python基础知识9——模块2——常见内置模块
http://www.cnblogs.com/wupeiqi/articles/5501365.html
内置模块
内置模块是Python自带的功能,在使用内置模块相应的功能时,需要【先导入】再【使用】
1、sys
用于提供对Python解释器相关的操作:

1 sys.argv 命令行参数List,第一个元素是程序本身路径
2 sys.exit(n) 退出程序,正常退出时exit(0)
3 sys.version 获取Python解释程序的版本信息
4 sys.maxint 最大的Int值
5 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
6 sys.platform 返回操作系统平台名称
7 sys.stdin 输入相关
8 sys.stdout 输出相关
9 sys.stderror 错误相关
结果:从1%一直变化到99%
使用模块sys.argv


这个文件只能用终端运行,因为argv变量
sys模块有一个argv变量,用list存储了命令行的所有参数。argv至少有一个元素,因为第一个参数永远是该.py文件的名称,例如:
运行python3 hello.py获得的sys.argv就是['hello.py'];
先解释什么是命令行参数。
$ Python --version
Python 2.7.6
这里的--version 就是命令行参数。如果你使用 Python --help 可以看到更多:
1 $ Python --help
2 usage: Python [option] ... [-c cmd | -m mod | file | -] [arg] ...
3 Options and arguments (and corresponding environment variables):
4 -B : don't write .py[co] files on import; also PYTHONDONTWRITEBYTECODE=x
5 -c cmd : program passed in as string (terminates option list)
6 -d : debug output from parser; also PYTHONDEBUG=x
7 -E : ignore PYTHON* environment variables (such as PYTHONPATH)
8 -h : print this help message and exit (also --help)
9 -i : inspect interactively after running script; forces a prompt even
10 if stdin does not appear to be a terminal; also PYTHONINSPECT=x
11 -m mod : run library module as a script (terminates option list)
12 -O : optimize generated bytecode slightly; also PYTHONOPTIMIZE=x
13 -OO : remove doc-strings in addition to the -O optimizations
14 -R : use a pseudo-random salt to make hash() values of various types be
15 unpredictable between separate invocations of the interpreter, as
16 a defense against denial-of-service attacks
只选择了部分内容摆在这里。所看到的如 -B, -h 之流,都是参数,比如 Python -h,其功能同上。那么 -h 也是命令行参数。
1 if __name__=='__main__':
2 test()
__name__ 是当前模块名,当模块被直接运行时模块名为 __main__ 。这句话的意思就是,当模块被直接运行时,代码将被运行,当模块是被导入时,代码不被运行。
更好的例子是为了代码重用。比如你现在写了一些程序,都存在单独的py文件里。有一天你突然想用1.py文件中的一个写好的函数来处理现在这个文件中的事物,你当然可以拷贝过来,你也可以把那个文件加上if __name__ == "__main__":这句话,然后从你现在写的文件中import 1就可以用1.py中的函数了。
模块搜索路径sys.path
默认情况下,Python解释器会搜索当前目录、所有已安装的内置模块和第三方模块,搜索路径存放在sys模块的path变量中:
1 >>> import sys 2 >>> sys.path 3 ['', '/usr/local/lib/python3.5/dist-packages/setuptools-18.1-py3.5.egg', '/usr/local/lib/python3.5/dist-packages/pip-7.1.0-py3.5.egg', '/usr/lib/python35.zip', '/usr/lib/python3.5', '/usr/lib/python3.5/plat-x86_64-linux-gnu', '/usr/lib/python3.5/lib-dynload', '/usr/local/lib/python3.5/dist-packages', '/usr/lib/python3/dist-packages']
2、os
提供对操作系统进行调用的接口:
1 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
2 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
3 os.curdir 返回当前目录: ('.')
4 os.pardir 获取当前目录的父目录字符串名:('..')
5 os.makedirs('dir1/dir2') 可生成多层递归目录
6 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
7 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
8 os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
9 os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
10 os.remove() 删除一个文件
11 os.rename("oldname","new") 重命名文件/目录
12 os.stat('path/filename') 获取文件/目录信息
13 os.sep 操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
14 os.linesep 当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
15 os.pathsep 用于分割文件路径的字符串
16 os.name 字符串指示当前使用平台。win->'nt'; Linux->'posix'
17 os.system("bash command") 运行shell命令,直接显示
18 os.environ 获取系统环境变量
19 os.path.abspath(path) 返回path规范化的绝对路径
20 os.path.split(path) 将path分割成目录和文件名二元组返回
21 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
22 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
23 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
24 os.path.isabs(path) 如果path是绝对路径,返回True
25 os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
26 os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
27 os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
28 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
29 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
3、hashlib
用于加密相关的操作,代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
1 import hashlib
2
3 # ######## md5 ########
4 hash = hashlib.md5()
5 # help(hash.update)
6 hash.update('admin')
