RabbitMQ 高可用集群搭建
- 面向EDA(事件驱动架构)的方式来设计你的消息
- AMQP routing key的设计
- RabbitMQ cluster搭建
- Mirror queue policy设置
- 两个不错的RabbitMQ plugin 大型应用插件(Sharding、Rederation)
- Queue镜像失败手动同步
- 各集群配置同步方式(RabbitMQ export\import)
- 客户端连接方式(尽量采用AMQP组来动态链接)
- RabbitMQ 产线二次产品化封装(消息补偿、发送消息持久化、异常处理、监控页面、重复消息剔除)
1.面向EDA(事件驱动架构)的方式来设计你的消息
在通常情况下你在使用消息中间件的时候,都是未经设计的使用,你没有把应用架构和系统架构边界搞清楚。消息中间件只是一个纯粹的技术工具,当你引入的时候是站在应用架构的角度引入的。这是架构的角度,也是架构的上帝视角,这样你就不会用到最后发现越来越混乱,而且也无法结合软件模式、方法论、最佳实践来综合提升系统的架构能力。
EDA(Event Driven Architecture,EDA) 事件驱动架构,它是一种用来在SOA或者Micro service中进行的架构模式。它的好处有几个,柔性具有很高的伸缩性。
(具体参考本人的SOA架构文章:SOA架构设计经验分享—架构、职责、数据一致性)
既然要EDA就要规划好你当前的系统边界之内有多少业务实体,这些实体是围绕着领域模型而得来。所以这里不要很主观的就定义一些你认为的事件,这些事件要根据业务实体中的对象来设计。业务实体起码是有唯一Identity的。比如,订单、商品,围绕着这些实体展开,订单可能有几个状态是比较常用的,创建、支付、配送、取消。商品可能有价格、关键属性修改等等。这些实体的抽象和提炼取决于你当前的业务。
(有关这方面内容可以参考:《领域驱动设计》、《探索CQRS和事件源》)
这些是相对理论的指导思想,有了这些之后你可以落地你的Rabbitmq,这样你就不会跑偏了。比如,你的消息名称不会是看起来没结构和层次的,deliveryMssage(配送消息)。而是应该,order.delivery.ondeliveryEvented(订单.配送.配送完成事件)这样的结构。
当你的层次结构不满足业务需求的时候,你可能还需要进一步明确事件范围,order.viporder.delivery.ondeliveryEvented(订单.VIP订单.配送.配送完成事件)。

上图是一个事件驱动的基本场景,它最瞩目的几个特性就是这几个,首先是异步化的,可以大大提高系统的抗峰值能力。然后就是解耦,这不用说了,设计模式里的观察者模式没有人不知道它的好处。伸缩性,可以按需scaleout,比如rabbitmq的node可以很方便的加入。最终一致性解决了分布式系统的CAP定理的问题。
2.AMQP routing key的设计
AMQP协议中约定了routing key的设计和交互。为了实现订阅发布功能,我们需要某种方式能够订阅自己所感兴趣的事件。所以在AMQP中的Binding中,可以根据routing key来进行模式匹配。所以,这里可以结合amqp routingkey与领域事件,发出来的事件就相当于amqp中的routingkey,这样可以完美的结合起来。
你的事件肯定是随着业务发展逐渐增加的,而这个事件集合也没办法在一开始就定义清楚,所以这里有一个需要注意的就是,绑定的时候千万不要写死具体的routing key。比如,order.delivery.OnDeliveryEvented,这是订单配送,此时你Binding的时候routingkey就写成了”order.delivery.OnDeliveryEvented”。未来订单事件一扩展,就会很麻烦,不相关的事件都被订阅到,无法细化或者事件你无法获取到,因为routingkey改变了。所以在绑定的时候记住具体点绑定,也就是借助字符串的模式匹配绑定,比如,*.delivery.*,*.onDeliveryEvented”这样。将来越来越多的routingkey和event出来都不会影响你的绑定。你只需要根据自己的关心程度,绑定在事件的不同层级上即可。

