sql基础语句大杂烩
(坑Open Office,这排版。。。)
1、distinct列出不同值,过滤掉相同的值
例:company中有两个相同的值比如(apple和apple)时,则只取出一个值
SELECTDISTINCTCompany FROM Orders
只会列出一个apple 2、通配符
|
通配符 |
描述 |
|---|---|
|
% |
替代一个或多个字符 |
|
_ |
仅替代一个字符 |
|
[charlist] |
字符列中的任何单一字符 |
|
[^charlist] 或者 [!charlist] |
不在字符列中的任何单一字符 |
3、BETWEEN
操作符
操作符 BETWEEN
... AND 会选取介于两个值之间的数据范围。这些值可以是数值、文本或者日期。
例:SELECT
* FROM Persons WHERE LastName BETWEEN
'Adams' AND 'Carter'
注:mysql会将adams与carter都放入结果集。
如需使用上面的例子显示范围之外的人,请使用
NOT 操作符:
SELECT * FROM Persons
WHERE LastName
NOTBETWEEN 'Adams' AND 'Carter'
4、表连接
(1)LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行
例:
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons LEFT JOIN Orders ON Persons.Id_P=Orders.Id_P ORDER BY Persons.LastName
说明:LEFT JOIN 关键字会从左表 (Persons) 那里返回所有的行,即使在右表 (Orders) 中没有匹配的行。 左表会全部列出,右表有则列出,没有则空。
(2)RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行
例:
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons RIGHT JOIN Orders ON Persons.Id_P=Orders.Id_P ORDER BY Persons.LastName
说明:RIGHT JOIN 关键字会从右表 (Orders) 那里返回所有的行,即使在左表 (Persons) 中没有匹配的行。
(3)FULL JOIN: 只要其中一个表中存在匹配,就返回行
例:
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons FULL JOIN Orders ON Persons.Id_P=Orders.Id_P ORDER BY Persons.LastName
说明:FULL JOIN 关键字会从左表 (Persons) 和右表 (Orders) 那里返回所有的行。如果 "Persons" 中的行在表 "Orders" 中没有匹配,或者如果 "Orders" 中的行在表 "Persons" 中没有匹配,这些行同样会列出。
(4)JOIN 、 INNER JOIN:内连接,在表中存在至少一个匹配时,INNER JOIN 关键字返回行
例:
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons INNER JOIN Orders ON Persons.Id_P = Orders.Id_P ORDER BY Persons.LastName
说明:INNER JOIN 关键字在表中存在至少一个匹配时返回行。如果 "Persons" 中的行在 "Orders" 中没有匹配,就不会列出这些行。
5、union
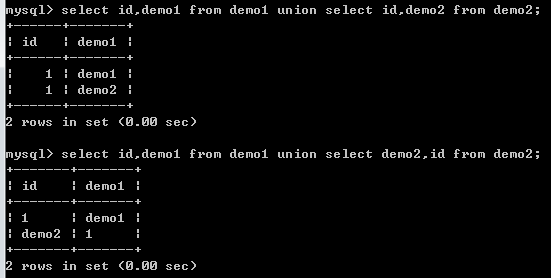
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。(w3c上:列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。 但是依据实际操作如下图好像不需要数据类型相同,待深究!)
