啰里吧嗦CountDownLatch
java.util.concurrent
Class CountDownLatch
目录
- CountDownLatch 是什么
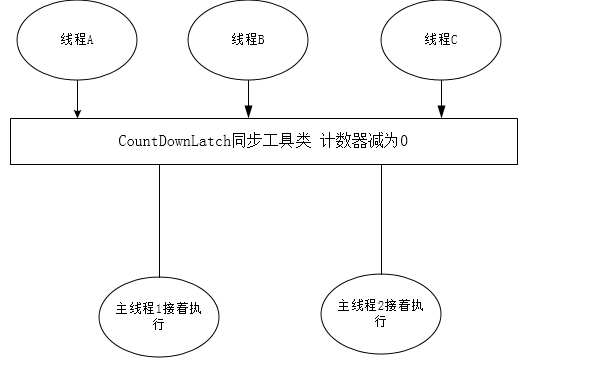
CountDownLatch是一个同步工具类,它允许一个或多个线程一直等待,直到其他线程的操作执行完后再执行
- CountDownLatch 怎么用
CountDownLatch是通过一个计数器来实现的,计数器的初始值为线程的数量,这个值只能被设置一次且后期无法更改
每当一个线程完成了自己的任务后,计数器的值就会减1
当计数器值到达0时,它表示所有的线程已经完成了任务,然后在 闭锁上等待的线程就可以恢复执行任务
线程必须在启动其他线程后立即调用 CountDownLatch.await() 方法
这样主线程的操作就会在这个方法上阻塞,直到其他线程完成各自的任务,并且调用CountDownLatch实例的countDown()方法。
每调用一次这个方法,在构造函数中初始化的count值就减1
直到计数器为0的时候, 停止阻塞
- CountDownLatch 案例
话不多说,直接上
import java.util.concurrent.CountDownLatch;
public class TestCountDownLatch {
static int n = 0;
public static void main(String[] args) {
int thread_num = 10;
final CountDownLatch countDown = new CountDownLatch(thread_num);
long start = System.currentTimeMillis();
for (int i =0; i<thread_num; i++) {
//模拟多线程执行任务 ,启动10个线程,
new Thread(new Runnable(){
@Override
public void run() {
// 比如你想测多线程环境下 饿汉式懒汉式 执行效率
// 可在里面执行要测试的代码,我就简单模拟下
for (int i =0; i<1000; i++) {
n++;
}
System.out.println("线程:" + Thread.currentThread().getName()+" 任务执行完毕");
//计数器减一
countDown.countDown();
}
}).start();
}
try {
//主线程就一直阻塞了
countDown.await();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("线程:" + Thread.currentThread().getName()+" 恢复,开始接着执行");
long end = System.currentTimeMillis()-start;
System.out.println("执行时间:" + end);
}
}
执行结果
线程:Thread-0 任务执行完毕
线程:Thread-2 任务执行完毕
线程:Thread-1 任务执行完毕
线程:Thread-4 任务执行完毕
线程:Thread-3 任务执行完毕
线程:Thread-5 任务执行完毕
线程:Thread-6 任务执行完毕
线程:Thread-8 任务执行完毕
线程:Thread-7 任务执行完毕
线程:Thread-9 任务执行完毕
线程:main 恢复,开始接着执行
执行时间:2
可见主线程之前一直被阻塞,直到所有的线程都执行完毕,再接着执行
如果不使用CountDownLatch, 那么可能其他线程还没执行完, 主线程就结束了, 主线程又不是守护线程
类似这样
线程:Thread-0 任务执行完毕
线程:Thread-1 任务执行完毕
线程:Thread-3 任务执行完毕
线程:Thread-7 任务执行完毕
线程:Thread-2 任务执行完毕
线程:Thread-5 任务执行完毕
线程:main 恢复,开始接着执行
执行时间:19
线程:Thread-4 任务执行完毕
线程:Thread-9 任务执行完毕
线程:Thread-6 任务执行完毕
线程:Thread-8 任务执行完毕
题外话,如果不使用CountDownLatch有没有其他的办法,其实也有
