Mybatis源码分析之Cache一级缓存原理(四)
之前的文章我已经基本讲解到了SqlSessionFactory、SqlSession、Excutor以及Mpper执行SQL过程,下面我来了解下myabtis的缓存,
它的缓存分为一级缓存和二级缓存,本文我们主要分析下一级缓存。
先看一个例子,代码还是之前(第一篇)的的demo
public static void main(String[] args) throws Exception {
SqlSessionFactory sessionFactory = null;
String resource = "configuration.xml";
sessionFactory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsReader(resource));
SqlSession sqlSession = sessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
System.out.println(userMapper.findUserById(1));
System.out.println(userMapper.findUserById(1));
}
上面代码我们执行了两次userMapper.findUserById(1),结果如下图
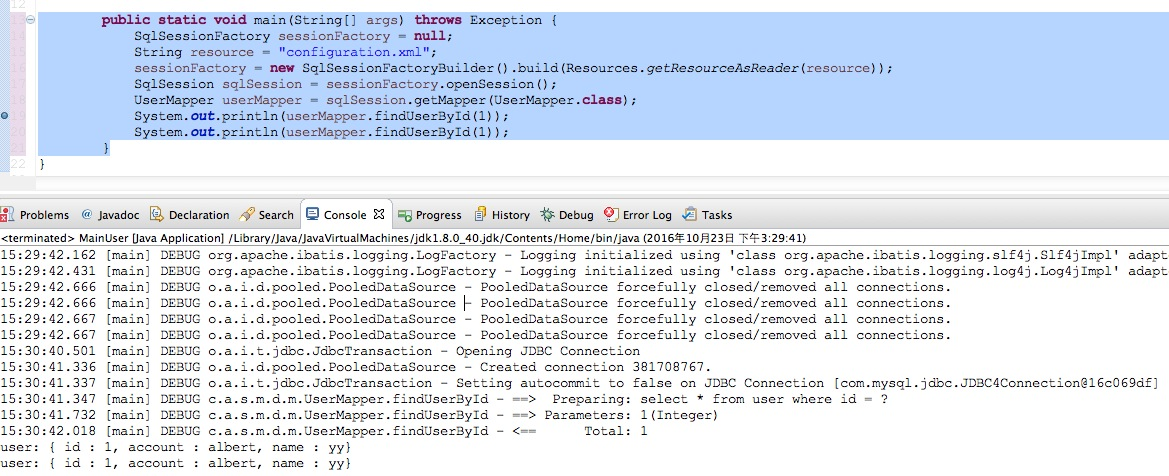
从执行结果看,DB的查询只有1次,那么第二次的查询结果是在怎么来的呢?
一:什么是一级缓存
每当我们使用MyBatis开启一次和数据库的会话,MyBatis会创建出一个SqlSession对象表示一次数据库会话。 在对数据库的一次会话中,我们有可能会反复地执行完全相同的查询语句,如果不采取一些措施的话,每一次查询都会查询一次数据库,而我们在极短的时间内做了完全相同的查询,那么它们的结果极有可能完全相同,由于查询一次数据库的代价很大,这有可能造成很大的资源浪费。
为了解决这一问题,减少资源的浪费,MyBatis会在表示会话的SqlSession对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候,如果判断先前有个完全一样的查询,会直接从缓存中直接将结果取出,返回给用户,不需要再进行一次数据库查询了。
基本的流程示意图如下:
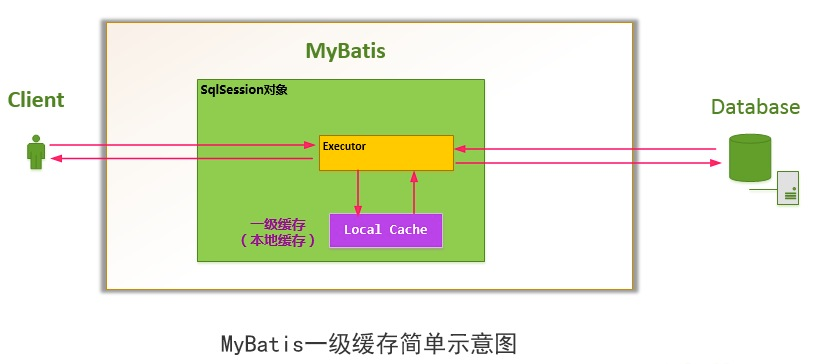
对于会话(Session)级别的数据缓存,我们称之为一级数据缓存,简称一级缓存。
二:如何执行缓存
我们知道mybatis的SQL执行最后是交给了Executor执行器来完成的,我们看下BaseExecutor类的源码
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
@SuppressWarnings("unchecked")
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;//localCache 本地缓存
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); //如果缓存没有就走DB
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);//清空现有缓存数据
}
