Kafka: Connect
转自:http://www.cnblogs.com/f1194361820/p/6108025.html
Kafka Connect 简介
Kafka Connect 是一个可以在Kafka与其他系统之间提供可靠的、易于扩展的数据流处理工具。使用它能够使得数据进出Kafka变得很简单。Kafka Connect有如下特性:
·是一个通用的构造kafka connector的框架
·有单机、分布式两种模式。开发时建议使用单机模式,生产环境下使用分布式模式。
·提供restful的管理connector的API。
·自动化的offset管理。Kafka Connect自动的管理offset提交。
·分布式、可扩展。采用与concumer group中对partition rebalance同样的机制来管理在worker group中的connector、task。
·流/批处理的集成。
接下来会对Kafka Connect做一个全面的分析,来帮助了解上述特性。
1、基本组件:
1.1 Worker

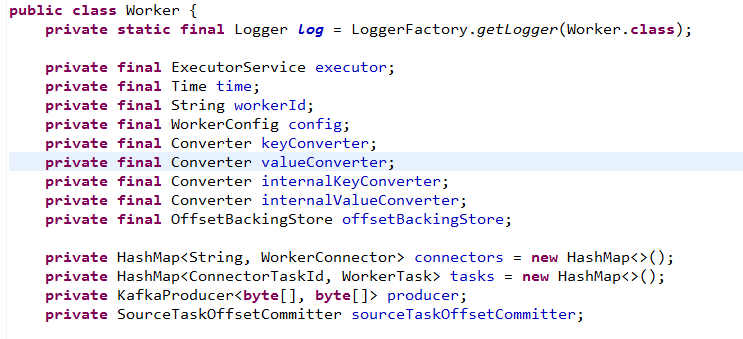
Worker用于调度source task、sink task 来处理数据的进出Kafka。一个Worker中包括多个Connector。一个Connector与多个task关联。当启动(或者加入)一个Connector时,与之关联的Tasks会被创建并提交到executor去执行;停止(或移除)一个Connector时,与之关联的Tasks会被停止并移除。也就是说Worker管理Connector插件的插、拔,Task的启、停。
1.2 Connector
Connector,可以看做是Kafka Connect的插件,用来与其他系统进行集成。有两类:SourceConnector、SinkConnector。如果要实现一个Connector,那么必须继承这两个类中的一个,这是硬性要求。Connector 与Task关联,Worker对Connector的启、停、插、拔,其实最终反映在对Task启、停、插、拔上。
Connector主要为创建Task实例提供配置,可以提供connector本身的配置,也可以提供task的配置。
1.3 Task
Task是由Worker中的executor来执行的。在Worker中包括了所有的WorkerTask。WorkerTask有两类:WorkerSourceTask、WorkSinkTask。
在运行过程中,WorkerSourceTask不断的做如下调用:
1)调用SourceTask.poll()方法取得数据SourceRecords,
2)使用相应的Converter将SourceRecords转换为ProducerRecords,
3)并由KafkaProducer#send推给Kafka Broker
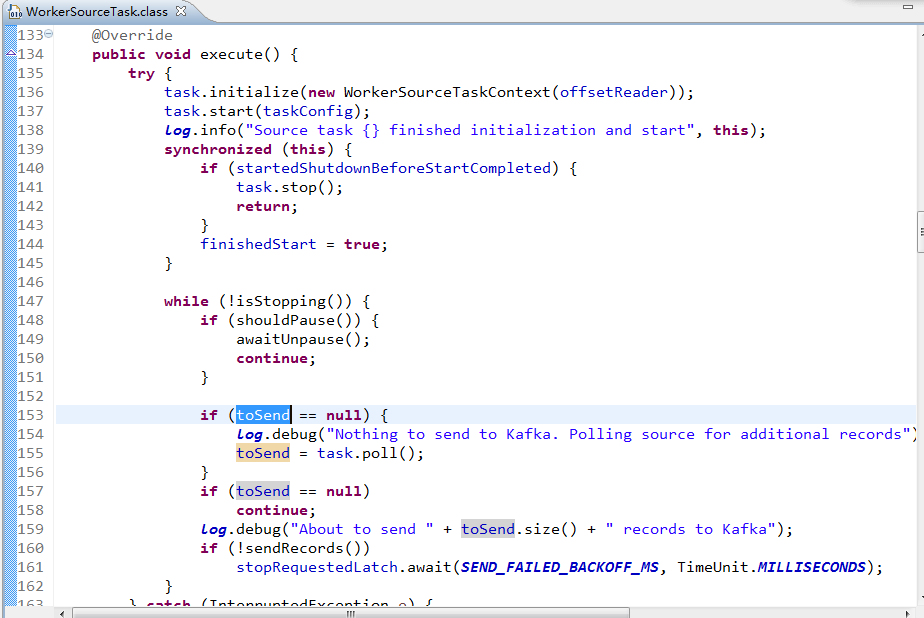
在运行过程中,WorkerSinkTask不断的做如下调用:
1)调用KafkaConsumer#poll方法从Kafka Broker拉取ConsumerRecords,
2)使用相应的Converter将ConsumerRecords转换为SinkRecords,
3)调用SinkTask#flush方法来执行自定义的处理
4)提交 offset到Kafka Broker。


不难看出,只有系统运行正常,SinkTask、SourceTask都会被一次又一次的调用。即一个Task实例会占用一个线程。如果一个为Connector配置了task数量大于1,就会有多个tasks实例(这多个Task实例是同一个Java类的多个实例)与该Connector关联,那么这多个tasks在运行时必然是并发执行的。这就要求SourceTask#poll()、SinkTask#flush()在运行时能够保证线程安全性。
另外从WorkerSinkTask#flush如果出现异常,是不会提交offset的。此外,还会调用consumer#seek找到上一次提交的offset,seek的作用是:让下一次使用consumer#poll方法时,从上一次提交的offset开始poll。这样就可以保证数据在consume过程中不会丢失。
1.3.1 Kafka Connect与Kafka Producer、Kafka Consumer关系
Kafka Connect必然是要依赖于KafkaProducer、KafkaConsumer的。这种依赖关系到底是怎样的呢?从上面WorkerSinkTask、WorkerSourceTask的执行过程来看,他们是直接与KafkaConsumer、KafkaProducer直接关联的。经过源码的查看可以了解到:
在一个Worker内,所有的WorkerSourceTask共享同一个KafkaProducer对象来发送record到Kafka,这种设计也符合KafkaProducer的使用原则;每一个WorkerSinkTask拥有一个私有的KafkaConsumer,也就是说不存在KafkaConsumer共享使用的情况。
既然一个WorkerSinkTask独自使用一个KafkaConsumer,那么一个WorkerSinkTask就可以认为是一个独立的KafkaConsumer。那么如果一个WorkerSinkTask因某种原因启动、加入、重启、结束、中断、停止,就等于是说一个KafkaConsumer加入、退出consumer group,那么该consumer group 的Coordinator Broker就会发起rebalance,使得该KafkaConsumer被分配到的partiion分配到group 内其他的KafkaConsumer上。
