公司HBase基准性能测试之结果篇
上一篇文章《公司HBase基准性能测试之准备篇》中详细介绍了本次性能测试的基本准备情况,包括测试集群架构、单台机器软硬件配置、测试工具以及测试方法等,在此基础上本篇文章主要介绍HBase在各种测试场景下的性能指标(主要包括单次请求平均延迟和系统吞吐量)以及对应的资源利用情况,并对各种测试结果进行分析。
测试结果
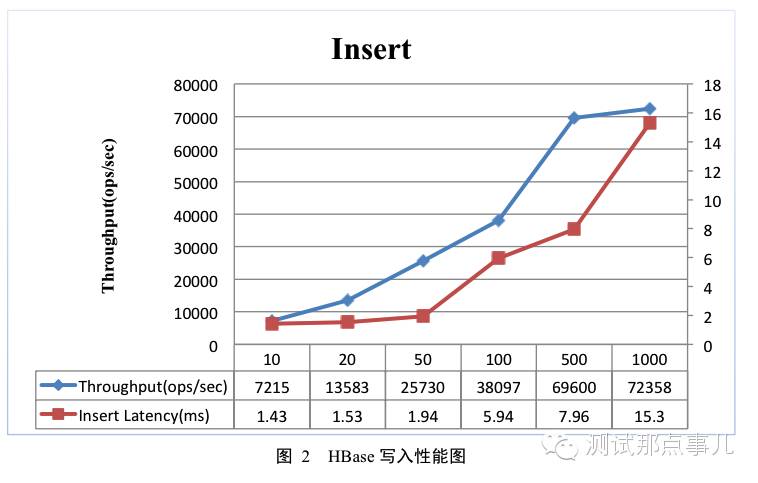
单条记录插入
测试参数
总记录数为10亿,分为128个region,均匀分布在4台region server上;插入操作执行2千万次;插入请求分布遵从zipfian分布;
测试结果
资源使用情况
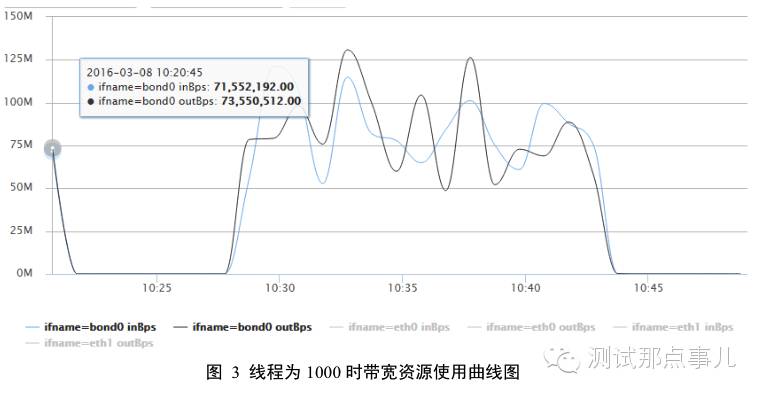
上图为单台RegionServer的带宽使用曲线图(资源使用情况中只列出和本次测试相关的资源曲线图,后面相关资源使用情况类似),本次测试线程为1000的情况下带宽基本维持在100M左右,对于百兆网卡来说基本上已经打满。
结果分析
1. 吞吐量曲线分析:线程数在10~500的情况下,随着线程数的增加,系统吞吐量会不断升高;之后线程数再增加,系统吞吐量基本上不再变化。结合图3带宽资源使用曲线图可以看出,当线程数增加到一定程度,系统带宽资源基本耗尽,系统吞吐量就不再会增加。可见,HBase写操作是一个带宽敏感型操作,当带宽资源bound后,写入吞吐量基本就会稳定。
2. 写入延迟曲线分析:随着线程数的不断增加,写入延迟也会不断增大。这是因为写入线程过多,导致CPU资源调度频繁,单个线程分配到的CPU资源会不断降低;另一方面由于线程之间可能会存在互斥操作导致线程阻塞;这些因素都会导致写入延迟不断增大。
建议
根据曲线显示,500线程以内的写入延迟并不大于10ms,而此时吞吐量基本最大,因此如果是单纯写入的话500线程写入会是一个比较合适的选择。
单纯查询
测试参数
总记录数为10亿,分为128个region,均匀分布在4台region server上;查询操作执行2千万次;查询请求分布遵从zipfian分布;
测试结果

资源使用情况

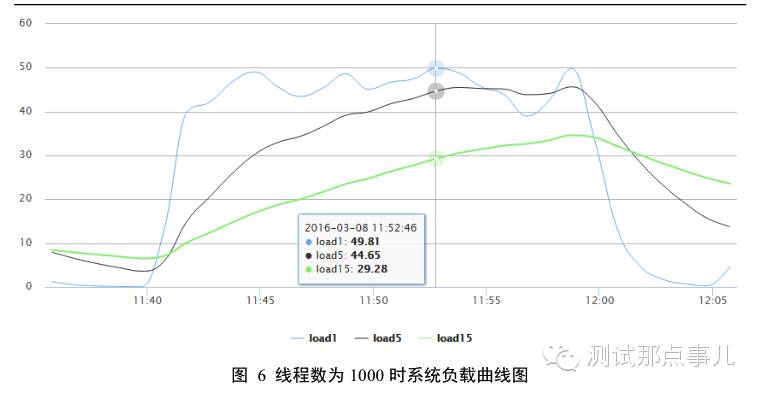
