Eligibility Traces and Plasticity on Behavioral Time Scales: Experimental Support of neoHebbian Three-Factor Learning Rules
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Abstract
大多数基本行为,如移动手臂抓住物体或走进隔壁房间探索博物馆,都是在几秒钟的时间尺度上进化的;相反,神经元动作电位则是在几毫秒的时间尺度上发生的。因此,大脑的学习规则必须弥合这两个不同时间尺度之间的差距。现代的突触可塑性理论假设,突触前和突触后神经元的共同激活在突触上设置了一个标记,称为资格迹。只有在标记设置时存在一个额外的因素时,这个标记才会导致权重变化。第三个因素,发送奖励、惩罚、惊奇(Surprise)或新奇(Novelty)信号,可以通过神经调节剂的阶段性活动或特定的神经元输入信号特殊事件来实现。虽然理论框架是在过去几十年中发展起来的,但在过去几年中才收集到支持秒时间尺度上资格迹的实验证据。在这里,我们回顾了在突触可塑性三因素规则的背景下,支持突触资格迹与第三个因素结合作用的四个关键实验,作为neoHebbian三因素学习规则的生物学实现。
Keywords:资格迹,Hebb规则,强化学习,神经调节剂,惊奇(Surprise),突触标记,突触可塑性,行为学习
1 Introduction
人类能够学习诸如按下按钮、挥动网球拍或闯红灯等新奇的行为;他们还能够形成对重大事件的记忆,学会辨别花朵,并在探索新奇环境时建立一个心理地图。记忆形成和行为学习与突触连接的变化有关(Martin et al., 2000)。对于记忆来说,长期持续的突触变化是必要的,可以由Hebbian规则诱导,将突触前末端的激活与突触后神经元的电压或发放状态的操纵结合起来(Lisman, 2003)。长期增强(LTP)的传统实验方案(Bliss and Lømo, 1973;Bliss and Collingridge, 1993)、长期抑制(LTD)(Levy and Stewart, 1983;Artola and Singer, 1993)和脉冲时间依赖可塑性(STDP)(Markram et al., 1997;Zhang et al., 1998;Sjöström et al., 2001)忽略了神经调节剂或其他门控信号等其他因素可能是允许突触改变的必要条件(Gu, 2002;Hasselmo, 2006;Reynolds and Wickens, 2002)。早期涉及神经调节剂的STDP实验主要集中在调节因素的tonic bath应用上(Pawlak et al., 2010)。然而,从形式学习理论的角度来看,调节因素的时机同样至关重要(Schultz and Dickinson, 2000;Schultz, 2002)。从理论上看,在神经调节剂控制下的STDP导致了三因素学习规则的框架(Xie and Seung, 2004;Legenstein et al., 2008;Vasilaki et al., 2009),其中资格迹代表了Hebbian关于突触前和突触后神经元共同激活的想法(Hebb, 1949),同时可塑性的调节通过额外的门信号通常由“第三个因素”表示(Crow, 1968;Barto, 1985;Legenstein et al., 2008)。第三个因素可以表示诸如“奖励减去预期奖励”(Williams, 1992;Schultz, 1998;Sutton and Barto, 1998)或意外事件的显著性(Ljunberg and amd W.Schultz, 1992;Redgrave and Gurney, 2006)等变量。
在之前的一篇论文(Frémaux and Gerstner, 2016)中,我们回顾了2013年底前可用的三因素规则的理论文献和实验支持。然而,近年来,实验程序取得了显著进展,首次提供了资格迹和三因素学习规则的直接生理证据,因此有必要对三因素规则进行更新。在下文中,我们 —— 一组理论家 —— 回顾了五篇实验论文,表明纹状体(Yagishita et al., 2014)、皮层(He et al., 2015)和海马体(Brzosko et al., 2015, 2017;Bittner et al., 2017)中资格迹的支持。最后,我们将对计算神经科学领域中理论预测的自相矛盾性发表几点看法。
2 Hebbian rules versus three-factor rules
