stl中顺序性容器,关联容器两者粗略解释
什么是容器
首先,我们必须理解一下什么是容器,在C++ 中容器被定义为:在数据存储上,有一种对象类型,它可以持有其它对象或指向其它对像的指针,这种对象类型就叫做容器。很简单,容器就是保存其它对象的对象,当然这是一个朴素的理解,这种“对象”还包含了一系列处理“其它对象”的方法,因为这些方法在程序的设计上会经常被用到,所以容器也体现了一个好处,就是“容器类是一种对特定代码重用问题的良好的解决方案”。
容器还有另一个特点是容器可以自行扩展。在解决问题时我们常常不知道我们需要存储多少个对象,也就是说我们不知道应该创建多大的内存空间来保存我们的对象。显然,数组在这一方面也力不从心。容器的优势就在这里,它不需要你预先告诉它你要存储多少对象,只要你创建一个容器对象,并合理的调用它所提供的方法,所有的处理细节将由容器来自身完成。它可以为你申请内存或释放内存,并且用最优的算法来执行您的命令。
容器是随着面向对象语言的诞生而提出的,容器类在面向对象语言中特别重要,甚至它被认为是早期面向对象语言的基础。在现在几乎所有的面向对象的语言中也都伴随着一个容器集,在C++ 中,就是标准模板库(STL )。
和其它语言不一样,C++ 中处理容器是采用基于模板的方式。标准C++ 库中的容器提供了多种数据结构,这些数据结构可以与标准算法一起很好的工作,这为我们的软件开发提供了良好的支持!

通用容器的分类
STL 对定义的通用容器分三类:顺序性容器、关联式容器和容器适配器。
顺序性容器 是一种各元素之间有顺序关系的线性表,是一种线性结构的可序群集。顺序性容器中的每个元素均有固定的位置,除非用删除或插入的操作改变这个位置。这个位置和元素本身无关,而和操作的时间和地点有关,顺序性容器不会根据元素的特点排序而是直接保存了元素操作时的逻辑顺序。比如我们一次性对一个顺序性容器追加三个元素,这三个元素在容器中的相对位置和追加时的逻辑次序是一致的。
关联式容器 和顺序性容器不一样,关联式容器是非线性的树结构,更准确的说是二叉树结构。各元素之间没有严格的物理上的顺序关系,也就是说元素在容器中并没有保存元素置入容器时的逻辑顺序。但是关联式容器提供了另一种根据元素特点排序的功能,这样迭代器就能根据元素的特点“顺序地”获取元素。
关联式容器另一个显著的特点是它是以键值的方式来保存数据,就是说它能把关键字和值关联起来保存,而顺序性容器只能保存一种(可以认为它只保存关键字,也可以认为它只保存值)。这在下面具体的容器类中可以说明这一点。
容器适配器 是一个比较抽象的概念, C++的解释是:适配器是使一事物的行为类似于另一事物的行为的一种机制。容器适配器是让一种已存在的容器类型采用另一种不同的抽象类型的工作方式来实现的一种机制。其实仅是发生了接口转换。那么你可以把它理解为容器的容器,它实质还是一个容器,只是他不依赖于具体的标准容器类型,可以理解是容器的模版。或者把它理解为容器的接口,而适配器具体采用哪种容器类型去实现,在定义适配器的时候可以由你决定。
下表列出STL 定义的三类容器所包含的具体容器类:
|
标准容器类 |
特点 |
|
顺序性容器 |
|
|
vector |
从后面快速的插入与删除,直接访问任何元素 |
|
deque |
从前面或后面快速的插入与删除,直接访问任何元素 |
|
list |
双链表,从任何地方快速插入与删除 |
|
关联容器 |
|
|
set |
快速查找,不允许重复值 |
|
multiset |
快速查找,允许重复值 |
|
map |
一对多映射,基于关键字快速查找,不允许重复值 |
|
multimap |
一对多映射,基于关键字快速查找,允许重复值 |
|
容器适配器 |
|
|
stack |
后进先出 |
