hbase源码系列(十)HLog与日志恢复
HLog概述
hbase在写入数据之前会先写入MemStore,成功了再写入HLog,当MemStore的数据丢失的时候,还可以用HLog的数据来进行恢复,下面先看看HLog的图。
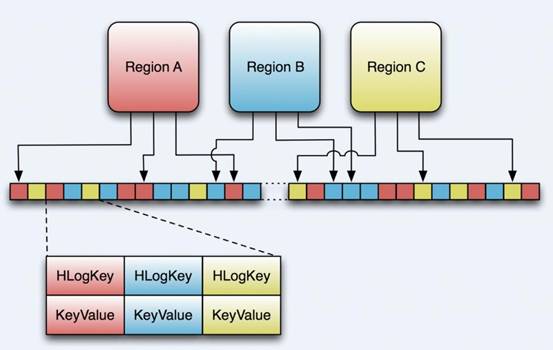
旧版的HLog是实际上是一个SequceneFile,0.96的已经使用Protobuf来进行序列化了。从Writer和Reader上来看HLog的都是Entry的,换句话说就是,它的每一条记录就是一个Entry。
class Entry implements Writable {
private WALEdit edit;
private HLogKey key;
}
所以上面那个图已经不准确了,HLogKey没变,但是Value缺不是KeyValue,而是WALEdit。
下面我们看看HLogKey的五要素,region、tableName、log的顺序、写入时间戳、集群id。
public HLogKey(final byte [] encodedRegionName, final TableName tablename,
long logSeqNum, final long now, List<UUID> clusterIds){
init(encodedRegionName, tablename, logSeqNum, now, clusterIds);
}
protected void init(final byte [] encodedRegionName, final TableName tablename,
long logSeqNum, final long now, List<UUID> clusterIds) {
this.logSeqNum = logSeqNum;
this.writeTime = now;
this.clusterIds = clusterIds;
this.encodedRegionName = encodedRegionName;
this.tablename = tablename;
}
下面看看WALEdit的属性, 这里只列出来一个重要的,它是内部持有的一群KeyValue。。
public class WALEdit implements Writable, HeapSize {
......private final ArrayList<KeyValue> kvs = new ArrayList<KeyValue>();
HLog的具体实现类是FSHLog,一个Region Server有两个FSHLog,一个负责RS上面所有的用户region的日志,一个负责RS上面的META表的region的日志。
对于日志来说,我们关心的是它如何保证一致性和准确性,在需要它的时候可以发挥救命作用。
HLog同步
对于meta region的HLog写入之后,它会立即同步到硬盘,非meta表的region,它会先把Entry添加到一个队列里面等待同步。
while(!this.isInterrupted() && !closeLogSyncer.get()) {
try {
if (unflushedEntries.get() <= syncedTillHere) {
synchronized (closeLogSyncer) {
closeLogSyncer.wait(this.optionalFlushInterval);
}
}// 同步已经添加的entry sync();
} catch (IOException e) {
LOG.error("Error while syncing, requesting close of hlog ", e);
requestLogRoll();
Threads.sleep(this.optionalFlushInterval);
}
}
它这里是有一个判断条件的,如果判断条件不成立就立即同步,等待this.optionalFlushInterval时间,默认的同步间隔是1000,它是通过参数hbase.regionserver.optionallogflushinterval设置。unflushedEntries是一个AtomicLong在写入entry的时候递增,syncedTillHere是一个volatile long,同步完成之后也是变大,因为可能被多个线程调用同步操作,所以它是volatile的,从条件上来看,如果没有日志需要同步就等待一秒再进行判断,如果有日志需要同步,也是立马就写入硬盘的,如果发生错误,就是调用requestLogRoll方法,进行回滚,这个回滚比较有意思,它是跑过去flush掉MemStore中的数据,把他们写入硬盘。
下面是回滚的方法。中间我忽略了几步,然后找到LogRoller中的这段代码。
byte [][] regionsToFlush = getWAL().rollWriter(rollLog.get());
if (regionsToFlush != null) {
for (byte [] r: regionsToFlush) scheduleFlush(r);
}
找出来需要flush的region,然后计划flush。
regions = findMemstoresWithEditsEqualOrOlderThan(this.outputfiles.firstKey(),
this.oldestUnflushedSeqNums);
static byte[][] findMemstoresWithEditsEqualOrOlderThan(
final long walSeqNum, final Map<byte[], Long> regionsToSeqNums) {
List<byte[]> regions = null;
for (Map.Entry<byte[], Long> e : regionsToSeqNums.entrySet()) {
//逐个对比,找出小于已输出为文件的最小的seq id的region
if (e.getValue().longValue() <= walSeqNum) {
if (regions == null) regions = new ArrayList<byte[]>();
regions.add(e.getKey());
}
}
return regions == null ? null : regions
.toArray(new byte[][] { HConstants.EMPTY_BYTE_ARRAY });
}
逐个对比,找出来未flush MemStore的比输出的文件的HLog流水号还小的region,当它准备flush MemStore之前会调用startCacheFlush方法来把region从oldestUnflushedSeqNums这个map当中去除,添加到已经flush的map当中。
从日志恢复
看过《HMaster启动过程》的童鞋都知道,如果之前有region失败的话,在启动之前会把之前的HLog进行split,把属于该region的为flush过的日志提取出来,然后生成一个新的HLog到recovered.edits目录下,中间的过程控制那块有点儿类似于snapshot的那种,在zk里面建立一个splitWAL节点,在这个节点下面建立任务,不一样的是,snapshot那块是自己处理自己的,这里是别人的闲事它也管,处理完了之后就更新这个任务的状态了,没有snapshot那么复杂的交互过程。
那啥时候会用到这个呢,在region打开的时候,我们从HRegionServer的openRegion方法一路跟踪,中间历经OpenMetaHandler,再到HRegion.openHRegion方法,终于在initializeRegionStores方法里面找到了那么一句话。
// 如果recovered.edits有日志的话,就恢复日志
maxSeqId = Math.max(maxSeqId, replayRecoveredEditsIfAny(
this.fs.getRegionDir(), maxSeqIdInStores, reporter, status));
高潮来了!!!