去掉 count相关代码, 加一句
while(Thread.activeCount()>1) //保证前面的线程都执行完
Thread.yield();
System.out.println("线程:" + Thread.currentThread().getName()+" 恢复,开始接着执行");
- CountDownLatch 源码解析
首先,如果让你实现这个工具类, 可想的办法有哪些
1. 比如 在主线程执行的代码里 , 用 threadB.join(), 先执行 B线程的join方法, 再执行主线程
2. 比如 用object对象的 wait(),和notify() notifyAll()方法, 需要注意的是这两个方法需要配合着 synchronized 一起使用,
不然会报 java.lang.IllegalMonitorStateException
亲测, 并且使用wait 锁住的对象 和 notify 唤醒 释放锁的对象必须是同一个
为了方便eclipse步入,我写了个测试类, 然后打断点看的更清楚,
这里模拟CountDown简单写了下
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
public class TestCountDownLatch1 {
private static final class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = 4982264981922014374L;
Sync(int count) {
System.out.println("this" + this);
setState(count);
}
int getCount() {
return getState();
}
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
protected boolean tryReleaseShared(int releases) {
// Decrement count; signal when transition to zero
for (;;) {
int c = getState();
if (c == 0)
return false;
int nextc = c-1;
if (compareAndSetState(c, nextc))
return nextc == 0;
}
}
}
private final Sync sync;
public TestCountDownLatch1(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
this.sync = new Sync(count);
}
public void await() throws InterruptedException {
sync.acquireSharedInterruptibly(1);//在这里打上断点
}
public void countDown() {
sync.releaseShared(1);//在这里打上断点
}
public static void main(String[] args) {
final TestCountDownLatch1 a = new TestCountDownLatch1(11);
try {
a.await();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
首先看CountDownLatch的构造方法
public CountDownLatch(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
this.sync = new Sync(count);
}
发现初始化了sync实例, 并且传入了计数器的值
进入sync构造器,
Sync(int count) {
setState(count);
}
setState点进去,发现是继承的AbstractQueuedSynchronizer类里的方法, 简称AQS,给抽象类的
private volatile int state;
