Linux文件系统之Mount流程分析
转载:原文地址http://www.linuxeye.com/linuxrumen/1121.html
本质上,Ext3 mount的过程实际上是inode被替代的过程。例如,/dev/sdb块设备被mount到/mnt/alan目录。那么mount这个过程所需要解决的问题就是将/mnt/alan的dentry目录项所指向的inode屏蔽掉,然后重新定位到/dev/sdb所表示的inode索引节点。在没有分析阅读linux vfs mount代码的时候,我的想法是修改dentry所指向的inode索引节点,以此实现mount文件系统的访问。经过分析,在实际的vfs mount实现过程中,还是和我原始的想法略有差别,但是,基本目标还是相同的。
Linux VFS的mount过程基本原理如下图所示:
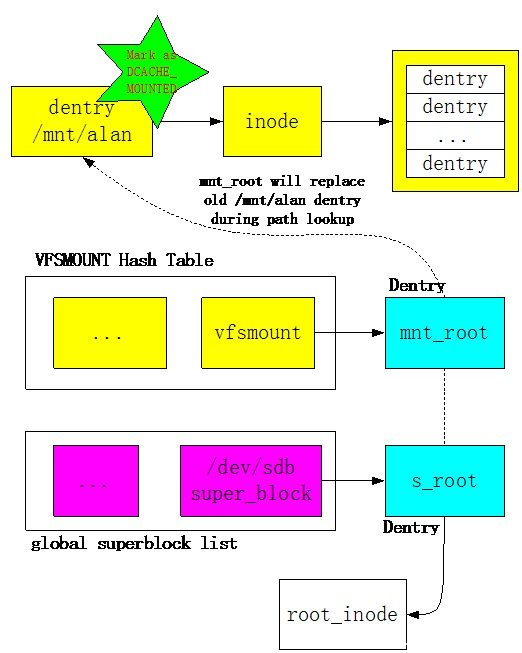
当用户输入”mount /dev/sdb /mnt/alan”命令后,Linux会解析/mnt/alan字符串,并且从Dentry Hash表中获取相关的dentry目录项,然后将该目录项标识成DCACHE_MOUNTED。一旦该dentry被标识成DCACHE_MOUNTED,也就意味着在访问路径上对其进行了屏蔽。
在mount /dev/sdb设备上的ext3文件系统时,内核会创建一个该文件系统的superblock对象,并且从/dev/sdb设备上读取所有的superblock信息,初始化该内存对象。Linux内核维护了一个全局superblock对象链表。s_root是superblock对象所维护的dentry目录项,该目录项是该文件系统的根目录。即新mount的文件系统内容都需要通过该根目录进行访问。在mount的过程中,VFS会创建一个非常重要的vfsmount对象,该对象维护了文件系统mount的所有信息。Vfsmount对象通过HASH表进行维护,通过path地址计算HASH值,在这里vfsmount的HASH值通过“/mnt/alan”路径字符串进行计算得到。Vfsmount中的mnt_root指向superblock对象的s_root根目录项。因此,通过/mnt/alan地址可以检索VFSMOUNT Hash Table得到被mount的vfsmount对象,进而得到mnt_root根目录项。
例如,/dev/sdb被mount之后,用户想要访问该设备上的一个文件ab.c,假设该文件的地址为:/mnt/alan/ab.c。在打开该文件的时候,首先需要进行path解析。在解析到/mnt/alan的时候,得到/mnt/alan的dentry目录项,并且发现该目录项已经被标识为DCACHE_MOUNTED。之后,会采用/mnt/alan计算HASH值去检索VFSMOUNT Hash Table,得到对应的vfsmount对象,然后采用vfsmount指向的mnt_root目录项替代/mnt/alan原来的dentry,从而实现了dentry和inode的重定向。在新的dentry的基础上,解析程序继续执行,最终得到表示ab.c文件的inode对象。
关键数据结构说明
Linux VFS mount所涉及的关键数据结构分析如下。
Vfsmount数据结构
Vfsmount数据结构是vfs mount最为重要的数据结构,其维护了一个mount点的所有信息。该数据结构描述如下:
struct vfsmount {
struct list_head mnt_hash; /* 连接到VFSMOUNT Hash Table */
struct vfsmount *mnt_parent; /* 指向mount树中的父节点 */
struct dentry *mnt_mountpoint; /* 指向mount点的目录项 */
struct dentry *mnt_root; /* 被mount的文件系统根目录项 */
struct super_block *mnt_sb; /* 指向被mount的文件系统superblock */
#ifdef CONFIG_SMP
struct mnt_pcp __percpu *mnt_pcp;
atomic_t mnt_longterm; /* how many of the refs are longterm */
#else
int mnt_count;
int mnt_writers;
#endif
struct list_head mnt_mounts; /* 下级(child)vfsmount对象链表 */
struct list_head mnt_child; /* 链入上级vfsmount对象的链表点 */
int mnt_flags;
/* 4 bytes hole on 64bits arches without fsnotify */
#ifdef CONFIG_FSNOTIFY
__u32 mnt_fsnotify_mask;
struct hlist_head mnt_fsnotify_marks;
#endif
const char *mnt_devname; /* 文件系统所在的设备名字,例如/dev/sdb */
struct list_head mnt_list;
struct list_head mnt_expire; /* link in fs-specific expiry list */
