6.Django扩展
富文本编辑器
- 借助富文本编辑器,管理员能够编辑出来一个包含html的页面,从而页面的显示效果,可以由管理员定义,而不用完全依赖于前期开发人员
- 此处以tinymce为例,其它富文本编辑器的使用可以自行学习
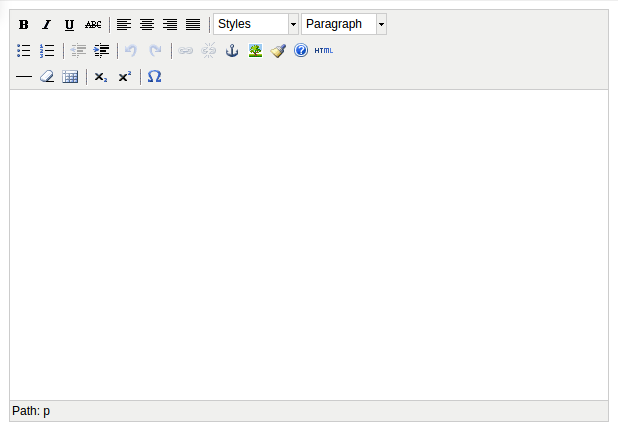
- 使用编辑器的显示效果为:
下载安装
- 在网站pypi网站搜索并下载"django-tinymce-2.4.0"
- 解压
tar zxvf django-tinymce-2.4.0.tar.gz
- 进入解压后的目录,工作在虚拟环境,安装
python setup.py install
应用到项目中
- 在settings.py中为INSTALLED_APPS添加编辑器应用
- INSTALLED_APPS = (
- ...
- 'tinymce',
- )
- 在settings.py中添加编辑配置项
- TINYMCE_DEFAULT_CONFIG = {
- 'theme': 'advanced',
- 'width': ,
- 'height': ,
- }
- 在根urls.py中配置
- urlpatterns = [
- ...
- url(r'^tinymce/', include('tinymce.urls')),
- ]
- 在应用中定义模型的属性
- from django.db import models
- from tinymce.models import HTMLField
- class HeroInfo(models.Model):
- ...
- hcontent = HTMLField()
- 在后台管理界面中,就会显示为富文本编辑器,而不是多行文本框
自定义使用
- 定义视图editor,用于显示编辑器并完成提交
- def editor(request):
- return render(request, 'other/editor.html')
- 配置url
- urlpatterns = [
- ...
- url(r'^editor/$', views.editor, name='editor'),
- ]
- 创建模板editor.html
- <!DOCTYPE html>
- <html>
- <head>
- <title></title>
- <script type="text/javascript" src='/static/tiny_mce/tiny_mce.js'></script>
- <script type="text/javascript">
- tinyMCE.init({
- 'mode':'textareas',
- 'theme':'advanced',
- 'width':,
- 'height':
- });
- </script>
- </head>
- <body>
- <form method="post" action="/content/">
- <input type="text" name="hname">
- <br>
- <textarea name='hcontent'>哈哈,这是啥呀</textarea>
- <br>
- <input type="submit" value="提交">
- </form>
- </body>
- </html>
- 定义视图content,接收请求,并更新heroinfo对象
- def content(request):
- hname = request.POST['hname']
- hcontent = request.POST['hcontent']
- heroinfo = HeroInfo.objects.get(pk=)
- heroinfo.hname = hname
- heroinfo.hcontent = hcontent
- heroinfo.save()
- return render(request, 'other/content.html', {'hero': heroinfo})
- 添加url项
- urlpatterns = [
- ...
