Tensorflow线程和队列
读取数据
小数量数据读取
这仅用于可以完全加载到存储器中的小的数据集有两种方法:
- 存储在常数中。
- 存储在变量中,初始化后,永远不要改变它的值。
使用常数更简单一些,但是会使用更多的内存,因为常数会内联的存储在数据流图数据结构中,这个结构体可能会被复制几次。
training_data = ...
training_labels = ...
with tf.Session():
input_data = tf.constant(training_data)
input_labels = tf.constant(training_labels)
要改为使用变量的方式,您就需要在数据流图建立后初始化这个变量。
training_data = ...
training_labels = ...
with tf.Session() as sess:
data_initializer = tf.placeholder(dtype=training_data.dtype,
shape=training_data.shape)
label_initializer = tf.placeholder(dtype=training_labels.dtype,
shape=training_labels.shape)
input_data = tf.Variable(data_initalizer, trainable=False, collections=[])
input_labels = tf.Variable(label_initalizer, trainable=False, collections=[])
...
sess.run(input_data.initializer,
feed_dict={data_initializer: training_data})
sess.run(input_labels.initializer,
feed_dict={label_initializer: training_lables})
设定trainable=False可以防止该变量被数据流图的GraphKeys.TRAINABLE_VARIABLES收集,这样我们就不会在训练的时候尝试更新它的值;设定collections=[]可以防止GraphKeys.VARIABLES收集后做为保存和恢复的中断点。设定这些标志,是为了减少额外的开销
文件读取
先看下文件读取以及读取数据处理成张量结果的过程:
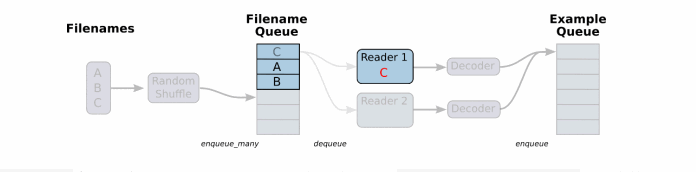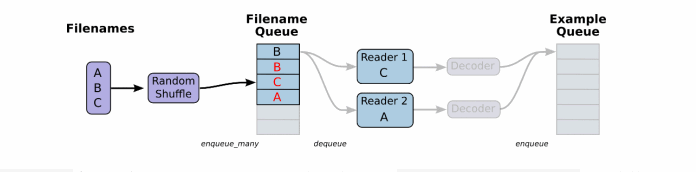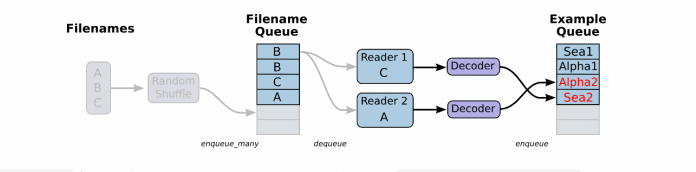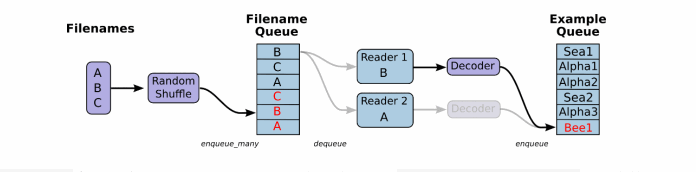
一般数据文件格式有文本、excel和图片数据。那么TensorFlow都有对应的解析函数,除了这几种。还有TensorFlow指定的文件格式。
标准TensorFlow格式
TensorFlow还提供了一种内置文件格式TFRecord,二进制数据和训练类别标签数据存储在同一文件。模型训练前图像等文本信息转换为TFRecord格式。TFRecord文件是protobuf格式。数据不压缩,可快速加载到内存。TFRecords文件包含 tf.train.Example protobuf,需要将Example填充到协议缓冲区,将协议缓冲区序列化为字符串,然后使用该文件将该字符串写入TFRecords文件。在图像操作我们会介绍整个过程以及详细参数。
数据读取实现
文件队列生成函数
- tf.train.string_input_producer(string_tensor, num_epochs=None, shuffle=True, seed=None, capacity=32, name=None)
产生指定文件张量
文件阅读器类
- class tf.TextLineReader
阅读文本文件逗号分隔值(CSV)格式
- tf.FixedLengthRecordReader
要读取每个记录是固定数量字节的二进制文件
- tf.TFRecordReader
读取TfRecords文件
解码
由于从文件中读取的是字符串,需要函数去解析这些字符串到张量
tf.decode_csv(records,record_defaults,field_delim = None,name = None)将CSV转换为张量,与tf.TextLineReader搭配使用
tf.decode_raw(bytes,out_type,little_endian = None,name = None) 将字节转换为一个数字向量表示,字节为一字符串类型的张量,与函数tf.FixedLengthRecordReader搭配使用
