[ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest)
[ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest)
##决策树
决策树算法以树状结构表示数据分类的结果。每个决策点实现一个具有离散输出的测试函数,记为分支。
一棵决策树的组成:根节点、非叶子节点(决策点)、叶子节点、分支
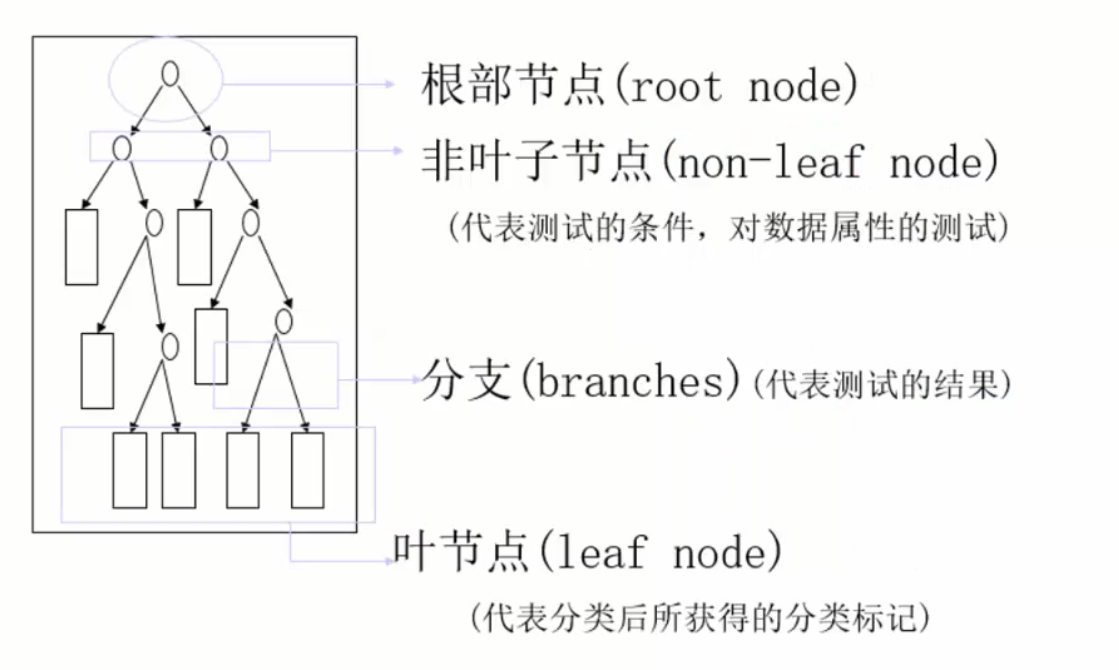
算法分为两个步骤:1. 训练阶段(建模) 2. 分类阶段(应用)
###熵的概念
设用P(X)代表X发生的概率,H(X)代表X发生的不确定性,则有:P(X)越大,H(X)越小;P(X)越小,H(X)越大。
信息熵的一句话解释是:消除不确定性的程度。熵 =$ -\sum_{i=1}^nP_i\log(P_i)$
当熵较小时表示集合较纯,分类效果较好。因此,构造树的基本想法是随着树深度的增加,节点的熵迅速降低,降低的速度越快越好,这样才有望得到一棵高度最矮的决策树。
###如何划分
为了满足上述基本想法,想要选取一个划分标准来为当前集合分类,需要定义一个指标来评判分类效果。
常见的有以下三种指标:
ID3:信息增益(划分前熵值 - 划分后熵值)
C4.5:信息增益率(信息增益 / 划分前的熵值)
CART:Gini系数
最传统的做法就是选取信息增益最大的特征作为划分节点(ID3),但它在一些情况下不适用,比如当存在某些特征的取值很多、每个取值对应的样本数据很少(如id值,会将N个用户划分为N类),此时虽然信息增益大,但其实和样本的划分关系不大(泛化能力弱)。因此引入信息增益率(信息增益 / 划分前的熵值)。
CART分类使用基尼指数(Gini)来选择最好的数据分割的特征,Gini描述的是纯度,与信息熵的含义相似。Gini系数 \(Gini(p)=\sum_{k=1}^Kp_k(1-p_k)=1-\sum_{k=1}^Kp^2\) (同熵一样,值较小时分类效果好)。
引入评价函数:\(C(T)=\sum_{t\in leaf}N_t*H(t)\) ,\(H(t)\)表示熵值或Gini系数值,\(N_t\)表示叶节点中的样本数 (评价函数值越小越好)。
###其他
如何处理连续型的属性:离散化,将连续型属性的值分为不同的区间,依据是比较各个分裂点得到Gain值的大小。
缺失数据的考虑:忽略,即在计算增益时仅考虑那些具有属性值的记录。
当决策树太高、分支太多时很容易过拟合(在训练集上划分为100% 但在测试集上效果不好),于是引入剪枝操作:
- 预剪枝:在构建决策树的过程中,提前停止。如限制深度、限制当前集合的样本个数的最低阈值。
- 后剪枝:在决策树构建好后才开始剪枝。如重新定义评价函数 \(C_\alpha(T)=C(T)+\alpha\cdot\mid T_{leaf}\mid\)(限制叶子节点个数,手动设置\(\alpha\)以控制影响程度),在建树完成之后对每个节点比较剪枝和不剪枝的效果。
##随机森林
随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,本质是一种集成学习(Ensemble Learning)方法。
从直观角度来解释,每棵决策树都是一个分类器,那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的 Bagging 思想。
随机森林体现了两方面的随机:
- 样本随机 不使用全部数据集,而是随机放回采样(有一定概率避免选到异常点,使得树的效果更好)