图5为线程数在1000时IO利用率曲线图,图中IO利用率基本保持在100%,说明IO资源已经达到使用上限。图6为线程数在1000时系统负载曲线图,图中load1曲线表示在最近一分钟内的平均负载,load5表示最近五分钟内的平均负载。最近5分钟的负责达到了50左右,对于32核系统来说,表示此时系统负载很高,已经远远超负荷运行。
结果分析
1. 吞吐量曲线分析:线程数在10~500的情况下,随着线程数的增加,系统吞吐量会不断升高;之后线程数再增加,系统吞吐量基本上不再变化。结合图5、图6系统资源使用曲线图可以看出,当线程数增加到一定程度,系统IO资源基本达到上限,系统负载也特别高。IO利用率达到100%是因为大量的读操作都需要从磁盘查找数据,系统负载很高是因为HBase需要对查找的数据进行解压缩操作,解压缩操作需要耗费大量CPU资源。这两个因素结合导致系统吞吐量就不再随着线程数增肌而增加。可见,HBase读操作是一个IO/CPU敏感型操作,当IO或者CPU资源bound后,读取吞吐量基本就会稳定不变。
2. 延迟曲线分析:随着线程数的不断增加,读取延迟也会不断增大。这是因为读取线程过多,导致CPU资源调度频繁,单个线程分配到的CPU资源会不断降低;另一方面由于线程之间可能会存在互斥操作导致线程阻塞;这些因素都会导致写入延迟不断增大。和写入延迟相比,读取延迟会更大,是因为读取涉及IO操作,IO本身就是一个耗时操作,导致延迟更高。
建议
根据曲线显示,500线程以内的读取延迟并不大于20ms,而此时吞吐量基本最大,因此如果是单纯读取的话500线程读取会是一个比较合适的选择。
Range扫描查询
测试参数
总记录数为10亿,分为128个region,均匀分布在4台region server上;scan操作执行一千两百万次,请求分布遵从zipfian分布; scan最大长度为100条记录, scan长度随机分布且遵从uniform分布;
测试结果

资源使用情况
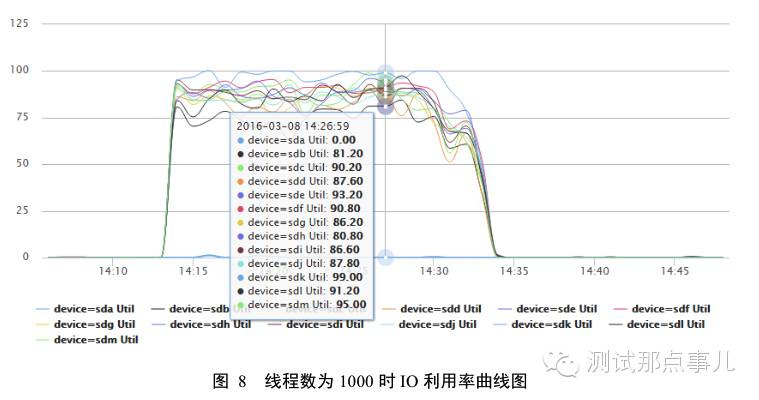

图8为线程数在1000时IO利用率曲线图,图中IO利用率基本保持在100%,说明IO资源已经达到使用上限。图9为线程数在1000时带宽资源使用曲线图,图中带宽资源基本也已经达到上限。
结果分析