|
queue |
先进先出 |
|
priority_queue |
最高优先级元素总是第一个出列 |
顺序性容器
向量 vector :
是一个线性顺序结构。相当于数组,但其大小可以不预先指定,并且自动扩展。它可以像数组一样被操作,由于它的特性我们完全可以将vector 看作动态数组。
在创建一个vector 后,它会自动在内存中分配一块连续的内存空间进行数据存储,初始的空间大小可以预先指定也可以由vector 默认指定,这个大小即capacity ()函数的返回值。当存储的数据超过分配的空间时vector 会重新分配一块内存块,但这样的分配是很耗时的,在重新分配空间时它会做这样的动作:
首先,vector 会申请一块更大的内存块;
然后,将原来的数据拷贝到新的内存块中;
其次,销毁掉原内存块中的对象(调用对象的析构函数);
最后,将原来的内存空间释放掉。
如果vector 保存的数据量很大时,这样的操作一定会导致糟糕的性能(这也是vector 被设计成比较容易拷贝的值类型的原因)。所以说vector 不是在什么情况下性能都好,只有在预先知道它大小的情况下vector 的性能才是最优的。
vector 的特点:
(1) 指定一块如同数组一样的连续存储,但空间可以动态扩展。即它可以像数组一样操作,并且可以进行动态操作。通常体现在push_back() pop_back() 。
(2) 随机访问方便,它像数组一样被访问,即支持[ ] 操作符和vector.at()
(3) 节省空间,因为它是连续存储,在存储数据的区域都是没有被浪费的,但是要明确一点vector 大多情况下并不是满存的,在未存储的区域实际是浪费的。
(4) 在内部进行插入、删除操作效率非常低,这样的操作基本上是被禁止的。Vector 被设计成只能在后端进行追加和删除操作,其原因是vector 内部的实现是按照顺序表的原理。
(5) 只能在vector 的最后进行push 和pop ,不能在vector 的头进行push 和pop 。
(6) 当动态添加的数据超过vector 默认分配的大小时要进行内存的重新分配、拷贝与释放,这个操作非常消耗性能。 所以要vector 达到最优的性能,最好在创建vector 时就指定其空间大小。
双向链表list
是一个线性链表结构,它的数据由若干个节点构成,每一个节点都包括一个信息块(即实际存储的数据)、一个前驱指针和一个后驱指针。它无需分配指定的内存大小且可以任意伸缩,这是因为它存储在非连续的内存空间中,并且由指针将有序的元素链接起来。
由于其结构的原因,list 随机检索的性能非常的不好,因为它不像vector 那样直接找到元素的地址,而是要从头一个一个的顺序查找,这样目标元素越靠后,它的检索时间就越长。检索时间与目标元素的位置成正比。
虽然随机检索的速度不够快,但是它可以迅速地在任何节点进行插入和删除操作。因为list 的每个节点保存着它在链表中的位置,插入或删除一个元素仅对最多三个元素有所影响,不像vector 会对操作点之后的所有元素的存储地址都有所影响,这一点是vector 不可比拟的。
list 的特点:
(1) 不使用连续的内存空间这样可以随意地进行动态操作;
(2) 可以在内部任何位置快速地插入或删除,当然也可以在两端进行push 和pop 。
(3) 不能进行内部的随机访问,即不支持[ ] 操作符和vector.at() ;
(4) 相对于verctor 占用更多的内存。
双端队列deque
是一种优化了的、对序列两端元素进行添加和删除操作的基本序列容器。它允许较为快速地随机访问,但它不像vector 把所有的对象保存在一块连续的内存块,而是采用多个连续的存储块,并且在一个映射结构中保存对这些块及其顺序的跟踪。向deque 两端添加或删除元素的开销很小。它不需要重新分配空间,所以向末端增加元素比vector 更有效。