struct list_head mnt_share; /* circular list of shared mounts */
struct list_head mnt_slave_list;/* list of slave mounts */
struct list_head mnt_slave; /* slave list entry */
struct vfsmount *mnt_master; /* slave is on master->mnt_slave_list */
struct mnt_namespace *mnt_ns; /* containing namespace */
int mnt_id; /* mount identifier */
int mnt_group_id; /* peer group identifier */
int mnt_expiry_mark; /* true if marked for expiry */
int mnt_pinned;
int mnt_ghosts;
};
在Linux内核中不仅存在VFSMOUNT的Hash Table,而且还维护了一棵Mount对象树,通过该mount树,我们可以了解到各个文件系统之间的关系。该mount树描述如下:
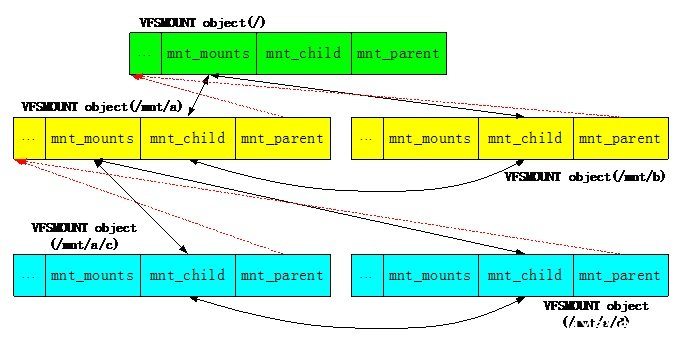
上图所示为三层mount文件系统树。第一层为系统根目录“/”;第二层有两个mount点,一个为/mnt/a,另一个是/mnt/b;第三层在/mnt/a的基础上又创建了两个mount点,分别为/mnt/a/c和/mnt/a/d。通过mount树,可以对整个系统的mount结构一目了然。
Superblock数据结构
每个文件系统都会拥有一个superblock对象对其基本信息进行描述。对于像ext3之类的文件系统而言,在磁盘上会持久化存储一份superblock元数据信息,内存的superblock对象由磁盘上的信息初始化。对于像block device 之类的“伪文件系统”而言,在mount的时候也会创建superblock对象,只不过很多信息都是临时生成的,没有持久化信息。Vfs superblock数据结构定义如下:
struct super_block {
struct list_head s_list; /* 链入全局链表的对象*/
dev_t s_dev; /* search index; _not_ kdev_t */
unsigned char s_dirt;
unsigned char s_blocksize_bits;
unsigned long s_blocksize;
loff_t s_maxbytes; /* Max file size */
struct file_system_type *s_type;
const struct super_operations *s_op; /* superblock操作函数集 */
const struct dquot_operations *dq_op;
const struct quotactl_ops *s_qcop;
const struct export_operations *s_export_op;
unsigned long s_flags;
unsigned long s_magic;
struct dentry *s_root; /* 文件系统根目录项 */
struct rw_semaphore s_umount;
struct mutex s_lock;
int s_count;
atomic_t s_active;
#ifdef CONFIG_SECURITY
void *s_security;
#endif
const struct xattr_handler **s_xattr;
struct list_head s_inodes; /* all inodes */
struct hlist_bl_head s_anon; /* anonymous dentries for (nfs) exporting */
#ifdef CONFIG_SMP
struct list_head __percpu *s_files;
#else
struct list_head s_files;
#endif
/* s_dentry_lru, s_nr_dentry_unused protected by dcache.c lru locks */
struct list_head s_dentry_lru; /* unused dentry lru */
int s_nr_dentry_unused; /* # of dentry on lru */
/* s_inode_lru_lock protects s_inode_lru and s_nr_inodes_unused */
spinlock_t s_inode_lru_lock ____cacheline_aligned_in_smp;
struct list_head s_inode_lru; /* unused inode lru */
int s_nr_inodes_unused; /* # of inodes on lru */
struct block_device *s_bdev;
struct backing_dev_info *s_bdi;
struct mtd_info *s_mtd;