1. 吞吐量曲线分析:线程数在10~500的情况下,随着线程数的增加,系统吞吐量会不断升高;之后线程数再增加,系统吞吐量基本上不再变化。结合图8 、图9资源使用曲线图可以看出,当线程数增加到一定程度,系统IO资源基本达到上限,带宽也基本达到上限。IO利用率达到100%是因为大量的读操作都需要从磁盘查找数据,而带宽负载很高是因为每次scan操作最多可以获取50Kbyte数据,TPS太高会导致数据量很大,因而带宽负载很高。两者结合导致系统吞吐量就不再随着线程数增大会增大。可见,scan操作是一个IO/带宽敏感型操作,当IO或者带宽资源bound后,scan吞吐量基本就会稳定不变。
2. 延迟曲线分析:随着线程数的不断增加,读取延迟也会不断增大。这是因为读取线程过多,导致CPU资源调度频繁,单个线程分配到的CPU资源会不断降低;另一方面由于线程之间可能会存在互斥操作导致线程阻塞;这些因素都会导致写入延迟不断增大。和写入延迟以及单次随机查找相比,读取延迟会更大,是因为scan操作会涉及多次IO操作,IO本身就是一个耗时操作,因此会导致延迟更高。
建议
根据图表显示,用户可以根据业务实际情况选择100~500之间的线程数来执行scan操作。
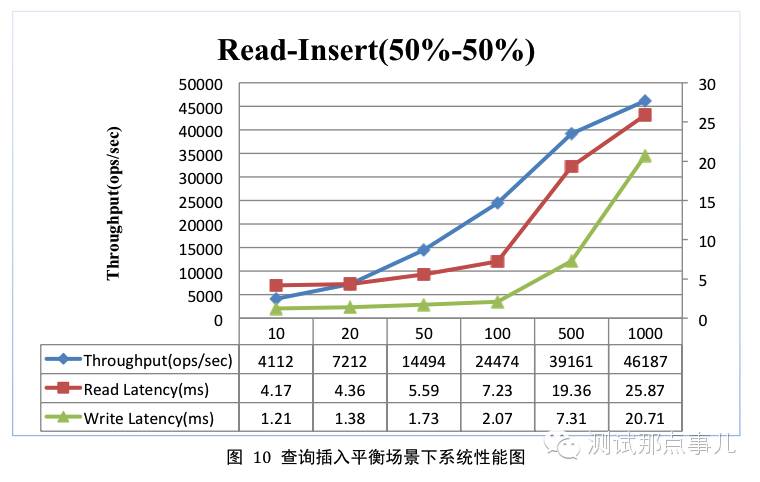
查询插入平衡
测试参数
总记录数为10亿,分为128个region,均匀分布在4台region server上;查询插入操作共执行8千万次;查询请求分布遵从zipfian分布;
测试结果
资源使用情况
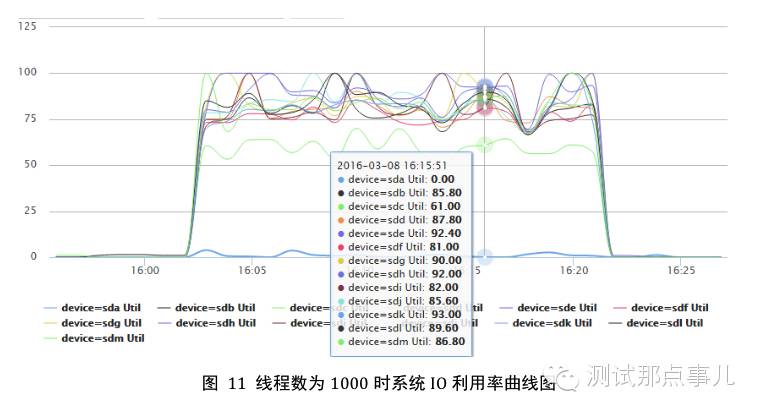
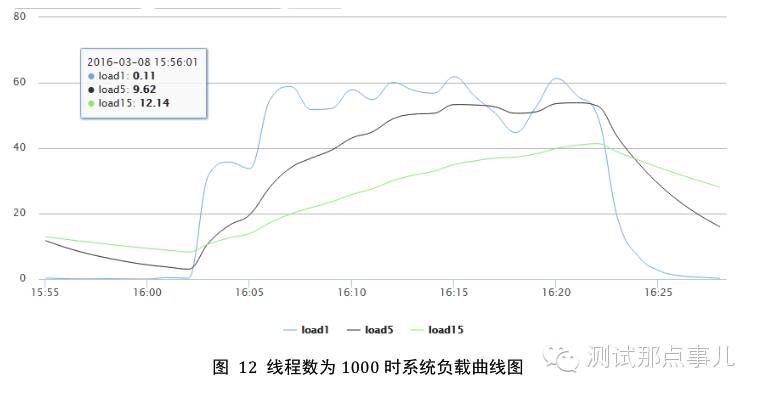
图11为线程数在1000时系统IO利用率曲线图,图中IO利用率基本保持在100%,说明IO资源已经达到使用上限。图12为线程数在1000时系统负载曲线图,图中显示CPU负载资源达到了40+,对于只有32核的系统来说,已经远远超负荷工作了。
结果分析
1. 吞吐量曲线分析:线程数在10~500的情况下,随着线程数的增加,系统吞吐量会不断升高;之后线程数再增加,系统吞吐量变化就比较缓慢。结合图11、图12系统资源使用曲线图可以看出,当线程数增加到一定程度,系统IO资源基本达到上限,带宽也基本达到上限。IO利用率达到100%是因为大量的读操作都需要从磁盘查找数据,而系统负载很高是因为大量读取操作需要进行解压缩操作,而且线程数很大本身就需要更多CPU资源。因此导致系统吞吐量就不再会增加。可见,查询插入平衡场景下,当IO或者CPU资源bound后,系统吞吐量基本就会稳定不变。
