MySQL中的xtrabackup的原理解析
xtrabackup的官方下载地址为
http://www.percona.com/software/percona-xtrabackup。
xtrabackup包含两个主要的工具,即xtrabackup和innobackupex,二者区别如下:
1 xtrabackup只能备份innodb和xtradb两种引擎的表,而不能备份myisam引擎的表; 2 innobackupex是一个封装了xtrabackup的Perl脚本,支持同时备份innodb和myisam,但在对myisam备份时需要加一个全局的读锁。还有就是myisam不支持增量备份。
innobackupex工具的备份过程原理图
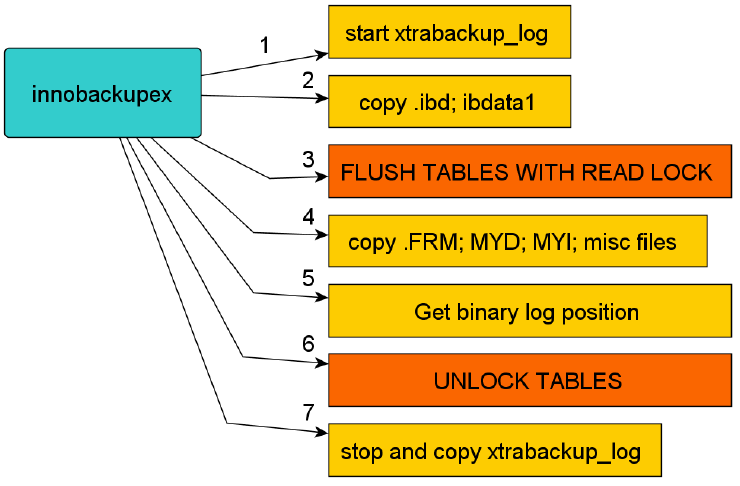
如图,备份开始的时候

1 首先会启动一个xtrabackup_log后台检测的进程,实时检测mysql redo的变化,一旦发现redo有新的日志写入,立刻将日志写入到日志文件xtrabackup_log中 2 复制innodb的数据文件和系统表空间文件idbdata1到对应的以默认时间戳为备份目录的地方 3 复制结束后,执行flush table with read lock操作 4 复制.frm .myd .myi文件 5 并且在这一时刻获得binary log 的位置 6 将表进行解锁unlock tables 7 停止xtrabackup_log进程
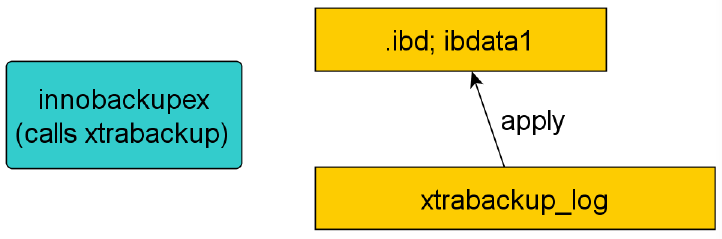
全库恢复的过程
这一阶段会启动xtrabackup内嵌的innodb实例,将xtrabackup日志xtrabackup_Log进行回放,将提交的事务信息变更应用到innodb数据或表空间,同时回滚未提交的事务
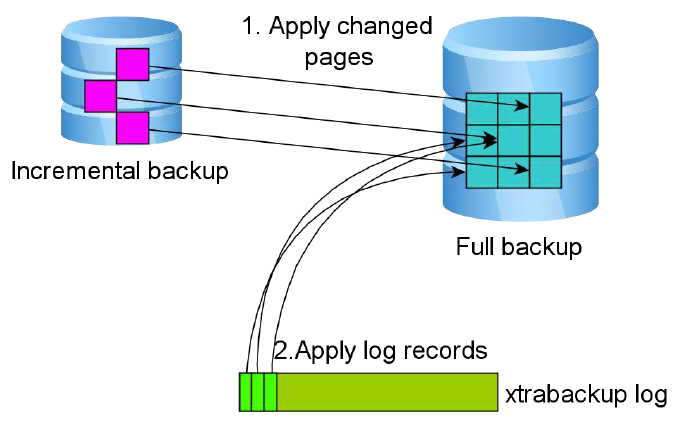
增量备份
增量备份主要是通过拷贝innodb中有变更的页(指的是LSN大于xtrabackup_checkpoints中的LSN号)。增量备份是基于全备的,第一次增量备份的数据是基于上一次全备,之后的每一次增倍都是基于上一次的增倍,最终达到一致性的增倍,增倍的过程中,和全备很类似,区别在于第二步

增量备份的恢复
和全库恢复类似,也需要两步
1 数据文件的恢复 分3部分 全备 增量备份和xtrabackup_log
2 对未提交事务的回滚

=================================================================================
innobackupex的使用案例
rpm -Uhv http://www.percona.com/downloads/percona-release/percona-release-0.0-1.x86_64.rpm
yum -y install percona-xtrabackup
1 创建备份用户
mysql> grant reload,lock tables,replication client on *.* to 'dbbak'@'localhost' identified by 'bk2016' ;
mysql> flush privileges;
进行数据库全备
mkdir -pv /data/dbbak
cd /data/dbbak
使用以下参数进行全库备份
[root@MASTER_03 dbbak]# innobackupex --defaults-file=/etc/my.cnf --user=dbbak --password=bk2016 --socket=/data/3306/tmp/mysql.sock /data/dbbak/
xtrabackup: Stopping log copying thread.