上图中,orderBinding绑定了order事件,它订阅了顶级事件,也就是说未来任何类型的订单都可以被订阅到,比如,order.normalorder.delivery.onDeliveryEvent也可以被订阅到。而viporderBinding订阅了viporder事件,如果发送了一个order.normalorder.delivery.onDeliveryEvent就跟它没关系了。
3.RabbitMQ cluster搭建
搞清楚了应用架构的事情,我们开始着手搭建RabbitMQ cluster。rabbitmq这款AMQP产品是用erlang开发的,那么我们稍微介绍下erlang。
我第一次正式接触erlang就是从rabbitmq开始的,一开始并没有太多感觉到特别的地方,后来才明白越明白越发现挺喜欢这门语言的。喜欢的理由就是,它是天然的分布式语言。这句话说起来好像挺平常的,但是当你明白了.erlang.cookie机制之后才恍然大悟。瞬间顿悟了,为什么要用erlang来搞rabbitmq,而是它真的很适合信息交换之类的软件。erlang是爱立信公司开发的专门用来开发高性能信息交换机的,想想也会觉得那些软件的性能和稳定性要求是极高的。RabbitMQ的节点发现和互连真的很方便,这在erlang的虚拟机中就集成了,而且具有高度容错能力。反正我对它很有好感。
还有一点值得骄傲的是RabbitMQ是伟大的pivotal公司的,你应该知道pivotal公司是干什么的,如果你还不清楚建议你立刻google下。

一开始我并没有太关注他们的copyright,后来对pivotal公司越来越佩服之后突然看到原来RabbitMQ也是他们家的,突然信心倍增。这就是影响力和口碑,看看人家公司的spring、springboot、spring cloud,佩服的五体投地。(RabbtiMQ 官网:http://www.rabbitmq.com/)
3.1.安装erlang & RabbitMQ
要想安装RabbitMQ,首先需要安装和配置好它的宿主环境erlang。去erlang官网下载好erlang otp_src源码包,然后在本地执行源码安装。(erlang官网:http://www.erlang.org/)
由于我本机已经下载好了otp_src源码包,我是使用的otp_src_19.1版本。下载好之后解压缩,然后进入目录,执行./configure --prefix=/usr/erlang/,进行环境的检查和安装路径的选择。如果你提示“No curses library functions found”错误,是因为缺少curses库,yum install –y ncurses-devel。安装后在进行configure。
如果没有报错的话,就说明安装成功了。你还需要配置下环境变量:
export PATH=$PATH:/usr/erlang/bin
source /etc/profile
此时使用erl命令检查下erlang是否能正常工作了。
接下来安装RabbitMQ,去官网下载运行的包就行了。
同样要配置下环境变量,这样你的命令才能被系统查找到。然后运行rabbitmq实例。

这里有一个需要注意,记得配置下hosts,在127.0.0.1里加上本机的名称。erlang进程需要host来进行连接,所以它会检查你的hosts配置。还需要设置下防火墙,三个端口要打开。15672是管理界面用的,25672是集群之间使用的端口,4369是erlang进程epmd用来做node连接的。
我配置了两个节点,192.168.0.105、192.168.0.107,现在已经全部就绪。我们添加原始账号进入rabbitmq管理界面。
3.2.配置RabbitMQ cluster
先保证你的各个rabbitmq节点都是可以访问的,且打开rabbitmq_management plugin,这样可以当出现某个节点挂掉之后可以切换到其他管理界面查看情况或者管理。
打开管理界面插件:
rabbitmq-plugins enable rabbitmq_management
添加账号:
rabbitmqctl add_user admin admin
添加 权限tag
rabbitmqctl set_user_tags admin administrator


保证两个节点都是可以正常工作的。下面我们就将这两个节点连接起来形成高可用的cluster,这样我们就可以让我们的exchange、queue在这两个节点之间复制,形成高可用的queue。
cd 到你的home目录下,我是在root下,里面有一个隐藏的.erlang.cookie文件,这就是我在前面介绍erlang时候提到的,这个文件是erlang用来发现和互连的基础。我们需要做的很简单,将两个节点中的.erlang.cookie设置成一样的。这是erlang的约定,一样的cookie hash key他认为是合法和正确的连接。
.erlang.cookie默认是只读的,你需要修改下写入权限,然后复制粘贴下cookie 字符串即可。
chmod u+w .erlang.cookie
配置好了之后接下来配置hosts文件,erlang会使用hosts文件里的配置去发现节点。
vim /etc/hosts
192.168.0.107 rabbitmq_node2
192.168.0.105 rabbitmq_node1
保证同样的配置在所有的节点上都是相同的。验证你配置的正确不正确你只需要在你的机器上ping rabbitmq_node1,试下请求的ip是不是你配置的即可。按照DNS的请求原理,hosts是最高优先权,除非浏览器有缓存,你直接用ping就不会有问题的。
选择一个节点stop,然后连接到另外节点。
rabbitmqctl stop_app
rabbitmqctl join_cluster rabbit@rabbitmq_node2
Clustering node rabbit@rabbitmq_node1 with rabbit@rabbitmq_node2 ...
rabbitmqctl start_app
节点已经连接成功。