state赋值, 可以猜到 此变量就是实际用来表示计数器的值, 至于为什么要用 volatile关键字, 有兴趣的童鞋可以去看看这篇博客
https://www.cnblogs.com/dolphin0520/p/3920373.html
简单来说volatile关键字保证了其对线程的透明性, 用其修饰的代码 jvm 保证了其的 可见性和有序性 ,相对来说更安全
具体来说就是 当此变量被修改, 会被立即刷新到主存,并且将其他线程的缓存行置为失效状态
被它修饰的变量 不会被进行指令重排序
简单的猜想下,countDown.await();就是阻塞线程, 然后不停的检查state的值, 如果为0, 则停止阻塞
而 countDown.countDown(); 就是将计数器的值减一
好, 现在看countDown的await方法, 将TestCountDownLatch1的断点打好, 然后debug as 启动该类
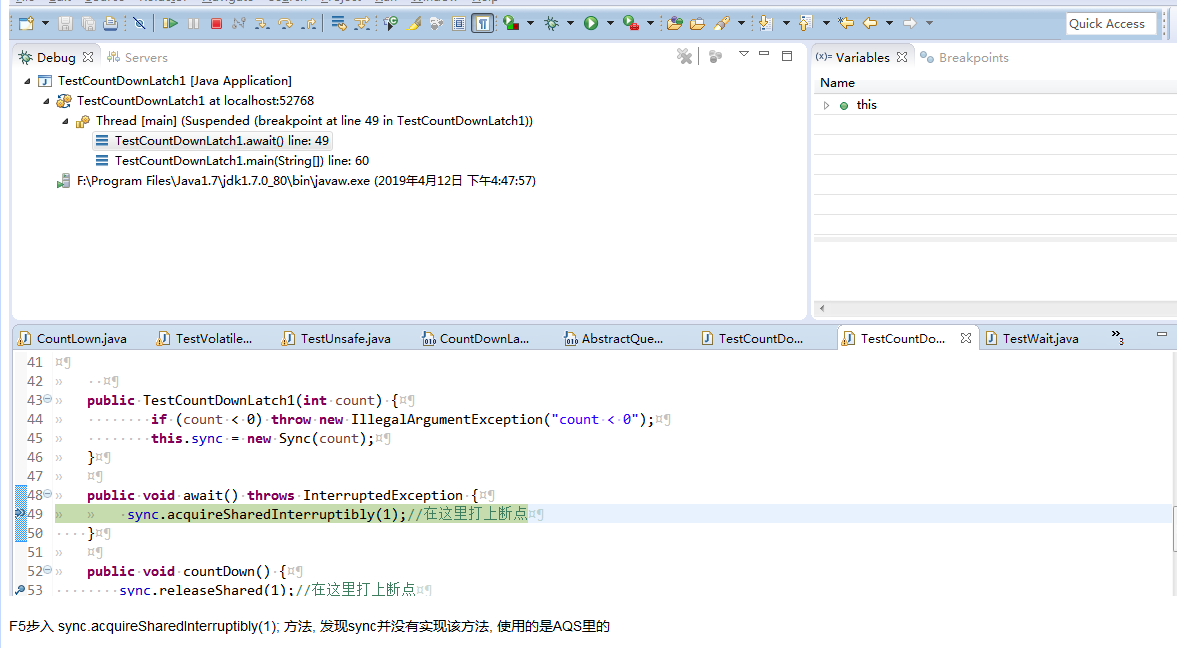
F5步入 sync.acquireSharedInterruptibly(1); 方法, 发现sync并没有实现该方法, 使用的是AQS里的
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
这方法的名字叫 获得 共享的 断点? ,
方法声明了一个InterruptedException异常,表示调用该方法的线程支持打断操作,如果中断了,清除掉, 捕获异常,再接着往下执行
这里先检查了下 线程的中断状态 , 这里要说下, Thread.interrupted()方法
public static void main(String[] args) {
System.out.println(Thread.currentThread().getName());
System.out.println(Thread.interrupted());
Thread.currentThread().interrupt();
System.out.println(Thread.interrupted());
System.out.println(Thread.interrupted());
)
main
false
true
false
该方法是获得线程的中断状态,并且会清除线程的中断
再接着往下看, 别忘了此时的arg 是1 , 虽然在CountDownLatch工具类中没有用到, 但其他工具类有可能会用
AQS有两套方式获取锁,一个独占式,一个共享式
独占式就是只能一个线程访问,例如Reentrantlock,同步队列每次也只唤醒一个线程;
共享式就是多个线程访问,例如CountDownLatch,同步队列唤醒头节点,然后依次唤醒后面所有节点,实现共享状态传播
方法名:尝试 获得 共享 ,
tryAcquireShared(arg) < 0
马后炮猜猜这个方法的作用,
这个方法应该是判断计数器是否为0, 为0 则不阻塞了, 线程接着往下走, 不为0 ,
则继续阻塞
返回true
接着执行doAcquireSharedInterruptibly
接着F5步入, 发现是CountDownLatch的Syn内部静态类自己重写了此方法
根据名字和判断<0 这个值 , 我觉得这个方法的含义是 返回值 如果 >=0, 那么就是 获得 共享了, 然后停止阻塞, 线程接着往下执行
返回负数 就表示 获取失败, 接着阻塞吧
//共享的模式下获取状态
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
果然, 入参acquires,也就是 arg 是没什么用的, 它判断 AQS的state 计数器是不是0 , 如果为0 返回1 ,
那么 1<0 为false ,方法直接结束退出
我们代码里设置的是10, 返回-1,那么接着看 doAcquireSharedInterruptibly 方法
AQS里的 方法名: 去做 获得 共享 中断 --不必在意 瞎解释的
private void doAcquireSharedInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.SHARED); // 添加Node节点 不明白为什么要这样写 static final Node SHARED = new Node(); 一个静态的node对象
.........