- url(r'^content/$', views.content, name='content'),
- ]
- 定义模板content.html
- <!DOCTYPE html>
- <html>
- <head>
- <title></title>
- </head>
- <body>
- 姓名:{{hero.hname}}
- <hr>
- {%autoescape off%}
- {{hero.hcontent}}
- {%endautoescape%}
- </body>
- </html>
缓存
- 对于中等流量的网站来说,尽可能地减少开销是必要的。缓存数据就是为了保存那些需要很多计算资源的结果,这样的话就不必在下次重复消耗计算资源
- Django自带了一个健壮的缓存系统来保存动态页面,避免对于每次请求都重新计算
- Django提供了不同级别的缓存粒度:可以缓存特定视图的输出、可以仅仅缓存那些很难生产出来的部分、或者可以缓存整个网站
设置缓存
- 通过设置决定把数据缓存在哪里,是数据库中、文件系统还是在内存中
- 通过setting文件的CACHES配置来实现
- 参数TIMEOUT:缓存的默认过期时间,以秒为单位,这个参数默认是300秒,即5分钟;设置TIMEOUT为None表示永远不会过期,值设置成0造成缓存立即失效
- CACHES={
- 'default': {
- 'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
- 'TIMEOUT': ,
- }
- }
- 可以将cache存到redis中,默认采用1数据库,需要安装包并配置如下:
安装包:pip install django-redis-cache
- CACHES = {
- "default": {
- "BACKEND": "redis_cache.cache.RedisCache",
- "LOCATION": "localhost:6379",
- 'TIMEOUT': ,
- },
- }
- 可以连接redis查看存的数据
连接:redis-cli切换数据库:select 1查看键:keys *查看值:get 键
单个view缓存
- django.views.decorators.cache定义了cache_page装饰器,用于对视图的输出进行缓存
- 示例代码如下:
- from django.views.decorators.cache import cache_page
- @cache_page( * )
- def index(request):
- return HttpResponse('hello1')
- #return HttpResponse('hello2')
- cache_page接受一个参数:timeout,秒为单位,上例中缓存了15分钟
- 视图缓存与URL无关,如果多个URL指向同一视图,每个URL将会分别缓存
模板片断缓存
- 使用cache模板标签来缓存模板的一个片段
- 需要两个参数:
- 缓存时间,以秒为单位
- 给缓存片段起的名称
- 示例代码如下:
- {% load cache %}
- {% cache hello %}
- hello1
- <!--hello2-->
- {% endcache %}
底层的缓存API
from django.core.cache import cache设置:cache.set(键,值,有效时间)获取:cache.get(键)删除:cache.delete(键)清空:cache.clear()
全文检索
- 全文检索不同于特定字段的模糊查询,使用全文检索的效率更高,并且能够对于中文进行分词处理
- haystack:django的一个包,可以方便地对model里面的内容进行索引、搜索,设计为支持whoosh,solr,Xapian,Elasticsearc四种全文检索引擎后端,属于一种全文检索的框架
- whoosh:纯Python编写的全文搜索引擎,虽然性能比不上sphinx、xapian、Elasticsearc等,但是无二进制包,程序不会莫名其妙的崩溃,对于小型的站点,whoosh已经足够使用
- jieba:一款免费的中文分词包,如果觉得不好用可以使用一些收费产品
操作
1.在虚拟环境中依次安装包
- pip install django-haystack
- pip install whoosh
- pip install jieba
2.修改settings.py文件
- 添加应用
- INSTALLED_APPS = (
- ...
- 'haystack',
- )
- 添加搜索引擎
- HAYSTACK_CONNECTIONS = {
- 'default': {
- 'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
- 'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
- }
- }
- #自动生成索引
- HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
3.在项目的urls.py中添加url
- urlpatterns = [
- ...
- url(r'^search/', include('haystack.urls')),
- ]
4.在应用目录下建立search_indexes.py文件
- # coding=utf-
- from haystack import indexes
- from models import GoodsInfo
- class GoodsInfoIndex(indexes.SearchIndex, indexes.Indexable):
- text = indexes.CharField(document=True, use_template=True)
- def get_model(self):
- return GoodsInfo
- def index_queryset(self, using=None):
- return self.get_model().objects.all()
5.在目录“templates/search/indexes/应用名称/”下创建“模型类名称_text.txt”文件
- #goodsinfo_text.txt,这里列出了要对哪些列的内容进行检索
- {{ object.gName }}
- {{ object.gSubName }}
- {{ object.gDes }}
6.在目录“templates/search/”下建立search.html
