一个无锁消息队列引发的血案(三)——地:q3.h 与 RingBuffer
目录
(一)起因 (二)混合自旋锁 (三)q3.h 与 RingBuffer
(四)RingQueue(上) 自旋锁 (五)RingQueue(中) 休眠的艺术
无锁队列
第一篇文章末尾我们提到的《无锁队列的实现》(陈皓(hào)),该文末尾提到的“用数组实现无锁队列”,即用 RingBuffer 实现的无锁队列:

RingBuffer 是一个很好的东西,用在无锁/有锁队列实在是太棒了,如该文提到的一样,RingBuffer由于使用的是序号(或可称为索引),且用数组存储的队列,跟使用链表存储队列相比,优点是可以避免ABA问题(关于ABA问题可以参考该文,或Google、百度自己搜),使用链表和指针来构造FIFO Queue(先进先出队列),只有使用Double CAS(Double Compare And Swap)才能避免ABA问题,这里不做讨论。《无锁队列的实现》一文虽有提到,但是其描述是乱七八糟的,足见其只是大自然的搬运工,自己其实完全不懂。不过,东西是点到了。
包括上面截图中的 RingBuffer 的描述,很多地方也是错漏百出,RingBuffer 更新 head 和 tail 根本不需要使用Double CAS,我们也并不需要把(TAIL, EMPTY) 更新成 (x, TAIL),只需要使用CAS更新HEAD或TAIL即可。不过对于我们还是有帮助的,至少你知道了这个东西,还有个好处,就是你看这个东西需要自己脑补一下,也算是一个功德吧,不然一点脑子都不动也不好玩。哈哈。
Compare-and-swap
Compare and Swap 或 Compare and Set(CAS)是 lock-free(无锁编程) 中常见的技术,可以参考 wikipedia 的 Compare-and-swap,用C语言的实现就是:
- int val_compare_and_swap(volatile int *dest_ptr,
- int old_value, int new_value)
- {
- int orig_value = *dest_ptr;
- if (*dest_ptr == old_value)
- *dest_ptr = new_value;
- return orig_value;
- }
意思就是,先保存*dest_ptr的值(dest_ptr是一个指针),再检查 *dest_ptr 的值是否等于旧址 old_value,如果等于的话,就把新值 new_value 写入*dest_ptr,否则什么都不做,最后返回值是 *dest_ptr 的原始值。CAS操作在CPU里是能保证原子性的,即整个CAS操作不会被CPU的中断或别的原因打断。在x86下对应的汇编指令是 LOCKCMPXCHG 。
Compare and Swap 还有一种形式,即:
- bool bool_compare_and_swap(volatile int *dest_ptr,
- int old_value, int new_value)
- {
- if (*dest_ptr == old_value) {
- *dest_ptr = new_value;
- return true;
- }
- return false;
- }
这其实是 val_compare_and_swap() 的变种,即如果 *dest_ptr 跟 old_value 相等则写入新值 new_value,并返回 true,不相等则返回 false。
RingBuffer
下面我们来看看什么叫做 RingBuffer,先忘掉前面那篇文章,我们以 q3.h 的实现为范例:
文件地址:https://github.com/shines77/RingQueue/blob/master/douban/q3.h
定义
我们把 RingBuffer 这么定义:
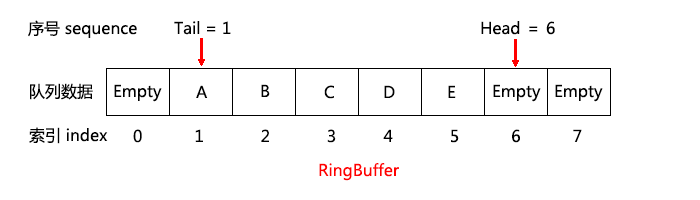
上面定义的是一个容量(Capacity)为8的RingBuffer,一般RingBuffer的容量取为2的N次幂,这样计算索引时可以使用 index = sequence & mask; (其中mask = capacity - 1;) 以提高代码效率。其中索引表示数组的下标,数组中保存的数据是A, B, C, D, Empty等。Head 表示队列的头指针(即首个可以压入数据的位置),Tail 表示队列的尾指针(即首个可以弹出数据的位置),Head、Tail都是以序号的形式存在,且是单调递增的,且可以大于等于Capacity(8),如果Head = 8 时表示数组的第一个元素(因为回转回来了,即 index = 8 & (8 - 1) = 8 & 7 = 0;),Head = 9 表示的其实是存储在数组的第二个元素。