2. 延迟曲线分析:随着线程数的不断增加,读取延迟也会不断增大。这是因为读取线程过多,导致CPU资源调度频繁,单个线程分配到的CPU资源会不断降低;另一方面由于线程之间可能会存在互斥操作导致线程阻塞;这些因素都会导致写入延迟不断增大。图中读延迟大于写延迟是因为读取操作涉及到IO操作,比较耗时。
建议
根据图表显示,在查询插入平衡场景下用户可以根据业务实际情况选择100~500之间的线程数。
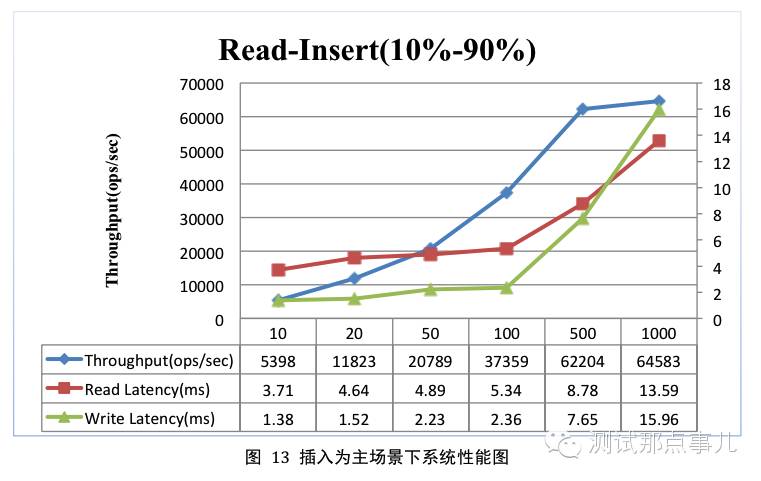
插入为主
测试参数
总记录数为10亿,分为128个region,均匀分布在4台region server上;查询插入操作共执行4千万次;查询请求分布遵从latest分布;
测试结果
资源使用情况
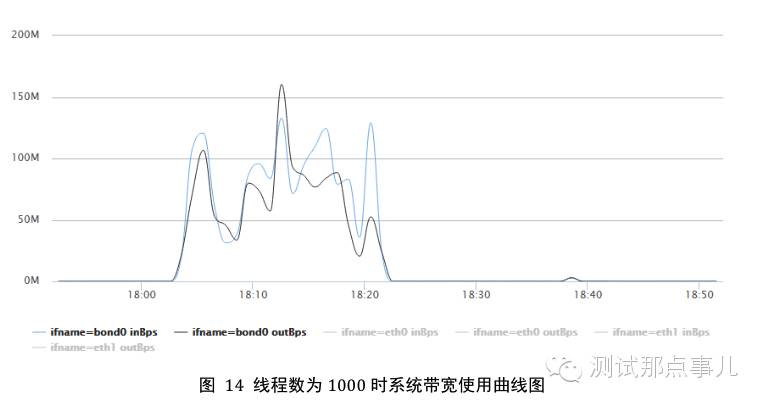
图15为线程数在1000时系统带宽使用曲线图,图中系统带宽资源基本到达上限,而总体IO利用率还比较低。
结果分析
1. 曲线分析:线程数在10~500的情况下,随着线程数的增加,系统吞吐量会不断升高;之后线程数再增加,系统吞吐量基本上不再变化。结合图14带宽资源使用曲线图可以看出,当线程数增加到一定程度,系统带宽资源基本耗尽,系统吞吐量就不再会增加。基本同单条记录插入场景相同。
2. 写入延迟曲线分析: 基本同单条记录插入场景。
建议
根据图表显示,插入为主的场景下用户可以根据业务实际情况选择500左右的线程数来执行。
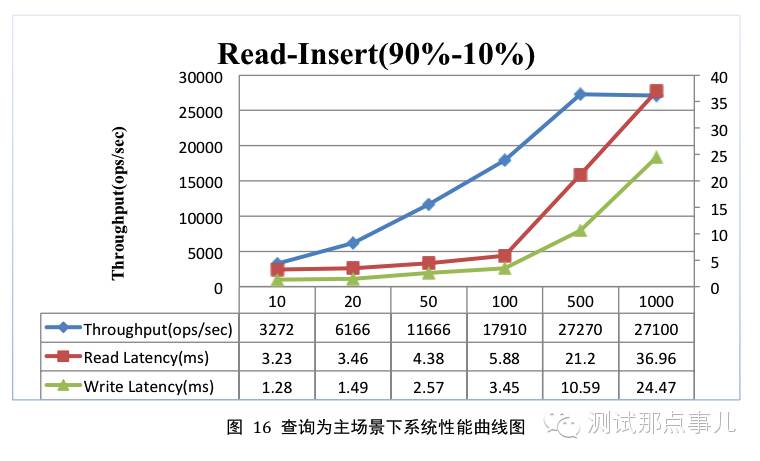
查询为主
测试参数
总记录数为10亿,分为128个region,均匀分布在4台region server上;查询插入操作共执行4千万次;查询请求分布遵从zipfian分布;
测试结果
资源使用情况
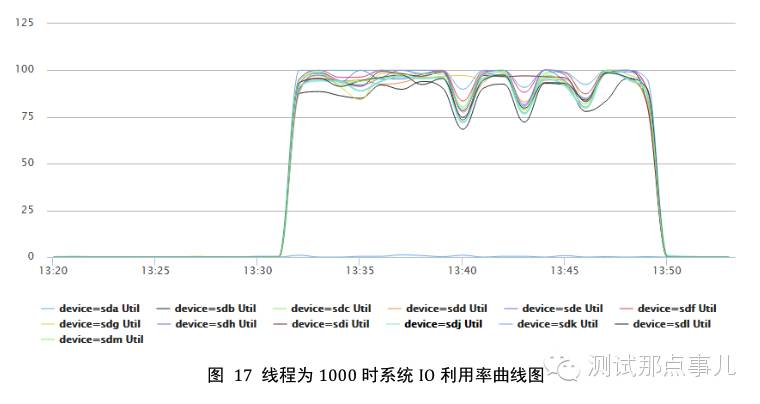
图17为线程数在1000时IO利用率曲线图,图中IO利用率基本保持在100%,说明IO资源已经达到使用上限。
结果分析
基本分析见单纯查询一节,原理类似。
建议
