使用 XPath 选择器
在前面的内容中,我们掌握了一些 CSS 选择器和它们的使用方法,以及 rvest 包中
用于提取网页内容的函数。
一般来说,CSS 选择器足够满足绝大部分
的 HTML 节点匹配的需要。但是,当需要根据某些
特殊条件选择节点时,需要用更强大的技术。
图 14-5 所示的网页比 data/products.html 复杂
一点:
这个网页作为一个独立的 HTML 文件被存储
在 data/new-products.html。全部的源代码很长,这
里只展示 <body> 部分。请浏览一遍源代码,以便
对它的结构有个印象:
<body>
<h1>New Products</h1>
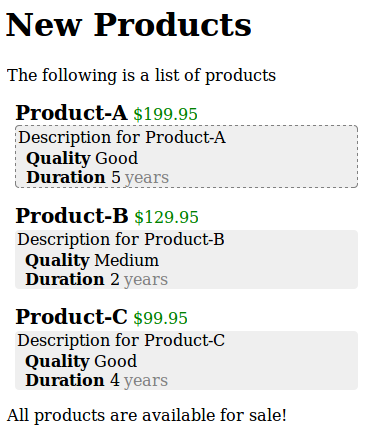
图 14-5
<p>The following is a list of products</p>
<div id = "list" class = "product-list">
<ul>
<li>
<span class = "name">Product-A</span>
<span class = "price">$199.95</span>
<div class = "info bordered">
<p>Description for Product-A</p>
<ul>
<li><span class = "info-key">Quality</span> <span class =
"infovalue">Good</span></li>
<li><span class = "info-key">Duration</span> <span class =
"infovalue">5 </span><span class = "unit">years</span></li>
</ul>
</div>
</li>
<li class = "selected">
<span class = "name">Product-B</span>
<span class = "price">$129.95</span>
<div class = "info">
<p>Description for Product-B</p>
<ul>
<li><span class = "info-key">Quality</span> <span class = "infovalue">
Medium</span></li>
<li><span class = "info-key">Duration</span> <span class = "infovalue">
2</span><span class = "unit">years</span></li>
</ul>
</div>
</li>
<li>
<span class = "name">Product-C</span>
<span class = "price">$99.95</span>
<div class = "info">
<p>Description for Product-C</p>
<ul>
<li><span class = "info-key">Quality</span> <span class = "infovalue">
Good</span></li>
<li><span class = "info-key">Duration</span> <span class = "infovalue">
4</span><span class = "unit">years</span></li>
</ul>
</div>
</li>
</ul>
</div>
<p>All products are available for sale!</p>
</body>
网页的源代码包含了一个样式表和产品详细信息的列表。每个产品都有其描述和很多
性质。接下来,就像前面的例子一样,我们载入网页:
page <- read_ _html("data/new-products.html")
HTML 的代码结构简单明晰。在深入挖掘 XPath 之前,我们需要了解一下 XML。编写
良好且组织规范的 HTML 文档可以被看作 XML(eXtensive Markup Language)文档的一个
特例。与 HTML 不同,XML 允许任意的标签和属性。下面是一个简单的 XML 文档示例:
<?xml version = "1.0"?>
<root>
<product id = "1">
<name>Product-A<name>
<price>$199.95</price>
</product>
<product id = "2">
<name>Product-B</name>
<price>$129.95</price>
</product>
</root>
XPath 专门用于提取 XML 文档中的数据。在本节中,我们比较 XPath 表达式和 CSS 选
择器,查看二者在提取网页数据过程中的作用。
函数 html_node( ) 和 html_nodes( ) 支持 XPath 表达式,并通过参数 xpath= 实
现。表 14-2 展示了 CSS 选择器和等价的 XPath 表达式之间的一些重要对比。
表 14-2
CSS XPath Math
li > * //li/* All children of <li>
li[attr] //li[@attr] All <li> with attr attribute
li[attr=value] //li[@attr = 'value'] <li attr = "value">
li#item //li[@id = 'item'] <li id = "item">
li.info //li[contains(@class,'info')] <li class = "info">
续表
CSS XPath Math
li:first-child //li[1] First <li>
li:last-child //li[last()] Last <li>
li:nth-child(n) //li[n] n th <li>
(N/A) //p[a] All <p> with a child <a>
(N/A) //p[position() <= 5] The first five <p> nodes
(N/A) //p[last()-2] The last third last <p>
(N/A) //li[value>0.5] All <li> with child <value>whose value > 0.5
CSS 选择器会匹配所有子层级的节点。在 XPath 表达式中,标签 // 和 / 匹配不同的
节点。更具体地说,// 标签引用所有子层级的 <tag> 节点,而 / 标签只引用第 1 个子层级
的 <tag> 节点。
我们通过下面这些例子展示它们的用法:
选择所有 <p> 节点:
page %>% html_ _nodes(xpath = "//p")
## {xml_nodeset (5)}
## [1] <p>The following is a list of products</p>
## [2] <p>Description for Product-A</p>
## [3] <p>Description for Product-B</p>
## [4] <p>Description for Product-C</p>
## [5] <p>All products are available for sale!</p>
选择所有具有 class 属性的 <li> 节点:
page %>% html_ _nodes(xpath = "//li[@class]")