union会过滤掉重复值,union all不会
例:SELECT E_Name FROM Employees_ChinaUNIONSELECT E_Name FROM Employees_USA
SELECT E_Name FROM Employees_ChinaUNION ALLSELECT E_Name FROM Employees_USA
当两张表结果集对应的列名不同时,结果集中列名为第一张表列名
6、SELECT
INTO
SELECT
INTO 语句从一个表中选取数据,然后把数据插入另一个表中。
SELECT
INTO 语句常用于创建表的备份复件或者用于对记录进行存档。
Select
into 可以加where条件
例1、(1)SELECT
* INTO
Persons_backup FROM Persons备份整张表
(2)SELECT
* INTO
Persons IN
'Backup.mdb' FROM Persons 向另外一个数据库中copy表
例2、SELECT
LastName,FirstName INTO
Persons_backup FROM Persons只拷贝某些列
例3、SELECT
Persons.LastName,Orders.OrderNo INTO
Persons_Order_Backup FROM
Persons INNER
JOIN
Orders ON
Persons.Id_P=Orders.Id_P 利用表连接copy表。
7、表约束(Constraints)
(1)not
null
(2)PRIMARY
KEY 拥有自动定义的
UNIQUE
约束
例:CREATE
TABLE Persons(
Id_P
int NOT NULL,
LastName
varchar(255) NOT NULL,
FirstName
varchar(255),
Address
varchar(255),
City
varchar(255),
UNIQUE
(Id_P)
)
如果需要命名
UNIQUE
约束,以及为多个列定义
UNIQUE
约束,请使用下面的
SQL
语法:
CREATE TABLE Persons(
Id_P int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
CONSTRAINT uc_PersonID UNIQUE (Id_P,LastName)
)
当表已被创建时,如需在 "Id_P" 列创建 UNIQUE 约束,请使用下列 SQL:
ALTER TABLE PersonsADD UNIQUE (Id_P)
如需命名 UNIQUE 约束,并定义多个列的 UNIQUE 约束,请使用下面的 SQL 语法:
ALTER TABLE PersonsADD CONSTRAINT uc_PersonID UNIQUE (Id_P,LastName)
如需撤销 UNIQUE 约束,请使用下面的 SQL: ALTER TABLE PersonsDROP INDEX uc_PersonID
(3)SQL PRIMARY KEY约束(主键)
CREATE TABLE Persons(
Id_P int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (Id_P)
)
如果需要命名 PRIMARY KEY 约束,以及为多个列定义 PRIMARY KEY 约束,请使用下面的 SQL 语法:
CREATE TABLE Persons(
Id_P int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
CONSTRAINT pk_PersonID PRIMARY KEY (Id_P,LastName)
)
如果在表已存在的情况下为 "Id_P" 列创建 PRIMARY KEY 约束,请使用下面的 SQL:
ALTER TABLE PersonsADD PRIMARY KEY (Id_P)如果需要命名 PRIMARY KEY 约束,以及为多个列定义 PRIMARY KEY 约束,请使用下面的 SQL 语法:
ALTER TABLE PersonsADD CONSTRAINT pk_PersonID PRIMARY KEY (Id_P,LastName)
如果使用ALTER TABLE语句添加主键,必须把主键列声明为不包含NULL值(在表首次创建时)。如需撤销PRIMARY KEY约束,请使用下面的SQL:ALTER TABLE PersonsDROP PRIMARY KEY
(4)SQL FOREIGN KEY约束(外键)
一个表中的FOREIGN KEY指向另一个表中的PRIMARY KEY。
例:
CREATE TABLE Orders(
Id_O int NOT NULL,
OrderNo int NOT NULL,
Id_P int,
PRIMARY KEY (Id_O),
FOREIGN KEY (Id_P) REFERENCES Persons(Id_P)
)
(5)SQL CHECK 约束
CHECK 约束用于限制列中的值的范围。
如果对单个列定义 CHECK 约束,那么该列只允许特定的值。
如果对一个表定义 CHECK 约束,那么此约束会在特定的列中对值进行限制。
例:
CREATE TABLE Persons(
Id_P int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
CHECK (Id_P>0)
)8、create index(创建索引)
CREATE INDEX index_nameON table_name (column_name)
创建唯一索引:CREATE UNIQUE INDEX index_name ON table_name (column_name)
创建一个名为PersonIndex的索引 CREATE INDEX PersonIndex ON Person (LastName)
如果希望以降序索引某个列中的值,您可以在列名称之后添加保留字 DESC: CREATE INDEX PersonIndex ON Person (LastName DESC)
希望索引不止一个列,您可以在括号中列出这些列的名称,用逗号隔开: CREATE INDEX PersonIndex ON Person (LastName, FirstName)
删除索引:ALTER TABLE table_name DROP INDEX index_name
9、ALTER语句
ALTER TABLE 语句用于在已有的表中添加、修改或删除列。
添加列:ALTER TABLE table_name ADD column_name datatype
删除列:ALTER TABLE table_name DROP COLUMN column_name
要改变表中列的数据类型,请使用下列语法: ALTER TABLE table_name ALTER COLUMN column_name datatype
sql基础语句大杂烩的更多相关文章
- T——SQL基础语句(定义变量,赋值,取值,分支,循环,存储过程)
T--SQL基础语句 1.定义变量: declare @变量名 数据类型 ; declare @a int ; declare @b nvarchar(10) ; 2.赋值: 法1:set @变量名 ...