根据图表显示,查询为主的场景下用户可以根据业务实际情况选择100~500之间的线程数来执行。
Increment自增
测试参数
1亿条数据,分成16个Region,分布在4台RegionServer上;操作次数为100万次;
测试结果
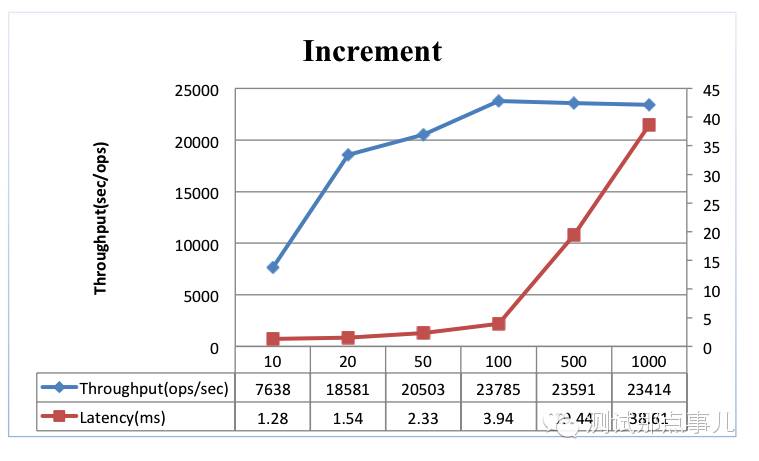
结果分析
1. 线程数增加,Increment操作的吞吐量会不断增加,线程数到达100个左右时,吞吐量会达到顶峰(23785 ops/sec),之后再增加线程数,吞吐量基本维持不变;
2. 随着线程数增加,Increment操作的平均延迟会不断增加。线程数在100以下,平均延时都在4ms以内;
建议
根据图表显示,查询为主的场景下用户可以根据业务实际情况选择100~500之间的线程数来执行。
测试结果总结
根据以上测试结果和资源利用情况可以得出如下几点:
1. 写性能:集群吞吐量最大可以达到70000+ ops/sec,延迟在几个毫秒左右。网络带宽是主要瓶颈,如果将千兆网卡换成万兆网卡,吞吐量还可以继续增加,甚至达到目前吞吐量的两倍。
2. 读性能:很多人对HBase的印象可能都是写性能很好、读性能很差,但实际上HBase的读性能远远超过大家的预期。集群吞吐量最大可以达到26000+,单台吞吐量可以达到8000+左右,延迟在几毫秒~20毫秒左右。IO和CPU是主要瓶颈。
3. Range 扫描性能:集群吞吐量最大可以达到14000左右,系统平均延迟在几毫秒~60毫秒之间(线程数越多,延迟越大);其中IO和网络带宽是主要瓶颈。
测试注意事项
1. 需要关注是否是全内存测试,全内存测试和非全内存测试结果相差会比较大。参考线上实际数据情况,本次测试采用非全内存读测试。是否是全内存读取决于总数据量大小、集群Jvm内存大小、Block Cache占比、访问分布是否是热点访问这四者,在JVM内存大小以及Block Cache占比不变的情况下,可以增大总数据量大小或者修改访问分布;
2. 测试客户端是否存在瓶颈。HBase测试某些场景特别耗费带宽资源,如果单个客户端进行测试很可能会因为客户端带宽被耗尽导致无法测出实际服务器集群性能。本次测试使用6个客户端并发进行测试。