HLog.Reader reader = null;
try {
//创建reader读取hlog
reader = HLogFactory.createReader(fs, edits, conf);
long currentEditSeqId = -1;
long firstSeqIdInLog = -1;
long skippedEdits = 0;
long editsCount = 0;
long intervalEdits = 0;
HLog.Entry entry;
Store store = null;
boolean reported_once = false;
try {//逐个读取
while ((entry = reader.next()) != null) {
HLogKey key = entry.getKey();
WALEdit val = entry.getEdit();
//实例化firstSeqIdInLog
if (firstSeqIdInLog == -1) {
firstSeqIdInLog = key.getLogSeqNum();
}
boolean flush = false;
for (KeyValue kv: val.getKeyValues()) {
// 从WALEdits里面取出kvs
if (kv.matchingFamily(WALEdit.METAFAMILY) ||
!Bytes.equals(key.getEncodedRegionName(),
this.getRegionInfo().getEncodedNameAsBytes())) {//是meta表的kv就有compaction
CompactionDescriptor compaction = WALEdit.getCompaction(kv);
if (compaction != null) {
//完成compaction未完成的事情,校验输入输出文件,完成文件替换等操作
completeCompactionMarker(compaction);
}
skippedEdits++;
continue;
}
// 获得kv对应的store
if (store == null || !kv.matchingFamily(store.getFamily().getName())) {
store = this.stores.get(kv.getFamily());
}
if (store == null) {
// 应该不会发生,缺少它对应的列族
skippedEdits++;
continue;
}
// seq id小,呵呵,说明已经被处理过了这个日志
if (key.getLogSeqNum() <= maxSeqIdInStores.get(store.getFamily().getName())) {
skippedEdits++;
continue;
}
currentEditSeqId = key.getLogSeqNum(); // 这个就是我们要处理的日志,添加到MemStore里面就ok了
flush = restoreEdit(store, kv);
editsCount++;
}
//MemStore太大了,需要flush掉
if (flush) internalFlushcache(null, currentEditSeqId, status);
}
} catch (IOException ioe) {
// 就是把名字改了,然后在后面加上".时间戳",这个有毛意思? if (ioe.getCause() instanceof ParseException) {
Path p = HLogUtil.moveAsideBadEditsFile(fs, edits);
msg = "File corruption encountered! " +
"Continuing, but renaming " + edits + " as " + p;
} else {// 不知道是啥错误,抛错误吧,处理不了
throw ioe;
}
}
status.markComplete(msg);
return currentEditSeqId;
} finally {
status.cleanup();
if (reader != null) {
reader.close();
}
}
呵呵,读取recovered.edits下面的日志,符合条件的就加到MemStore里面去,完成之后,就把这些文件删掉。大家也看到了,这里通篇讲到一个logSeqNum,哪里都有它的身影,它实际上是FSHLog当中的一个递增的AtomicLong,每当往FSLog里面写入一条日志的时候,它都会加一,然后MemStore请求flush的时候,会调用FSLog的startCacheFlush方法,获取(logSeqNum+1)回来,然后写入到StoreFile的sequenceid字段,再次拿出来的时候,就遍历这个HStore下面的StoreFile的logSeqNum,取出来最大的跟它比较,小于它的都已经写过了,没必要再写了。
好了,HLog结束了,累死我了,要睡了。
hbase源码系列(十)HLog与日志恢复的更多相关文章
- 10 hbase源码系列(十)HLog与日志恢复
hbase源码系列(十)HLog与日志恢复 HLog概述 hbase在写入数据之前会先写入MemStore,成功了再写入HLog,当MemStore的数据丢失的时候,还可以用HLog的数据来进行恢 ...