生成文件队列
将文件名列表交给tf.train.string_input_producer函数。string_input_producer来生成一个先入先出的队列,文件阅读器会需要它们来取数据。string_input_producer提供的可配置参数来设置文件名乱序和最大的训练迭代数,QueueRunner会为每次迭代(epoch)将所有的文件名加入文件名队列中,如果shuffle=True的话,会对文件名进行乱序处理。一过程是比较均匀的,因此它可以产生均衡的文件名队列。
这个QueueRunner工作线程是独立于文件阅读器的线程,因此乱序和将文件名推入到文件名队列这些过程不会阻塞文件阅读器运行。根据你的文件格式,选择对应的文件阅读器,然后将文件名队列提供给阅读器的 read 方法。阅读器的read方法会输出一个键来表征输入的文件和其中纪录(对于调试非常有用),同时得到一个字符串标量,这个字符串标量可以被一个或多个解析器,或者转换操作将其解码为张量并且构造成为样本。
# 读取CSV格式文件
# 1、构建文件队列 # 2、构建读取器,读取内容 # 3、解码内容 # 4、现读取一个内容,如果有需要,就批处理内容
import tensorflow as tf
import os
def readcsv_decode(filelist):
"""
读取并解析文件内容
:param filelist: 文件列表
:return: None
""" # 把文件目录和文件名合并
flist = [os.path.join("./csvdata/",file) for file in filelist] # 构建文件队列
file_queue = tf.train.string_input_producer(flist,shuffle=False) # 构建阅读器,读取文件内容
reader = tf.TextLineReader() key,value = reader.read(file_queue) record_defaults = [["null"],["null"]] # [[0],[0],[0],[0]] # 解码内容,按行解析,返回的是每行的列数据
example,label = tf.decode_csv(value,record_defaults=record_defaults) # 通过tf.train.batch来批处理数据
example_batch,label_batch = tf.train.batch([example,label],batch_size=9,num_threads=1,capacity=9) with tf.Session() as sess: # 线程协调员
coord = tf.train.Coordinator() # 启动工作线程
threads = tf.train.start_queue_runners(sess,coord=coord) # 这种方法不可取
# for i in range(9):
# print(sess.run([example,label])) # 打印批处理的数据
print(sess.run([example_batch,label_batch])) coord.request_stop() coord.join(threads) return None if __name__=="__main__":
filename_list = os.listdir("./csvdata")
readcsv_decode(filename_list)
每次read的执行都会从文件中读取一行内容,注意,(这与后面的图片和TfRecords读取不一样),decode_csv操作会解析这一行内容并将其转为张量列表。如果输入的参数有缺失,record_default参数可以根据张量的类型来设置默认值。在调用run或者eval去执行read之前,你必须调用tf.train.start_queue_runners来将文件名填充到队列。否则read操作会被阻塞到文件名队列中有值为止。
Tensorflow线程和队列的更多相关文章
- TensorFlow笔记-线程和队列
线程和队列 在使用TensorFlow进行异步计算时,队列是一种强大的机制. 为了感受一下队列,让我们来看一个简单的例子.我们先创建一个“先入先出”的队列(FIFOQueue),并将其内部所有元素初始 ...
- TensorFlowIO操作(一)----线程和队列
线程和队列 在使用TensorFlow进行异步计算时,队列是一种强大的机制. 为了感受一下队列,让我们来看一个简单的例子.我们先创建一个“先入先出”的队列(FIFOQueue),并将其内部所有元素初始 ...