## {xml_nodeset (1)}
## [1] <li class = "selected">\n <span class = "name">Pro ...
选择 <div id = "list"><ul> 节点中所有 <li> 子节点:
page %>% html_ _nodes(xpath = "//div[@id = 'list']/ul/li")
## {xml_nodeset (3)}
## [1] <li>\n <span class = "name">Product-A</span>\n ...
## [2] <li class = "selected">\n <span class = "name">Pro ...
## [3] <li>\n <span class = "name">Product-C</span>\n ...
选择所有嵌套于<div id = "list"> 中 <li> 标签下的 <span class = "name"> 子
节点:
page %>% html_ _nodes(xpath = "//div[@id = 'list']//li/span[@class = 'name']")
## {xml_nodeset (3)}
## [1] <span class = "name">Product-A</span>
## [2] <span class = "name">Product-B</span>
## [3] <span class = "name">Product-C</span>
选择所有嵌套于 <li class = "selected"> 中的 <span class = "name"> 子节点:
page %>%
html_ _nodes(xpath = "//li[@class = 'selected']/span[@class = 'name']")
## {xml_nodeset (1)}
## [1] <span class = "name">Product-B</span>
上面这些例子也可以使用等效的 CSS 选择器来实现。然而,下面这些例子就不能
用 CSS 选择器实现了:
选择所有包含 <p> 子节点的 <div> 节点:
page %>% html_ _nodes(xpath = "//div[p]")
## {xml_nodeset (3)}
## [1] <div class = "info bordered">\n <p>Description ...
## [2] <div class = "info">\n <p>Description for Prod ...
## [3] <div class = "info">\n <p>Description for Prod ...
选择所有的 <span class = "info-value">Good</span>:
page %>%
html_ _nodes(xpath = "//span[@class = 'info-value' and text() = 'Good']")
## {xml_nodeset (2)}
## [1] <span class = "info-value">Good</span>
## [2] <span class = "info-value">Good</span>
选择所有优质产品的名称:
page %>%
html_ _nodes(xpath = "//li[div/ul/li[1]/span[@class = 'info-value' and
text() = 'Good']]/span[@class = 'name']")
## {xml_nodeset (2)}
## [1] <span class = "name">Product-A</span>
## [2] <span class = "name">Product-C</span>
选择所有持续时间超过 3 年的产品名称:
page %>%
html_ _nodes(xpath = "//li[div/ul/li[2]/span[@class = 'info-value' and
text()>3]]/span[@class = 'name']")
## {xml_nodeset (2)}
## [1] <span class = "name">Product-A</span>
## [2] <span class = "name">Product-C</span>
XPath 是非常灵活的,在匹配网页节点方面是一个强大的工具。想要了解更多内容,
请访问 http://www.w3schools.com/xsl/xpath_syntax.aspac。
使用 XPath 选择器的更多相关文章
- Python爬虫与数据分析之爬虫技能:urlib库、xpath选择器、正则表达式
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- 使用scrapy中xpath选择器的一个坑点
情景如下: 一个网页下有一个ul,这个ur下有125个li标签,每个li标签下有我们想要的 url 字段(每个 url 是唯一的)和 price 字段,我们现在要访问每个li下的url并在生成的请求中 ...
- 常用xpath选择器和css选择器总结
xpath选择器 表达式 说明 article 选取所有article元素的所有子节点 /article 选取根元素article article/a 选取所有属于article的子元素的a元素 // ...