3. 单条记录大小对测试的影响。单条记录设置太大,会导致并发插入操作占用大量带宽资源进而性能产生瓶颈。而设置太小,测试出来的TPS峰值会比较大,和线上实际数据不符。本次测试单条数据大小设置为50M,基本和实际情况相符。
本文章为作者原创
本次测试主要评估线上HBase的整体性能,量化当前HBase的性能指标,对各种场景下HBase性能表现进行评估,为业务应用提供参考. 测试环境 测试环境包括测试过程中HBase集群的拓扑结构.以及需要 ... 作者:范欣欣 本次测试主要评估线上HBase的整体性能,量化当前HBase的性能指标,对各种场景下HBase性能表现进行评估,为业务应用提供参考.本篇文章主要介绍此次测试的基本条件,HBase在各种测 ... 因官方Book Performance Tuning部分章节没有按配置项进行索引,不能达到快速查阅的效果.所以我以配置项驱动,重新整理了原文,并补充一些自己的理解,如有错误,欢迎指正. 配置优化 zo ... 性能计数器(counter)是描述服务器或操作系统性能的一些数据指标.计数器在性能测试中发挥着“监控和分析”的关键作用,尤其是在分析系统的可扩展性.进行性能瓶颈的定位时,对计数器的取值的分析非常关键. ... 性能测试培训:Ajax接口级性能测试之jmeter版 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.在poptest认为工具 ... 老李分享知识:性能测试之TPS和吞吐率 当增大系统的压力(或添加并发用户数)时,吞吐率和TPS的改变曲线呈大体一致,则系统基本稳定. 若压力增大时,吞吐率的曲线添加到一定程度后出现改变缓 ... 因官方Book Performance Tuning部分章节没有按配置项进行索引,不能达到快速查阅的效果.所以我以配置项驱动,重新整理了原文,并补充一些自己的理解,如有错误,欢迎指正. 配置优化 zo ... 安卓应用的流量统计有多种方式,点击「阅读原文」可以看到一篇别人写的文章,关于安卓流量数据的获取,写的挺全的,列举了几种不同方式的优劣.(见文末参考链接) 今天我要分享的是通过脚本一键获取应用的启动流量 ... 性能测试之JMeter远程模式 事实上,你的JMeter客户端机器是不能表现出完美的压力请求,来模拟足够多的用户或由于网络限制去向服务施加压力,一种解决方法是通过一个JMeter去控制多个/远程JMe ... 1.