7 print(hash.hexdigest()) 21232f297a57a5a743894a0e4a801fc3
1 zh@zh-Lenovo-G470 ~ $ python #进入环境
2 Python 2.7.12 (default, Nov 19 2016, 06:48:10)
3 [GCC 5.4.0 20160609] on linux2
4 Type "help", "copyright", "credits" or "license" for more information.
5 >>> import hashlib #导入模块
6 >>> hash = hashlib.md5() #加密方法
7 >>> hash.update("Hello") #加密的字符串
8 >>> hash.update("It's me")
9 >>> hash.digest() #以二进制格式
10 ']\xde\xb4{/\x92Z\xd0\xbf$\x9cR\xe3Br\x8a'
11 >>> hash.hexdigest() #十六进制
12 '5ddeb47b2f925ad0bf249c52e342728a'
13 >>>
10
11 ######## sha1 ########
12
13 hash = hashlib.sha1()
14 hash.update('admin')
15 print(hash.hexdigest())
16
结果:d033e22ae348aeb5660fc2140aec35850c4da997
17 # ######## sha256 ########
18
19 hash = hashlib.sha256()
20 hash.update('admin')
21 print(hash.hexdigest())
22
23 结果:8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918 24 # ######## sha384 ########
25
26 hash = hashlib.sha384()
27 hash.update('admin')
28 print(hash.hexdigest())
29
结果:9ca694a90285c034432c9550421b7b9dbd5c0f4b6673f05f6dbce58052ba20e4248041956ee8c9a2ec9f10290cdc0782
30 # ######## sha512 ########
31
32 hash = hashlib.sha512()
33 hash.update('admin')
34 print(hash.hexdigest()) 结果:c7ad44cbad762a5da0a452f9e854fdc1e0e7a52a38015f23f3eab1d80b931dd472634dfac71cd34ebc35d16ab7fb8a90c81f975113d6c7538dc69dd8de9077ec
以上加密算法虽然依然非常厉害,但有时存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
1 import hashlib
2
3 hash = hashlib.md5('898oaFs09f') # 这里把自定义的信息加上然后再进行加密
4 hash.update('shuaige')
5 print hash.hexdigest() 结果:6d1233c4e14a52379c6bc7a045411dc3
python内置还有一个 hmac 模块,它内部对我们创建 key 和 内容 进行进一步的处理,然后再加密
1 import hmac
2 h = hmac.new('shuaige')
3 h.update('hello laoshi')
4 print h.hexdigest() 结果:44a40c9eb3760938112688e93ec68575
4、random
1 import random
2
3 print(random.random())
4 print(random.randint(1, 2))
5 print(random.randrange(1, 10)) 结果:注意每一运行结果在范围内随机
0.265829883567
2
6
结果:注意每次执行都不一样
X2SV
68LK
5、re
python中re模块提供了正则表达式相关操作
次数
1 '.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
2 '^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
3 '$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以
4 '*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
5 '+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
6 '?' 匹配前一个字符1次或0次
7 '{m}' 匹配前一个字符m次
8 '{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
9 '|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
10 '(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c
11 字符
13 '\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的
14 '\Z' 匹配字符结尾,同$
15 '\d' 匹配数字0-9
16 '\D' 匹配非数字
17 '\w' 匹配[A-Za-z0-9]
18 '\W' 匹配非[A-Za-z0-9]
19 's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t'
20
21 '(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city") 结果{'province': '3714', 'city': '81', 'birthday': '1993'}
22
语法:
1 import re #导入模块名
2
3 p = re.compile("^[0-9]") #生成要匹配的正则对象 , ^代表从开头匹配,[0-9]代表匹配0至9的任意一个数字, 所以这里的意思是对传进来的字符串进行匹配,如果这个字符串的开头第一个字符是数字,就代表匹配上了
4
5 m = p.match('14534Abc') #按上面生成的正则对象 去匹配 字符串, 如果能匹配成功,这个m就会有值, 否则m为None<br><br>if m: #不为空代表匹配上了
6 print(m.group()) #m.group()返回匹配上的结果,此处为1,因为匹配上的是1这个字符<br>else:<br> print("doesn't match.")<br>
上面的第2 和第3行也可以合并成一行来写:
1 m = p.match("^[0-9]",'14534Abc')
效果是一样的,区别在于,第一种方式是提前对要匹配的格式进行了编译(对匹配公式进行解析),这样再去匹配的时候就不用在编译匹配的格式,第2种简写是每次匹配的时候 都 要进行一次匹配公式的编译,所以,如果你需要从一个5w行的文件中匹配出所有以数字开头的行,建议先把正则公式进行编译再匹配,这样速度会快点。
正则表达式常用的5种操作
1.match
1 # match,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
2
3
4 match(pattern, string, flags=0)
5 # pattern: 正则模型
6 # string : 要匹配的字符串
7 # falgs : 匹配模式
8 X VERBOSE Ignore whitespace and comments for nicer looking RE's.
9 I IGNORECASE Perform case-insensitive matching.
10 M MULTILINE "^" matches the beginning of lines (after a newline)
11 as well as the string.
12 "$" matches the end of lines (before a newline) as well
13 as the end of the string.
14 S DOTALL "." matches any character at all, including the newline.
15
16 A ASCII For string patterns, make \w, \W, \b, \B, \d, \D
17 match the corresponding ASCII character categories
18 (rather than the whole Unicode categories, which is the
19 default).
20 For bytes patterns, this flag is the only available
21 behaviour and needn't be specified.
22
23 L LOCALE Make \w, \W, \b, \B, dependent on the current locale.
24 U UNICODE For compatibility only. Ignored for string patterns (it
25 is the default), and forbidden for bytes patterns.
