cloudera learning5:Hadoop集群高级配置
HDFS-NameNode Tuning:
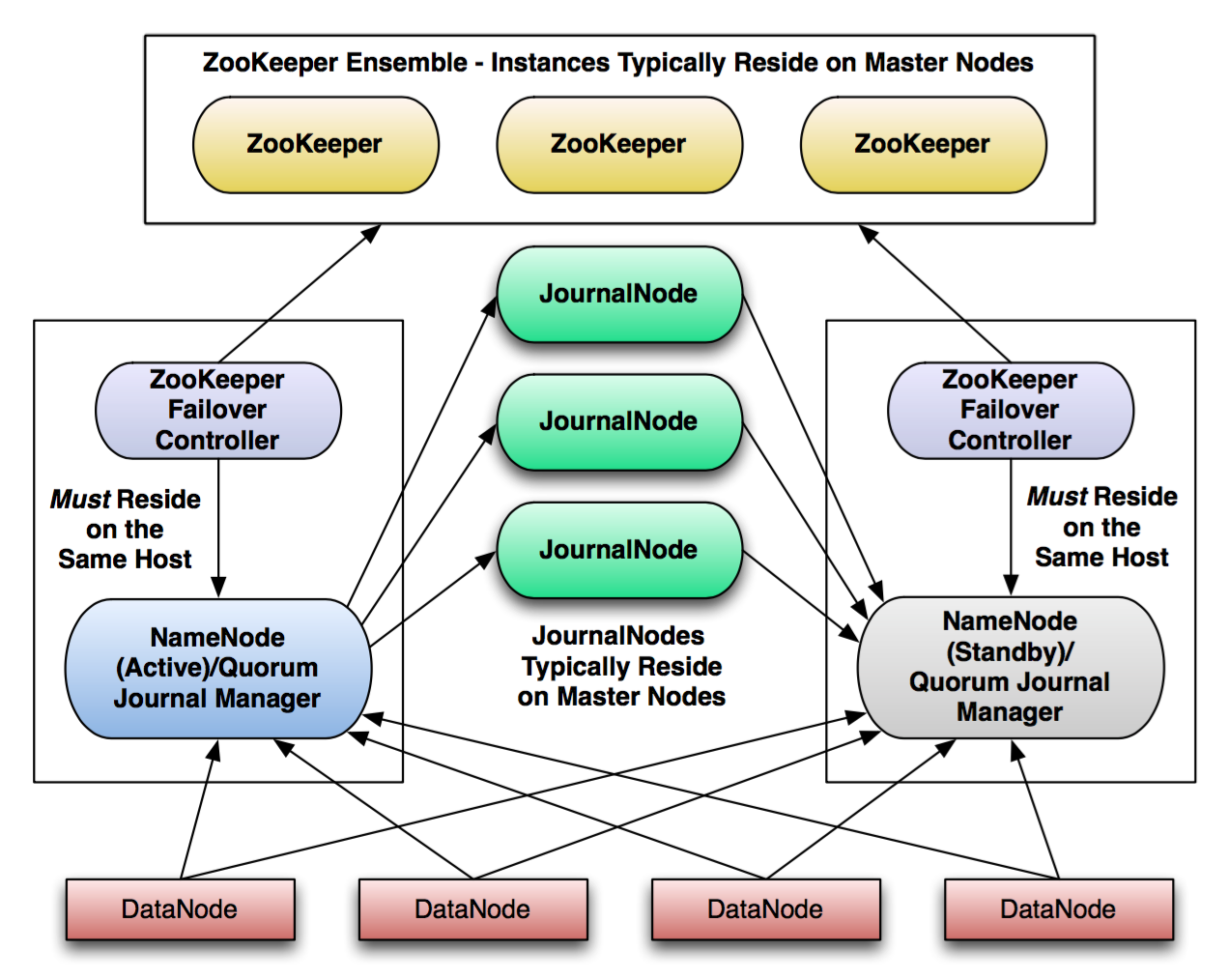
cloudera learning5:Hadoop集群高级配置的更多相关文章
- 【Big Data】HADOOP集群的配置(一)
Hadoop集群的配置(一) 摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问 ...