}
这里先看下AQS里的一个代码图
* +------+ prev +-----+ +-----+
* head | | <---- | | <---- | | tail
* +------+ +-----+ +-----+
*

接着进去看 addWaiter方法, 名字上看是 添加等待者,
这里实际上要说下AQS,抽象的同步队列, AQS里有个 static final class Node {}, 静态内部类,
该类里面有 volatile Node prev; // 指向 当前节点的 前一个节点
volatile Node next; // 指向 当前节点的 后一个节点
volatile Thread thread; //放入线程 包装线程
当然如果是头节点,那么它的prev为null,同理尾节点的next为null
然后AQS里有
private transient volatile Node head;
private transient volatile Node tail;
用来表示同步队列的头节点和尾节点
接着F5步入addWaiter方法
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode); //包装节点 当前节点 置入 当前线程对象 和 Node对象
// Try the fast path of enq; backup to full enq on failure
Node pred = tail; // 声明尾节点
if (pred != null) { //
node.prev = pred; // 如果尾节点不为空, 那么新节点 的 前一个节点 是尾节点 ,
if (compareAndSetTail(pred, node)) { // 毕竟是多线程操作, 1-N个线程都能被阻塞, 等待, 添加到队列里, 有volatile关键字还不够
// 还需要 cas 方式替换AQS里的 尾节点对象 compareAndSetTail , 会比较 pred 和 现在AQS的尾节点是不是一个对象
// 如果是 则替换 node 为新的尾节点 替换成功 , 则之前的尾节点的 next 指向 新的尾节点
pred.next = node;
return node; //
}
}
enq(node); //我们只有主线程阻塞, 而且是第一次进来, 所以尾节点 头节点 肯定都是空的, 所以走这里
return node;
}
额外小芝士:
很多人不明白compareAndSetTail(pred, node) 是什么, 这个其实是CAS, Compare And SWAP, 先比较 , 再替换, 只有比较的和预期对象相等, 才会替换成新的对象
模仿着写个小荔枝
package thead1;
import sun.misc.Unsafe;
import java.lang.reflect.Field;
public class TestUnsafe {
public static void main(String[] args) {
Node node = new Node();
/**
* 通过CAS方法更新node的next属性
* 原子操作
*/
Node n = new Node();
boolean flag = node.casNext(null,n);// 一开始的 volatile Node next; 确实是null
System.out.println(flag); //true ,被更新成n
flag = node.casNext(new Node(),new Node()); //没更新 , 因为现在 next 应该是n 指向的对象
System.out.println(flag);//false
flag = node.casNext(n,new Node());
System.out.println(flag);//true
}
private static class Node{
volatile Node next;
/**
* 使用Unsafe CAS方法
* @param cmp 目标值与cmp比较,如果相等就更新返回true;如果不相等就不更新返回false;
* @param val 需要更新的值;
* @return
*/
boolean casNext(Node cmp, Node val) {
/**
* compareAndSwapObject(Object var1, long var2, Object var3, Object var4)
* var1 操作的对象
* var2 操作的对象属性 而这个offset只是记录该属性放哪 , 比较的应该是属性 所指的对象 的地址
* var3 var2与var3比较,相等才更新
* var4 更新值
*/
System.out.println("nextOffset : " +nextOffset + " this " +this + " cmp " +cmp
+ " val " +val + " next " + next);
Boolean a = UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
System.out.println(" next " + next + " 更新结果 " + a);
return a;
}
private static final sun.misc.Unsafe UNSAFE;
private static final long nextOffset;
static {
try {
UNSAFE = getUnsafe();
Class<?> k = Node.class;
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
/**
* 获取Unsafe的方法
*
* @return
*/