- <!DOCTYPE html>
- <html>
- <head>
- <title></title>
- </head>
- <body>
- {% if query %}
- <h3>搜索结果如下:</h3>
- {% for result in page.object_list %}
- <a href="/{{ result.object.id }}/">{{ result.object.gName }}</a><br/>
- {% empty %}
- <p>啥也没找到</p>
- {% endfor %}
- {% if page.has_previous or page.has_next %}
- <div>
- {% if page.has_previous %}<a href="?q={{ query }}&page={{ page.previous_page_number }}">{% endif %}« 上一页{% if page.has_previous %}</a>{% endif %}
- |
- {% if page.has_next %}<a href="?q={{ query }}&page={{ page.next_page_number }}">{% endif %}下一页 »{% if page.has_next %}</a>{% endif %}
- </div>
- {% endif %}
- {% endif %}
- </body>
- </html>
7.建立ChineseAnalyzer.py文件
- 保存在haystack的安装文件夹下,路径如“/home/python/.virtualenvs/django_py2/lib/python2.7/site-packages/haystack/backends”
- import jieba
- from whoosh.analysis import Tokenizer, Token
- class ChineseTokenizer(Tokenizer):
- def __call__(self, value, positions=False, chars=False,
- keeporiginal=False, removestops=True,
- start_pos=, start_char=, mode='', **kwargs):
- t = Token(positions, chars, removestops=removestops, mode=mode,
- **kwargs)
- seglist = jieba.cut(value, cut_all=True)
- for w in seglist:
- t.original = t.text = w
- t.boost = 1.0
- if positions:
- t.pos = start_pos + value.find(w)
- if chars:
- t.startchar = start_char + value.find(w)
- t.endchar = start_char + value.find(w) + len(w)
- yield t
- def ChineseAnalyzer():
- return ChineseTokenizer()
8.复制whoosh_backend.py文件,改名为whoosh_cn_backend.py
- 注意:复制出来的文件名,末尾会有一个空格,记得要删除这个空格
- from .ChineseAnalyzer import ChineseAnalyzer
- 查找
- analyzer=StemmingAnalyzer()
- 改为
- analyzer=ChineseAnalyzer()
9.生成索引
- 初始化索引数据
python manage.py rebuild_index
10.在模板中创建搜索栏
- <form method='get' action="/search/" target="_blank">
- <input type="text" name="q">
- <input type="submit" value="查询">
- </form>
celery
- 官方网站
- 中文文档
- 示例一:用户发起request,并等待response返回。在本些views中,可能需要执行一段耗时的程序,那么用户就会等待很长时间,造成不好的用户体验
- 示例二:网站每小时需要同步一次天气预报信息,但是http是请求触发的,难道要一小时请求一次吗?
- 使用celery后,情况就不一样了
- 示例一的解决:将耗时的程序放到celery中执行
- 示例二的解决:使用celery定时执行
名词
- 任务task:就是一个Python函数
- 队列queue:将需要执行的任务加入到队列中
- 工人worker:在一个新进程中,负责执行队列中的任务
- 代理人broker:负责调度,在布置环境中使用redis
使用
- 安装包
- celery==3.1.
- celery-with-redis==3.0
- django-celery==3.1.
- 配置settings
- INSTALLED_APPS = (
- ...
- 'djcelery',
- }
- ...
- import djcelery
- djcelery.setup_loader()
- BROKER_URL = 'redis://127.0.0.1:6379/0'
- CELERY_IMPORTS = ('应用名称.task')
- 在应用目录下创建task.py文件
- import time
- from celery import task
- @task
- def sayhello():
- print('hello ...')
- time.sleep()
- print('world ...')
- 迁移,生成celery需要的数据表
python manage.py migrate
- 启动Redis
sudo redis-server /etc/redis/redis.conf
- 启动worker
python manage.py celery worker --loglevel=info
- 调用语法
function.delay(parameters)
- 使用代码
- #from task import *
- def sayhello(request):
- print('hello ...')
- import time
- time.sleep()
- print('world ...')