- 【Big Data】HADOOP集群的配置(二)
Hadoop集群的配置(二) 摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问 ...
- Hadoop的学习前奏(二)——Hadoop集群的配置
前言: Hadoop集群的配置即全然分布式Hadoop配置. 笔者的环境: Linux: CentOS 6.6(Final) x64 JDK: java version "1.7 ...
- Hadoop集群的配置(一)
摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问题.但是网上一些文档大多互相抄 ...
- cloudera learning4:Hadoop集群规划
涉及到一些关于硬件的东西,我也不是很懂,记录下来有待以后学习. Hadoop集群一般都是由小到大,刚开始可能只有4到6个节点,随着存储数据的增加,计算量的增大,内存需求的增加,集群慢慢变大. 比如按照 ...
- hadoop 集群的配置
在经过几天折腾,终于将hadoop环境搭建成功,整个过程中遇到各种坑,反复了很多遍,光虚拟机就重新安装了4.5次,接下来就把搭建的过程详细叙述一下 0.相关工具: 1,系统环境说明: 我这边给出我的集 ...
- hadoop集群默认配置和常用配置【转】
转自http://www.cnblogs.com/ggjucheng/archive/2012/04/17/2454590.html 获取默认配置 配置hadoop,主要是配置core-site.xm ...
- Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS
摘自:http://www.powerxing.com/install-hadoop-cluster/ 本教程讲述如何配置 Hadoop 集群,默认读者已经掌握了 Hadoop 的单机伪分布式配置,否 ...
- hadoop集群默认配置和常用配置
http://www.cnblogs.com/ggjucheng/archive/2012/04/17/2454590.html 获取默认配置 配置hadoop,主要是配置core-site.xml, ...
随机推荐
- .NET LINQ 元素操作
元素操作 元素操作从一个序列返回单个特定元素. 方法 方法名 说明 C# 查询表达式语法 Visual Basic 查询表达式语法 更多信息 ElementAt 返回集合中指定索引处的元素. ...
- APP测试实用小工具
1.ADB万能驱动 http://pan.baidu.com/s/1jIJPwhS 2.安卓手机屏幕共享 http://pan.baidu.com/s/1nv6ma1b 3.IOS手机屏幕共享 htt ...
- 测试Oracle 11gr2 RAC 非归档模式下,offline drop数据文件后的数据库的停止与启动测试全过程
测试Oracle 11gr2 RAC 非归档模式下,offline drop数据文件后的数据库的停止与启动测试全过程 最近系统出现问题,由于数据库产生的日志量太大无法开启归档模式,导致offline的 ...
- Mybatis关联查询(嵌套查询)
上一篇文章介绍了基于Mybatis对数据库的增.删.改.查.这一篇介绍下关联查询(join query). 三张表:user article blog 表的存储sql文件: /* Navicat My ...
- Mybatis 学习笔记1 不整合Spring的方式使用mybatis
两种方式都包含了: package com.test.mybatis; import java.util.List; import org.apache.ibatis.io.Resources; im ...
- 在SQL SERVER中实现RSA加解密函数(第二版)
/*************************************************** 作者:herowang(让你望见影子的墙) 日期:2010.1.5 注: 转载请保留此信息 更 ...
- Android UI 之实现多级列表TreeView
所谓TreeView就是在Windows中常见的多级列表树,在Android中系统只默认提供了ListView和ExpandableListView两种列表,最多只支持到二级列表的实现,所以如果想要实 ...
- jquery 使用需要注意
jquery选择器,层选择器等多个选择器,jquery生成对象,jquery遍历对象, jquery ajax调用不要进行方法封装返回值方式调用,会取不到值. jquery使用要注意很多细节点才能将其 ...
- 表单验证——jquery validate使用说明【另一个教程】
[参考:http://www.tuicool.com/articles/y6fyme] jQuery Validate jQuery Validate 插件为表单提供了强大的验证功能,让客户端表单验证 ...
- 解决Winform应用程序中窗体背景闪烁的问题
本文转载:https://my.oschina.net/Tsybius2014/blog/659742 我的操作系统是Win7,使用的VS版本是VS2012,文中的代码都是C#代码. 这几天遇到一个问 ...