2.search
1 # search,浏览整个字符串去匹配第一个,匹配整个字符串,直到找到一个匹配,未匹配成功返回None
2 # search(pattern, string, flags=0)
3.findall
1 # findall,找到所有要匹配的字符并返回列表格式
获取非重复的匹配列表;如果有一个组则以列表形式返回,且每一个匹配均是字符串;如果模型中有多个组,则以列表形式返回,且每一个匹配均是元祖;
2 # 空的匹配也会包含在结果中
3 #findall(pattern, string, flags=0)
1 >>>m = re.findall("[0-9]", "alex1rain2jack3helen rachel8")
2 >>>print(m)<br>
3 输出:['1', '2', '3', '8']
4.sub
1 # sub,替换匹配成功的指定位置字符串
2
3 sub(pattern, repl, string, count=0, flags=0)
4 # pattern: 正则模型
5 # repl : 要替换的字符串或可执行对象
6 # string : 要匹配的字符串
7 # count : 指定匹配个数
8 # flags : 匹配模式
1 m=re.sub("[0-9]","|", "alex1rain2jack3helen rachel8",count=2 )
2 print(m)
3 输出:alex|rain|jack3helen rachel8
5.split
1 # split, 将匹配到的格式当做分割点对字符串分割成列表
2
3 split(pattern, string, maxsplit=0, flags=0)
4 # pattern: 正则模型
5 # string : 要匹配的字符串
6 # maxsplit:指定分割个数
7 # flags : 匹配模式
1 >>>m = re.split("[0-9]", "alex1rain2jack3helen rachel8")
2 >>>print(m)
3 输出: ['alex', 'rain', 'jack', 'helen rachel', '']
常见几个正则例子
匹配手机号
匹配IP V4
分组匹配地址
匹配email
6、序列化
http://wiki.jikexueyuan.com/project/start-learning-python/227.html
Python中用于序列化的两个模块
- json 用于【字符串】和 【python基本数据类型】 间进行转换
- pickle 用于【python特有的类型】 和 【python基本数据类型】间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
json dumps把数据类型转换成字符串 dump把数据类型转换成字符串并存储在文件中 loads把字符串转换成数据类型 load把文件打开把字符串转换成数据类型
pickle同理
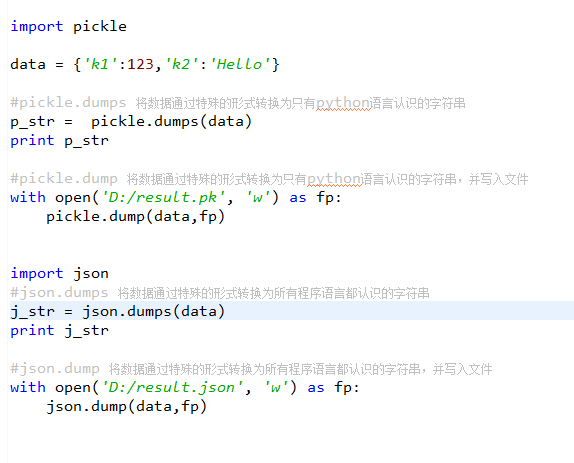
1 #!/usr/bin/env python
2 #-*- coding:utf-8 -*-
3 __author__ = 'zhenghao'
4
5
6 import json
7
8 test_dic = {'name':'zhenghao','age':18}
9 print '未dumps前类型为:',type(test_dic)
10 #dumps 将数据通过特殊的形式转换为所有程序语言都识别的字符串
11 json_str = json.dumps(test_dic)
12 print 'dumps后的类型为:',type(json_str)
13
14 #loads 将字符串通过特殊的形式转为python是数据类型
15
16 new_dic = json.loads(json_str)
17 print '重新loads加载为数据类型:',type(new_dic)
18
19 print '*' * 50
20
21 #dump 将数据通过特殊的形式转换为所有语言都识别的字符串并写入文件
22 with open('test.txt','w') as openfile:
23 json.dump(new_dic,openfile)
24 print 'dump为文件完成!!!!!'
25 #load 从文件读取字符串并转换为python的数据类型
26
27 with open('test.txt','rb') as loadfile:
28 load_dic = json.load(loadfile)
29 print 'load 并赋值给load_dic后的数据类型:',type(load_dic)
结果:
1 未dumps前类型为: <type 'dict'>
2 dumps后的类型为: <type 'str'>
3 重新loads加载为数据类型: <type 'dict'>
4 **************************************************
5 dump为文件完成!!!!!
6 load 并赋值给load_dic后的数据类型: <type 'dict'>
7
8 Process finished with exit code 0
7、Configparser
用于生成和修改常见配置文档,当前模块的名称在 python 3.x 版本中变更为 configparser,其本质上是利用open来操作文件。
来看一个好多软件的常见文档格式如下:
1 # 注释1
2 ; 注释2
3
4 [section1] # 节点
5 k1 = v1 # 值
6 k2:v2 # 值
7
8 [section2] # 节点
9 k1 = v1 # 值
10
11 指定格式
1 [DEFAULT] # 节点 #全局写在每个section下面,下面读时从循环能看出来
2 ServerAliveInterval = 45
3 Compression = yes
4 CompressionLevel = 9
5 ForwardX11 = yes
6
7 [bitbucket.org]
8 User = hg
9 10 [topsecret.server.com]
11 Port = 50022
12 ForwardX11 = no
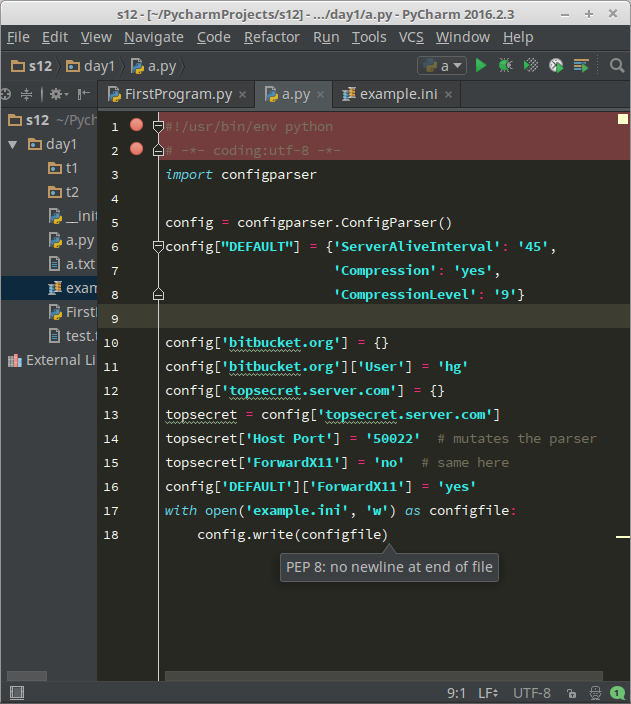
如果想用python生成一个这样的文档怎么做呢?