- 特征随机 不使用全部特征,而是随机选取一部分特征(有一定概率避开使用传统信息增益出问题的特征)
##sklearn库中的决策树算法
使用sklearn自带的决策树方法简单代码如下:
from sklearn import tree
mode = tree.DecisionTreeClassifier(criterion='gini')
mode.fit(X,Y)
y_test = mode.predict(x_test)
参数解释:
1.criterion gini or entropy 选择基尼系数或熵值作为评判标准
2.splitter best or random 在连续的特征中需要做切分 前者是在所有特征中找最好的切分点 后者是在部分特征中(数据量大的时候)
3.max_features None(所有),log2,sqrt,N 当候选特征较多时需要作出选择 特征小于50的时候一般使用所有的
4.max_depth 指定最大深度(预剪枝时使用) 数据少或者特征少的时候可以不管这个值,如果模型样本量多,特征也多的情况下,可以尝试限制下
5.min_samples_split 如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。(预剪枝时使用)
6.min_samples_leaf 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝,如果样本量不大,不需要管这个值,大些如10W可是尝试下5
7.min_weight_fraction_leaf 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。一般来说,如果有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重
8.max_leaf_nodes 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制具体的值可以通过交叉验证得到。
9.class_weight 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
10.min_impurity_split 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
[ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest)的更多相关文章
- 随机森林分类器(Random Forest)
阅读目录 1 什么是随机森林? 2 随机森林的特点 3 随机森林的相关基础知识 4 随机森林的生成 5 袋外错误率(oob error) 6 随机森林工作原理解释的一个简单例子 7 随机森林的Pyth ...
- 随机森林分类(Random Forest Classification)
其实,之前就接触过随机森林,但仅仅是用来做分类和回归.最近,因为要实现一个idea,想到用随机森林做ensemble learning才具体的来看其理论知识.随机森林主要是用到决策树的理论,也就是用决 ...
- 机器学习技法笔记:Homework #7 Decision Tree&Random Forest相关习题
原文地址:https://www.jianshu.com/p/7ff6fd6fc99f 问题描述 程序实现 13-15 # coding:utf-8 # decision_tree.py import ...