public static Unsafe getUnsafe() {
try {
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
return (Unsafe)f.get(null);
} catch (Exception e) {
return null;
}
}
}
}
会发现第一次更新成功 , 应该刚new 的node对象 next属性为null ,
还记得 之前的volatile 关键字吗 , 由于不保证原子性 , 如果多个线程进行更新, 就会出现问题
比如 i++ 可以拆分成3个动作
读取i的原始值 i副本压入操作数栈
对i进行+1 操作,
弹出操作数栈,写入主存
比如线程A 读取i 的值10, 正准备向cpu发送指令 +1时被阻塞了, 线程A由于还没修改, 不会导致线程B的工作内存中缓存变量inc的缓存行无效
然后线程B 也去读, 线程A还没修改, 线程B 读内存的值10 , +1 , 然后把11 写入工作内存,写入主存 volatile虽然保证线程B修改后可以另其他线程缓存行失效,并立即写入主存
但此时线程A已经读到了i的值,
线程A已经读取到了值, 不在涉及读操作, 所以并没有更新缓存,(我的理解是如果线程A 还需要读, 那么才会发现自己的缓存失效了, 那么才从主存读11)
之前已经把操作数放入了自己的操作数栈中 线程A才中断的 CPU由于保存了上次线程A的工作状态
因此, 轮到线程A工作时, 会继续上次的操作, 即: 开始对操作数栈中的数进行+1操作, 然后立即刷回主存, 因此不再涉及读操作,否则CPU保存线程的工作状态将毫无意义
变成11 写入主存
两次操作,只加了1
写个例子证明下
package thead1;
import java.lang.reflect.Field;
import sun.misc.Unsafe;
public class TestVolatile {
private volatile int i = 0 ;
private int j = 0 ;
private volatile int next = 0 ;
private static final sun.misc.Unsafe UNSAFE;
private static final long nextOffset;
public static Unsafe getUnsafe() {
try {
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
return (Unsafe)f.get(null);
} catch (Exception e) {
return null;
}
}
static {
try {
UNSAFE = getUnsafe();
Class<?> k = TestVolatile.class;
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
public final boolean compareAndSetState(int expect, int update) {
// See below for intrinsics setup to support this
return UNSAFE.compareAndSwapInt(this, nextOffset, expect, update);
}
public void add () {
i++;
}
public void add1 () {
synchronized(this) {
j++;
}
}
public void add2 () {
int c = next;
int nextc = c+1;
for ( ;; ){
if (compareAndSetState(c, nextc)){
return;
}
}
}
public static void main(String[] args) {
final TestVolatile tr = new TestVolatile();
for (int i =0; i<10; i++) {
new Thread(new Runnable(){
@Override
public void run() {
// TODO Auto-generated method stub
for (int i =0; i<300; i++) {
tr.add();
tr.add1();
//tr.add2();
}
}
}).start();;
}
for (int i =0; i<10; i++) {
new Thread(new Runnable(){
@Override
public void run() {
// TODO Auto-generated method stub
for (int i =0; i<300; i++) {
tr.add2();
}
}
}).start();;
}
while(Thread.activeCount()>1) //保证前面的线程都执行完
Thread.yield();
//然main方法等到他们都执行完了在打印
System.out.println(tr.i);
System.out.println(tr.j);
System.out.println(tr.next);
}
}
可以看到变量i 虽然加了volite, 依然不能保证每次执行的结果是3000,
synchronized是用来对比的
线程方法里面的循环可以设置成10000会更明显点, i总是低于10w的一个数
那么用CAS原子性的方式去更改能不能保证呢, 答案是肯定了, 我试了很多次
next的结果和 j的结果都一样 ,
附: 有个小疑问, 就是当线程里循环的次数是1w时, 很容易停住不动, 是产生死锁了吗
所以才用的300 200来测试
好的, 题外话说完, 在接着回到AQS,
addWaiter 方法里, 由于我们是第一次进入, 所以AQS的尾节点肯定是空的, 执行enq()方法