在Kafka-Connect中,如何对KafkaConsumer进行分组呢?
从WorkerSinkTask的相关源码来看:
|
private KafkaConsumer<byte[], byte[]> createConsumer() { // Include any unknown worker configs so consumer configs can be set globally on the worker // and through to the task Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.GROUP_ID_CONFIG, "connect-" + id.connector()); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, Utils.join(workerConfig.getList(WorkerConfig.BOOTSTRAP_SERVERS_CONFIG), ",")); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.ByteArrayDeserializer"); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.ByteArrayDeserializer"); props.putAll(workerConfig.originalsWithPrefix("consumer.")); KafkaConsumer<byte[], byte[]> newConsumer; try { newConsumer = new KafkaConsumer<>(props); } catch (Throwable t) { throw new ConnectException("Failed to create consumer", t); } return newConsumer; } |
是把与同一个Connector关联的Task会分到一个Consumer Group中。如果要自定义并且 组名默认是connector的名字。如果要自定义Consumer的属性,可以在worker 的配置文件中使用consumer.前缀的方式来完成。
通过上述代码也可以看出,默认情况下,关闭了KafkaConsumer的自动提交offset,改为由Kafka Connect来完成offset的提交。
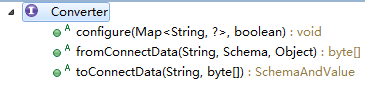
1.4 Converter
WorkerSinkTask、WorkerSourceTask的执行过程中,会使用Key的Converter、Value的Converter对Key、Value进行转换。
这样做的原因:
作为一个Connector框架,在进行producer#send、consumer#pool时,框架本身并不知道用户的程序中,如何进行序列化、反序列化操作。并且进入Kafka的数据类别不同,所需要的序列化、反序列化工具也不同。
为了解决这一问题,Kafka Connect中引入了Converter、Schema。
WorkerSoureTask中,将SourceRecord中的key、value取出来,经过Converter转换(序列化)成byte[],转成ProducerRecord。
|
for (final SourceRecord record : toSend) { byte[] key = keyConverter.fromConnectData(record.topic(), record.keySchema(), record.key()); byte[] value = valueConverter.fromConnectData(record.topic(), record.valueSchema(), record.value()); final ProducerRecord<byte[], byte[]> producerRecord = newProducerRecord<>(record.topic(), record.kafkaPartition(), key, value); … } |
WorkerSinkTask中,将consumer#poll到的ConsumerRecord转换(反序列化)成SinkRecord:
|
private void convertMessages(ConsumerRecords<byte[], byte[]> msgs) { for (ConsumerRecord<byte[], byte[]> msg : msgs) { log.trace("Consuming message with key {}, value {}", msg.key(), msg.value()); SchemaAndValue keyAndSchema = keyConverter.toConnectData(msg.topic(), msg.key()); SchemaAndValue valueAndSchema = valueConverter.toConnectData(msg.topic(), msg.value()); messageBatch.add( new SinkRecord(msg.topic(), msg.partition(), keyAndSchema.schema(), keyAndSchema.value(), valueAndSchema.schema(), valueAndSchema.value(), msg.offset()) ); } } |