默认情况下节点占用的memory是总内存的40%,可以根据自己的用途仔细研究rabbitmq的配置项。为了提高性能,不需要两个节点都是disc的节点,所以我们需要启动一个节点为RAM模式。
rabbitmqctl change_cluster_node_type ram
改变rabbitmq_node1为内存节点模式。

4.Mirror queue policy设置
节点是准备好了,接下来我们需要设置exchange、queue 高可用策略,这样才能真的做到高可用。现在是物理上的机器或者说虚拟机节点是高可用的,但是里面的对象需要我们进行配置策略。
RabbitMQ支持很好的策略模式,需要管理员才能操作。
首先我们需要创建一个属于自己业务范围内的vhost,标示一个逻辑上的独立空间,所有的账号、策略、队列都是强制在某个虚拟机里的。我创建了一个common vhost。
开始添加policie。

最主要是Apply to ,可以作用在exchange或者queues上,当然也可以包含这两个。策略选择还是比较丰富的,最常用的是HAmode,还有MessageTTL(消息的过期时间)。这些策略按照几个维度分组了,有跟高可用相关的,有Federation(集群之间同步消息)相关的 ,有Queue相关的,还有Exchange相关的。可以根据的业务场景进行调整。

我们定义了策略的匹配模式.order.,这样可以避免将所有的exchange、queue都镜像了。

我们新建了一个ex.order.topic exchange,它的features中应用了exchange_queue_ha策略。(相同的策略是无法叠加使用的。)其他的exchange并没有应用这个策略,是因为我们的pattern限定了只匹配.order.的名称。

创建一个qu.order.crm queue,注意看它的node属性里有一个”Synchronised mirrors:rabbit@rabbitmq_node2“镜像复制。features里也应用了exchange_queue_ha策略。这个时候,队列其实在两个节点里都是有的,虽然我们创建的时候是在rabbit@rabbitmq_node1里的,但是它会复制到集群里的其他节点。在创建HAmode的时候可以提供HA params参数,来限定复制节点的个数,这通常用来提高性能和HA之间的平衡。
5.两个不错的RabbitMQ plugin 大型应用插件(Sharding、Rederation)
在rabbitmq-plugins中有两个plugin还是可以试着研究研究的。rabbitmq-plugins list。
rabbitmq-plugins list
Configured: E = explicitly enabled; e = implicitly enabled
| Status: * = running on rabbit@rabbitmq_node1
|/
[e*] amqp_client 3.6.5
[ ] cowboy 1.0.3
[ ] cowlib 1.0.1
[e*] mochiweb 2.13.1
[ ] rabbitmq_amqp1_0 3.6.5
[ ] rabbitmq_auth_backend_ldap 3.6.5
[ ] rabbitmq_auth_mechanism_ssl 3.6.5
[ ] rabbitmq_consistent_hash_exchange 3.6.5
[ ] rabbitmq_event_exchange 3.6.5
[ ] rabbitmq_federation 3.6.5
[ ] rabbitmq_federation_management 3.6.5
[ ] rabbitmq_jms_topic_exchange 3.6.5
[E*] rabbitmq_management 3.6.5
[e*] rabbitmq_management_agent 3.6.5
[ ] rabbitmq_management_visualiser 3.6.5
[ ] rabbitmq_mqtt 3.6.5
[ ] rabbitmq_recent_history_exchange 1.2.1
[ ] rabbitmq_sharding 0.1.0
[ ] rabbitmq_shovel 3.6.5
[ ] rabbitmq_shovel_management 3.6.5
[ ] rabbitmq_stomp 3.6.5
[ ] rabbitmq_top 3.6.5
[ ] rabbitmq_tracing 3.6.5
[ ] rabbitmq_trust_store 3.6.5
[e*] rabbitmq_web_dispatch 3.6.5
[ ] rabbitmq_web_stomp 3.6.5
[ ] rabbitmq_web_stomp_examples 3.6.5
[ ] sockjs 0.3.4
[e*] webmachine 1.10.3
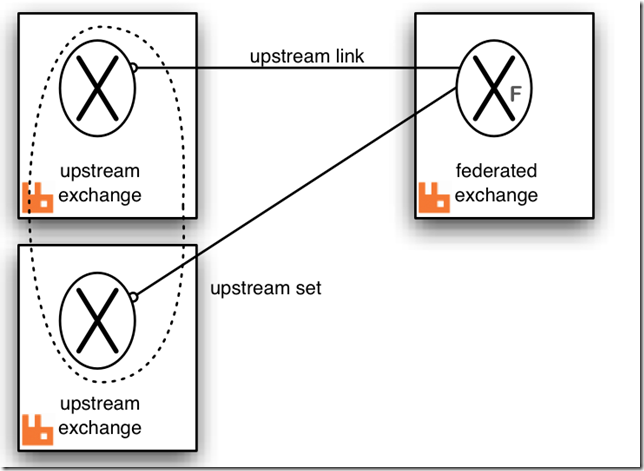
rabbitmq_sharding、rabbitmq_federation,rabbitmq_sharding的版本有点低了,github地址:https://github.com/rabbitmq/rabbitmq-sharding