1 import configparser
2
3 config = configparser.ConfigParser()
4 config["DEFAULT"] = {'ServerAliveInterval': '45',
5 'Compression': 'yes',
6 'CompressionLevel': '9'}
7
8 config['bitbucket.org'] = {}
9 config['bitbucket.org']['User'] = 'hg'
10 config['topsecret.server.com'] = {}
11 topsecret = config['topsecret.server.com']
12 topsecret['Host Port'] = '50022' # mutates the parser
13 topsecret['ForwardX11'] = 'no' # same here
14 config['DEFAULT']['ForwardX11'] = 'yes'
15 with open('example.ini', 'w') as configfile:
16 config.write(configfile)

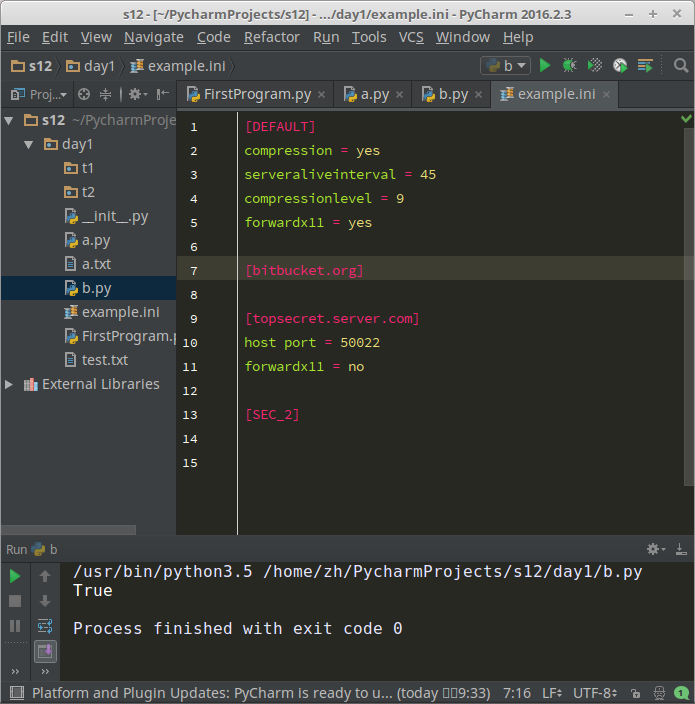
写完了还可以再读出来哈。
1 # coding=utf-8
2 import ConfigParser
3
4 config = ConfigParser.ConfigParser()
5 config.read('example.ini')
6
7 # ########## 读 ##########
8 # secs = config.sections() #获取所有节点
9 # print (secs)
10 # options = config.options('bitbucket.org')#获取指定节点下所有的建
11 # print (options)
12 '''
13 结果:
14 /usr/bin/python2.7 /home/zh/PycharmProjects/s12/day1/b.py
15 ['bitbucket.org', 'topsecret.server.com']
16 ['user', 'compression', 'serveraliveinterval', 'compressionlevel', 'forwardx11']
17
18 Process finished with exit code 0
19
20 '''
21
22 # item_list = config.items('bitbucket.org')#获取指定节点下所有的键值对
23 # print item_list
24 '''
25 结果:
26 [('compression', 'yes'), ('serveraliveinterval', '45'), ('compressionlevel', '9'), ('forwardx11', 'yes'), ('user', 'hg')]
27
28 '''
29
30 #val = config.get('bitbucket.org','forwardx11') #获取指定节点下指定key的值
31 # val = config.getboolean('bitbucket.org','forwardx11')
32 # print (val)
33 '''
34 结果:
35 [('compression', 'yes'), ('serveraliveinterval', '45'), ('compressionlevel', '9'), ('forwardx11', 'yes'), ('user', 'hg')]
36 True
37
38 '''
configparser增删改查语法
1.检查、删除、添加节点

2.检查、删除、设置指定组内的键值对
8、XML
http://wiki.jikexueyuan.com/project/start-learning-python/226.html
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
1 <?xml version="1.0"?>
2 <data> #xml的根节点可随便起名
3 <country name="Liechtenstein"> #子节点,相当于json里面的k,其实都是字典套字典,xml占用空间比json大
4 <rank updated="yes">2</rank> #节点属性和值
5 <year>2008</year>
6 <gdppc>141100</gdppc>
7 <neighbor name="Austria" direction="E"/>
8 <neighbor name="Switzerland" direction="W"/>
9 </country>
10 <country name="Singapore"> #注意,这里和上面的不一样多,因为都是可以自定义的,多少都行
11 <rank updated="yes">5</rank>
12 <year>2011</year>
13 <gdppc>59900</gdppc>
14 <neighbor name="Malaysia" direction="N"/>
15 </country>
16 <country name="Panama">
17 <rank updated="yes">69</rank>
18 <year>2011</year>
19 <gdppc>13600</gdppc>
20 <neighbor name="Costa Rica" direction="W"/>
21 <neighbor name="Colombia" direction="E"/>
22 </country>
23 </data>
xml协议在各个语言里的都是支持的,在python中可以用以下模块操作xml
1 # coding=utf-8
2 import xml.etree.ElementTree as ET
3
4 tree = ET.parse("test.xml") # 直接解析xml文件
5 root = tree.getroot() # 获取xml文件的根节点
6 print(root.tag)
7
8 # 遍历xml文档
9 for child in root:
10 print(child.tag, child.attrib)
11 for i in child:
12 print(i.tag, i.text)
13
14 # 只遍历year 节点
15 for node in root.iter('year'):
16 print(node.tag, node.text)
结果:
1 data
2 country {'name': 'Liechtenstein'}
3 rank 2
4 year 2008
5 gdppc 141100
6 neighbor None
7 neighbor None
8 country {'name': 'Singapore'}
9 rank 5
10 year 2011
11 gdppc 59900
12 neighbor None
13 country {'name': 'Panama'}
14 rank 69
15 year 2011
16 gdppc 13600
17 neighbor None
18 neighbor None
19 year 2008
20 year 2011
21 year 2011
修改和删除xml文档内容
1 import xml.etree.ElementTree as ET
2
3 tree = ET.parse("xmltest.xml")
4 root = tree.getroot()
5
6 #修改
7 for node in root.iter('year'):
8 new_year = int(node.text) + 1
9 node.text = str(new_year)
10 node.set("updated","yes")
11
12 tree.write("xmltest.xml")
13
14