2、Rebalance
Kafka Connect支持单机、分布式(集群)两种模式。在生产环境下,通常会使用分布式模式。
通常情况下业务系统集群的数据进入到kafka,然后有Consumer集群进行数据消费处理。如果使用Kafka Connect,集群方案就变得很简单并且扩展性很好。
根据前面所了解的内容来看,一个Connector关联到一类Task,可以指定该类Task的数目,也就是Consumer的数目。也就是说一个Connector关联到一个Consumer Group上。如果Worker是单机模式,那么这个Consumer Group内的多个Consumer就是在同一进程内。如果进程挂掉,也就是整个Consumer Group全部挂掉。
在使用集群模式(Worker Cluster)时,这个问题如果不解决,所谓的集群就没有任何意义。所以在Worker Cluster模式时,重点要解决上述问题。
通过之前的Consumer、Broker的学习,知道Broker会为每一个Consumer Group提供一个协处理器。在Broker Coordinator、 Consumer Leader的配合下,当有Consumer 加入或退出Consumer Group时,会对partition进行rebalance。使得partition相对均匀的分配给各个Consumer上,以此来避免出现热点(partition分配给少数的Consumer上)问题。
Kafka Connect在解决这个问题时,也采用了同样的方案:即使用Broker Coordinator 配合 Worker Leader的方式,对connector、task进行rebalance。这样一来,使connector、task相对均匀的分配到同一个Worker Group中的不同的Worker上。如此便可以解决上述问题了。
一个Worker Leader分配connector、task时的处理是:
|
private Map<String, ByteBuffer> performTaskAssignment(String leaderId,long maxOffset, Map<String, ConnectProtocol.WorkerState> allConfigs) { Map<String, List<String>> connectorAssignments = new HashMap<>(); Map<String, List<ConnectorTaskId>> taskAssignments = newHashMap<>(); // Perform round-robin task assignment CircularIterator<String> memberIt = new CircularIterator<>(sorted(allConfigs.keySet())); for (String connectorId : sorted(configSnapshot.connectors())) { String connectorAssignedTo = memberIt.next(); log.trace("Assigning connector {} to {}", connectorId, connectorAssignedTo); List<String> memberConnectors = connectorAssignments.get(connectorAssignedTo); if (memberConnectors == null) { memberConnectors = new ArrayList<>(); connectorAssignments.put(connectorAssignedTo, memberConnectors); } memberConnectors.add(connectorId); for (ConnectorTaskId taskId :sorted(configSnapshot.tasks(connectorId))) { String taskAssignedTo = memberIt.next(); log.trace("Assigning task {} to {}", taskId, taskAssignedTo); List<ConnectorTaskId> memberTasks = taskAssignments.get(taskAssignedTo); if (memberTasks == null) { memberTasks = new ArrayList<>(); taskAssignments.put(taskAssignedTo, memberTasks); } memberTasks.add(taskId); } } this.leaderState = new LeaderState(allConfigs, connectorAssignments, taskAssignments); return fillAssignmentsAndSerialize(allConfigs.keySet(), ConnectProtocol.Assignment.NO_ERROR, leaderId, allConfigs.get(leaderId).url(), maxOffset, connectorAssignments, taskAssignments); } |