struct list_head s_instances;
struct quota_info s_dquot; /* Diskquota specific options */
int s_frozen;
wait_queue_head_t s_wait_unfrozen;
char s_id[]; /* Informational name */
u8 s_uuid[]; /* UUID */
void *s_fs_info; /* Filesystem private info */
fmode_t s_mode;
/* Granularity of c/m/atime in ns.
Cannot be worse than a second */
u32 s_time_gran;
/*
* The next field is for VFS *only*. No filesystems have any business
* even looking at it. You had been warned.
*/
struct mutex s_vfs_rename_mutex; /* Kludge */
/*
* Filesystem subtype. If non-empty the filesystem type field
* in /proc/mounts will be "type.subtype"
*/
char *s_subtype;
/*
* Saved mount options for lazy filesystems using
* generic_show_options()
*/
char __rcu *s_options;
const struct dentry_operations *s_d_op; /* default d_op for dentries */
/*
* Saved pool identifier for cleancache (-1 means none)
*/
int cleancache_poolid;
struct shrinker s_shrink; /* per-sb shrinker handle */
};
代码流程分析
Linux中实现mount操作需要一定的代码量,下面对Linux VFS Mount代码进行分析说明,整个分析过程按照mount操作函数调用流程进行。代码分析基于Linux-3.2版本。
当用户在用户层执行mount命令时,会执行系统调用从用户态陷入linux内核,执行如下函数(namespace.c):
SYSCALL_DEFINE5(mount, char __user *, dev_name, char __user *, dir_name,
char __user *, type, unsigned long, flags, void __user *, data)
{
int ret;
char *kernel_type;
char *kernel_dir;
char *kernel_dev;
unsigned long data_page;
/* 获取mount类型 */
ret = copy_mount_string(type, &kernel_type);
if (ret < )
goto out_type;
/* 获取mount点目录字符串 */
kernel_dir = getname(dir_name);
if (IS_ERR(kernel_dir)) {
ret = PTR_ERR(kernel_dir);
goto out_dir;
}
/* 获取设备名称字符串 */
ret = copy_mount_string(dev_name, &kernel_dev);
if (ret < )
goto out_dev;
/* 获取其它选项 */
ret = copy_mount_options(data, &data_page);
if (ret < )
goto out_data;
/* 主要函数,执行挂载文件系统的具体操作 */
ret = do_mount(kernel_dev, kernel_dir, kernel_type, flags,
(void *) data_page); free_page(data_page);
out_data:
kfree(kernel_dev);
out_dev:
putname(kernel_dir);
out_dir:
kfree(kernel_type);
out_type:
return ret;
}
do_mount()函数是mount操作过程中的核心函数,在该函数中,通过mount的目录字符串找到对应的dentry目录项,然后通过do_new_mount()函数完成具体的mount操作。do_mount()函数分析如下:
long do_mount(char *dev_name, char *dir_name, char *type_page,
unsigned long flags, void *data_page)
{
struct path path;
int retval = ;
int mnt_flags = ; 。。。 /* 通过mount目录字符串获取path,path结构中包含有mount目录的dentry目录对象 */
retval = kern_path(dir_name, LOOKUP_FOLLOW, &path);
if (retval)