- # sayhello.delay()
- return HttpResponse("hello world")
布署
- 从uwsgi、nginx、静态文件三个方面处理
服务器介绍
- 服务器:私有服务器、公有服务器
- 私有服务器:公司自己购买、自己维护,只布署自己的应用,可供公司内部或外网访问
- 公有服务器:集成好运营环境,销售空间或主机,供其布署自己的应用
- 私有服务器成本高,需要专业人员维护,适合大公司使用
- 公有服务器适合初创公司使用,成本低
- 常用的公有服务器,如阿里云、青云等,可根据需要,按流量收费或按时间收费
- 此处的服务器是物理上的一台非常高、线路全、运行稳定的机器
服务器环境配置
- 在本地的虚拟环境中,项目根目录下,执行命令收集所有包
pip freeze > plist.txt
- 通过ftp软件将开发好的项目上传到此服务器的某个目录
- 安装并创建虚拟环境,如果已有则跳过此步
sudo apt-get install python-virtualenvsudo easy_install virtualenvwrappermkvirtualenv [虚拟环境名称]
- 在虚拟环境上工作,安装所有需要的包
workon [虚拟环境名称]pip install -r plist.txt
- 更改settings.py文件
DEBUG = FalseALLOW_HOSTS=['*',]表示可以访问服务器的ip
- 启动服务器,运行正常,但是静态文件无法加载
WSGI
- python manage.py runserver:这是一款适合开发阶段使用的服务器,不适合运行在真实的生产环境中
- 在生产环境中使用WSGI
- WSGI:Web服务器网关接口,英文为Python Web Server Gateway Interface,缩写为WSGI,是Python应用程序或框架和Web服务器之间的一种接口,被广泛接受
- WSGI没有官方的实现, 因为WSGI更像一个协议,只要遵照这些协议,WSGI应用(Application)都可以在任何服务器(Server)上运行
- 命令django-admin startproject会生成一个简单的wsgi.py文件,确定了settings、application对象
- application对象:在Python模块中使用application对象与应用服务器交互
- settings模块:Django需要导入settings模块,这里是应用定义的地方
- 此处的服务器是一个软件,可以监听网卡端口、遵从网络层传输协议,收发http协议级别的数据
uWSGI
- uWSGI实现了WSGI的所有接口,是一个快速、自我修复、开发人员和系统管理员友好的服务器
- uWSGI代码完全用C编写
- 安装uWSGI
pip install uwsgi
- 配置uWSGI,在项目中新建文件uwsgi.ini,编写如下配置
- [uwsgi]
- socket=外网ip:端口(使用nginx连接时,使用socket)
- http=外网ip:端口(直接做web服务器,使用http)
- chdir=项目根目录
- wsgi-file=项目中wsgi.py文件的目录,相对于项目根目录
- processes=
- threads=
- master=True
- pidfile=uwsgi.pid
- daemonize=uswgi.log
- 启动:uwsgi --ini uwsgi.ini
- 停止:uwsgi --stop uwsgi.pid
- 重启:uwsgi --reload uwsgi.pid
- 使用http协议查看网站运行情况,运行正常,但是静态文件无法加载
nginx
- 使用nginx的作用
- 负载均衡:多台服务器轮流处理请求
- 反射代理:隐藏真实服务器
- 实现构架:客户端请求nginx,再由nginx请求uwsgi,运行django框架下的python代码
- nginx+uwsgi也可以用于其它框架的python web代码,不限于django
- 到官网下载nginx压缩文件或通过命令安装
sudo apt-get nginx
- 这里以下载压缩文件为例演示
解压缩:tar zxvf nginx-1.6.3.tar.gz进入nginx-1.6.3目录依次执行如下命令进行安装:./configuremakesudo make install
- 默认安装到/usr/local/nginx目录,进入此目录执行命令
- 查看版本:sudo sbin/nginx -v
- 启动:sudo sbin/nginx
- 停止:sudo sbin/nginx -s stop
- 重启:sudo sbin/nginx -s reload
- 通过浏览器查看nginx运行结果
- 指向uwsgi项目:编辑conf/nginx.conf文件
sudo conf/nginx.conf在server下添加新的location项,指向uwsgi的ip与端口
- location / {
- include uwsgi_params;将所有的参数转到uwsgi下
- uwsgi_pass uwsgi的ip与端口;
- }
- 修改uwsgi.ini文件,启动socket,禁用http
- 重启nginx、uwsgi
- 在浏览器中查看项目,发现静态文件加载不正常,接下来解决静态文件的问题
静态文件
- 静态文件一直都找不到,现在终于可以解决了
- 所有的静态文件都会由nginx处理,不会将请求转到uwsgi
- 配置nginx的静态项,打开conf/nginx.conf文件,找到server,添加新location
location /static {alias /var/www/test5/static/;}
- 在服务器上创建目录结构“/var/www/test5/”
- 修改目录权限
sudo chmod 777 /var/www/test5
- 创建static目录,注意顺序是先分配权限,再创建目录
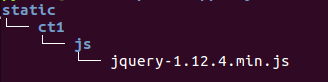
mkdir static
- 最终目录结构如下图:
- 修改settings.py文件
- STATIC_ROOT='/var/www/test5/static/'
- STATIC_URL='/static/'
- 收集所有静态文件到static_root指定目录:python manage.py collectstatic
- 重启nginx、uwsgi
6.Django扩展的更多相关文章
- Django扩展自定义manage命令
使用django开发,对python manage.py ***命令模式肯定不会陌生.比较常用的有runserver,migrate... 本文讲述如何自定义扩展manage命令. 1.源码分析 ma ...