15 #删除node
16 for country in root.findall('country'):
17 rank = int(country.find('rank').text)
18 if rank > 50:
19 root.remove(country)
20
21 tree.write('output.xml')
自己创建xml文档
1 import xml.etree.ElementTree as ET
2
3
4 new_xml = ET.Element("namelist")
5 name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
6 age = ET.SubElement(name,"age",attrib={"checked":"no"})
7 sex = ET.SubElement(name,"sex")
8 sex.text = '33'
9 name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
10 age = ET.SubElement(name2,"age")
11 age.text = '19'
12
13 et = ET.ElementTree(new_xml) #生成文档对象
14 et.write("test.xml", encoding="utf-8",xml_declaration=True)
15
16 ET.dump(new_xml) #打印生成的格式
1、解析XML
2、操作XML
XML格式类型是节点嵌套节点,对于每一个节点均有以下功能,以便对当前节点进行操作:
由于 每个节点 都具有以上的方法,并且在上一步骤中解析时均得到了root(xml文件的根节点),so 可以利用以上方法进行操作xml文件。
a. 遍历XML文档的所有内容
b、遍历XML中指定的节点
c、修改节点内容
由于修改的节点时,均是在内存中进行,其不会影响文件中的内容。所以,如果想要修改,则需要重新将内存中的内容写到文件。
d、删除节点
3、创建XML文档
由于原生保存的XML时默认无缩进,如果想要设置缩进的话, 需要修改保存方式:
4、命名空间
详细介绍,猛击这里
9. PyYAML模块
Python也可以很容易的处理ymal文档格式,只不过需要安装一个模块,参考文档:http://pyyaml.org/wiki/PyYAMLDocumentation
urllib模块
http://wiki.jikexueyuan.com/project/start-learning-python/225.html
10.requests
Python标准库中提供了:urllib等模块以供Http请求,但是,它的 API 太渣了。它是为另一个时代、另一个互联网所创建的。它需要巨量的工作,甚至包括各种方法覆盖,来完成最简单的任务。
注:更多见Python官方文档:https://docs.python.org/3.5/library/urllib.request.html#module-urllib.request
Requests 是使用 Apache2 Licensed 许可证的 基于Python开发的HTTP 库,其在Python内置模块的基础上进行了高度的封装,从而使得Pythoner进行网络请求时,变得美好了许多,使用Requests可以轻而易举的完成浏览器可有的任何操作。
1、安装模块
pip3 install requests
2、使用模块
更多requests模块相关的文档见:http://cn.python-requests.org/zh_CN/latest/
3、Http请求和XML实例
实例:检测QQ账号是否在线
实例:查看火车停靠信息
注:更多接口猛击这里
11、logging
错误调试与测试
1 try:
2 arr = [1,2,3]
3 a = arr[8]
4 except ZeroDivisionError as e:
5 print e
6
7 #断言
8 def foo(s):
9 n = int(s)
10 assert n != 0
11 return 10 / n
12
13 def main():
14 print foo('0')
15
16 main()
用于便捷记录日志且线程安全的模块,很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误、警告等信息输出,python的logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志,logging的日志可以分为 debug(), info(), warning(), error() and critical() 5个级别,下面我们看一下怎么用。
1、单文件日志
1 import logging
2
3
4 logging.basicConfig(filename='log.log', #文件名
5 #基本配置 format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', #格式
6 datefmt='%Y-%m-%d %H:%M:%S %p',
7 level=10)
8
9 logging.debug('debug')
10 logging.info('info')
11 logging.warning('warning')
12 logging.error('error')
13 logging.critical('critical')
14 logging.log(10,'log')
日志等级:
| Level | When it’s used |
|---|---|
DEBUG |
Detailed information, typically of interest only when diagnosing problems. 详细信息,通常仅在诊断问题时感兴趣。 |
INFO 信息 |
Confirmation that things are working as expected. 确认事情按预期工作。 |
WARNING |
An indication that something unexpected happened, or indicative of some problem in the near future (e.g. ‘disk space low’). The software is still working as expected. 表示意外发生,或表示在不久的将来出现一些问题(例如“磁盘空间低”)。 该软件仍然按预期工作。 |
ERROR |
Due to a more serious problem, the software has not been able to perform some function. 由于更严重的问题,软件无法执行某些功能。 |
|
CRITICAL 危急,紧要,批评 |
A serious error, indicating that the program itself may be unable to continue running. 一个严重的错误,指示程序本身可能无法继续运行。 |
CRITICAL = 50
FATAL = CRITICAL
ERROR = 40
WARNING = 30
WARN = WARNING
INFO = 20
DEBUG = 10
NOTSET = 0
注:只有【当前写等级】大于【日志等级】时,日志文件才被记录。
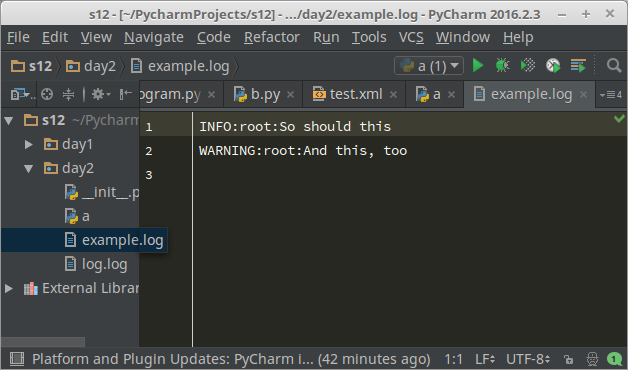
如果想把日志写到文件里,也很简单
1 import logging
2
3 logging.basicConfig(filename='example.log',level=logging.INFO)
4 logging.debug('This message should go to the log file')
5 logging.info('So should this')
6 logging.warning('And this, too')
感觉上面的日志格式忘记加上时间啦,日志不知道时间怎么行呢,下面就来加上!