- hbase源码系列(十二)Get、Scan在服务端是如何处理
hbase源码系列(十二)Get.Scan在服务端是如何处理? 继上一篇讲了Put和Delete之后,这一篇我们讲Get和Scan, 因为我发现这两个操作几乎是一样的过程,就像之前的Put和Del ...
- 11 hbase源码系列(十一)Put、Delete在服务端是如何处理
hbase源码系列(十一)Put.Delete在服务端是如何处理? 在讲完之后HFile和HLog之后,今天我想分享是Put在Region Server经历些了什么?相信前面看了<HTab ...
- 9 hbase源码系列(九)StoreFile存储格式
hbase源码系列(九)StoreFile存储格式 从这一章开始要讲Region Server这块的了,但是在讲Region Server这块之前得讲一下StoreFile,否则后面的不好讲下去 ...
- HBase源码系列之HFile
本文讨论0.98版本的hbase里v2版本.其实对于HFile能有一个大体的较深入理解是在我去查看"到底是不是一条记录不能垮block"的时候突然意识到的. 首先说一个对HFile ...
- hbase源码系列(十二)Get、Scan在服务端是如何处理?
继上一篇讲了Put和Delete之后,这一篇我们讲Get和Scan, 因为我发现这两个操作几乎是一样的过程,就像之前的Put和Delete一样,上一篇我本来只打算写Put的,结果发现Delete也可以 ...
- hbase源码系列(十五)终结篇&Scan续集-->如何查询出来下一个KeyValue
这是这个系列的最后一篇了,实在没精力写了,本来还想写一下hbck的,这个东西很常用,当hbase的Meta表出现错误的时候,它能够帮助我们进行修复,无奈看到3000多行的代码时,退却了,原谅我这点自私 ...
- hbase源码系列(十四)Compact和Split
先上一张图讲一下Compaction和Split的关系,这样会比较直观一些. Compaction把多个MemStore flush出来的StoreFile合并成一个文件,而Split则是把过大的文件 ...
- hbase源码系列(二)HTable 探秘
hbase的源码终于搞一个段落了,在接下来的一个月,着重于把看过的源码提炼一下,对一些有意思的主题进行分享一下.继上一篇讲了负载均衡之后,这一篇我们从client开始讲吧,从client到master ...
随机推荐
- [转]SpringMVC中使用Interceptor拦截器
SpringMVC 中的Interceptor 拦截器也是相当重要和相当有用的,它的主要作用是拦截用户的请求并进行相应的处理.比如通过它来进行权限验证,或者是来判断用户是否登陆,或者是像12306 那 ...
- 比较@Resource、@Autowired
@Resource @Resource默认按byName自动注入.既不指定name属性,也不指定type属性,则自动按byName方式进行查找.如果没有找到符合的bean,则回退为一个原始类型进行进行 ...
- springboot 整合 Redis 方法二
方法一请参考之前博文 spring boot 整合 redis 自己的版本 java8 + redis3.0 + springboot 2.0.0 1 spring boot已经支持集成 redis ...
- 有用的 Mongo命令行 db.currentOp() db.collection.find().explain() - 摘自网络
在Heyzap 和 Bugsnag 我已经使用MongoDB超过一年了,我发现它是一个非常强大的数据库.和其他的数据库一样,它有一些缺陷,但是这里有一些东西我希望有人可以早一点告诉我的. 即使建立索引 ...
- php分享十五:php的命令行操作
一:像命令行传参数方法: 1: 使用$argc $argv 用法: /usr/local/php/bin/php ./getopt.php 123 456 2:使用getopt函数() http:/ ...
- iOS-一个弹出菜单动画视图开源项目分享
相似于Tumblr公布button的弹出视图 使用非常easy: 初始化: @property (nonatomic, strong) XWMenuPopView *myMenuPopView; - ...
- tmux用于恢复远程屏幕
1.我主要用tmux在远程登陆后,恢复以前会话时候用. 2.tmux创建新会话: tmux new -s 会话名 3.返回控制台: Ctrl+b d ,Ctrl+b命令是tmux前置命令,每次都要先输 ...
- 关于如果从SQLSERVER中获取 数据库信息 或者 表信息
1.首先呢.要明确一点.SQLSERVER中的系统信息一般都无从table中找到的.通常都在View中找到 这是重点. 2.接着我们打开算起来SQLSERVER,展开你某一数据库.看到类似 3.然后展 ...
- PCIE 调试过程记录
遇到的问题 PCIE link不稳定 配置空间读写正常,Memory mapping空间读写异常 缘由 之前对PCIE的认识一直停留在概念的阶段,只知道是一个高速通讯协议,主要用于板内.板间的高速BU ...
- 【Unity】8.2 GUI Style和GUISkin
分类:Unity.C#.VS2015 创建日期:2016-04-27 一.自定义GUI Control 功能控件 (Functional Control) 是游戏必要的,而这些控件的外观对游戏的美感非 ...