Rederation 可以用来进行跨cluster或者node之间同步消息。http://www.rabbitmq.com/federated-exchanges.html
这个用来在不同的domain之间传递消息还是个不错的解决方案,跨机房或者跨网络区域,订阅别人的rabbitmq消息始终不太稳定,可以用这种方式来传递消息。
6.Queue镜像失败手动同步
有时候可能由于各种原因导致queue mirror失败,这个时候可以手动进行同步,而不是像其他分布式系统来重启节点或者重建数据。


这个还是比较方便的,有时候总有那么几个小问题需要你手动处理的。
7.各集群配置同步方式(RabbitMQ export\import)
各个环境的集群配置同步也是个日常运维的问题,还好RabbitMQ也提供了相关工具。



8.客户端连接方式(尽量采用AMQP组来动态链接)
由于RabbitMQ是AMQP协议的实现,所以在进行远程连接的时候尽量采用amqp协议的方式连接。
var amqpList = new List<AmqpTcpEndpoint>
{
new AmqpTcpEndpoint(new Uri("amqp://192.168.0.105:5672")),
new AmqpTcpEndpoint(new Uri("amqp://192.168.0.107:5672"))
};
关于集群的vip方案其实也是需要综合考虑的,如果是统一的地址会面临三个问题,DNS、LoadBalance、VIP,这三个点都有可能导致集群连接不上。现在越来越多的方案倾向于在客户端做负载和故障转移,这有很多好处,消除了中间节点带来的故障概率。如果这三个点加在一起出现的可用性指标肯定是比直接在客户端连接的低的多。
我们碰到最多就是VIP的问题,这类系统的VIP不同于数据库,数据库的master\slave大多都是要人工check后才切换,不会随便自动的切换主从库。而非数据库的VIP大多都是Keepalived自动检测切换,这带来一些列问题,包括连接重试、心跳保持。这只是VIP的出错场景之一。还有LoadBalance带来的问题,DNS出错的可能性也是很大。所以我倾向于使用客户端来做这些。

有几个地方很重要,第一个就是消息的Persistent持久化状态要带上,第二个就是ContentType,这个属性很实用,方便你查看消息的正文。

如果没设置,默认是null。
第三个就是AutomaticRecoveryEnabled,自动连接重试,这致命重要。当上面的VIP切换之后这个可以保命。第四个就是TopologyRecoveryEnabled,重新恢复Exchange、queue、binding。在出现网络断开之后,一旦恢复连接就会恢复这些设置以保证是最新的设置。
9.RabbitMQ 产线二次产品化封装(消息补偿、发送消息持久化、异常处理、监控页面、重复消息剔除)
不管rabbitmq保证的多么强壮,多么高可用,记住一定要有备用方案。
在之前我写了一篇文章,WebAPi的可视化输出模式(RabbitMQ、消息补偿相关)——所有webapi似乎都缺失的一个功能
说了就是消息的持久化和补偿。