队列内元素的实际长度为:Length = Head - Tail,其中 (Head - Tail) 必须 <= Capacity(最大容量),因为这个时候表示队列已经满了,如果(Head - Tail) = 0,则代表队列为空。为什么叫 RingBuffer,就是因为它是一个环,游标到了数组的尾部又回转到数组的头部。
至于定义哪边是头,哪边是尾,这不是很重要,逻辑上更换一下即可。但是这样定义比较直观,你试想一下,如果把上面那个图竖起来,你觉得哪边是头哪边是尾?还有个原因是因为 q3.h 也是这么定义的,而云风自己写的 mq.c 里则是刚好反过来定义的。不过如何定义的确不重要,只是不方便讨论而已。
边界问题
这里讨论一下边界的问题,q3.h 的边界判定不是很准确,if ((mask + tail - head) < 1U) return -1; 这样的写法会导致队列的实际最大长度为 Capacity - 1,而不是 Capacity。这还不是最大的问题,我们从上面得知 RingBuffer 的实际长度为:Length = Head - Tail,只要 Head, Tail 是无符号整型,即使 Head 从 4294967295 回绕到 0 的时候,这个公式依然成立。例如:Head = 2, Tail = 4294967295,Length = 2 - 4294967295 = -4294967293,而 4294967293 = 0xFFFFFFFD,一个数的负数计算机里是用补码,即取反再加1,0xFFFFFFFD 取反等于 0x00000002,再加1,就是3,所以实际长度为3,正确。所以只要RingQueue的定义一旦确定,只要Head,Tail使用无符号整型表示,实际元素长度公式 Length = Head - Tail 是永远成立的。
那么我们来看看 (mask + tail - head) < 1U 意味着什么,tail - head其实等于-length,则有:(mask - length) < 1U,因为两边都是无符号整型,所以只有 (mask - length) = 0 的时候才能成立,其他时候都不会成立,即 length = mask 的时候条件才会成立,而 mask = capacity - 1; 所以 length = capacity - 1 的时候,q3.h 就认为队列已经满了,所以 q3.h 最大的实际长度只能为 capacity - 1 个元素。
而且他还有一个问题,可能你也看到了,因为只有 length = mask 这一种情况是被认为队列满了,当 length < mask 还好一点,一旦 length > (mask + 1) 的时候,实际上队列已经满了,但 q3.h 不知道,它依旧认为是可以push()的,为什么它没出错呢?原因是这样的,你分析过 q3.h 的push()代码后,可以得知,由于head,tail都是单调递增的,由于线程可能随时被中断,所以head,tail只会比当前实际的head,tail值小,而head不等于当前实际值时,是通不过CAS的原子性检验的,所以我们可以认为head永远等于实际当前值,那么只考虑一种情况,就是tail可能比当前实际的tail值小,由于length = head - tail,那么意味着我们计算的length值,要比实际的length要大,也就是说队列实际没满,而 q3.h 可能会认为满了,从而导致push()失败。没有满却push()失败没有什么坏处,大不了再继续push()就是了,所以它并没有出现问题。但从逻辑上讲是不严密的。
所以通过上面的分析,我们得知判断队列是否已满的逻辑为:队列实际长度 >= 队列最大容量,即:if ((head - tail) >= capacity) return -1; 由于 mask = capacity - 1,还可以简化为:if ((head - tail) > mask) return -1; 。
同样的道理,q3.h 里判断队列为空的逻辑:if ((tail - head) < 1U) return NULL; 也是存在问题的,由于都是无符号整型,所以其等价于:if ((tail - head) == 0) return NULL; 同理,它在 q3.h 里也不会出现问题,不过更严密的判断逻辑应该为:if ((tail == head) || (tail > head && (head - tail) > mask)) return NULL; 。