1 import logging
2 logging.basicConfig(format='%(asctime)s %(message)s', datefmt='%m/%d/%Y %I:%M:%S %p')
3 logging.warning('is when this event was logged.')
结果:
12/05/2016 09:46:32 AM is when this event was logged.
日志记录格式:
|
%(name)s |
Logger的名字 |
|
%(levelno)s |
数字形式的日志级别 |
|
%(levelname)s |
文本形式的日志级别 |
|
%(pathname)s |
调用日志输出函数的模块的完整路径名,可能没有 |
|
%(filename)s |
调用日志输出函数的模块的文件名 |
|
%(module)s |
调用日志输出函数的模块名 |
|
%(funcName)s |
调用日志输出函数的函数名 |
|
%(lineno)d |
调用日志输出函数的语句所在的代码行 |
|
%(created)f |
当前时间,用UNIX标准的表示时间的浮 点数表示 |
|
%(relativeCreated)d |
输出日志信息时的,自Logger创建以 来的毫秒数 |
|
%(asctime)s |
字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
|
%(thread)d |
线程ID。可能没有 |
|
%(threadName)s |
线程名。可能没有 |
|
%(process)d |
进程ID。可能没有 |
|
%(message)s |
用户输出的消息 |
对于格式,有如下属性可以配置:

2、多文件日志
对于上述记录日志的功能,只能将日志记录在单文件中,如果想要设置多个日志文件,logging.basicConfig将无法完成,需要自定义文件和日志操作对象。
如上述创建的两个日志对象
- 当使用【logger1】写日志时,会将相应的内容写入 l1_1.log 和 l1_2.log 文件中
- 当使用【logger2】写日志时,会将相应的内容写入 l2_1.log 文件中
如果想同时把log打印在屏幕和文件日志里,就需要了解一点复杂的知识了
Python 使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适:
logger提供了应用程序可以直接使用的接口;
handler将(logger创建的)日志记录发送到合适的目的输出;
filter提供了细度设备来决定输出哪条日志记录;
formatter决定日志记录的最终输出格式。
logger
每个程序在输出信息之前都要获得一个Logger。Logger通常对应了程序的模块名,比如聊天工具的图形界面模块可以这样获得它的Logger:
LOG=logging.getLogger(”chat.gui”)
而核心模块可以这样:
LOG=logging.getLogger(”chat.kernel”)
Logger.setLevel(lel):指定最低的日志级别,低于lel的级别将被忽略。debug是最低的内置级别,critical为最高
Logger.addFilter(filt)、Logger.removeFilter(filt):添加或删除指定的filter
Logger.addHandler(hdlr)、Logger.removeHandler(hdlr):增加或删除指定的handler
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical():可以设置的日志级别
handler
handler对象负责发送相关的信息到指定目的地。Python的日志系统有多种Handler可以使用。有些Handler可以把信息输出到控制台,有些Logger可以把信息输出到文件,还有些 Handler可以把信息发送到网络上。如果觉得不够用,还可以编写自己的Handler。可以通过addHandler()方法添加多个多handler
Handler.setLevel(lel):指定被处理的信息级别,低于lel级别的信息将被忽略
Handler.setFormatter():给这个handler选择一个格式
Handler.addFilter(filt)、Handler.removeFilter(filt):新增或删除一个filter对象
每个Logger可以附加多个Handler。接下来我们就来介绍一些常用的Handler:
1) logging.StreamHandler
使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。它的构造函数是:
StreamHandler([strm])
其中strm参数是一个文件对象。默认是sys.stderr
2) logging.FileHandler
和StreamHandler类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件。它的构造函数是:
FileHandler(filename[,mode])
filename是文件名,必须指定一个文件名。
mode是文件的打开方式。参见Python内置函数open()的用法。默认是’a',即添加到文件末尾。
3) logging.handlers.RotatingFileHandler
这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。它的构造函数是:
RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]])
其中filename和mode两个参数和FileHandler一样。
maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。
backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。
4) logging.handlers.TimedRotatingFileHandler