- xpath选择器简介及如何使用
xpath选择器简介及如何使用 一.总结 一句话总结:XPath 的全称是 XML Path Language,即 XML 路径语言,它是一种在结构化文档(比如 XML 和 HTML 文档)中定位信息 ...
- 在Scrapy中如何利用Xpath选择器从HTML中提取目标信息(两种方式)
前一阵子我们介绍了如何启动Scrapy项目以及关于Scrapy爬虫的一些小技巧介绍,没来得及上车的小伙伴可以戳这些文章: 手把手教你如何新建scrapy爬虫框架的第一个项目(上) 手把手教你如何新建s ...
- Selenium(九):Xpath选择器
1. Xpath选择器 1.1 Xpath语法简介 前面我们学习了CSS选择元素. 大家可以发现非常灵活.强大. 还有一种灵活.强大的选择元素的方式,就是使用Xpath表达式. XPath (XML ...
- 用Xpath选择器解析网页(lxml)
在<爬虫基础以及一个简单的实例>一文中,我们使用了正则表达式来解析爬取的网页.但是正则表达式有些繁琐,使用起来不是那么方便.这次我们试一下用Xpath选择器来解析网页. 首先,什么是XPa ...
- xpath选择器使用
简单说,xpath就是选择XML文件中节点的方法. 所谓节点(node),就是XML文件的最小构成单位,一共分成7种. - element(元素节点)- attribute(属性节点)- text ( ...
- 初始scrapy,简单项目创建和CSS选择器,xpath选择器(1)
一 安装 #Linux: pip3 install scrapy #Windows: a. pip3 install wheel b. 下载twisted http://www.lfd.uci.edu ...
随机推荐
- 打造高可靠与高性能的React同构解决方案
前言 随着React的兴起, 结合Node直出的性能优势和React的组件化,React同构已然成为趋势之一.享受技术福利的同时,直面技术挑战,在复杂场景下,挑战10倍以上极致的性能优化. 什么是同构 ...
- JavaScript位运算符 2
按位运算符是把操作数看作一系列单独的位,而不是一个数字值.所以在这之前,不得不提到什么是“位”: 数值或字符在内存内都是被存储为0和 1的序列,每个0和1被称之为1个位,比如说10进制数据2在计算机内 ...
- JavaScript位运算符
位运算符是在数字底层(即表示数字的 32 个数位)进行操作的. 重温整数 ECMAScript 整数有两种类型,即有符号整数(允许用正数和负数)和无符号整数(只允许用正数).在 ECMAScript ...
- 通过Java 线程堆栈进行性能瓶颈分析
改善性能意味着用更少的资源做更多的事情.为了利用并发来提高系统性能,我们需要更有效的利用现有的处理器资源,这意味着我们期望使 CPU 尽可能出于忙碌状态(当然,并不是让 CPU 周期出于应付无用计算, ...
- MySQL Crash Course #20# Chapter 28. Managing Security
限制用户的操作权限并不是怕有人恶意搞破坏,而是为了减少失误操作的可能性. 详细文档:https://dev.mysql.com/doc/refman/8.0/en/user-account-manag ...
- Docker与虚拟机技术
最近docker技术在网络上非常火爆,各种技术下载中心总能看到一个以docker镜像方式下载的下载选项,而当你下载下来运行发现,这就是一个虚拟机嘛.究竟是不是呢?一起来看看. 我们先来看看传统意义上的 ...
- 10:Python2与Python3比较
1.print 函数 1. print语句没有了,取而代之的是print()函数. Python 2.6与Python 2.7部分地支持这种形式的print语法. 2.Unicode 1. 在pyt ...
- 20145127《java程序设计》第二次实验
一.实验内容及其步骤 1.要想对某个程序进行单元测试,我们先是在eclipse中建立了一个新的项目,项目的名字是TDDDmeo.并在这个新的项目里右键单击创建一个source floder.并将flo ...
- 20145205武钰《网络对抗》web安全基础实践
实验后问题回答 (1)SQL注入攻击原理,如何防御 攻击原理:SQL注入攻击就是通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意SQL命令的目的 防御手 ...
- noip2007部分题
1.统计数字 题目描述 Description 某次科研调查时得到了n个自然数,每个数均不超过1500000000(1.5*109).已知不相同的数不超过10000 个,现在需要统计这些自然数各自出现 ...