struct queue
我们再来看一下 q3.h,地址是:
https://github.com/shines77/RingQueue/blob/master/douban/q3.h
q3.h 里 struct queue 是这么定义的:
- struct queue {
- struct {
- uint32_t mask;
- uint32_t size;
- volatile uint32_t head;
- volatile uint32_t tail;
- } p;
- char pad[CACHE_LINE_SIZE - * sizeof(uint32_t)];
- struct {
- uint32_t mask;
- uint32_t size;
- volatile uint32_t head;
- volatile uint32_t tail;
- } c;
- char pad2[CACHE_LINE_SIZE - * sizeof(uint32_t)];
- void *msgs[];
- };
说实话,这样写并不是很准确,而且难于理解,其所定义的 struct p 和 struct c,严格意义来讲,p 应该叫 head,c 应该叫 tail,而p,c里面定义的 head,tail 应该叫 first,second,他们其实是一个pair,有点类似于std::pair,所以你也就知道我为什么叫它们 first,second 了。(注:在 disruptor 里面,first, second 被称之为 next,cursor(next是首个可压入数据的位置,cursor(游标)是最新一个已经成功提交(publish)数据的位置,这里我们还是使用我的叫法)。
disruptor 里next,cursor的示意图如下:
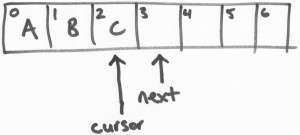
所以 struct queue 更准确的定义应该是这样:
- struct queue {
- struct {
- uint32_t mask;
- uint32_t size;
- volatile uint32_t first;
- volatile uint32_t second;
- } head;
- char pad1[CACHE_LINE_SIZE - * sizeof(uint32_t)];
- struct {
- uint32_t mask;
- uint32_t size;
- volatile uint32_t first;
- volatile uint32_t second;
- } tail;
- char pad2[CACHE_LINE_SIZE - * sizeof(uint32_t)];
- void *msgs[];
- };
这里面mask,size其实都是常量,完全可以不用放进来,不过这个不算太重要,暂时忽略。
所以 q3.h 里的 push() 和 pop() 可以改写为,同时我们把边界判断也修改了:
- static inline int
- push(struct queue *q, void *m)
- {
- uint32_t head, tail, mask, next;
- int ok;
- mask = q->head.mask;
- do {
- head = q->head.first;
- tail = q->tail.second;
- if ((head - tail) > mask)
- return -;
- next = head + ;
- ok = __sync_bool_compare_and_swap(&q->head.first, head, next);
- } while (!ok);
- q->msgs[head & mask] = m;
- asm volatile ("":::"memory");
- while (unlikely((q->head.second != head)))
- _mm_pause();
- q->head.second = next;
- return ;
- }
- static inline void *
- pop(struct queue *q)
- {
- uint32_t tail, head, mask, next;
- int ok;
- void *ret;
- mask = q->tail.mask;
- do {
- tail = q->tail.first;
- head = q->head.second;