localCache.putObject(key, list);//新的结果集存入缓存
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
通过上面的三个方法我们基本已经看明白了缓存的使用,它的本地缓存使用的是PerpetualCache类,内部其实还是一个HashMap,只是稍微做了封装而已。
我们再看下天的Key是如何生成的
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
@Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
CacheKey cacheKey = new CacheKey();
cacheKey.update(ms.getId());
cacheKey.update(Integer.valueOf(rowBounds.getOffset()));
cacheKey.update(Integer.valueOf(rowBounds.getLimit()));
cacheKey.update(boundSql.getSql());
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
// mimic DefaultParameterHandler logic
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
cacheKey.update(value);
}
}
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId());
}
return cacheKey;
}
它是通过statementId,params,rowBounds,BoundSql来构建一个key值,根据这个key值去缓存Cache中取出对应的key值存储的缓存结果。
我们用一张图来看清楚一级缓存的基本流程(本图网上早来的,自己懒得画了)
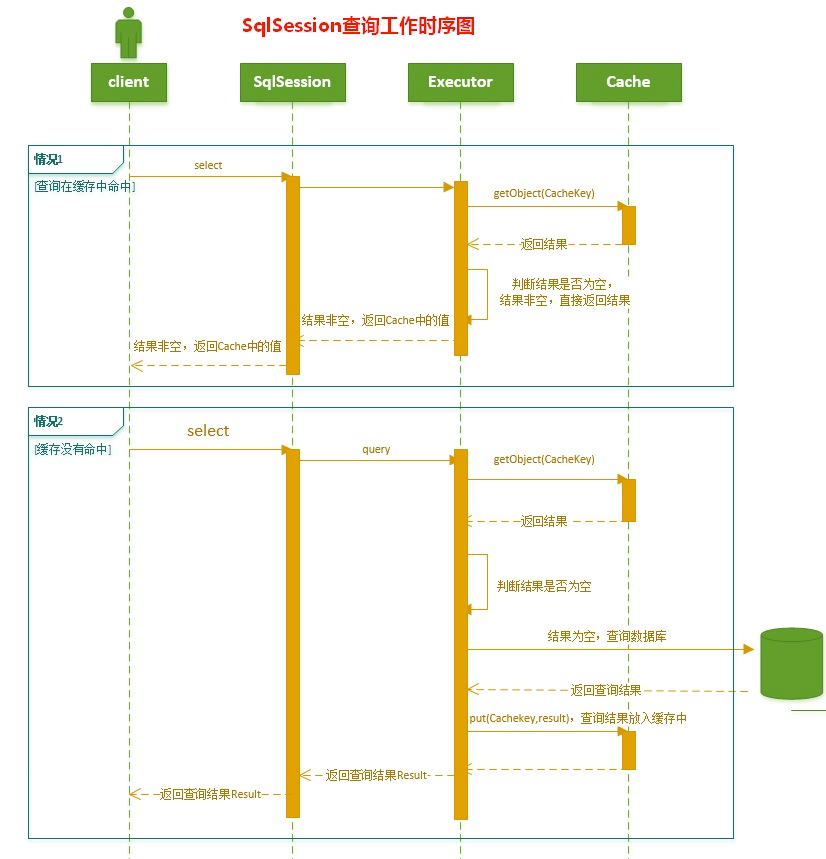
三:一级缓存生命周期
1. MyBatis在开启一个数据库会话时,会创建一个新的SqlSession对象,SqlSession对象中会有一个新的Executor对象,
Executor对象中持有一个新的PerpetualCache对象;当会话结束时,SqlSession对象及其内部的Executor对象还有PerpetualCache对象也一并释放掉。
2. 如果SqlSession调用了close()方法,会释放掉一级缓存PerpetualCache对象,一级缓存将不可用。
3. 如果SqlSession调用了clearCache(),会清空PerpetualCache对象中的数据,但是该对象仍可使用。
4.SqlSession中执行了任何一个update操作(update()、delete()、insert()) ,都会清空PerpetualCache对象的数据,但是该对象可以继续使用。
Mybatis源码分析之Cache一级缓存原理(四)的更多相关文章
- Mybatis源码分析之Cache二级缓存原理 (五)
一:Cache类的介绍 讲解缓存之前我们需要先了解一下Cache接口以及实现MyBatis定义了一个org.apache.ibatis.cache.Cache接口作为其Cache提供者的SPI(Ser ...