一旦将发送和接受的消息持久化之后我们能做到事情就比较多了。消息补偿是可以做的,异常也不用担心。但是在发送消息的时候一定要注意,是先持久化消息在业务逻辑处理。为了应对特殊活动的监控,还可以开发一定的业务来监控消息的接受和处理的数量,然后自动补偿。
在开发补偿程序的时候有一个逻辑挺饶人的,当你对某一个消息进行补偿的时候会多出发送消息,而接受的消息肯定是比你发送的少。所以你在统计的时候记得DISTINCT下。
相关文章:
封装RabbitMQ.NET Library 的一点经验总结
WebAPi的可视化输出模式(RabbitMQ、消息补偿相关)——所有webapi似乎都缺失的一个功能
RabbitMQ 高可用集群搭建的更多相关文章
- RabbitMQ 高可用集群搭建及电商平台使用经验总结
面向EDA(事件驱动架构)的方式来设计你的消息 AMQP routing key的设计 RabbitMQ cluster搭建 Mirror queue policy设置 两个不错的RabbitMQ p ...
- RabbitMQ高级指南:从配置、使用到高可用集群搭建
本文大纲: 1. RabbitMQ简介 2. RabbitMQ安装与配置 3. C# 如何使用RabbitMQ 4. 几种Exchange模式 5. RPC 远程过程调用 6. RabbitMQ高可用 ...
- Linux源码安装RabbitMQ高可用集群
1.环境说明 linux版本:CentOS Linux release 7.9.2009 erlang版本:erlang-24.0 rabbitmq版本:rabbitmq_server-3.9.13 ...
- Redis总结(五)缓存雪崩和缓存穿透等问题 Web API系列(三)统一异常处理 C#总结(一)AutoResetEvent的使用介绍(用AutoResetEvent实现同步) C#总结(二)事件Event 介绍总结 C#总结(三)DataGridView增加全选列 Web API系列(二)接口安全和参数校验 RabbitMQ学习系列(六): RabbitMQ 高可用集群
Redis总结(五)缓存雪崩和缓存穿透等问题 前面讲过一些redis 缓存的使用和数据持久化.感兴趣的朋友可以看看之前的文章,http://www.cnblogs.com/zhangweizhon ...
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- Spark高可用集群搭建
Spark高可用集群搭建 node1 node2 node3 1.node1修改spark-env.sh,注释掉hadoop(就不用开启Hadoop集群了),添加如下语句 export ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- MongoDB高可用集群搭建(主从、分片、路由、安全验证)
目录 一.环境准备 1.部署图 2.模块介绍 3.服务器准备 二.环境变量 1.准备三台集群 2.安装解压 3.配置环境变量 三.集群搭建 1.新建配置目录 2.修改配置文件 3.分发其他节点 4.批 ...
随机推荐
- 介绍了如何取成员函数的地址以及调用该地址:C++
摘要:介绍了如何取成员函数的地址以及调用该地址. 关键字:C++成员函数 this指针 调用约定 一.成员函数指针的用法 在C++中,成员函数的指针是个比较特殊的东西.对普通的函数指针来说,可以视为一 ...
- JavaScript之图片操作2
在前一次,我们实现最简单的图片切换效果,这一次,依旧还是图片切换,具体效果如下: 通过点击下面的小图,上面的大图和标题随之切换.因此,我们需要三个容器分别放标题,大图和小图. <!--大图描述- ...
- zufe oj 引水工程( 巧妙地把在i建水设为e[0][i])
引水工程 时间限制: 3 Sec 内存限制: 128 MB提交: 11 解决: 6[提交][状态][讨论版] 题目描述 南水北调工程是优化水资源配置.促进区域协调发展的基础性工程,是新中国成立以来 ...
- Nginx的ip_hash指令
ip_hash 语法:ip_hash 默认值:none 使用环境:upstream 当对后端的多台动态应用服务器做负载均衡时,ip_hash指令能够将某个客户端IP的请求通过哈希算法定位到同一台后端服 ...
- ie下 iframe在页面中显示白色背景 如何去掉的问题
ie下:
- Dependency Injection in ASP.NET Web API 2 Using Unity
What is Dependency Injection? A dependency is any object that another object requires. For example, ...
- OPatch failed with error code 73(OracleHomeInventory gets null oracleHomeInfo)
OPatch failed with error code 73(OracleHomeInventory gets null oracleHomeInfo) 1.问题描述 [oracle@dou_ra ...
- ElasticSearch Document API
删除索引库 可以看到id为1的索引库不见了 这里要修改下配置文件 slave1,slave2也做同样的操作,在这里就不多赘述了. 这个时候记得要重启elasticseach才能生效,怎么重启这里就不多 ...
- 运维不得不知的 Linux 性能监控、测试、优化工具
Linux 平台上的性能工具有很多,眼花缭乱,长期的摸索和经验发现最好用的还是那些久经考验的.简单的小工具.系统性能专家 Brendan D. Gregg 在 LinuxCon NA 2014 大会上 ...
- php 学习笔记 设计和管理
代码管理 文件路径.数据库名.密码禁止 hard coded 避免重复代码在多个页面复制粘贴 Gang of Four eXtreme Programming 的主要原则是坚决主张测试是项目成功的关键 ...