- if ((tail == head) || (tail > head && (head - tail) > mask))
- return NULL;
- next = tail + ;
- ok = __sync_bool_compare_and_swap(&q->tail.first, tail, next);
- } while (!ok);
- ret = q->msgs[tail & mask];
- asm volatile ("":::"memory");
- while (unlikely((q->tail.second != tail)))
- _mm_pause();
- q->tail.second = next;
- return ret;
- }
这样应该比原来要清晰明了,容易理解了吧。其中“asm volatile ("":::"memory");”是编译器内存屏障,如果你不理解的话,可以忽略它,大意就是编译器做优化的时候,所有该屏障之前的写入或读入操作都不能越过该屏障,反之屏障之后的也类似。
该文件已上传至:https://github.com/shines77/RingQueue/blob/master/douban/q3_new.h
push()
下面我们来分析一下push()是怎么工作的?代码如下:
- static inline int
- push(struct queue *q, void *m)
- {
- uint32_t head, tail, mask, next;
- int ok;
- mask = q->head.mask;
- do {
- head = q->head.first;
- tail = q->tail.second;
- if ((head - tail) > mask)
- return -;
- next = head + ;
- ok = __sync_bool_compare_and_swap(&q->head.first, head, next);
- } while (!ok);
- q->msgs[head & mask] = m;
- asm volatile ("":::"memory");
- while (unlikely((q->head.second != head)))
- _mm_pause();
- q->head.second = next;
- return ;
- }
先来看看 head 里的 head.first,head.second 的示意图:
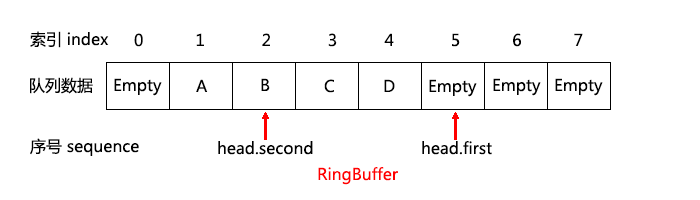
根据前面也提到过的 disruptor 的 next 与 cursor,类似的,这里 head.first 是首个可以压入数据的位置,head.second 是最新一个已经成功提交数据的位置。head.first 通过do while() 和 CAS 操作的保证,让每个线程取得一个唯一的序号(sequence),因为CAS的原子性,即可保证每次只有一个线程有令 head.first 增一的机会。这有点类似你去银行取钱的时候,一进门先得去一台机器上领个号码,然后银行再按照这个号码的先后顺序为客户服务。我们称这个号码为序号(sequence),比如你领到的是5号,如上图,但是银行目前只处理完了2号客户之前的客户(包括2号客户,即上图中的 head.second),3, 4号客服都是正在办理中的,而5号是你新领到的。跟现实银行不太一样地方是,这里只要你一领到序号,窗口就立刻开始为你服务了,而各个窗口(各个线程)办理完成的时间是不定的,可能4号窗口先办理完,然后再是3号窗口,最后5号窗口,也就是你领到的号码。还有一点跟现实银行不一样的地方,就是不管3, 4, 5窗口谁先办理完成,都必须按照序号的大小来结束办理过程,即4号窗口即使完成了,也要等3号窗口完成了以后才算完成,否则只能等3号窗口完成。如果5号窗口先办理完毕,也必须等4号窗口完成,才能算最终完成。因为只有这么依次完成,我们才好挪动 head.second 到最新成功提交数据的那个位置,如果不按照这个顺序,跳着挪动 head.second,那么 head.second 就乱套了。