这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。它的构造函数是:
TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]])
其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。
interval是时间间隔。
when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:
S 秒
M 分
H 小时
D 天
W 每星期(interval==0时代表星期一)
midnight 每天凌晨
打印到屏幕控制台和文件里的结果注意区别,因为定义的level不同:
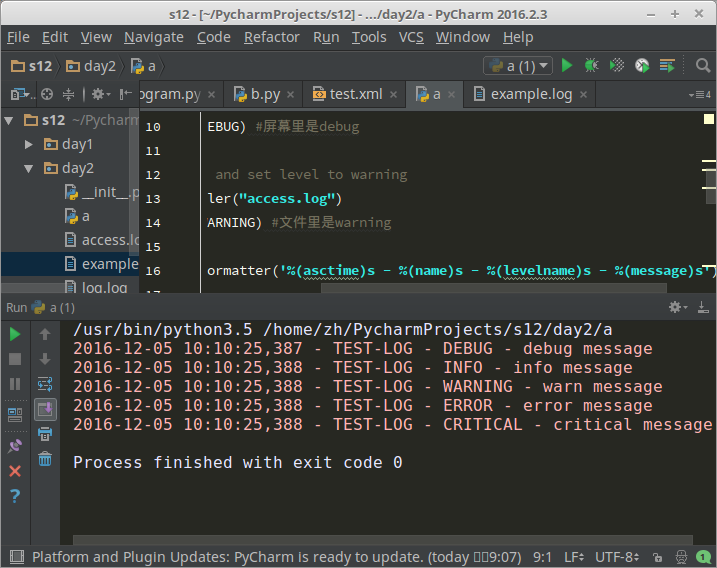
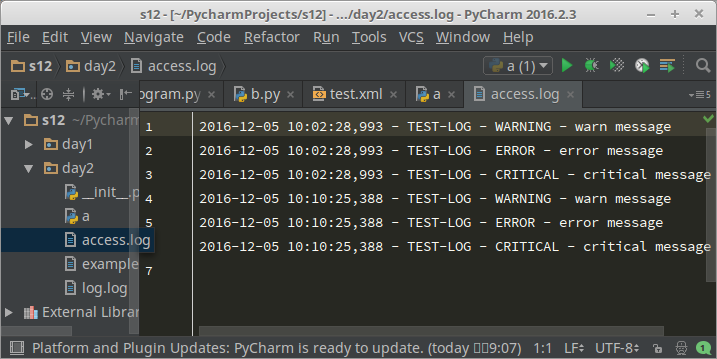
12、操作系统相关命令
可以执行shell命令的相关模块和函数有:
- os.system
- os.spawn*
- os.popen* --废弃
- popen2.* --废弃
- commands.* --废弃,3.x中被移除
1 import commands
2 testmodel = commands.getoutput('fdisk -l ') #获取用户的输出结果(结果以字符串存储)
3 print type(testmodel)
结果:<type 'str'>
4 f=commands.getstatus('/etc/passwd') #判断文件是否存在,存在返回不存在报错
5 print f 结果:
-rw-r--r-- 1 root root 2351 11月 19 16:02 /etc/passwd
6 d=commands.getstatus('/etc/passwdsd')
7 print d
结果:
ls: cannot access '/etc/passwdsd': No such file or directory
8
9 result = commands.getstatusoutput('cmd') #获取用户的输出结果和状态正确状态为:0 10 print result
结果:
(32512, 'sh: 1: cmd: not found')
以上执行shell命令的相关的模块和函数的功能均在 subprocess 模块中实现,并提供了更丰富的功能。建议以后使用此方法来执行系统命令:
call
执行命令,返回状态码。如果正确,状态码为0,错误为大于0的值!
1 import subprocess
2 subprocess.call(["ls",'-l','/etc/'],shell=False) #使用python执行shell命令shell=False
3 #subprocess.call(‘ls -l /etc/ ’,shell=True) #使用原生的shell执行命令shell=True
4 #一般建议统一使用python执行shell命名除非python没有的,在建议使用shell原生执行 结果:
total 1288
drwxr-xr-x 3 root root 4096 6月 28 20:39 acpi
-rw-r--r-- 1 root root 3028 6月 28 20:00 adduser.conf
等等等等
check_call
执行命令,如果执行,状态码是 0 ,则返回0,否则抛异常
1 import subprocess
2
3 >>>subprocess.call(["ls",'-l','/etc/'],shell=False) #执行成功返回状态码0
4 >>>subprocess.call(["ls",'-l','/etc/sdfsdf'],shell=False) #执行错误直接报异常
5
6 >>> subprocess.check_call('exit 1' ,shell=True)
7 Traceback (most recent call last):
8 File "<stdin>", line 1, in <module>
9 File "/usr/lib/python2.7/subprocess.py", line 540, in check_call
10 raise CalledProcessError(retcode, cmd)
11 subprocess.CalledProcessError: Command 'exit 1' returned non-zero exit status 1
12 >>> subprocess.check_call('exit 0' ,shell=True)
13 >>>
check_output
执行命令,如果状态码是 0 ,则返回执行结果,否则抛异常
1 >>> subprocess.check_output(["echo", "Hello World!"]) #执行结果成功状态码是0直接返回结果
2 'Hello World!\n'
3 >>> subprocess.check_output(["echo1", "Hello World!"]) #执行结果失败状态码不为0直接报错
4 Traceback (most recent call last):
5 File "<stdin>", line 1, in <module>
6 File "/usr/lib/python2.7/subprocess.py", line 566, in check_output
7 process = Popen(stdout=PIPE, *popenargs, **kwargs)
8 File "/usr/lib/python2.7/subprocess.py", line 710, in __init__
9 errread, errwrite)
10 File "/usr/lib/python2.7/subprocess.py", line 1327, in _execute_child
11 raise child_exception
12 OSError: [Errno 2] No such file or directory
subprocess.Popen(...)