实际上,deque 是对vector 和list 优缺点的结合,它是处于两者之间的一种容器。
deque 的特点:
(1) 随机访问方便,即支持[ ] 操作符和vector.at() ,但性能没有vector 好;
(2) 可以在内部进行插入和删除操作,但性能不及list ;
(3) 可以在两端进行push 、pop ;
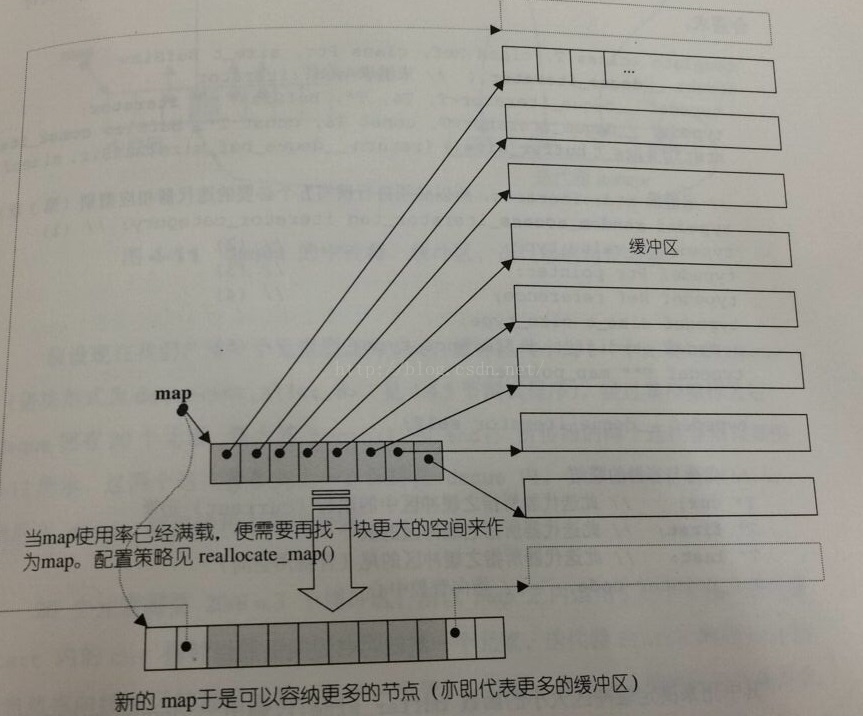
Deque相比于vector而言,它没有容量的概念,因为deque是动态地以分段连续空间组合而成,随时都可以增加一段新的空间并链接起来。为了使得deque在逻辑上看起来是连续空间,在STL内部实现实际是使用了一块map(不是STL中的map容器)作为主控,map是一小块连续空间,其中每个元素都是指针,指向另一段较大的连续线性空间,称为缓冲区,这些缓冲区才是真正存放deque元素的主体。
三者的比较
下图描述了vector 、list 、deque 在内存结构上的特点:

vector 是一段连续的内存块,而deque 是多个连续的内存块, list 是所有数据元素分开保存,可以是任何两个元素没有连续。
vector 的查询性能最好,并且在末端增加数据也很好,除非它重新申请内存段;适合高效地随机存储。
list 是一个链表,任何一个元素都可以是不连续的,但它都有两个指向上一元素和下一元素的指针。所以它对插入、删除元素性能是最好的,而查询性能非常差;适合 大量地插入和删除操作而不关心随机存取的需求。
deque 是介于两者之间,它兼顾了数组和链表的优点,它是分块的链表和多个数组的联合。所以它有被list 好的查询性能,有被vector 好的插入、删除性能。 如果你需要随即存取又关心两端数据的插入和删除,那么deque 是最佳之选。
关联容器
set, multiset, map, multimap 是一种非线性的树结构,具体的说采用的是一种比较高效的特殊的平衡检索二叉树—— 红黑树结构。(至于什么是红黑树,我也不太理解,只能理解到它是一种二叉树结构)
因为关联容器的这四种容器类都使用同一原理,所以他们核心的算法是一致的,但是它们在应用上又有一些差别,先描述一下它们之间的差别。
set ,又称集合,实际上就是一组元素的集合,但其中所包含的元素的值是唯一的,且是按一定顺序排列的,集合中的每个元素被称作集合中的实例。因为其内部是通过链表的方式来组织,所以在插入的时候比vector 快,但在查找和末尾添加上被vector 慢。
multiset ,是多重集合,其实现方式和set 是相似的,只是它不要求集合中的元素是唯一的,也就是说集合中的同一个元素可以出现多次。
map ,提供一种“键- 值”关系的一对一的数据存储能力。其“键”在容器中不可重复,且按一定顺序排列(其实我们可以将set 也看成是一种键- 值关系的存储,只是它只有键没有值。它是map 的一种特殊形式)。由于其是按链表的方式存储,它也继承了链表的优缺点。
multimap , 和map 的原理基本相似,它允许“键”在容器中可以不唯一。
关联容器的特点是明显的,相对于顺序容器,有以下几个主要特点:
1, 其内部实现是采用非线性的二叉树结构,具体的说是红黑树的结构原理实现的;
2, set 和map 保证了元素的唯一性,mulset 和mulmap 扩展了这一属性,可以允许元素不唯一;
3, 元素是有序的集合,默认在插入的时候按升序排列。
基于以上特点,