.160204 00:36:20 >> log scanned up to (1095197210)
160204 00:36:20 Executing UNLOCK TABLES
160204 00:36:20 All tables unlocked
160204 00:36:20 Backup created in directory '/data/dbbak//2016-02-04_00-35-36'
MySQL binlog position: filename 'mysql-bin.000011', position '1338619'
160204 00:36:20 [00] Writing backup-my.cnf
160204 00:36:20 [00] ...done
160204 00:36:20 [00] Writing xtrabackup_info
160204 00:36:20 [00] ...done
xtrabackup: Transaction log of lsn (1095197210) to (1095197210) was copied.
160204 00:36:20 completed OK!说明备份成功
查看对应生成的文件
[root@MASTER_03 dbbak]# ll 2016-02-04_00-35-36/
total 1048648
-rw-r-----. 1 root root 387 Feb 4 00:36 backup-my.cnf
-rw-r-----. 1 root root 1073741824 Feb 4 00:35 ibdata1
drwx------. 2 root root 4096 Feb 4 00:36 iot
drwx------. 2 root root 12288 Feb 4 00:36 iot2
drwx------. 2 root root 4096 Feb 4 00:36 iot3
drwx------. 2 root root 4096 Feb 4 00:36 lsn
drwx------. 2 root root 4096 Feb 4 00:36 mysql
drwx------. 2 root root 4096 Feb 4 00:36 performance_schema
drwx------. 2 root root 4096 Feb 4 00:36 sakila
drwx------. 2 root root 4096 Feb 4 00:36 sbtest
drwx------. 2 root root 4096 Feb 4 00:36 test
drwx------. 2 root root 4096 Feb 4 00:36 xtrabackup0219
-rw-r-----. 1 root root 25 Feb 4 00:36 xtrabackup_binlog_info
-rw-r-----. 1 root root 119 Feb 4 00:36 xtrabackup_checkpoints
-rw-r-----. 1 root root 539 Feb 4 00:36 xtrabackup_info
-rw-r-----. 1 root root 2560 Feb 4 00:36 xtrabackup_logfile
需要注意的几个文件
[root@MASTER_03 dbbak]# cat 2016-02-04_00-35-36/xtrabackup_checkpoints
backup_type = full-backuped ###全备
from_lsn = 0
to_lsn = 1095197210
last_lsn = 1095197210 #####LSN号
compact = 0
recover_binlog_info = 0
[root@MASTER_03 dbbak]# cat 2016-02-04_00-35-36/xtrabackup_binlog_info
mysql-bin.000011 1338619
删掉某个数据库,进行全库恢复
mysql> drop database iot2;
Query OK, 49 rows affected (7.93 sec)
关闭数据库
[root@MASTER_03 dbbak]# /etc/init.d/mysqld stop
Shutting down MySQL.......... SUCCESS!
[root@MASTER_03 dbbak]# mv /data/3306/data /data/3306/data_bak
[root@MASTER_03 dbbak]# mkdir /data/3306/data
恢复
[root@MASTER_03 dbbak]# innobackupex --apply-log /data/dbbak/2016-02-04_00-35-36/
160204 00:56:47 innobackupex: Starting the apply-log operation IMPORTANT: Please check that the apply-log run completes successfully.