- Django扩展内置User类
内置User类 使用内置User可以方便实现登录验证,利用Admin管理界面还可以方便添加.删除.修改用户. 一个内置的User类定义了以下字段: username: 用户名 password: 密码 ...
- django扩展User认证系统
第一种方法proxy 如果你对Django提供的字段,以及验证的方法都比较满意,没有什么需要改的.但是只是需要在他原有的基础之上增加一些操作的方法.那么建议使用这种方式.示例代码如下: #在model ...
- Django扩展
一.文件上传 当Django在处理文件上传的时候,文件数据被保存在request.FILES FILES中的每个键为<input type="file" name=" ...
- Django扩展Auth-User表的几种方法
方式1, OneToOneField from django.contrib.auth.models import Userclass UserProfile(models.Model): user ...
- django扩展User模型(model),profile
from django.contrib.auth.models import User # Create your models here. class Profile(models.Model): ...
- Python - Django - 扩展默认 auth 表
models.py: from django.db import models from django.contrib.auth.models import AbstractUser class Us ...
- django 过滤器、日日期格式化参数
转载:http://blog.csdn.net/xyp84/article/details/7945094 django1.4 html页面从数据库中读出DateTimeField字段时,显示的时间格 ...
- Django 发布时间格式化
Django在数据库中读取的时间是这种格式: {{title.pub_date} 显示:Nov. 17, 2016, 6:31 p.m. 显然,这不符合我们的习惯,所以需要格式化: {{title.p ...
随机推荐
- 抽屉效果几大github第三方库
首先感谢董铂然博客园,鄙人收藏学习之用,如有朋友看到.有需要请直接前往董铂然博客园本文, 请点击查看原文 在公司项目新版本方案选择中,对主导航中要使用的抽屉效果进行了调研.主要原因是旧的项目中所用的库 ...
- 品味性能之道<十一>:JAVA中switch和if性能比较
通常而言大家普遍的认知里switch case的效率高于if else.根据我的理解而言switch的查找类似于二叉树,if则是线性查找.按照此逻辑推理对于对比条件数目大于3时switch更优,并且对 ...
- NC 6系后台调用接口保存单据
IPFBusiAction ipf = (IPFBusiAction)NCLocator.getInstance().lookup(IPFBusiAction.class); ipf.processA ...
- php mysql 丢失更新
php mysql 丢失更新问题,搜索整个互联网,很少有讲到,也许和php程序员出身一般都是非科班出身有关系吧. 另外php程序一般都是简单数据,很少有并发一致性问题,所以大家都没有谁专门提出这个问题 ...
- libpcap 库使用(三)
1.为了使收到的报文尽快给我们的处理程序,需要设置成immediate模式: int pcap_set_immediate_mode(pcap_t *p, int immediate_mode);
- memcache的add和set区别
add可以做memcache锁 使用场景:用户兑换商品,在网络不好的情况下,点击多次,set会将多次提交全纪录下来,add只会记录一次
- start()方法和run()方法有什么区别?
通过调用线程类的start()方法来启动一个线程,使线程处于就绪状态,即可以被JVM来调度执行,在调度过程中,JVM通过调用线程类的run()方法来完成实际的业务逻辑,当run()方法结束后,此线程就 ...
- install virtualenv
$ [sudo] pip install virtualenv $ mkdir ~/envs $ virtualenv ~/envs/lsbaws/ $ cd ~/envs/lsbaws/ $ ls ...
- DataTable xml 互相转换
//测试方法 public static DataTable Test() { string savePath = System.AppDomain.CurrentDomain.BaseDirecto ...
- Spring中@Autowired注解、@Resource注解的区别 (zz)
Spring中@Autowired注解.@Resource注解的区别 Spring不但支持自己定义的@Autowired注解,还支持几个由JSR-250规范定义的注解,它们分别是@Resource.@ ...