private Node enq(final Node node) {
for (;;) {//死循环
Node t = tail;//拿到尾节点
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))// 必须初始化尾节点, 还是cas, 判断头节点是空的, 那么就new 一个节点实例给 头节点
tail = head; // 头节点 尾节点 都用一个 实例对象
} else {
node.prev = t; // 尾节点不为空 将 当前节点的 prev 前一个节点执行 尾节点 head tail <----prev---node
if (compareAndSetTail(t, node)) {// 只有将 尾节点 替换为 当前节点 这个时候方法才结束 退出
t.next = node; head tail <----prev---node 就是新的尾节点
return t; -----next --->
}
}
}
}
这个方法很简单, 就是初始化尾节点和头节点, 并且设置 当前node 为新的尾节点, 然后把前后关系都关联上 ,在回到addWaiter方法
然后返回 新加的 这个尾节点
在回到doAcquireSharedInterruptibly
private void doAcquireSharedInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.SHARED);// 添加新的节点 为尾节点 并且初始化节点 并且设置新的节点为尾节点 暂时不明白为什么要包装一下 塞一个静态的Node对象
boolean failed = true;
try {
for (;;) {//死循环 注意退出条件
final Node p = node.predecessor();//不带着看了, 点进去其实就是 返回 当前节点的 上一个节点 ,如果为空抛异常,
if (p == head) {// 如果 当前节点的 上一个节点 就是 头节点 , 我们第一次进来 其实是的, 还记得 enq里的方法吗 , 头尾节点都是一个地址, 当前节点是尾节点, 指向上一个节点即头尾
int r = tryAcquireShared(arg); // 不解释了 子类重写的方法 自己定义什么情况下能够获得共享 , 不在阻塞 , 第一次进来肯定是 -1
if (r >= 0) {
setHeadAndPropagate(node, r);//在同步队列中挂起的线程,它们自省的观察自己是否满足条件醒来(state==0,且为头节点),如果成立将调用setHeadAndPropagate这个方法
p.next = null; // help GC
failed = false;
return;// 所以第一次进来无法退出 , 然后我发现F6一直走 ,到了判断下面的if 条件后, 走两遍, eclipse的步入 下一步都置灰了, 可能是判断如果没有新的条件, 死循环无法退出吧,
//所以一直阻塞着这里
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed) // 只有 上面第二个if条件 中断退出 才会执行 这个方法
cancelAcquire(node);
}
}
如果计数器为0 , tryAcquireShared 为1大于等于0 , 设置头节点和 传播 共享状态
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head; // Record old head for check below
setHead(node);
if (propagate > 0 || h == null || h.waitStatus < 0) { //
Node s = node.next; // 获得 当前节点的 下一个节点
if (s == null || s.isShared())
doReleaseShared();
}
}
设置当前节点为头节点 那么很自然 当前节点的前一个节点 即本来的头节点为空
private void setHead(Node node) {
head = node;
node.thread = null;
node.prev = null;
}
看到这里其实 countDown的方法也能猜到大概了
其实就是 想办法让 state技术器的值减1 , 还得保证线程安全,
volatile其实适合一写多读, 如果多个线程都写, 那么就需要CAS去更新
由于我们测试代码是阻塞一个main线程, 其实CountDownLatch能同时阻塞多个线程, 所以才用到队列
然后await()方法死循环里检测到条件满足了, 就退出死循环,退出阻塞, 接着往下执行了
之前我们了解到, 当不满足tryAcquireShared(),条件时,
await()方法就一直 死循环阻塞
那么猜countDown()方法除了让计数器减一以外, 还需要依次唤醒被阻塞的线程
即 当前线程节点 的前一个节点 为 头节点 , 当它满足这个条件 , 同时计数器又为0
猜测应该会 将该节点移除 , 将 头节点的下一个设置为null, p.next = null
该线程退出这个死循环
同时后面的那个 线程 应该会补上 , 它的prev 指向 头节点
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
failed = false;
return;
}
}
- CountDownLatch 的 countDown 源码解析
public void countDown() {
sync.releaseShared(1);//在countDownLatch 这个入参没什么用
}
AQS里的
名字: 可能意思就是 释放 共享的 猜测这个方法就尝试 释放共享的锁