- mybatis源码分析之05一级缓存
首先需要明白,mybatis的一级缓存就是指SqlSession缓存,Map缓存! 通过前面的源码分析知道mybatis框架默认使用的是DefaultSqlSession,它是由DefaultSqlS ...
- Guava 源码分析之Cache的实现原理
Guava 源码分析之Cache的实现原理 前言 Google 出的 Guava 是 Java 核心增强的库,应用非常广泛. 我平时用的也挺频繁,这次就借助日常使用的 Cache 组件来看看 Goog ...
- mybatis源码分析之06二级缓存
上一篇整合redis框架作为mybatis的二级缓存, 该篇从源码角度去分析mybatis是如何做到的. 通过上一篇文章知道,整合redis时需要在FemaleMapper.xml中添加如下配置 &l ...
- MyBatis源码分析(2)—— Plugin原理
@(MyBatis)[Plugin] MyBatis源码分析--Plugin原理 Plugin原理 Plugin的实现采用了Java的动态代理,应用了责任链设计模式 InterceptorChain ...
- mybatis源码分析(7)-----缓存Cache(一级缓存,二级缓存)
写在前面 MyBatis 提供查询缓存,用于减轻数据库压力,提高数据库性能. MyBatis缓存分为一级缓存和二级缓存. 通过对于Executor 的设计.也可以发现MyBatis的缓存机制(采用模 ...
- MyBatis源码分析(4)—— Cache构建以及应用
@(MyBatis)[Cache] MyBatis源码分析--Cache构建以及应用 SqlSession使用缓存流程 如果开启了二级缓存,而Executor会使用CachingExecutor来装饰 ...
- MyBatis 源码分析 - 缓存原理
1.简介 在 Web 应用中,缓存是必不可少的组件.通常我们都会用 Redis 或 memcached 等缓存中间件,拦截大量奔向数据库的请求,减轻数据库压力.作为一个重要的组件,MyBatis 自然 ...
- MyBatis源码分析(五):MyBatis Cache分析
一.Mybatis缓存介绍 在Mybatis中,它提供了一级缓存和二级缓存,默认的情况下只开启一级缓存,所以默认情况下是开启了缓存的,除非明确指定不开缓存功能.使用缓存的目的就是把数据保存在内存中,是 ...
随机推荐
- C++中的vector&find_if
<STL應用> vector & find_if 看到有人問有個名為C的struct如下 code: struct C { int v1; int v2; }; 應用在vecto ...
- 在vs2012下编译出现Msvcp120d.dll 丢失的问题
之前在vs2012下编译一个opencv程序时,一直出现msvcp120d.dll文件丢失的提示信息,最初会在网上找dll下载,将其拖入系统文件夹再进行regsvr32命令操作,结果都没有解决错误,甚 ...
- XE5 修复 安卓 输入法隐藏 后 无法退出的问题 3.1
(****************************************************)(* *)(* 编写:爱吃猪头肉 & Flying Wang *)(* 上面的版权声 ...
- javascript:currentStyle和getComputedStyle的兼容写法
currentStyle:获取计算后的样式,也叫当前样式.最终样式. 优点:可以获取元素的最终样式,包括浏览器的默认值,而不像style只能获取行间样式,所以更常用到. 注意:不能获取复合样式如bac ...
- 浅析c++中virtual关键字
http://blog.csdn.net/djh512/article/details/8973606 1.virtual关键字主要是什么作用? c++中的函数调用默认不适用动态绑定.要触发动态绑定, ...
- .NET:一微秒内可能执行多条 DateTime.Now
出现BUG的上下文 自己写的工作流引擎出现了一点问题,就是因为可能存在一个请求同时流转两个节点(不必深究这个问题),因为每个节点都有一个“进入时间”,引擎的实现将最后一个“进入时间“对应的节点当作了” ...
- .NET零基础入门09:SQL必知必会
一:前言 仿佛到了更进一步的时候了,每一个程序员迟早都会遇到数据存储的问题.我们拿什么来存储程序产生的数据?举例来说,用什么来存储我们的打老鼠游戏每次的成绩呢?选择如下: 1:内存中.缺点,退出游戏, ...
- Cannot convert type SomeClass to 'T'
以下代码会出问题: public static T Protect<T>(Func<T> func, UserLevel pageRole) where T : ActionR ...
- Apache的三种工作模式
Web服务器Apache目前一共有三种稳定的MPM(Multi-Processing Module,多进程处理模块)模式. 它们分别是prefork,worker和event,它们同时也代表这Apac ...
- State of Serverless
Some quick thoughts from Serverlessconf, Austin in April 2017 I wanted to take a bit of time to writ ...