At the end of a successful apply-log run innobackupex
prints "completed OK!". innobackupex version 2.3.3 based on MySQL server 5.6.24 Linux (x86_64) (revision id: 525ca7d)
xtrabackup: cd to /data/dbbak/2016-02-04_00-35-36/
xtrabackup: This target seems to be not prepared yet.
xtrabackup: xtrabackup_logfile detected: size=2097152, start_lsn=(1095197210)
xtrabackup: using the following InnoDB configuration for recovery:
xtrabackup: innodb_data_home_dir = ./
xtrabackup: innodb_data_file_path = ibdata1:1G:autoextend
xtrabackup: innodb_log_group_home_dir = ./
xtrabackup: innodb_log_files_in_group = 1
xtrabackup: innodb_log_file_size = 2097152
xtrabackup: using the following InnoDB configuration for recovery:
xtrabackup: innodb_data_home_dir = ./
xtrabackup: innodb_data_file_path = ibdata1:1G:autoextend
xtrabackup: innodb_log_group_home_dir = ./
xtrabackup: innodb_log_files_in_group = 1
xtrabackup: innodb_log_file_size = 2097152
xtrabackup: Starting InnoDB instance for recovery.
xtrabackup: Using 104857600 bytes for buffer pool (set by --use-memory parameter)
InnoDB: Using atomics to ref count buffer pool pages
InnoDB: The InnoDB memory heap is disabled
InnoDB: Mutexes and rw_locks use GCC atomic builtins
InnoDB: Memory barrier is not used
InnoDB: Compressed tables use zlib 1.2.3
InnoDB: Using CPU crc32 instructions
InnoDB: Initializing buffer pool, size = 100.0M
InnoDB: Completed initialization of buffer pool
InnoDB: Highest supported file format is Barracuda.
InnoDB: The log sequence numbers 532847032 and 532847032 in ibdata files do not match the log sequence number 1095197210 in the ib_logfiles!
InnoDB: Database was not shutdown normally!
InnoDB: Starting crash recovery.
InnoDB: Reading tablespace information from the .ibd files...
InnoDB: Restoring possible half-written data pages
InnoDB: from the doublewrite buffer...
InnoDB: 128 rollback segment(s) are active.
InnoDB: Waiting for purge to start
InnoDB: 5.6.24 started; log sequence number 1095197210
xtrabackup: Last MySQL binlog file position 1337268, file name mysql-bin.000011 xtrabackup: starting shutdown with innodb_fast_shutdown = 1
InnoDB: FTS optimize thread exiting.
InnoDB: Starting shutdown...
InnoDB: Shutdown completed; log sequence number 1095198530
xtrabackup: using the following InnoDB configuration for recovery:
xtrabackup: innodb_data_home_dir = ./
xtrabackup: innodb_data_file_path = ibdata1:1G:autoextend
xtrabackup: innodb_log_group_home_dir = ./
xtrabackup: innodb_log_files_in_group = 3
xtrabackup: innodb_log_file_size = 1073741824
InnoDB: Using atomics to ref count buffer pool pages
InnoDB: The InnoDB memory heap is disabled
InnoDB: Mutexes and rw_locks use GCC atomic builtins
InnoDB: Memory barrier is not used
InnoDB: Compressed tables use zlib 1.2.3
InnoDB: Using CPU crc32 instructions
InnoDB: Initializing buffer pool, size = 100.0M
InnoDB: Completed initialization of buffer pool
InnoDB: Setting log file ./ib_logfile101 size to 1024 MB
InnoDB: Progress in MB: 100 200 300 400 500 600 700 800 900 1000
InnoDB: Setting log file ./ib_logfile1 size to 1024 MB
InnoDB: Progress in MB: 100 200 300 400 500 600 700 800 900 1000
InnoDB: Setting log file ./ib_logfile2 size to 1024 MB
InnoDB: Progress in MB: 100 200 300 400 500 600 700 800 900 1000
InnoDB: Renaming log file ./ib_logfile101 to ./ib_logfile0
InnoDB: New log files created, LSN=1095198530
InnoDB: Highest supported file format is Barracuda.
InnoDB: 128 rollback segment(s) are active.
InnoDB: Waiting for purge to start
InnoDB: 5.6.24 started; log sequence number 1095198732
xtrabackup: starting shutdown with innodb_fast_shutdown = 1
InnoDB: FTS optimize thread exiting.
InnoDB: Starting shutdown...
InnoDB: Shutdown completed; log sequence number 1095202631
160204 00:57:31 completed OK!
以上对应的目录就是innobackupex全备份自己创建的目录
[root@MASTER_03 dbbak]# innobackupex --defaults-file=/etc/my.cnf --copy-back --rsync /data/dbbak/2016-02-04_00-35-36/
160204 01:08:39 [01] ...done
160204 01:08:39 [01] Copying ./iot2/t_hash1#P#p3.ibd to /data/3306/data/iot2/t_hash1#P#p3.ibd
160204 01:08:39 [01] ...done
160204 01:08:39 [01] Copying ./iot2/db.opt to /data/3306/data/iot2/db.opt
160204 01:08:39 [01] ...done
160204 01:08:39 [01] Copying ./xtrabackup0219/db.opt to /data/3306/data/xtrabackup0219/db.opt
160204 01:08:39 [01] ...done
160204 01:08:39 completed OK!