下面这张图展示了某个Worker失败情况下,对Task Rebalance的情况:
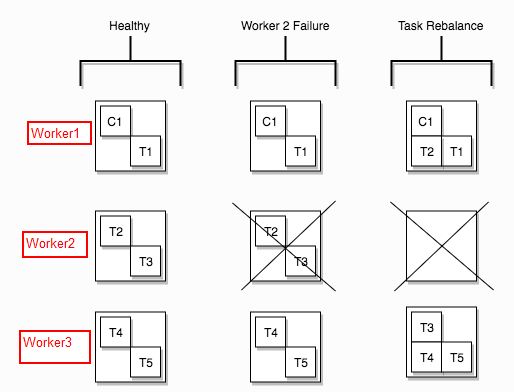
一个Connector 1设置了5个task:
第一列表示所有的Worker都正常工作情况下 Task的分配。
第二列表示Worker 2进程出现故障, task2、task3也就挂掉了。
第三列表示对Task进行rebalance后,task2、task3被rebalance到其他的Worker名下了。
3、Storage
3.1 内置Storage
在Kafka Connect中,内置了3种Storages。这三种配置都会(不论是Standalone,还是Distributed)有一份基于内存的Storage。下面只是针对内存Storage以外的方式进行说明:
·status’s storage
存储各个connector、task的状态信息。在Worker分布式的情况下,存储在Kafka 的一个Topic中,topic的名字由worker配置项status.storage.topic来指定。
Status 有5种:
1) UNASSIGNED:connector或者task是否被分配到了个Worker上。
2) RUNNING: connector或者task是否正在运行。
3) PAUSED: connector或者task是否已暂停运行。
4) FAILED: connector或者task是否失败(通常是抛出异常)。
5) DESTROYED:connector或者task是否已被删除。
在运行时,会定时更新状态信息。
·offset’s storage
在Kafka Connect中,WorkerSourceTask 用于从某个源拉数据,然后使用kafkaProducer#send推送到Kafka中。如果一个Connector 配置了多个Task,那么这多个Task应该是从不同的源中取数据。
其中这里说的源可以是多个File,一个或者多个Topic,可以是RDBMS中的多张表,可以是多个Queue等等。
为了记录从哪个源读取数据时读取到了哪个位置,当WorkerSourceTask中断重启时,能够继续从这个位置读取。Kafka Connect 为 SourceRecord设计了 两个字段:sourcePartition, sourceOffset:
public SourceRecord(Map<String, ?> sourcePartition, Map<String, ?> sourceOffset,
String topic, Integer partition, Schema valueSchema, Object value) {
this(sourcePartition, sourceOffset, topic, partition, null, null, valueSchema, value);
}
sourcePartition :用于表示从哪个Source中读取数据。所以它可以是一个File名、某个topic的partition、一个table名 等等。
sourceOffset:用于表示读取到哪个位置。可以它可以是一个File中哪一行、某个topic的partition的哪个offset、table中的第几行 等等。
因为sourcePartition, sourceOffset是可以自定义的,所以它具体的数据类型,并不知道。为了能够方便的进行序列化、反序列化,可以配置internal.key.converter (用于序列化、反序列化sourcePartition), interval.value.converter (用于序列化、反序列化sourceOffset)。
Kafka Connect会 会把sourcePartition, sourceOffset 以 一个key-value 方式(key 是 sourcePartition, value 是sourceOffset)存储起来。单机模式、分布式模式下,都会存储这个offset的。
只是在Standalone模式下,是以本地File方式存储。分布式模式下,是把sourcePartition, sourceOffset做为一条 record存储在Kafka中的一个topic中。Topic的名称由worker配置项offset.storage.topic来指定。
这个offset与Broker中的Log的offset 没有任何的关系。
·config’s storage
在Kafka connect中,每一个Connector,以及与之关联的Task都会有一些配置信息。在rebalance后,还是需要用到这些配置的。为了使得Worker Group内共享配置,也需要对connector、task的配置进行存储。
分布式模式下,会在一个topic中存储。Topic的名称由worker配置项 config.storage.topic来指定。
4、Connector 管理
4.1 Herder
在前面的基本组件中,可以了解到,Worker可以对Connector进行启、停、插、拔。为了更加方便的管理Connector,Kafka-Connect中在Worker之外提供了一个工具Herder(翻译为汉语:牧人,其实也就是管理者的意思)。
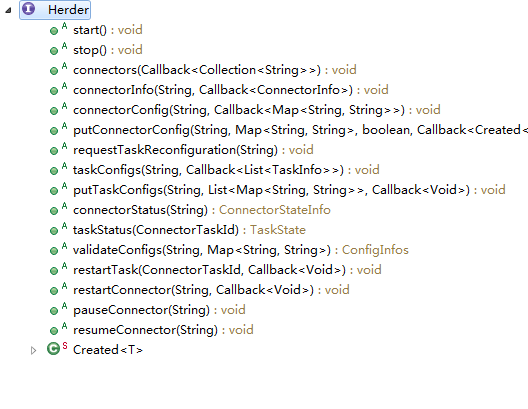