主要就是调用同步器的tryReleaseShared方法来释放状态,并同时在doReleaseShared方法中唤醒其后继节点
调用该方法释放共享状态,每次获取共享状态acquireShared都会操作状态,
同样在共享锁释放的时候,也需要将状态释放。比如说,一个限定一定数量访问的同步工具,每次获取都是共享的,
但是如果超过了一定的数量,将会阻塞后续的获取操作,只有当之前获取的消费者将状态释放才可以使阻塞的获取操作得以运行
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {// 子类负责实现 自定义 返回true 就表示要释放 否则不管
doReleaseShared(); //我设置了11个线程 每次都是 false , 直到最后一个线程执行 该方法时 state变成0 走这里
return true;
}
return false;//
}
CountDownLatch 可以把TestNode 的count 设置成1 在打断点 看下
//共享的模式下释放状态
protected boolean tryReleaseShared(int releases) {
// Decrement count; signal when transition to zero
for (;;) { //死循环
int c = getState(); // 获取计数器
if (c == 0)
return false;// 如果计数器为0 退出
int nextc = c-1; // 第一个线程进来时 11 变10
if (compareAndSetState(c, nextc)) //CAS 比较 c 和 AQS里的state是不是一样的 一样的则更新为10 在for死循环中 直到更新成功
return nextc == 0;// 如果为0 则退出 返回true
}
}
名字的意思可能是 做 释放 共享锁的事 state为0 的时候执行此方法
为了看head 头节点的ws 何时变成-1, 重新跟踪await, 发现 直到初始化头节点 ws都是0 ,
shouldParkAfterFailedAcquire 在此方法里 将头节点的ws 变成了-1
int waitStatus
表示节点的状态。其中包含的状态有:
CANCELLED,值为1,表示当前的线程被取消;
SIGNAL,值为-1,表示当前节点的后继节点包含的线程需要运行,也就是unpark;
CONDITION,值为-2,表示当前节点在等待condition,也就是在condition队列中;
PROPAGATE,值为-3,表示当前场景下后续的acquireShared能够得以执行;
值为0,表示当前节点在sync队列中,等待着获取锁。
private void doReleaseShared() {
for (;;) {
Node h = head;//头节点
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) { // -1 如果当前节点是single 表示它等待被唤醒 然后我设置count为1 走此方法看 ws为-1 , 因为
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0)) 重置waitStatus标志位 为0
continue; // loop to recheck cases
unparkSuccessor(h); // 重置成功 唤醒下一个节点 unpark 开走停着的汽车 唤醒 successor 继承者
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE)) 同时把头节点的 0-0 替换成 -3 失败了 则接着循环
continue; // loop on failed CAS
}
if (h == head) // loop if head changed
break;// 退出条件 h==head,即该线程是头节点,且状态为共享状态
}
}
为啥执着的猜名字, 因为写代码通常讲究见名知意, 如果名字起得好 , 别人看起来事半功倍
所以总结一下, CountDownLatch内部实现了一个静态内部类syn,主要利用了AQS这个抽象的同步队列类, 也可以叫同步器,
调用await 是调用AQS的 acquireSharedInterruptibly (该方法提供获取状态能力,在无法获取状态的情况下会进入sync队列进行排队), 进行线程中断和排队
调用countDown 实际上就是调用 releaseShared 方法释放共享状态
- 结束语
学无止境, 学海无涯
参考:https://www.cnblogs.com/yanphet/p/5788260.html
水平有限,欢迎讨论
啰里吧嗦CountDownLatch的更多相关文章
- 啰里吧嗦jvm
一.为什么要了解jvm 有次做项目的时候,程序run起来的时候,总是报OutOfMemoryError,有老司机教我们用jconsole.exe看内存溢出问题 就是这货启动jconsole后,发现一个 ...
- 啰里吧嗦redis
1.redis是什么 redis官网地址 Redis is an open source (BSD licensed), in-memory data structure store, used as ...
- 啰里吧嗦kafka
1.kafka是什么 kafka官网: http://kafka.apache.org/ kafka是一种高吞吐量的分布式发布订阅消息系统,用它可以在不同系统中间传递分发消息 2.zookeeper是 ...
- 啰里吧嗦式讲解java静态代理动态代理模式
一.为啥写这个 文章写的比较啰嗦,有些东西可以不看,因为想看懂框架, 想了解SSH或者SSM框架的设计原理和设计思路, 又去重新看了一遍反射和注解, 然后看别人的博客说想要看懂框架得先看懂设计模式,于 ...