更改权限
[root@MASTER_03 tmp]# chown -R mysql.mysql /data/3306/data/
启动mysqld
[root@MASTER_03 tmp]# /etc/init.d/mysqld start
[root@MASTER_03 tmp]# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 5.6.28-log MySQL Community Server (GPL) Copyright (c) 2000, 2015, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| iot |
| iot2 | ###被删除的库
| iot3 |
| lsn |
| mysql |
| performance_schema |
| sakila |
| sbtest |
| test |
| xtrabackup0219 |
+--------------------+
11 rows in set (0.00 sec)
发现数据是已经成功恢复
先全备
mysql> use xtrabackup0219;
mysql> create table t1(id int(5) primary key auto_increment,name varchar(20));
innobackupex --defaults-file=/etc/my.cnf --user=dbbak --password=bk2016 --socket=/data/3306/tmp/mysql.sock /data/dbbak/
增量备份
#####往表里插入数据
mysql> insert into t1 select 1,'love sql';
Query OK, 1 row affected (0.01 sec)
Records: 1 Duplicates: 0 Warnings: 0
mysql> insert into t1 select 2,'love sql';
Query OK, 1 row affected (0.00 sec)
Records: 1 Duplicates: 0 Warnings: 0
mysql> insert into t1 select 3,'love sql';
Query OK, 1 row affected (0.01 sec)
Records: 1 Duplicates: 0 Warnings: 0
mysql> select * from t1;
+----+----------+
| id | name |
+----+----------+
| 1 | love sql |
| 2 | love sql |
| 3 | love sql |
+----+----------+
3 rows in set (0.00 sec)
[root@MASTER_03 dbbak]# innobackupex --defaults-file=/etc/my.cnf --user=dbbak --password=bk2016 --socket=/data/3306/tmp/mysql.sock --incremental /data/dbbak/ --incremental-basedir=/data/dbbak/2016-02-04_01-44-24/ --parallel=2
[root@MASTER_03 dbbak]# du -sh *
1.5G 2016-02-04_01-44-24
6.0M 2016-02-04_01-46-48
[root@MASTER_03 dbbak]# cat 2016-02-04_01-46-48/xtrabackup_checkpoints
backup_type = incremental ###说明是增量的
from_lsn = 1095215215
to_lsn = 1095217565
last_lsn = 1095217565
compact = 0
recover_binlog_info = 0
此时再插入数据
mysql> insert into t1 select 4,'mysql dba';
Query OK, 1 row affected (0.01 sec)
Records: 1 Duplicates: 0 Warnings: 0
增量备份2
[root@MASTER_03 dbbak]# innobackupex --defaults-file=/etc/my.cnf --user=dbbak --password=bk2016 --socket=/data/3306/tmp/mysql.sock --incremental /data/dbbak/ --incremental-basedir=/data/dbbak/2016-02-04_01-46-48/ --parallel=2
[root@MASTER_03 dbbak]# du -sh *
1.5G 2016-02-04_01-44-24
6.0M 2016-02-04_01-46-48
5.9M 2016-02-04_01-49-21
增量备份的恢复
增量备份的恢复需要有3个步骤
1 恢复完全备份
2 恢复增量备份到完全备份(开始恢复的增量备份要添加--redo-only参数,到最后一次增量备份要去掉--redo-only)
3 对整体的完全备份进行恢复,回滚未提交的数据
[root@MASTER_03 dbbak]# innobackupex --apply-log --redo-only /data/dbbak/2016-02-04_01-44-24/
xtrabackup: starting shutdown with innodb_fast_shutdown = 1
InnoDB: Starting shutdown...
InnoDB: Shutdown completed; log sequence number 1095209828
160204 01:27:09 completed OK!