return retval; 。。。 /* Separate the per-mountpoint flags */
if (flags & MS_NOSUID)
mnt_flags |= MNT_NOSUID;
if (flags & MS_NODEV)
mnt_flags |= MNT_NODEV;
if (flags & MS_NOEXEC)
mnt_flags |= MNT_NOEXEC;
if (flags & MS_NOATIME)
mnt_flags |= MNT_NOATIME;
if (flags & MS_NODIRATIME)
mnt_flags |= MNT_NODIRATIME;
if (flags & MS_STRICTATIME)
mnt_flags &= ~(MNT_RELATIME | MNT_NOATIME);
if (flags & MS_RDONLY)
mnt_flags |= MNT_READONLY; flags &= ~(MS_NOSUID | MS_NOEXEC | MS_NODEV | MS_ACTIVE | MS_BORN |
MS_NOATIME | MS_NODIRATIME | MS_RELATIME| MS_KERNMOUNT |
MS_STRICTATIME); /* remount操作 */
if (flags & MS_REMOUNT)
retval = do_remount(&path, flags & ~MS_REMOUNT, mnt_flags,
data_page);
else if (flags & MS_BIND)
retval = do_loopback(&path, dev_name, flags & MS_REC);
else if (flags & (MS_SHARED | MS_PRIVATE | MS_SLAVE | MS_UNBINDABLE))
retval = do_change_type(&path, flags);
else if (flags & MS_MOVE)
retval = do_move_mount(&path, dev_name);
else
/* 正常的mount操作,完成具体的mount操作 */
retval = do_new_mount(&path, type_page, flags, mnt_flags,
dev_name, data_page);
dput_out:
path_put(&path);
return retval;
}
do_new_mount()函数主要分成两大部分:第一部分建立vfsmount对象和superblock对象,必要时从设备上获取文件系统元数据;第二部分将vfsmount对象加入到mount树和Hash Table中,并且将原来的dentry对象无效掉。do_new_mount函数说明如下:
static int do_new_mount(struct path *path, char *type, int flags,
int mnt_flags, char *name, void *data)
{
struct vfsmount *mnt;
int err; 。。。 /* 在内核建立vfsmount对象和superblock对象 */
mnt = do_kern_mount(type, flags, name, data);
if (IS_ERR(mnt))
return PTR_ERR(mnt);
/* 将vfsmount对象加入系统,屏蔽原有dentry对象 */
err = do_add_mount(mnt, path, mnt_flags);
if (err)
mntput(mnt);
return err;
}
do_new_mount()中的第一步调用do_kern_mount()函数,该函数的主干调用路径如下:
do_kern_mount--> vfs_kern_mount--> mount_fs
在mount_fs()函数中会调用特定文件系统的mount方法,如果mount是ext3文件系统,那么在mount_fs函数中最终会调用ext3的mount方法。Ext3的mount方法定义在super.c文件中:
static struct file_system_type ext3_fs_type = {
.owner = THIS_MODULE,
.name = "ext3",
.mount = ext3_mount, /* ext3文件系统mount方法 */
.kill_sb = kill_block_super,
.fs_flags = FS_REQUIRES_DEV,
};
ext3 mount函数主干调用路径为:ext3_mount--> mount_bdev。Mount_bdev()函数主要完成superblock对象的内存初始化,并且加入到全局superblock链表中。该函数说明如下:
struct dentry *mount_bdev(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data,
int (*fill_super)(struct super_block *, void *, int))
{
struct block_device *bdev;
struct super_block *s;
fmode_t mode = FMODE_READ | FMODE_EXCL;