- 一步步学习操作系统(1)——参照ucos,在STM32上实现一个简单的多任务(“啰里啰嗦版”)
该篇为“啰里啰嗦版”,另有相应的“精简版”供参考 “不到长城非好汉:不做OS,枉为程序员” OS之于程序员,如同梵蒂冈之于天主教徒,那永远都是块神圣的领土.若今生不能亲历之,实乃憾事! 但是,圣域不是 ...
- 啰哩吧嗦式讲解在windows 家庭版安装docker
1.docker是什么,为什么要使用docker Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中, 然后发布到任何流行的 Linux 机器上,也可以实 ...
- IDDD 实现领域驱动设计-理解领域和子域
上一篇:<IDDD 实现领域驱动设计-一个简单业务用例的回顾和理解> 在<实现领域驱动设计>第二章的前半部分内容中,提到领域和子域的概念,并且作者把这两者又进行了细致的区分,其 ...
- Css 动画的回调
在做项目中经常会遇到使用动画的情况.以前的情况是用js写动画,利用setTimeout函数或者window.requestAnimationFrame()实现目标元素的动画效果.虽然后者解决了刷新频率 ...
- 浅谈独立使用NDK编译库文件(Android)
阅读前准备 这是一篇相对入门的文章.文中会涉及到少许NDK的知识,但个人认为对初学者来说都相对比较实用,因为都是在平时项目中遇到的(目前自己也是初学者).一些其他高深的技术不再本文探讨范围之内(因为我 ...
随机推荐
- WPF App.xaml.cs常用模板,包括:异常捕获,App只能启动一次
App.xaml.cs中的代码每次都差不多,故特地将其整理出来直接复用: using System; using System.Configuration; using System.Diagnost ...
- 在Node中使用ES6语法
Node本身已经支持部分ES6语法,但是import export,以及async await(Node 8 已经支持)等一些语法,我们还是无法使用.为了能使用这些新特性,我们就需要使用babel把E ...
- Django(ORM查询2)
day70 ORM训练专题 :http://www.cnblogs.com/liwenzhou/articles/8337352.html 内容回顾 1. ORM 1. ORM ...
- Dubbo原理实现之代理接口的定义
Dubbo有很多的实现采用了代码模式,Dubbo由代理工厂ProxyFactory对象创建代理对象. ProxyFactory接口的定义如下: @SPI("javassist") ...
- C#6.0语言规范(十五) 委托
委托启用其他语言(如C ++,Pascal和Modula)已使用函数指针进行寻址的方案.但是,与C ++函数指针不同,委托是完全面向对象的,与成员函数的C ++指针不同,委托封装了对象实例和方法. 委 ...
- 设计模式《JAVA与模式》之责任链模式
在阎宏博士的<JAVA与模式>一书中开头是这样描述责任链(Chain of Responsibility)模式的: 责任链模式是一种对象的行为模式.在责任链模式里,很多对象由每一个对象对其 ...
- day 71 crm(8) 权限组件的设置,以及权限组件的应用
---恢复内容开始--- 前情提要: strak 组件是增删改查组件 , 生活中,需求权限组件, 不足: 1,前后端不分离, 2, 空url也会刷新界面,造成资源浪费 3,如果角色忘记设置权 ...
- WebRTC开发基础(WebRTC入门系列2:RTCPeerConnection)
RTCPeerConnection的作用是在浏览器之间建立数据的“点对点”(peer to peer)通信. 使用WebRTC的编解码器和协议做了大量的工作,方便了开发者,使实时通信成为可能,甚至在不 ...
- charles撰写工具/compose和Compose New
撰写工具/compose和Compose New compose 是在原有的请求基础上,修改: compose New 是新出一个弹窗,自己手动一个个的去写: 可以写各种状态:– URL:– Meth ...
- maven-compiler-plugin 指定jdk的版本和编码
为了让maven的jdk编译版本一致, 使用maven-compiler-plugin插件来协助管理 建议新建maven项目后的第一步就是配置该插件 <build> <plugins ...