将增量1应用到完全备份
[root@MASTER_03 dbbak]# innobackupex --apply-log --redo-only /data/dbbak/2016-02-04_01-44-24/ --incremental-dir=/data/dbbak/2016-02-04_01-46-48/
[root@MASTER_03 dbbak]# innobackupex --apply-log /data/dbbak/2016-02-04_01-44-24/ --incremental-dir=/data/dbbak/2016-02-04_01-49-21/
把所有合在一起的完全备份整体进行一次apply操作,回滚未提交的数据
[root@MASTER_03 dbbak]# innobackupex --apply-log /data/dbbak/2016-02-04_01-44-24/
模拟测试
mysql> drop table t1;
Query OK, 0 rows affected (0.05 sec) [root@MASTER_03 dbbak]# rm -rf /data/3306/data/
[root@MASTER_03 dbbak]# mkdir /data/3306/data
[root@MASTER_03 dbbak]# innobackupex --defaults-file=/etc/my.cnf --copy-back --rsync /data/dbbak/2016-02-04_01-44-24/
[root@MASTER_03 dbbak]# chown -R mysql.mysql /data/3306/data/
登录查看
mysql> select * from t1;
+----+-----------+
| id | name |
+----+-----------+
| 1 | love sql |
| 2 | love sql |
| 3 | love sql |
| 4 | mysql dba |
+----+-----------+
4 rows in set (0.05 sec)
发现数据是已经正确
************************************************************************************
- 摘要:Xtrabackup是基于InnoDB存储引擎灾难恢复的。它复制InnoDB的数据文件,尽管数据文件在内部是非一致性的,但在执行灾难恢复时可以保证这些数据文件是一致的,并且可用。官方原理在InnoDB内部会维护一个redo日志文件,我们也可以叫做事务日志文件。事务日志会存储每一个InnoDB表数据的记录修改。当InnoDB启动时,InnoDB会检查数据文件和事务日志,并执行两个步骤:它应用(前滚)已经提交的事务日志到数据文件,并将修改过但没有提交的数据进行回滚操作。Xtrab
Xtrabackup是基于InnoDB存储引擎灾难恢复的。它复制InnoDB的数据文件,尽管数据文件在内部是非一致性的,但在执行灾难恢复时可以保证这些数据文件是一致的,并且可用。
官方原理
在InnoDB内部会维护一个redo日志文件,我们也可以叫做事务日志文件。事务日志会存储每一个InnoDB表数据的记录修改。当InnoDB启动时,InnoDB会检查数据文件和事务日志,并执行两个步骤:它应用(前滚)已经提交的事务日志到数据文件,并将修改过但没有提交的数据进行回滚操作。
Xtrabackup在启动时会记住log sequence number(LSN),并且复制所有的数据文件。复制过程需要一些时间,所以这期间如果数据文件有改动,那么将会使数据库处于一个不同的时间点。这时,xtrabackup会运行一个后台进程,用于监视事务日志,并从事务日志复制最新的修改。Xtrabackup必须持续的做这个操作,是因为事务日志是会轮转重复的写入,并且事务日志可以被重用。所以xtrabackup自启动开始,就不停的将事务日志中每个数据文件的修改都记录下来。
上面就是xtrabackup的备份过程。接下来是准备(prepare)过程。在这个过程中,xtrabackup使用之前复制的事务日志,对各个数据文件执行灾难恢复(就像mysql刚启动时要做的一样)。当这个过程结束后,数据库就可以做恢复还原了。
以上的过程在xtrabackup的编译二进制程序中实现。程序innobackupex可以允许我们备份MyISAM表和frm文件从而增加了便捷和功能。Innobackupex会启动xtrabackup,直到xtrabackup复制数据文件后,然后执行FLUSH TABLES WITH READ LOCK来阻止新的写入进来并把MyISAM表数据刷到硬盘上,之后复制MyISAM数据文件,最后释放锁。
备份MyISAM和InnoDB表最终会处于一致,在准备(prepare)过程结束后,InnoDB表数据已经前滚到整个备份结束的点,而不是回滚到xtrabackup刚开始时的点。这个时间点与执行FLUSH TABLES WITH READ LOCK的时间点相同,所以myisam表数据与InnoDB表数据是同步的。类似oracle的,InnoDB的prepare过程可以称为recover(恢复),myisam的数据复制过程可以称为restore(还原)。
Xtrabackup和innobackupex这两个工具都提供了许多前文没有提到的功能特点。手册上有对各个功能都有详细的介绍。简单介绍下,这些工具提供了如流(streaming)备份,增量(incremental)备份等,通过复制数据文件,复制日志文件和提交日志到数据文件(前滚)实现了各种复合备份方式。
自己的理解