int error = ; if (!(flags & MS_RDONLY))
mode |= FMODE_WRITE;
/* 通过设备名字获取被mount设备的bdev对象 */
bdev = blkdev_get_by_path(dev_name, mode, fs_type);
if (IS_ERR(bdev))
return ERR_CAST(bdev); /*
* once the super is inserted into the list by sget, s_umount
* will protect the lockfs code from trying to start a snapshot
* while we are mounting
*/
mutex_lock(&bdev->bd_fsfreeze_mutex);
if (bdev->bd_fsfreeze_count > ) {
mutex_unlock(&bdev->bd_fsfreeze_mutex);
error = -EBUSY;
goto error_bdev;
}
/* 查找或者创建superblock对象 */
s = sget(fs_type, test_bdev_super, set_bdev_super, bdev);
mutex_unlock(&bdev->bd_fsfreeze_mutex);
if (IS_ERR(s))
goto error_s; if (s->s_root) {
/* 被mount文件系统的根目录项已经存在 */
if ((flags ^ s->s_flags) & MS_RDONLY) {
deactivate_locked_super(s);
error = -EBUSY;
goto error_bdev;
} /*
* s_umount nests inside bd_mutex during
* __invalidate_device(). blkdev_put() acquires
* bd_mutex and can't be called under s_umount. Drop
* s_umount temporarily. This is safe as we're
* holding an active reference.
*/
up_write(&s->s_umount);
blkdev_put(bdev, mode);
down_write(&s->s_umount);
} else {
/* 文件系统根目录项不存在,通过filler_super函数读取磁盘上的superblock元数据信息,并且初始化superblock内存结构 */
char b[BDEVNAME_SIZE]; s->s_flags = flags | MS_NOSEC;
s->s_mode = mode;
strlcpy(s->s_id, bdevname(bdev, b), sizeof(s->s_id));
sb_set_blocksize(s, block_size(bdev));
/* 对于ext3文件系统,调用ext3_fill_super函数 */
error = fill_super(s, data, flags & MS_SILENT ? : );
if (error) {
deactivate_locked_super(s);
goto error;
} s->s_flags |= MS_ACTIVE;
bdev->bd_super = s;
}
/* 正常返回被mount文件系统根目录项 */
return dget(s->s_root); error_s:
error = PTR_ERR(s);
error_bdev:
blkdev_put(bdev, mode);
error:
return ERR_PTR(error);
}
do_new_mount()函数的第二步是将创建的vfsmount对象加入到mount树和VFSMOUNT Hash Table中,并且将老的dentry目录项无效掉。该过程主干函数调用过程如下所示:
do_new_mount--> do_add_mount--> graft_tree--> attach_recursive_mnt
attach_recursive_mnt()函数完成第二步过程的主要操作。至此,文件系统的mount操作已经完成。Mount完成之后,如果用户想要访问新mount文件系统中的文件,那么需要在path解析过程中重定位dentry,该过程主要在follow_managed()函数中完成。在该函数中会判断一个dentry是否已经被标识成DCACHE_MOUNTED,如果该标志位已经被设置,那么通过VFSMOUNT Hash Table可以重定位dentry。
Linux文件系统之Mount流程分析的更多相关文章
- 【转】linux文件系统之mount流程分析
本质上,Ext3 mount的过程实际上是inode被替代的过程. 例如,/dev/sdb块设备被mount到/mnt/alan目录.命令:mount -t ext3 /dev/sdb /mnt/al ...
- Android SDCard Mount 流程分析
前段时间对Android 的SDCard unmount 流程进行了几篇简短的分析,由于当时只是纸上谈兵,没有实际上的跟进,可能会有一些误导人或者小错误.今天重新梳理了头绪,针对mount的流程再重新 ...