使用Herder可以插、拔Connector,可以启、停Task,可以修改Connector的配置,获取connector、task的状态。
针对Standalone、Distributed模式,实现的Herder也是不尽相同的。一些修改性质的操作都是只有Worker Leader能够进行的。所以一个Worker Group中的某个Worker的管理者Herder接收到一个修改的请求时,会将该请求路由(通过Restful请求)到Worker Leader。
在使用Kafka Connect时,如果是将Kafka Connect内嵌到业务系统中时,我们是可以通过Herder 对象来对Kafka Connect中的组件进行管理操作的。
但是很多情况下,并不是将Kafka Connect内嵌到我们的系统中的,而是使用它的CLI独立的启动一个或者多个进程的。这种情况下,如何来管理Kafka Connect的组件呢?
4.2 Restful
为了方便管理,另外也专门提供了一种基于Restful的方式来管理connector、task。不论是Standalone还是Distributed模式都支持Restful方式管理。
Restful管理方式,会在Kafka-Connect进程内部内嵌一个基于Jetty的Web Server。默认的端口是8083。
下面会列出当前Kafka-Connector 版本0.10.1.0支持的Restful请求:
- GET /connectors – 获取当前活动的 connectors列表
- POST /connectors – 创建一个新的Connector。请求体是一个JSON对象,包括connector的名称,和配置。
|
{ name:”conn-2”, config:{ // connector的配置项。 } } |
- GET /connectors/{name} – 获取指定的connector的信息。
- GET /connectors/{name}/config - 获取指定的connector的配置项。
- PUT /connectors/{name}/config – 修改指定的connector的配置项。
- GET /connectors/{name}/status – 获取指定的connector的当前状态。包括: 1)connector的status, 2)分配在哪个worker上, 3)如果失败的话,错误信息,4)与之关联的所有任务的状态。
- GET /connectors/{name}/tasks – 获取指定connector的任务列表。
- GET /connectors/{name}/tasks/{taskid}/status – 获取指定的connector的指定task的状态信息。包括:1)该任务的status,2)该任务分配在哪个worker上,3)如果有失败,错误信息。
- PUT /connectors/{name}/pause – 暂停某个Connector。暂停某个connector时,与之关联的task都会暂停。
- PUT /connectors/{name}/resume – 继续某个Connector。如果这个connector根本就没有暂停,那就什么也不用做。
- POST /connectors/{name}/restart – 重启一个Connector。通常在一Connector失败时。
- POST /connectors/{name}/tasks/{taskId}/restart – 重启一个task。
- DELETE /connectors/{name} –删除一个Connector。删除Connector时,会停止它关联的task,并删除相关的配置信息。
Kafka Connect 也为获取Connector Plugin的信息提供了 REST API :
- GET /connector-plugins- 获取在改Kafka-Connect集群中安装的Connector Plugin列表。需要注意的是,该API只能获取到正在Worker中正常运行状态的connector。某些connector是看不到的,特别是在进行升级时,例如add一个connector jar包。
- PUT/connector-plugins/{connector-type}/config/validate 验证connector的配置。
4.3 通用Connector升级
目前已提供了很多通用的Connector插件。
地址:https://www.confluent.io/product/connectors/
在使用这些插件时,如果需要升级connector,需要按照下面步骤进行:
1) 下载新版的connector
2) 停止所有的Kafka connect workers。
3)根据connector plugin 的安装说明来安装。
4)启动workers
5)如果采用分布式模式,启动connector。
5、Configuration
5.1 Worker
Worker 可以在Standalone模式运行,也可以在Distributed模式下运行,两种情况下有不同的配置,所以这里需要对他们加以区分:
5.1.1 Common Configuration
·bootstrap.server
因为Worker必然要有至少一个KafkaProducer实例(分布式时有两个),所以需要至少配置一个Kafka broker的host:port对。如果是Broker集群模式,也没有必要将所有的broker配置上。格式是:host1:port1,host2:port2,host3:port3...