用于执行复杂的系统命令
参数:
- args:shell命令,可以是字符串或者序列类型(如:list,元组)
- bufsize:指定缓冲。0 无缓冲,1 行缓冲,其他 缓冲区大小,负值 系统缓冲
- stdin, stdout, stderr:分别表示程序的标准输入、输出、错误句柄
- preexec_fn:只在Unix平台下有效,用于指定一个可执行对象(callable object),它将在子进程运行之前被调用
- close_sfs:在windows平台下,如果close_fds被设置为True,则新创建的子进程将不会继承父进程的输入、输出、错误管道。
所以不能将close_fds设置为True同时重定向子进程的标准输入、输出与错误(stdin, stdout, stderr)。 - shell:同上
- cwd:用于设置子进程的当前目录
- env:用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父进程中继承。
- universal_newlines:不同系统的换行符不同,True -> 同意使用 \n
- startupinfo与createionflags只在windows下有效
将被传递给底层的CreateProcess()函数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等
终端输入的命令分为两种:
- 输入即可得到输出,如:ifconfig
- 输入进行某环境,依赖再输入,如:python
14、paramiko
paramiko是一个用于做远程控制的模块,使用该模块可以对远程服务器进行命令或文件操作,值得一说的是,fabric和ansible内部的远程管理就是使用的paramiko来现实。
1、下载安装
1 pycrypto,由于 paramiko 模块内部依赖pycrypto,所以先下载安装pycrypto
2 pip3 install pycrypto
3 pip3 install paramiko
2、模块使用
15、time
时间相关的操作,时间有三种表示方式:
- 时间戳 1970年1月1日之后的秒,即:time.time()
- 格式化的字符串 2014-11-11 11:11, 即:time.strftime('%Y-%m-%d')
- 结构化时间 元组包含了:年、日、星期等... time.struct_time 即:time.localtime()
1 print time.time()
2 print time.mktime(time.localtime())
3
4 print time.gmtime() #可加时间戳参数
5 print time.localtime() #可加时间戳参数
6 print time.strptime('2014-11-11', '%Y-%m-%d')
7
8 print time.strftime('%Y-%m-%d') #默认当前时间
9 print time.strftime('%Y-%m-%d',time.localtime()) #默认当前时间
10 print time.asctime()
11 print time.asctime(time.localtime())
12 print time.ctime(time.time())
13
14 import datetime
15 '''
16 datetime.date:表示日期的类。常用的属性有year, month, day
17 datetime.time:表示时间的类。常用的属性有hour, minute, second, microsecond
18 datetime.datetime:表示日期时间
19 datetime.timedelta:表示时间间隔,即两个时间点之间的长度
20 timedelta([days[, seconds[, microseconds[, milliseconds[, minutes[, hours[, weeks]]]]]]])
21 strftime("%Y-%m-%d")
22 '''
23 import datetime
24 print datetime.datetime.now()
25 print datetime.datetime.now() - datetime.timedelta(days=5)
练习题:
1、通过HTTP请求和XML实现获取电视节目
API:http://www.webxml.com.cn/webservices/ChinaTVprogramWebService.asmx
2、通过HTTP请求和JSON实现获取天气状况
API:http://wthrcdn.etouch.cn/weather_mini?city=北京
python基础知识9——模块2——常见内置模块的更多相关文章
- python基础知识8——模块1——自定义模块和第三方开源模块
模块的认识 模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能需 ...
- Python基础知识:模块
目录 JSON模块&pickle模块 requests模块 time模块 datetime模块 logging模块 os模块 sys模块 hashlib模块 re模块.正则表达式 config ...
- Python基础知识—sys模块初探
有关Python解释器的信息 与所有其他模块一样,必须使用import语句导入sys模块,即import sys. sys模块提供有关Python解释器的常量,函数和方法.dir(系统)给出了可用常量 ...
- python基础知识-day8(模块与包、random、os)
1.模块与包 package:相同的模块代码存储在一个目录下(即包里边会包含多个模块). 包不能存储在文件夹的目录下,模块名称不能使用关键字.(不包含工程文件夹) 2.模块与包的实例 1)在工程文 ...
- python基础知识~logger模块
一 配置文件模块 import logging ->导入模块 logger = logging.getLogger('mylogger') ->初始化类二 创建句柄 1 文件句柄 fh = ...
- python基础知识~配置文件模块
一 配置文件模块 import ConfigParser ->导入模块 conf = ConfigParser.ConfigParser() ->初始化类二 系统函数 conf.r ...
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- python基础知识小结-运维笔记
接触python已有一段时间了,下面针对python基础知识的使用做一完整梳理:1)避免‘\n’等特殊字符的两种方式: a)利用转义字符‘\’ b)利用原始字符‘r’ print r'c:\now' ...
- python基础知识的学习和理解
参考链接:https://github.com/yanhualei/about_python/tree/master/python_learning/python_base python基础知识笔 ...
随机推荐
- 承接cardboard外包,unity3d外包(北京动软— 谷歌CARDBOARD真强大)
手把手教你玩转googlecardboard[不知道在这里发可以不?] 谷歌Google I/O开发者大会于北京时间6月26日0点在美国旧金山举行,谷歌发布了Android L手机系统:Android ...
- meta 标签 详细说明
meta 标签可提供页面元素信息, 使用键值对的定义方式,可以记录网页上的主要信息,也可以自定义键值对 属性 content(必须),name,http-equiv,scheme,lang 常用 me ...
- Install CentOS 7 on Thinkpad t430
- BIOS settings: - Thinkpadt430, BIOS settings: Config---------------------------- Network: wake on ...
- c#操作Excel
Excel是微软公司办公自动化套件中的一个软件,他主要是用来处理电子表格.Excel以其功能强大,界面友好等受到了许多用户的欢迎.在设计应用系统时,对于不同的用户,他们对于打印的需求是不一样的,如果要 ...
- opencv从txt文本读取像素点并显示
opencv从txt文本读取像素点并显示 文本储存格式为每行一个像素点,排列为RGB.每帧图像的帧头为65535. 如下图所示 废话不多说,代码如下: // #include <iostrea ...
- 高级搜索插件solis search在umbraco中的使用
好久没有写关于umbraco的博客了,这段时间在研究solis search,感觉它太强大,好东西是需要分享的,所以写一篇简单的使用博客分享给个人umbraco爱好者. 简介 在了解solis sea ...
- windows下CMake使用图文手册 Part 1
维基百科介绍“CMake是个开源的跨平台自动化建构系统,它用配置文件控制建构过程(build process)的方式和Unix的Make相似,只是CMake的配置文件取名为CMakeLists.txt ...
- java web工程 数据库操作报驱动类找不到的错误
这几天在进行数据库的操作,写好数据库操作类后,用测试类测试成功通过,但是部署到tomcat后,从页面访问就会报异常. 最后终于发现是tomcat使用了连接池的数据连接方式. 解决方法是把jdbc ja ...
- MongoDB常用操作
(备注: 对于 window, 不需要sudo) 验证成功与否: * 启动服务器: $sudo mongod --dbpath C:\data\db (需要 指明数据库存放的目录) * 打开shell ...
- mysql load data 乱码的问题
新学mysql在用load data导入txt文档时发现导入的内容,select 之后是乱码,先后把表,数据库的字符集类型修改为utf8,但还是一样,最后在 http://bbs.chinaunix. ...