- [ML学习笔记] XGBoost算法
[ML学习笔记] XGBoost算法 回归树 决策树可用于分类和回归,分类的结果是离散值(类别),回归的结果是连续值(数值),但本质都是特征(feature)到结果/标签(label)之间的映射. 这 ...
- R语言︱决策树族——随机森林算法
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:有一篇<有监督学习选择深度学习 ...
- web安全之机器学习入门——3.2 决策树与随机森林
目录 简介 决策树简单用法 决策树检测P0P3爆破 决策树检测FTP爆破 随机森林检测FTP爆破 简介 决策树和随机森林算法是最常见的分类算法: 决策树,判断的逻辑很多时候和人的思维非常接近. 随机森 ...
- [ML学习笔记] 朴素贝叶斯算法(Naive Bayesian)
[ML学习笔记] 朴素贝叶斯算法(Naive Bayesian) 贝叶斯公式 \[P(A\mid B) = \frac{P(B\mid A)P(A)}{P(B)}\] 我们把P(A)称为"先 ...
- [ML学习笔记] 回归分析(Regression Analysis)
[ML学习笔记] 回归分析(Regression Analysis) 回归分析:在一系列已知自变量与因变量之间相关关系的基础上,建立变量之间的回归方程,把回归方程作为算法模型,实现对新自变量得出因变量 ...
- 逻辑斯蒂回归VS决策树VS随机森林
LR 与SVM 不同 1.logistic regression适合需要得到一个分类概率的场景,SVM则没有分类概率 2.LR其实同样可以使用kernel,但是LR没有support vector在计 ...
随机推荐
- [Node.js] 3、搭建hexo博客
一.安装新版本的nodejs和npm 安装n模块: npm install -g n 升级node.js到最新稳定版 n stable 二.安装hexo note: 参考github,不要去其 ...
- zoj 2060 Fibonacci Again(fibonacci数列规律、整除3的数学特性)
题目链接: http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=2060 题目描述: There are another kind ...
- 网络之NSURLConnection
数据库总结完之后,下面来总结下网络这块,写博客的目的是为了让想学习IOS的不用去培训机构就能学习. // // ViewController.m // UrlConnection // // Crea ...
- 未能找到路径E:\项目文件\W\vbc.exe”的一部分
网上找的说要引用Microsoft.CodeDom.Providers.DotNetCompilerPlatform, 我已经引用了,是差roslyn文件夹,从别的项目考一份过来就好了
- WPF备忘录(6)WPF实现打印功能
在WPF 中可以通过PrintDialog 类方便的实现应用程序打印功能,本文将使用一个简单实例进行演示.首先在VS中编辑一个图形(如下图所示). 将需要打印的内容放入同一个<Canvas> ...
- 【公众号转载】超详细 Nginx 极简教程,傻瓜一看也会!
什么是Nginx? Nginx (engine x) 是一款轻量级的Web 服务器 .反向代理服务器及电子邮件(IMAP/POP3)代理服务器. 什么是反向代理? 反向代理(Reverse Proxy ...
- centos7: ifconfig出现command not found解决办法
问题 说下我linux配置情况,不一样的可以选择借鉴我的办法. 在虚拟机中以最小化方式安装centos7,ifconfig命令无效,而且在sbin目录中没有ifconfig文件. 原因 这是因为cen ...
- Java - "JUC"之Condition源码解析
Java多线程系列--“JUC锁”06之 Condition条件 概要 前面对JUC包中的锁的原理进行了介绍,本章会JUC中对与锁经常配合使用的Condition进行介绍,内容包括:Condition ...
- 大数据java基础day01
day01笔记 1.==操作符和equals方法 equals方法存在于Object类中,所有类的equals方法都继承于Object 2.String类的常用方法 ①.replace()替换字符串 ...
- ES6——TDZ(暂时性死区)
暂时性的死区(Temporal Dead Zone),简写为 TDZ: 只要块级作用域里存在let命令,它所声明的变量就绑定这个区域,不在受外部的影响 let 和 const 声明的变量不会被提升到作 ...