1, 关联容器对元素的插入和删除操作比vector 要快,因为vector 是顺序存储,而关联容器是链式存储;比list 要慢,是因为即使它们同是链式结构,但list 是线性的,而关联容器是二叉树结构,其改变一个元素涉及到其它元素的变动比list 要多,并且它是排序的,每次插入和删除都需要对元素重新排序;
插入元素(时间耗费):vector > 关联容器 > list
检索元素(时间耗费): list > 关联容器 > vector
2, 关联容器对元素的检索操作比vector 慢,但是比list 要快很多。vector 是顺序的连续存储,当然是比不上的,但相对链式的list 要快很多是因为list 是逐个搜索,它搜索的时间是跟容器的大小成正比,而关联容器 查找的复杂度基本是Log(N) ,比如如果有1000 个记录,最多查找10 次,1,000,000 个记录,最多查找20 次。容器越大,关联容器相对list 的优越性就越能体现;
3, 在使用上set 区别于vector,deque,list 的最大特点就是set 是内部排序的,这在查询上虽然逊色于vector ,但是却大大的强于list 。
4, 在使用上map 的功能是不可取代的,它保存了“键- 值”关系的数据,而这种键值关系采用了类数组的方式。数组是用数字类型的下标来索引元素的位置,而map 是用字符型关键字来索引元素的位置。在使用上map 也提供了一种类数组操作的方式,即它可以通过下标来检索数据,这是其他容器做不到的,当然也包括set 。(STL 中只有vector 和map 可以通过类数组的方式操作元素,即如同ele[1] 方式)
容器适配器
STL 中包含三种适配器:栈stack 、队列queue 和优先级priority_queue 。
适配器是容器的接口,它本身不能直接保存元素,它保存元素的机制是调用另一种顺序容器去实现,即可以把适配器看作“它保存一个容器,这个容器再保存所有元素”。
STL 中提供的三种适配器可以由某一种顺序容器去实现。默认下stack 和queue 基于deque 容器实现,priority_queue 则基于vector 容器实现。当然在创建一个适配器时也可以指定具体的实现容器,创建适配器时在第二个参数上指定具体的顺序容器可以覆盖适配器的默认实现。
由于适配器的特点,一个适配器不是可以由任一个顺序容器都可以实现的。
栈stack 的特点是后进先出,所以它关联的基本容器可以是任意一种顺序容器,因为这些容器类型结构都可以提供栈的操作有求,它们都提供了push_back 、pop_back 和back 操作;
队列queue 的特点是先进先出,适配器要求其关联的基础容器必须提供pop_front 操作,因此其不能建立在vector 容器上;
优先级队列priority_queue 适配器要求提供随机访问功能,因此不能建立在list 容器上。
转载自https://blog.csdn.net/guoshenglong11/article/details/9469881 和 https://blog.csdn.net/lhc548453346/article/details/50822294
stl中顺序性容器,关联容器两者粗略解释的更多相关文章
- STL的基本使用之关联容器:map和multiMap的基本使用
STL的基本使用之关联容器:map和multiMap的基本使用 简介 map 和 multimap 内部也都是使用红黑树来实现,他们存储的是键值对,并且会自动将元素的key进行排序.两者不同在于map ...
- STL的基本使用之关联容器:set和multiSet的基本使用
STL的基本使用之关联容器:set和multiSet的基本使用 简介 set 和 multiSet 内部都是使用红黑树来实现,会自动将元素进行排序.两者不同在于set 不允许重复,而multiSet ...