- SQL基础语句(详解版)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/CZXY18ji/article/deta ...
- sql基础语句50条
curdate() 获取当前日期 年月日 curtime() 获取当前时间 时分秒 sysdate() 获取当前日期+时间 年月日 时分秒 */ order by bonus desc limit ( ...
- sql 基础语句
一.基础 2 31.说明:创建数据库 4Create DATABASE database-name 5 62.说明:删除数据库 7drop database dbname 8 93.说 ...
- SQL基础语句入门
SQL语句入门 起因 学校开设数据库相关的课程了,打算总结一篇关于基础SQL语句的文章. SQL介绍 SQL最早版本是由IBM开发的,一直发展到至今. SQL语言有如下几个部分: 数据定义语言DDL: ...
- SQL 基础语句整理
SQL教程 SELECT 语句 SELECT * FROM 表名称 DISTINCT 语句 SELECT DISTINCT 列名称 FROM 表名称 SELECT LastName,FirstName ...
- sql基础语句(技巧)
1.压缩数据库 dbcc shrinkdatabase(dbname) 2.转移数据库给新用户已存在用户权限 exec sp_change_users_login'update_one','newga ...
- SQL基础语句(提升)
1.复制表(只复制结构,源表名:a 新表名:b) select * into b from a where 1<>1 2.拷贝表 insert into b(a,b,c) select d ...
- sql基础语句
1.创建数据库 create database 数据库名称 2.删除数据库 drop database 数据库名称 3.备份sql server 创建备份数据的device use master e ...
随机推荐
- Android图片复制
public void saveImage2Phone(SlideShowImage image){ String imagePath; if(Environment.getExternalStora ...
- flash 定义二维数组
一种二维数组的定义方法 //假设二维数组为 [5][7]var xn:Number = 5;var yn:Number = 7; //定义一数值变量var temp:Number = 0; ...
- 积累一点ctf需要掌握的常见脚本知识
1.暴力破解压缩包. 2.利用像素点还原图片. from PIL import Image import re if __name__ == '__main__': x = 887 //将像素点个数进 ...
- CentOS7 服务器 JDK+TOMCAT+MYSQL+redis 安装日志
防火墙配置(参考 CentOS7安装iptables防火墙) 检查是否安装iptables #先检查是否安装了iptables service iptables status #安装iptables ...
- Windows 自动关机/定时关机 命令 shuntdown
一 .倒计时关机: 指定系统在10分钟后自动关闭:点击"开始→运行",输入命令"Shutdown -s -t 60"(注意:引号不输入,参数之间有空格 ...
- hdu 3951 - Coin Game(找规律)
这道题是有规律的博弈题目,,, 所以我们只需要找出规律来就ok了 牛人用sg函数暴力找规律,菜鸟手工模拟以求规律...[牢骚] if(m>=2) { if(n<=m) {first第一口就 ...
- JAVA学习博客---2015-6
JAVA核心技术卷一第一遍看得差不多了,应该是五月初开始看的,用了两个月的中午时间看完的,一共七百多页,接下来还是需要再看一遍,不懂的还是有很多. JAVA和C++一样是面向对象OOP的语言,不同于命 ...
- spring 装配核心笔记
(1)自动装配 开启ComponentScan(自动扫描), 通过在类使用注解@Component(默认bean id为类名第一个字符小写), 使用@Autowired实现属性,构造函数,成员函数的自 ...
- [ASE][Daily Scrum]11.30
燃烧图的页面进不去了…… 小结一下吧,sprint2的内容已经基本完成了, 推迟到之后进行的任务: ·地图块的刷新 一些bug尚未修复不过不是特别重要所以也推到后面了, 之后两个sprint主要会增加 ...
- ddms(基于 Express 的表单管理系统)源码学习
ddms是基于express的一个表单管理系统,今天抽时间看了下它的代码,其实算不上源码学习,只是对它其中一些小的开发技巧做一些记录,希望以后在项目开发中能够实践下. 数据层封装 模块只对外暴露mod ...