这个按顺序提交数据是通过 while (unlikely((q->head.second != head))) _mm_pause(); 实现的。只要最后成功提交数据的位置跟你领的序号(sequence)不一样的话,就必须一直等,直到等于你的序号为止。这样就实现了按顺序提交数据(按领到的序号的顺序)。这里再提一下边界判断时讲过的,这里的 tail 可以认为小于等于实时的 tail.first 值(tail = tail.second,而 tail.second <= tail.first,而且 tail 也可以小于实时的 tail.second值),而 head 可以认为永远等于 head.first 值(因为如果不等于,则CAS是通不过的,必须重来),因此 (head - tail) 是比实时的 (head - tail) 值大的,所有 push() 可能会在队列未满的时候就可能认为队列满了,因而提前退出,这样是无害的,大不了重新push()。
另外,提交数据是由 q->msgs[head & mask] = m; 这句实现的,即按照你领到的序号写入数据即可,因为这个序号是唯一的,只要保证队列不溢出或负溢出,每一个独立的序号都会在数组中有唯一的一个存储位置。
我们再来分析一下Cache Line(缓存行)的占用,我们看到,前面那个do while() + CAS里,CAS操作会锁住 head.first 所在的缓存行(即让其失效)。而后面的确认提交的循环中,while (unlikely((q->head.second != head))) 有对 head.second 的内存引用,而根据 q3.h 和 q3_new.h 的定义,两者是在同一条Cache Line(内存行)上的(虽然不一定是100%在一条Cache Line上,但由于现在大部分编译器内存对齐默认都是8字节,所以在一行上的机率几乎接近100%)。而再后面的那句:q->head.second = next; 对 head.second 的写入操作也将时其他线程的 do while() + CAS 循环里的 head.first 的缓存失效。所以这是 q3.h 设计上的一个失误,虽然考虑了Cache Line Padding(缓存行填充),但是没有考虑周全,还是存在 False Sharing (伪共享)。这些问题在 disruptor 里都很好的规避了,因为它给每一个序号变量都运用了Cache Line Padding,即 Sequence 类。其实 False Sharing 也不是很严重的事情,只不过线程越多,被锁区域的运行时间越短,False Sharing造成的不利影响将越明显。
从循环的角度来看,前面那个do while() + CAS,可以认为是一个自旋计数为0的自旋锁,而后面那个确认提交的循环,则是一个真正意义的自旋,只有条件满足了才能退出,两个循环中都要依赖或等待别的线程才能确保退出循环,所以我们大致认为他们是两个自旋在运作,这个我在“第二篇:自旋锁”里也有提到。
q3.h 还有一个问题就是,有可能会活锁(livelock),虽然没有完全死锁(deadlock),但是 push() 和 pop() 执行得很慢很慢,超出常规的效率,原因还不太明白,有空再好好想想。出现这种情况的条件是(以下两种描述因为有点忘记了,如果说得不对我会及时纠正):如果不开CPU亲缘性的话,且当PUSH_CNT + POP_CNT 大于CPU的实际核心数的时候,会很慢;如果开启了CPU亲缘性的话,当PUSH_CNT + POP_CNT 大于CPU的实际核心数的时候,会非常慢,比前者还要慢。除了这些情况以外,执行效率还算正常。
pop()
我们再来看看pop(),代码如下:
- static inline void *
- pop(struct queue *q)
- {
- uint32_t tail, head, mask, next;
- int ok;
- void *ret;
- mask = q->tail.mask;
- do {
- tail = q->tail.first;
- head = q->head.second;
- if ((tail == head) || (tail > head && (head - tail) > mask))
- return NULL;
- next = tail + ;
- ok = __sync_bool_compare_and_swap(&q->tail.first, tail, next);
- } while (!ok);
- ret = q->msgs[tail & mask];
- asm volatile ("":::"memory");
- while (unlikely((q->tail.second != tail)))
- _mm_pause();
- q->tail.second = next;
- return ret;
- }
tail 里的 tail.first,tail.second 的示意图:
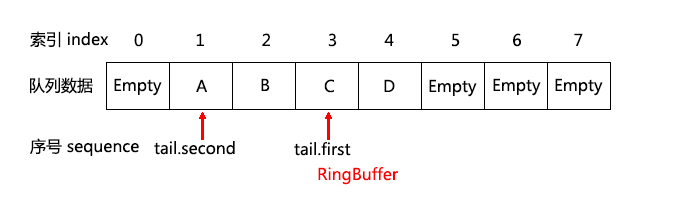