Xtrabackup只能备份和恢复InnoDB表,而且只有ibd文件,frm文件它不管,恢复时就需要DBA提供frm。innobackupex可以备份和恢复MyISAM表以及frm文件,并且对xtrabackup也做了很好的封装,所以可以使用innobackupex来备份MySQL数据库。还有一个问题,就是innobackupex备份MyISAM表之前要对全库进行加READ LOCK,阻塞写操作,若备份是在从库上进行的话会影响主从同步,造成延迟。对InnoDB表备份不会阻塞读写。
Xtrabackup增量备份的原理是:
1)首先完成一个完全备份,并记录下此时检查点LSN;
2)然后增量备份时,比较表空间中每个页的LSN是否大于上次备份的LSN,若是则备份该页并记录当前检查点的LSN。
具体来说,首先在logfile中找到并记录最后一个checkpoint(“last checkpoint LSN”),然后开始从LSN的位置开始拷贝InnoDB的logfile到xtrabackup_logfile;然后开始拷贝全部的数据文件.ibd;在拷贝全部数据文件结束之后,才停止拷贝logfile。
所以xtrabackup_logfile文件在并发写入很大时也会变得很大,占用很多空间,需要注意。另外当我们使用--stream=tar或者远程备份--remote-host时默认使用/tmp,但最好显示用参数--tmpdir指定,以免把/tmp目录占满影响备份以及系统其它正常服务。
因为logfile里面记录全部的数据修改情况,所以即使在备份过程中数据文件被修改过了,恢复时仍然能够通过解析xtrabackup_logfile保持数据的一致。
Xtrabackup的增量备份只能用于InnoDB表,不能用在MyISAM表上。采用增量备份MySQL数据库时xtrabackup会依据上次全备份或增量备份目录对InnoDB表进行增量备份,对MyISAM表会进行全表复制。
流备份(streaming)可以将备份直接保存到远程服务器上。
当执行恢复时,由于复制是不锁表的所以此时数据文件都是不一致的,xtrabackup使用之前保存的redo log对各个数据文件检查是否与事务日志的checkpoint一致,执行恢复:
1)根据复制数据文件时以及之后已提交事务产生的事务日志进行前滚;
2)将未提交的事务进行回滚。
这个过程就是MySQL数据库宕机之后执行的crash recovery。
增量备份
在InnoDB中,每个page中都记录LSN信息,每当相关数据发生改变,page的LSN就会自动增加,xtrabackup的增量备份就是依据这一原理进行的。Xtrabackup将上次备份(完全备份集或者也是一个增量备份集)以来LSN改变的page进行备份。
所以,要做增量备份第一次就要做一个完全备份(就是将MySQL实例或者说要备份的数据库表做一个完全复制,同时记录LSN),之后可以基于此进行增量备份以及恢复。
增量备份优点:
1)数据库太大没有足够的空间全量备份,增量备份能有效节省空间,并且效率高。
2)支持热备份,备份过程不锁表(针对InnoDB而言),不阻塞数据库的读写。
3)每日备份只产生少量数据,也可采用远程备份,节省本地空间。
4)备份恢复基于文件操作,降低直接对数据库操作风险。
5)备份效率更高,恢复效率更高。
恢复与还原
backup的恢复过程中包括恢复和还原两个部分。
我们前面已经说了xtrabackup只备份InnoDB表的ibd文件,而innobackupex可以备份包括InnoDB表在内的其他存储引擎的表的所有数据文件。由于不同引擎表备份时的不同,也会让恢复过程看起来不一样。
先来看看完全备份集的恢复。
在InnoDB表的备份或者更直接的说ibd数据文件复制的过程中,数据库处于不一致的状态,所以要将xtraback_logfile中尚未提交的事务进行回滚,以及将已经提交的事务进行前滚,
使各个数据文件处于一个一致性状态,这个过程叫做“准备(prepare)”。
如果你是在一个从库上执行的备份,那说明你没有东西需要回滚,只是简单的apply redo log就可以了。另外在prepare过程中可以使用参数--use-memory增大使用系统内存量从而提高恢复速度。
之后,我们就可以根据backup-my.cnf中的配置把数据文件复制回对应的目录了,当然你也可以自己复制回去,但innobackupex都会帮我们完成。在这里,对于InnoDB表来说是完成“后准备”动作,我们称之为“恢复(recovery)”,而对于MyISAM表来说由于备份时是采用锁表方式复制的,所以此时只是简单的复制回来,不需要apply log,这个我们称之为“还原(restore)”。
注:本文档里之所以使用恢复和还原,也是和其他数据库比如Oracle看起来一样。
对于增量备份的恢复过程,与完全备份集的恢复类似,只是有少许不同:
1)恢复过程需要使用完全备份集和各个增量备份集,各个备份集的恢复与前面说的一样(前滚和回滚),之后各个增量备份集的redo log都会应用到完全备份集中;
2)对于完全备机集之后产生的新表,要有特殊处理方式,以便恢复后不丢表;
3)要以完全备份集为基础,然后按顺序应用各个增量备份集。
流备份和压缩
提到流备份(streaming)就要说远程备份和备份压缩,先说流备份吧。
流备份是指备份的数据通过标准输出STDOUT传输给tar程序进行归档,而不是单纯的将数据文件保存到指定的备份目录中,参数--stream=tar表示开启流备份功能并打包。同时也可以利用流备份到远程服务器上。
举例来说,
$ innobackupex --stream=TAR ${BACKUP_DIR}/base | gzip > ${BACKUP_DIR}/base.tar.gz