·key.converter, value.converter
配置record中的key、value 所采用的converter类名。比较流行的Converter有:JSON、Avro。
·internal.key.converter, internal.value.converter
配置connect-offset topic (也即 offset storage’s topic)中的record的key、value所采用的converter类名。比较流行的Converter有JSON、Avro。
·rest.host.name, rest.port
Rest Server的要绑定的IP和port。其中port模式是8083。
·session.time.out
每一个worker会周期性的发送一个heartbeat到Broker,以告诉Broker自己还活着。如果超过session.timeout.ms 还没有发送heartbeat给Broker,Worker就会断开相关的连接。那么Broker就不能收到heartbeat,就会导致Broker 认为该Worker已经挂掉了。然后Broker就会触发Rebalance,来重新分配connector、task。这个值必须配置的 group.min.session.timeout.ms 与 group.max.session.timeout.ms之间。
默认值:10000,即10s。
·heartbeat.interval.ms
心跳间隔。心跳用于keep-alive Worker与Broker之间的连接。这个值必须低于session.timeout.ms。建议设置的值不要高于session.timeout.ms的1/3。
默认值:3000,即3s 。
. rebalance.timeout.ms
一旦一个rebalance开始了,一个Worker加入到group的时间。在此期间,运行在该Worker上的所有的任务需要flush掉那些还没有处理完毕的数据,并且要提交offset。
如果超过了这个时间,offset commit就会失败。
默认值 60000,即60s 。
·connection.max.idle.ms
连接最大空闲时间。模式值:540000,即9 min。
·client.id
指定一个认为可读的worker id,只是用于跟踪。
5.1.2 Standalone Worker Configuration
·offset.storage.file.filename
存储connector offset 的文件。
5.1.3 Distributed Worker Configuration
·group.id
指定worker属于哪个worker group。
·config.storage.topic, offset.storage.topic, status.storage.topic
在一个Worker Group内, Workers 能够发现彼此并共享connector、Task相关的config、offset、status信息。这些共享信息分别存储在一个topic内。这3个配置项就是用来指定topic名称的。在同一个Worker Group下的每一个worker的配置文件中,这三项必须以一致的。
创建这三个topic时的注意事项:
1)Offset存储的topic 需要有很多个partation并且每一个partition至少三个replicas。
2)config存储的topic 只创建一个partition,并且至少3个replicas。
3)status存储的topic需要创建多个partition并且每一个partition至少3个replicas。
要了解更多信息,可以参考前面Storage部分。
如果想要了解更多关于Kafka-Connect的知识,可以参考:http://docs.confluent.io/current
Kafka: Connect的更多相关文章
- Streaming data from Oracle using Oracle GoldenGate and Kafka Connect
This is a guest blog from Robin Moffatt. Robin Moffatt is Head of R&D (Europe) at Rittman Mead, ...
- Build an ETL Pipeline With Kafka Connect via JDBC Connectors
This article is an in-depth tutorial for using Kafka to move data from PostgreSQL to Hadoop HDFS via ...
- Kafka connect快速构建数据ETL通道
摘要: 作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 业余时间调研了一下Kafka connect的配置和使用,记录一些自己的理解和心得,欢迎 ...