同上可知,这里 tail.first 是首个可以弹出数据的位置,tail.second 是最新一个已经成功弹出数据的位置。弹出数据的语句是:ret = q->msgs[tail & mask]; 最终确认弹出的语句是:q->tail.second = next; 其他分析同 push() 类似。
问题
纵观 push() 和 pop(),你会发现 head.first,head.second,tail.first,tail.second 这四个变量环环相扣,互相影响,push() 一开始引用了 head.first 和 tail.second,而 pop() 一开始引用了 tail.first 和 head.second,但 head.first 和 head.second 是一条Cache Line上的,而 tail.first 和 tail.second 也是在一条Cache Line上的,无论谁的值更新或进入CAS操作,都会造成 False Sharing(伪共享) 让缓存失效而互相影响。十足有当年赤壁之战曹军水军连环船的风范……(火烧连环船)。这是 q3.h 设计上的一个大失误,如果想提高一点效率,可以把这四个变量分别放到不同的 Cache Line 上,会好很多,而 disruptor 在这方面考虑得比较周全。
前面提到的关于 disruptor 的那篇原理文章是:http://blog.codeaholics.org/2011/the-disruptor-lock-free-publishing/ ,这不是我唯一看过的 disruptor 文章,我看了很多,不过这篇文章让我能更好的来写本文。关于 disruptor 的一些原理介绍,请自行 Google 或 百度,因为 disruptor 版本升级很快,而各篇文章描述所用的代码、名称或结构不一定跟最新版的相同,但原理上大致是一样的,我也是看到了各种版本,各种说话,需要自己综合起来。
休眠
暂时写到这了,先休息,晚安,地球……。
RingQueue
RingQueue 的GitHub地址是:https://github.com/shines77/RingQueue,也可以下载UTF-8编码版:https://github.com/shines77/RingQueue-utf8。 我敢说是一个不错的混合自旋锁,你可以自己去下载回来看看,支持Makefile,支持CodeBlocks, 支持Visual Studio 2008, 2010, 2013等,还支持CMake,支持Windows, MinGW, cygwin, Linux, Mac OSX等等,当然可能不支持ARM。
目录
(一)起因 (二)混合自旋锁 (三)q3.h 与 RingBuffer
(四)RingQueue(上) 自旋锁 (五)RingQueue(中) 休眠的艺术
下一篇:一个无锁消息队列引发的血案(四)——月:关于RingQueue(上)
.
一个无锁消息队列引发的血案(三)——地:q3.h 与 RingBuffer的更多相关文章
- 一个无锁消息队列引发的血案(六)——RingQueue(中) 休眠的艺术 [续]
目录 (一)起因 (二)混合自旋锁 (三)q3.h 与 RingBuffer (四)RingQueue(上) 自旋锁 (五)RingQueue(中) 休眠的艺术 (六)RingQueue(中) 休眠的 ...
- 一个无锁消息队列引发的血案(五)——RingQueue(中) 休眠的艺术
目录 (一)起因 (二)混合自旋锁 (三)q3.h 与 RingBuffer (四)RingQueue(上) 自旋锁 (五)RingQueue(中) 休眠的艺术 (六)RingQueue(中) 休眠的 ...
- 一个无锁消息队列引发的血案(四)——月:RingQueue(上) 自旋锁
目录 (一)起因 (二)混合自旋锁 (三)q3.h 与 RingBuffer (四)RingQueue(上) 自旋锁 (五)RingQueue(中) 休眠的艺术 (六)RingQueue(中) 休眠的 ...
- 【数据结构】C++语言无锁环形队列的实现
无锁环形队列 1.Ring_Queue在payload前加入一个头,来表示当前节点的状态 2.当前节点的状态包括可以读.可以写.正在读.正在写 3.当读完成后将节点状态改为可以写,当写完成后将节点状态 ...
- DPDK 无锁环形队列(Ring)详解
DPDK 无锁环形队列(Ring) 此篇文章主要用来学习和记录DPDK中无锁环形队列相关内容,结合了官方文档说明和源码中的实现,供大家交流和学习. Author : Toney Email : vip ...