$ innobackupex --stream=TAR ${BACKUP_DIR}/base|ssh somebackupaddr “cat > ${DIR}/base.tar”12
$ innobackupex --stream=TAR ${BACKUP_DIR}/base | gzip > ${BACKUP_DIR}/base.tar.gz $ innobackupex --stream=TAR ${BACKUP_DIR}/base|ssh somebackupaddr “cat > ${DIR}/base.tar”
当然了,如果你使用了流备份,那么增量备份也就不能用了,因为增量备份需要参考次备份情况,而上次备份却被打包或者压缩了。
在我们现实使用中,更多的使用增量备份,至于归档压缩我们可以通过脚本自主完成。
部分备份和恢复
Xtrabackup可以只备份/恢复部分库表,可以正则模式匹配或者是你想备份库表的列表,但InnoDB表必须是独立表空间,同时不能使用流备份功能。
1)使用正则模式匹配备份部分库表,需要使用参数--include,语句类似如下:
$ innobackupex --include=’^qb.*’ ${BACKUP_DIR}/part-base
1
$ innobackupex --include=’^qb.*’ ${BACKUP_DIR}/part-base
2)使用数据库列表备份部分库,需要使用参数--databases,语句类似如下:
$ innobackupex --databases=qb0 qb1 qb2 qb3 ${BACKUP_DIR}/part-base
1
$ innobackupex --databases=qb0 qb1 qb2 qb3 ${BACKUP_DIR}/part-base
3) 使用表列表备份部分表,需要使用参数--tables-file,语句类似如下:
$ innobackupex --tables-list=${CONF_DIR}/tab.conf ${BACKUP_DIR}/part-base
1
$ innobackupex --tables-list=${CONF_DIR}/tab.conf ${BACKUP_DIR}/part-base
注:在我们的现实应用中,很少会只备份集群中部分库表,所以只是了解此功能即可,若有现实需要可以参考percona官方资料以获取更多信息。
能备份部分库表,也就能根据完全备份集进行部分库表的恢复,在现实中很少会用到,但还是说一下吧。
首先在“准备prepare”的过程中,使用参数--export将表导出,这个导出会将每个InnoDB表创建一个以.exp结尾的文件,这些文件为之后的导入过程服务。
$ innobackupex --apply-log --export ${BACKUP_DIR}/base
1
$ innobackupex --apply-log --export ${BACKUP_DIR}/base
然后将你需要恢复的表的ibd和exp文件复制到目标机器,在目标机器上执行导入:
mysql> create table t() engine=innodb; //此处需要DBA手动创建一个同结构的表或表已存在
mysql> ALTER TABLE t DISCARD TABLESPACE;
$ cp t.ibd t.exp ${DATA_DIR}/${DB}/
mysql> ALTER TABLE t IMPORT TABLESPACE;1234
mysql> create table t() engine=innodb; //此处需要DBA手动创建一个同结构的表或表已存在 mysql> ALTER TABLE t DISCARD TABLESPACE; $ cp t.ibd t.exp ${DATA_DIR}/${DB}/ mysql> ALTER TABLE t IMPORT TABLESPACE;
这样的导出导入就可以保住恢复的表可以与数据库其他表保持一致性了。
并行备份
Xtrbackup还支持并行备份,默认情况下xtrabackup备份时只会开启一个进程进行数据文件的备份,若配置参数--parallel=N可以让xtrabackup开启N个子进程对多个数据文件进行并发备份,这样可以加快备份的速度。当然服务器的IO处理能力以及对服务器的影响也是要考虑的,所以另一个参数--throttle=IOS会与它同时使用,这个参数用来限制备份过程中每秒读写的IO次数,对服务器的IO是一个保护。
这两个参数xtrabackup和innobackupex都支持,举例如下:
$ innobackupex --parallel=4 --throttle=400 ${BACKUP_DIR}/part-base
1
$ innobackupex --parallel=4 --throttle=400 ${BACKUP_DIR}/part-base
注意:对同一个数据文件只会有一个进程在备份。
其他
Xtrabackup在备份时主要的工作是做数据文件复制,它每次只会读写1MB的数据(即64个page,不能修改),xtrabackup逐页访问1MB数据,使用innodb的buf_page_is_corrupted()函数检查此页的数据是否正常,如果数据不正常,就重新读取这一页,最多重新读取10次,如果还是失败,备份就失败了,退出。
在复制事务日志的时候,每次读写512KB的数据,同样不可以配置。
MySQL中的xtrabackup的原理解析的更多相关文章
- mysql中limit的用法实例解析
mysql中limit的用法解析. 在mysql中,select * from table limit m,n.其中m是指记录开始的index,从0开始,n是指从第m条开始,取n条. 例如: mysq ...