什么是GeoWebCache GeoWebCache是地图缓存软件公司成员开发的一个基于java的开源项目.和其他的缓存系统相似,它作为一个客户端和地图服务的代理.它可以单独部署,适用于任何基于W ... 众所周知,mysql5.7推出后有很多没有填好的坑,对于老的系统和项目兼容性也存在问题,所以现在普遍的web项目还是应该跑在centos6.8+mysql5.6的环境之下,今天主要说一下mysql5. ... Linux系统上安装MySQL 安装MySQL 卸载自带mysql 查询mysql的安装情况,可以直接使用了 rpm -qa | grep -i mysql –-color 卸载原生的MySQL rp ... Hibernate的基本用法 ⊙ ORM的基本知识 ⊙ ORM和Hibernate的关系 ⊙ Hibernate的基本映射思想 ⊙ Hibernate入门知识 ⊙ 使用Eclipse开发Hiberna ... <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ... Maven update project...后jdk变成1.5,update project后jdk版本改变 ============================== 蕃薯耀 2018年3月14 ... java List分批处理,例如对List中的数据进行批量插入. 方法一: /** * ClassName:Test List分批处理 * @author Joe * @version * @sinc ... Selenium 模拟浏览器操作,有一些操作,它们没有特定的执行对象,比如鼠标拖曳.键盘按键等,这些动作用另一种方式来执行,那就是动作链 更多动作链参考官网:https://selenium-pyth ... <dd id="pingjia${evaluation.orderItemId }" class="ms-wf clearfix" idx="$ ... 一.Linux下安装ElasticSearch 1.检测是否安装了Elasticsearch ps aux |grep elasticsearch 2.安装JDK 3.下载Elasticsearch ...公司HBase基准性能测试之结果篇的更多相关文章
随机推荐