- STL 笔记(二) 关联容器 map、set、multimap 和 multimap
STL 关联容器简单介绍 关联容器即 key-value 键值对容器,依靠 key 来存储和读取元素. 在 STL 中,有四种关联容器,各自是: map 键值对 key-value 存储,key 不可 ...
- Effective STL 为包含指针的关联容器指定比较类型
// 为包含指针的关联容器指定比较类型.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <set> #incl ...
- STL中的set容器的一点总结2
http://blog.csdn.net/sunshinewave/article/details/8068326 1.关于set C++ STL 之所以得到广泛的赞誉,也被很多人使用,不只是提供了像 ...
- STL中常用容器及操作 学习笔记1
@[TOC](下面介绍STL中常见的容器及操作)## 不定长数组 vector> vetcor:其实就是一个数组或者说是容器 其操作不同于之前直接定义的数组 > 而且可以直接赋值也可以直接 ...
- STL中的Set用法(详+转)
set是STL中一种标准关联容器(vector,list,string,deque都是序列容器,而set,multiset,map,multimap是标准关联容器),它底层使用平衡的搜索树——红黑树实 ...
- 【STL容器学习】-关联容器与map的用法
STL提供了4个关联容器:set.multiset.map和multimap.这些容器提供了通过keyword高速存储和訪问数据元素的能力.Set和map不同意有反复keyword,而multiset ...
- C++基础之关联容器
关联容器 关联容器和顺序容器的本质区别:关联容器是通过键存取和读取元素.顺序容器通过元素在容器中的位置顺序存储和访问元素.因此,关联容器不提供front.push_front.pop_front.ba ...
随机推荐
- Ik分词器没有使用---------elasticsearch-analysis-ik 5.6.3分词问题
此文章在作者认真阅读源码后发现,这并不是问题所在. 此篇文章是对IK配置的错误理解.新版本的IK配置的扩展字典本来就该使用者自己去手动配置! 1.问题 现在项目中用的是ES5.6.3的版本,在解决Fi ...
- Centos6.5 防火墙设置详解
vim /etc/sysconfig/iptables #丢弃所有进入请求 INPUT DROP [0:0] #丢弃所有转发请求 FORWARD DROP [0:0] #允许所有的output请求 O ...
- Spring集成MyBatis的使用-使用SqlSessionTemplate
Spring集成MyBatis的使用 Spring集成MyBatis,早期是使用SqlSessionTemplate,当时并没有用Mapper映射器,既然是早期,当然跟使用Mapper映射器是存在一些 ...
- ORACLE grant权限
oracle的系统和对象权限 本文转自: http://hi.baidu.com/zhaojing_boy/blog/item/0ffe95091266d939e824885f.html alter ...
- 【Nodejs】Expressのファイルアップロード(FileUpload)のMulterについて
https://github.com/expressjs/multer/blob/master/doc/README-zh-cn.md Multer 是一个 node.js 中间件,用于处理 mult ...
- pycharm的安装(图文)
pycharm的安装, PyCharm是一种 IDE,可以在里面对python代码调试.语法高亮.Project管理.跳转.智能提示.自动完成.单元测试.版本控制.pycharm提供了一些高级功能,以 ...
- pta l2-6(树的遍历)
题目链接:https://pintia.cn/problem-sets/994805046380707840/problems/994805069361299456 题意:给出一个二叉树的结点数目n, ...
- Openstack 集群,及常用服务的 高可用 haproxy配置
一.介绍 配置文件位置(yum 安装):/etc/haproxy/haproxy.cfg 全局配置 #------------------------------------------------- ...
- linux之基本命令讲解
前言 [root@localhost python]# vim /root/.bashrc export PS1='\[\e[32;1m\][\u@\h \w \t]#\[\e[0m\] source ...
- 大数据hadoop的伪分布式搭建
1.配置环境变量JDK配置 1.JDK安装 个人喜欢在 vi ~/.bash profile 下配置 export JAVA_HOME=/home/hadoop/app/jdk1.8.0_91ex ...