- 【原创】Mysql中事务ACID实现原理
引言 照例,我们先来一个场景~ 面试官:"知道事务的四大特性么?" 你:"懂,ACID嘛,原子性(Atomicity).一致性(Consistency).隔离性(Isol ...
- Mysql中事务ACID实现原理
引言 照例,我们先来一个场景~ 面试官:"知道事务的四大特性么?"你:"懂,ACID嘛,原子性(Atomicity).一致性(Consistency).隔离性(Isola ...
- Android中微信抢红包插件原理解析和开发实现
一.前言 自从去年中微信添加抢红包的功能,微信的电商之旅算是正式开始正式火爆起来.但是作为Android开发者来说,我们在抢红包的同时意识到了很多问题,就是手动去抢红包的速度慢了,当然这些有很多原因导 ...
- 【转】Mysql中事务ACID实现原理
转自:https://www.cnblogs.com/rjzheng/p/10841031.html 作者:孤独烟 引言 照例,我们先来一个场景~ 面试官:"知道事务的四大特性么?" ...
- SpringBoot 2.0 中 HikariCP 数据库连接池原理解析
作为后台服务开发,在日常工作中我们天天都在跟数据库打交道,一直在进行各种CRUD操作,都会使用到数据库连接池.按照发展历程,业界知名的数据库连接池有以下几种:c3p0.DBCP.Tomcat JDBC ...
- mysql中group by 的用法解析
1. group by的常规用法 group by的常规用法是配合聚合函数,利用分组信息进行统计,常见的是配合max等聚合函数筛选数据后分析,以及配合having进行筛选后过滤. 假设现有数据库表如下 ...
- spring boot跨域请求访问配置以及spring security中配置失效的原理解析
一.同源策略 同源策略[same origin policy]是浏览器的一个安全功能,不同源的客户端脚本在没有明确授权的情况下,不能读写对方资源. 同源策略是浏览器安全的基石. 什么是源 源[orig ...
- oracle获得日期与向oracle表中插入Date字符串原理解析
工作中要用到 Oracle 9i,经常要向其中的某张表插入事件发生的日期及时间.专门就 Oracle 的日期及时间显示方式和插入方式记一笔. 像 Number,varchar2 等内置的数据类型一样, ...
随机推荐
- 资深程序员的Metal入门教程总结
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由落影发表于云+社区专栏 正文 本文介绍Metal和Metal Shader Language,以及Metal和OpenGL ES的差异 ...
- Python后端相关技术/工具栈
编辑器 最常见: vim / SublimeText2 / PyCharm Vim有兴趣可以看看 k-vim 适合Python/Golang开发 本地环境 pip/easy_install 包管理 v ...
- HDU 3613 Best Reward(拓展KMP算法求解)
题目链接: https://cn.vjudge.net/problem/HDU-3613 After an uphill battle, General Li won a great victory. ...
- C#生成带Logo二维码
1.下载ThoughtWorks.QRCode引用并添加在工程中2.在实现类QRCodeEncoderDemo中引入Dll,添加方法 using System; using System.Collec ...
- [转][MVC4]ASP.NET MVC4+EF5(Lambda/Linq)读取数据
本文转自:https://blog.csdn.net/dingxiaowei2013/article/details/29405687 继续上一节初始ASP.NET MVC4,继续深入学习,感受了一下 ...
- 呼叫WCF Service的方法出现Method not allowed异常
asp.net mvc练习程序,经常性在家里电脑,笔记本或是公司的电脑之间拷贝与粘贴,如果忘记携带最新的练习程序,一些小功能只能重新写了.如前一篇<ASP.NET MVC呼叫WCF Servic ...
- (转).net平台下垃圾回收机制
引言:使用c++进行编程,内存的处理绝对是让每个程序设计者最头疼的一块了.但是对于.net平台下使用c#语言开发系统,内存管理可以说已经不算是问题了.在.net平台下CLR负责管理内存,CLR中的垃圾 ...
- [android] WebView与Js交互
获取WebView对象 调用WebView对象的getSettings()方法,获取WebSettings对象 调用WebSettings对象的setJavaScriptEnabled()方法,设置j ...
- PHP语法-该注意的细节
php in_array(mixed $needle, array $haystack[, bool $strict = FALSE] ) 注意: 一.如果$needle 是字符串,则比较是区分大小写 ...
- Tomcat9.0环境搭建与源码编译
使用IntelliJ IDEA 搭建Tomcat9.0项目 准备条件: 下载源码 这里我们下载的Tomcat的源码版本是9.0.12. 下载地址: https://tomcat.apache ...