- 使用kafka connect,将数据批量写到hdfs完整过程
版权声明:本文为博主原创文章,未经博主允许不得转载 本文是基于hadoop 2.7.1,以及kafka 0.11.0.0.kafka-connect是以单节点模式运行,即standalone. 首先, ...
- 基于Kafka Connect框架DataPipeline可以更好地解决哪些企业数据集成难题?
DataPipeline已经完成了很多优化和提升工作,可以很好地解决当前企业数据集成面临的很多核心难题. 1. 任务的独立性与全局性. 从Kafka设计之初,就遵从从源端到目的的解耦性.下游可以有很多 ...
- 基于Kafka Connect框架DataPipeline在实时数据集成上做了哪些提升?
在不断满足当前企业客户数据集成需求的同时,DataPipeline也基于Kafka Connect 框架做了很多非常重要的提升. 1. 系统架构层面. DataPipeline引入DataPipeli ...
- 以Kafka Connect作为实时数据集成平台的基础架构有什么优势?
Kafka Connect是一种用于在Kafka和其他系统之间可扩展的.可靠的流式传输数据的工具,可以更快捷和简单地将大量数据集合移入和移出Kafka的连接器.Kafka Connect为DataPi ...
- 打造实时数据集成平台——DataPipeline基于Kafka Connect的应用实践
导读:传统ETL方案让企业难以承受数据集成之重,基于Kafka Connect构建的新型实时数据集成平台被寄予厚望. 在4月21日的Kafka Beijing Meetup第四场活动上,DataPip ...
- kafka connect 使用说明
KAFKA CONNECT 使用说明 一.概述 kafka connect 是一个可扩展的.可靠的在kafka和其他系统之间流传输的数据工具.简而言之就是他可以通过Connector(连接器)简单.快 ...
- kafka connect rest api
1. 获取 Connect Worker 信息curl -s http://127.0.0.1:8083/ | jq lenmom@M1701:~/workspace/software/kafka_2 ...
随机推荐
- java 下对字符串的格式化
1.对整数进行格式化:%[index$][标识][最小宽度]转换方式 我们可以看到,格式化字符串由4部分组成,其中%[index$]的含义我们上面已经讲过,[最小宽度]的含义也很好理解 ...
- [转载]linux下如何查看系统和内核版本
原文地址:linux下如何查看系统和内核版本作者:vleage 1. 查看内核版本命令: 1) [root@q1test01 ~]# cat /proc/version Linux version 2 ...
- [转]解决Eclipse中编辑xml文件的智能提示问题
转自:http://hi.baidu.com/cghroom/item/48fd2d0dc1fc23c675cd3c3e 摘要: Eclipse for Android xml 文件代码自动提示功能 ...
- 虚拟机virtualbox中挂载新硬盘
在virtualbox中装好Ubuntu后,发现硬盘空间太小,怎样才能增加硬盘容量?那就是再建一个硬盘: 1. 添加新硬盘 设置 -> Storage -> SATA控制器->右击, ...
- Redis 学习之路 (009) - Redis-cli命令最新总结
资料来源: http://redisdoc.com/ http://redis.io/commands 连接操作相关的命令 默认直接连接 远程连接-h 192.168.1.20 -p 6379 pi ...
- HDU 1850 Being a Good Boy in Spring Festival (Nim博弈)
Being a Good Boy in Spring Festival Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32 ...
- NPM Node.js 包管理
1.NPM 简介 1.1 NPM Node.js® 是一个基于 Chrome V8 引擎的 JavaScript 运行环境,可方便地构建快速,可扩展的网络应用程序的平台.Node.js 使用事件驱动, ...
- solrj索引操作
添加索引 Solr添加文档至索引: http://www.cnblogs.com/dennisit/p/3621717.html 删除索引: 每天索引记录有一个唯一标识,索引的删除通过唯一标识操作,如 ...
- easyUI设置textbox的值
我们知道<input type="text" class="easyui-validatebox" id="txtrName" nam ...
- js中为什么你不敢用 “==”
文章引用:http://0313.name/archives/480 前言 类型转换在各个语言中都存在,而在 JavaScript 中由于缺乏对其的了解而不慎在使用中经常造成bug被人诟病.为了避免某 ...