- Linux 内核:匠心独运之无锁环形队列kfifo
Linux 内核:匠心独运之无锁环形队列 Kernel version Linux 2.6.12 Author Toney Email vip_13031075266@163.com Da ...
- Nah Lock: 一个无锁的内存分配器
概述 我实现了两个完全无锁的内存分配器:_nalloc 和 nalloc. 我用benchmark工具对它们进行了一组综合性测试,并比较了它们的指标值. 与libc(glibc malloc)相比, ...
- Java编程的逻辑 (61) - 内存映射文件及其应用 - 实现一个简单的消息队列
本系列文章经补充和完善,已修订整理成书<Java编程的逻辑>,由机械工业出版社华章分社出版,于2018年1月上市热销,读者好评如潮!各大网店和书店有售,欢迎购买,京东自营链接:http:/ ...
- nodejs一个函数实现消息队列中间件
消息队列中间件(Message Queue)相信大家不会陌生,如Kafka.RabbitMQ.RocketMQ等,已经非常成熟,在大大小小的公司和项目中也已经广泛使用. 有些项目中,如果是只使用初步的 ...
随机推荐
- ElasticSearch 2 (37) - 信息聚合系列之内存与延时
ElasticSearch 2 (37) - 信息聚合系列之内存与延时 摘要 控制内存使用与延时 版本 elasticsearch版本: elasticsearch-2.x 内容 Fielddata ...
- HDU 2097 Sky数
http://acm.hdu.edu.cn/showproblem.php?pid=2097 Problem Description Sky从小喜欢奇特的东西,而且天生对数字特别敏感,一次偶然的机会, ...
- 打包spring项目遇到的坑 Unable to locate Spring NamespaceHandler for XML schema ……shcema/context 产生的原因及解决方法
图1 图2 问题原因:导致该问题的原因就是打包的时候,同时将 spring-context 和 spring-aop包提取到了我们的程序应用的包中,在package过程中,这2个依赖包的 XML sc ...
- Android studio Gradle编译错误: Unable to tunnel through proxy. Proxy returns "HTTP/1.1 400 Bad Reques
两种处理方法: 1.修改distributionUrl链接 gradle-wrapper.properties文件 distributionUrl=https\://services.gradle.o ...
- 通过.json()将服务器返回的字符串转换成字典
- BZOJ5465 APIO2018选圆圈(KD-Tree+堆)
考虑乱搞,用矩形框圆放KD-Tree上,如果当前删除的圆和矩形有交就递归下去删.为防止被卡,将坐标系旋转一定角度即可.注意eps稍微设大一点,最好开上long double. #include< ...
- 【刷题】BZOJ 3033 太鼓达人
Description 七夕祭上,Vani牵着cl的手,在明亮的灯光和欢乐的气氛中愉快地穿行.这时,在前面忽然出现了一台太鼓达人机台,而在机台前坐着的是刚刚被精英队伍成员XLk.Poet_shy和ly ...
- Tomcat如何开启SSL配置(https)
一.创建证书 证书用于客户端与服务端安全认证.我们可以使用JDK自带的keytool工具来生成证书.真正在产品环境中使用肯定要去证书提供商去购买,证书认证一般都是由VeriSign认证,官方地址:ht ...
- 服务器启动报mybatis配置错误
启动服务器时后台报了一大堆的错误,仔细检查发现都是冲着mybatis的配置文件去的,事实上配置文件的东西很少,经过反复启动服务器,发现了只要写了where条件就报错,不写就可以正常启动,经过百度发现m ...
- 20个令人惊叹的深度学习应用(Demo+Paper+Code)
20个令人惊叹的深度学习应用(Demo+Paper+Code) 从计算机视觉到自然语言处理,在过去的几年里,深度学习技术被应用到了数以百计的实际问题中.诸多案例也已经证明,深度学习能让工作比之前做得更 ...