, it may advantageous to select blades with higher core density so that larger NUMA nodes can be created and memory locality can be increased.
Conclusion
The customer I referenced in the beginning of the post eventually decided to deploy their virtualized Oracle environment on a Vblock with Cisco UCS B200 M2 blades, with 2 CPUs, 12 cores (2×12); their standard Oracle was allocated 6 vCPUs. They did so to distribute their Oracle workload across multiple smaller VMs and to keep their VMs within NUMA node boundaries.
For more information about NUMA and vSphere sizing, you can reference Frank Denneman’s blog posts on “Sizing VMs and NUMA nodes” and “ESX 4.1 NUMA Scheduling.” For more information about virtualizing Business Critical Applications, go to VMware’s Virtualizing Business Critical Enterprise Applications webpage and read all available documentation, including the “Virtualizing Business Critical Applications on vSphere” white paper. I’ve also been helped by by reading and listening toMichael Webster; you can hear him talk about “Virtualizing Tier One Applications” on the APAC Virtualization Roundtable Podcast.
Related articles
- Could DINO Be The Future Of vSphere NUMA Scheduler? (deinoscloud.wordpress.com)
有价值的回帖:
Hi Ken,
In your example of the 20 vCPU VM on the 2 x 10 Core Host, with HT this is 40 logical cores or 20 logical cores per socket. By using numa.vcpu.preferht=TRUE on a per VM basis, or by using the host setting numa.preferht you could have kept the 20 vCPU Oracle VM’s on a single NUMA node. Assuming their memory also fitted within the NUMA node they’d get all local access. PreferHT has the effect if making the VM prefer to use the hot logical CPU’s within a CPU core instead of another socket. This improves cache coherency and can improve performance, but it’s not the same as have a full additional CPU socket. Quite a fer performance tests have shown performance improvements with this setting though. Especially with Oracle, because Oracle itself doesn’t work well with NUMA. You can refer to KB 2003582 for where to enter the settings, Frank also covers this in his articles.
NUMA总结。的更多相关文章
- SMP、NUMA、MPP(Teradata)体系结构介绍
从系统架构来看,目前的商用服务器大体可以分为三类,即对称多处理器结构 (SMP : Symmetric Multi-Processor) ,非一致存储访问结构 (NUMA : Non-Uniform ...
- 如何知道SQL Server机器上有多少个NUMA节点
如何知道SQL Server机器上有多少个NUMA节点 文章出处: How can you tell how many NUMA nodes your SQL Server has? http://i ...
- 我有几个NUMA节点
在SQL Server交流会,经常被问到的一个问题,SQL Server在几个NUMA节点上运行.因此,在今天的文章里,我想向你展示下几个方法和技术,找出你的SQL Server有几个NUMA节点. ...
- 一则因为numa引发的mysqldump hang住
新买的dell r430服务器,双CPU,64G内存,单CPU32g,swap 3G 出现故障现像:mysqldump时会hang住,innodb_buffer_pool_size = ...
- 服务器三大体系SMP、NUMA、MPP介绍
从系统架构来看,目前的商用服务器大体可以分为三类,即: 对称多处理器结构(SMP:Symmetric Multi-Processor) 非一致存储访问结构(NUMA:Non-Uniform Memor ...
- NUMA架构的CPU -- 你真的用好了么?
本文从NUMA的介绍引出常见的NUMA使用中的陷阱,继而讨论对于NUMA系统的优化方法和一些值得关注的方向. 文章欢迎转载,但转载时请保留本段文字,并置于文章的顶部 作者:卢钧轶(cenalulu) ...
- 虚拟机NUMA和内存KSM
KSM技术可以合并相同的内存页,即使是不同的NUMA节点,如果需要关闭跨NUMA节点的内存合并,设置/sys/kernel/mm/ksm/merge_across_nodes参数为0.或者可以关闭特定 ...
- Mongodb在NUMA机器上的优化
10gen在mongodb的部署指南上,提到了在NUMA机器上,mongodb可能会出现问题,参见:http://docs.mongodb.org/manual/administration/prod ...
- oracle开启numa的支持
在11.2中,即使是系统支持numa架构,oracle默认也不再检测硬件是否支持numa,也不开启对numa的支持. 要想开启对numa的支持,必须设置隐含参数: _enable_NUMA_suppo ...
- 系统调优之numa架构
NUMA简介 在传统的对称多处理器(SMP, Symmetric Multiprocessing)系统中,整个计算机中的所有cpu共享一个单独的内存控制器.当所有的cpu同时访问内存时,这个内存控制器 ...
随机推荐
- Java Calendar,Date,DateFormat,TimeZone,Locale等时间相关内容的认知和使用(6) Locale
本章介绍Locale. 1 Locale 介绍 Locale 表示地区.每一个Locale对象都代表了一个特定的地理.政治和文化地区. 在操作 Date, Calendar等表示日期/时间的对象时,经 ...
- HelloWorld 之JasperReports初步
在企业应用系统中,经常要输出各种格式的数据报表. 著名的开源项目<JasperReports可以很好的解决这个问题. 使用JasperReports可以在预先设定好格式的报表基础上进行数据的填充 ...
- SQL:显示每天的小计,某一天没有记录也要显示
对于这种需求,我们需要一个主表存储连续的日期,然后使用 left join 即可. declare @Daily table ( 日期 date ) declare @start date = '20 ...
- python测试开发django-25.表单提交之post注册案例
前言 一个网站上新用户注册,会写个注册页面,如果用django写个注册页面的流程呢? 本篇以post请求示例,从html页面上输入用户注册信息,提交到后台处理数据,然后传参数据到User数据库表里面 ...
- CentOS 7 修改时区
转自:http://blog.csdn.net/robertsong2004/article/details/42268701 本文转载至:http://mathslinux.org/?p=637 L ...
- [Web 前端] this作用域问题
如何不用这种写法:理想的写法是this.setState({ .... }) 可能是我没有描述清楚,我不想用这种学法而已,这样多了一个变量,我觉得很不舒服.我尝试了先把 setState 赋值到变量里 ...
- 脚本不得关闭非脚本打开的窗口。Scripts may close only the windows that were opened by it
今天脚本了里写了一句话: window.close() 但是浏览器却报了警告提示:Scripts may close only the windows that were opened by it,而 ...
- 强大的模板引擎开源软件NVelocity
背景知识NVelocity(http://sourceforge.net/projects/nvelocity )是从java编写的Velocity移植的.net版本,是java界超强的模版系统,.n ...
- iOS:三种常见计时器(NSTimer、CADisplayLink、dispatch_source_t)的使用
一.介绍 在iOS中,计时器是比较常用的,用于统计累加数据或者倒计时等,例如手机号获取验证码.计时器大概有那么三种,分别是:NSTimer.CADisplayLink.dispatch_source_ ...
- js中document.write的那点事
document.write()方法可以用在两个方面:页面载入过程中用实时脚本创建页面内容,以及用延时脚本创建本窗口或新窗口的内容.该方法需要一个字符串参数,它是写到窗口或框架中的HTML内容.这些字 ...