- Linux 3.14 待机流程分析
1:待机节点创建 static int __init pm_init(void) { int error = pm_start_workqueue(); if (error) return error ...
- linux网络协议栈--路由流程分析
转:http://blog.csdn.net/hsly_support/article/details/8797976 来吧,路由 路由是网络的核心,是linux网络协议栈的核心,我们找个入口进去看看 ...
- Linux文件/proc/net/tcp分析
本文转载自Linux文件/proc/net/tcp分析 导语 /proc/net/tcp文件提供了tcp的连接信息,是由net/ipv4/tcp_ipv4.c中的tcp4_seq_show()实现信息 ...
- 基于linux与busybox的reboot命令流程分析
http://www.xuebuyuan.com/736763.html 基于Linux与Busybox的Reboot命令流程分析 ********************************** ...
- linux文件系统和日志分析
一.Linux文件系统 1.inode与block 1.概述: (1)文件数据包括元信息与实际信息 (2)文件存储在硬盘上,硬盘最小存储单位是"扇区",每个扇区存储512字节 (3 ...
- Linux文件系统与日志分析
Linux文件系统与日志分析一.inode与block概述① 文件数据包括元信息(类似文件属性)与实际数据② 文件存储在硬盘上,硬盘最小存储单位是"扇区"(sector),每个扇区 ...
- Linux文件系统与日志分析的了解
Linux文件系统与日志分析 1.inode和block概述 2.模拟inode耗尽实验 3.ext类型文件恢复 4.xfs类型文件恢复 5.日志文件 6.日志分析 1.文件:文件是存储在硬盘上的,硬 ...
随机推荐
- c assert 用法
#include <stdio.h> /* printf */ #include <assert.h> /* assert */ void print_number(int* ...
- xinwenti
angularjs angular2脏检查机制和数据双向绑定远离 angular2 aot编译
- codeforces 559b//Equivalent Strings// Codeforces Round #313(Div. 1)
题意:定义了字符串的相等,问两串是否相等. 卡了时间,空间,不能新建字符串,否则会卡. #pragma comment(linker,"/STACK:1024000000,102400000 ...
- 谈谈http与https
今天简单的来说一下http和https, 简单来讲: HTTP 是 超文本协议,TCP 端口是 80 HTTPS 是一种配合了SSL协议的.加密的HTTP 协议 ,TCP端口是 443 HTTP ...
- Android设计模式之单例模式
定义 单例模式是一种常用的软件设计模式.在它的核心结构中只包含一个被称为单例的特殊类.通过单例模式可以保证系统中一个类只有一个实例 . 单例模式是设计模式中最简单的形式之一.这一模式的目的是使得类的一 ...
- 使用nginx+dnsmasq解决同IP不同端口Session冲突问题
由于一台服务器上需要部署多个项目,而我们的WEB项目因为用到框架都是一样的,导致同时运行,session相互冲突,这个登录后,那个就得重新登录,造成了使用不方便,原因是IP相同认为是同一个域,接收了B ...
- php安装redis扩展全
一.安装redis mac 下安装也可以使用 homebrew,homebrew 是 mac 的包管理器. 1.执行 brew install redis 2.启动 redis,可以使用后台服务启动 ...
- python-day39--mysql基本操作
1.修改密码: mysqladmin -uroot password 123 2.忘记密码如何修改密码: 1.干掉data目录---> 重新初始化 (不推荐,所有授权信息全部丢失!!!) 2 ...
- nyoj1248(阅读理解???)
海岛争霸 时间限制:1000 ms | 内存限制:65535 KB 难度:3 描述 神秘的海洋,惊险的探险之路,打捞海底宝藏,激烈的海战,海盗劫富等等.加勒比海盗,你知道吧?杰克船长驾驶着自己 ...
- 隔离级别 && SNAPSHOT
read uncommitted | 0 未提交读 将查询的隔离级别指定为 0. 可以读脏数据. 读脏数据:一事务对数据进行了增删改,但未提交,有可能回滚,另一事务却读取了未提交的数据. 例: 公 ...