- Linux多线程系列-2-条件变量的使用(线程安全队列的实现)
多线程情况下,往往需要使用互斥变量来实现线程间的同步,实现资源正确共享. linux下使用如下变量和函数 //条件变量 pthread_cond_t int pthread_cond_init (pt ...
- 使用Condition Variables 实现一个线程安全队列
使用Condition Variables实现一个线程安全队列 测试机: i7-4800MQ .7GHz, logical core, physical core, 8G memory, 256GB ...
- 线程池 队列 synchronized
线程池 BlockingQueue synchronized volatile 本章从线程池到阻塞队列BlockingQueue.从BlockingQueue到synchronized 和 volat ...
- Java线程安全队列BlockingQueue
线程安全队列BlockingQueue 用法跟普通队列没有区别,只是加入了多线程支持. 这里主要说说add和put,以及poll和take的区别: add和put都是用来忘队列里面塞东西的,而poll ...
- C++并发编程 条件变量 condition_variable,线程安全队列示例
1. 背景 c++11中提供了对线程与条件变量的更好支持,对于写多线程程序方便了很多. 再看c++并发编程,记一下学习笔记. 2. c++11 提供的相关api 3.1 wait wait用于无条件等 ...
- java多线程 --ConcurrentLinkedQueue 非阻塞 线程安全队列
ConcurrentLinkedQueue是一个基于链接节点的无界线程安全队列,它采用先进先出的规则对节点进行排序,当我们添加一个元素的时候,它会添加到队列的尾部:当我们获取一个元素时,它会返回队列头 ...
- c# 高效的线程安全队列ConcurrentQueue
c#高效的线程安全队列ConcurrentQueue<T>(上) c# 高效的线程安全队列ConcurrentQueue(下) Segment类 c#高效的线程安全队列Concurrent ...
随机推荐
- BZOJ3473: 字符串【后缀数组+思维】
Description 给定n个字符串,询问每个字符串有多少子串(不包括空串)是所有n个字符串中至少k个字符串的子串? Input 第一行两个整数n,k. 接下来n行每行一个字符串. Output 一 ...
- BZOJ3230: 相似子串【后缀数组】
Description Input 输入第1行,包含3个整数N,Q.Q代表询问组数. 第2行是字符串S. 接下来Q行,每行两个整数i和j.(1≤i≤j). Output 输出共Q行,每行一个数表示每组 ...
- Appium笔记(一) 丶Appium的自我介绍
一.我是谁,我的特点是什么 Appium是一款开源测试自动化框架,可用于原生.混合和移动Web应用程序.它使用WebDriver协议驱动iOS,Android和Windows应用程序.重要的是,App ...
- django所遇到问题简单总结
问题虽小,但却值得深思 一.改mysql密码 方法1: 用SET PASSWORD命令 首先登录MySQL. 格式:mysql> set password for 用户名@localhost = ...
- java泛型学习(2)
一:深入泛型使用.主要是父类和子类存在泛型的demo /** * 父类为泛型类 * @author 尚晓飞 * @date 2014-7-15 下午7:31:25 * * * 父类和子类的泛型. * ...
- Android已有的原生Camera框架中加入自己的API的实现方案。
版权声明:本文为CSDN博主(天才2012)原创文章.未经博主同意不得转载. https://blog.csdn.net/gzzaigcn/article/details/25707389 在 ...
- webpack externals
当我们想在项目中require一些其他的类库或者API,而又不想让这些类库的源码被构建到运行时文件中,这在实际开发中很有必要.此时我们就可以通过配置externals参数来解决这个问题: //webp ...
- C# Request.Params与Request.QueryString 的区别
1.Request.Params包含Request.QueryString,request.form.request.cookies和request.servervariables.这几种查找的时候会 ...
- java 网络编程UDP
获得主机名 和 ip 的操作 简单示例 发送 接收 发送:键盘录入获得数据 接收:接收端持续接收数据 配合多线程可以完成一个聊天的功能.
- 峰Spring4学习(4)spring自动装配
一.自动装配: Model类: People.java: package com.cy.entity; public class People { private int id; private St ...