学习规则描述了突触前神经元 j 和突触后神经元 i 之间突触接触强度的变化。兴奋性突触接触强度可以由突触后电位的幅度来定义,这与棘体积和AMPA受体的数量密切相关(Matsuzaki et al., 2001)。突触包含复杂的分子机制(Lisman, 2003;Redondo and Morris, 2011;Huganir and Nicoll, 2013;Lisman, 2017),但为了论证的透明性,我们将尽可能简单地使用数学符号,并仅用两个变量来描述突触:第一个变量是突触强度wij,测量为棘体积或突触后电位的幅度,第二个变量是突触内变量eij,在标准电生理实验中不直接可见。我们认为,内部变量eij代表棘头内相互作用分子的亚稳态瞬态,或突触后密度中的多分子亚结构。这作为突触标志,表明突触已准备好增加或减少其棘体积(Bosch et al., 2014)。eij的精确生物学性质对于理解下面回顾的理论和实验并不重要。我们将eij称为“突触标志”或“资格迹”,而wij为突触接触的“突触权重”或“强度”。突触标志的变化表示“候选权重变化”(Frémaux et al., 2010),而wij的变化表示突触权重的实际且可测量的变化。在我们讨论三因素规则之前,让我们先讨论一下Hebbian学习的传统模型。
2.1 Hebbian learning rules
Hebbian学习规则是诱导突触长期增强(LTP)或长期抑制(LTD)实验结果的数学总结。合适的实验方案包括对突触前纤维的强细胞外刺激(Bliss and Lømo, 1973;Levy and Stewart, 1983),在突触前脉冲到来时对突触后电压的操纵(Artola and Singer, 1993),或者脉冲时间依赖可塑性(STDP)(Markram et al., 1997;Sjöström et al., 2001)。在Hebbian学习的所有数学公式中,突触标志变量eij对突触前脉冲到达和突触后变量(如突触位置处的电压)的组合非常敏感。在Hebbian学习规则下,静息神经元突触处反复的突触前脉冲到达不会引起突触变量的改变。同样,在没有突触前脉冲的情况下,突触后电位的升高不会引起突触变量的改变。因此,Hebbian学习对于突触变化总是需要两个因素:一个是由突触前信号(如谷氨酸)引起的因素;另一个是取决于突触后神经元状态的因素。
这些因素是什么?我们可以认为突触前因素是可用的谷氨酸在突触间隙中或与突触后膜结合的时间过程。注意,我们将在下面使用的术语“突触前因素”并不意味着突触前因素的物理位置在突触前末端内——只要它只取决于可用神经递质的含量,该因素很可能位于突触后膜内。突触后因素可能是突触棘中的钙(Shouval et al., 2002;Rubin et al., 2005)、与钙相关的第二个信使分子(Graupner and Brunel, 2007)或仅仅是突触部位的电压(Brader et al., 2007;Clopath et al., 2010)。
我们提醒读者,我们总是用索引 j 指突触前神经元,索引 i 指突触后神经元。为了简单起见,我们称之为突触前因素xj(代表突触前神经元的活动或突触间隙中谷氨酸的含量)和突触后因素yi(代表突触后神经元的状态)。在Hebbian学习规则中,突触标志eij的变化需要xj和yi:

其中,η是学习率常数,τe是衰减时间常数,g(yj)是突触后变量yi的一些任意的潜在非线性函数。因此,突触标志eij充当突触前活动xj和突触后神经元状态yi之间的相关性检测器(correlation detector)。在一些模型中,在一个实验的时间尺度上(τe → ∞)没有衰减或者衰减可以忽略不计。

让我们讨论两个例子。在发育皮层可塑性的Bienenstock-Cooper-Munro(BCM)模型中(Bienenstock et al., 1982),突触前因素xj是突触前神经元的发放率,g(yi) = (yi - θ)yi是一个二次函数,其中yi是突触后发放率,θ是频率阈值。因此,如果突触前和突触后的神经元都以高频率xj = yi > θ一起发放,那么突触标志eij增加。在BCM模型中,与大多数其他传统模型一样,突触标志的改变(即突触的内部状态)会瞬间导致权重的变化eij → wij,因此实验方案会立即导致可测量的权重变化。根据BCM规则和其他类似规则(Oja, 1982;Miller and MacKay, 1994),如果突触前和突触后神经元都高度活跃,则突触权重增加,实现口号“一起发放,一起连接”(Lowel and Singer, 1992;Shatz, 1992);参见图1A(i)。
作为第二个例子,我们考虑了Clopath模型(Clopath et al., 2010)。在这个模型中,有两个相关性检测器分别被实现为LTP和LTD的突触标志 。LTP的突触标志
。LTP的突触标志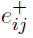 使用突触前因素
使用突触前因素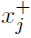 (与突触间隙中可用的谷氨酸含量相关),该因素随突触前脉冲的增加而增加,并在几毫秒内衰减回零(Clopath et al., 2010)。LTP的突触后因素依赖于突触后电压yi,通过一个函数
(与突触间隙中可用的谷氨酸含量相关),该因素随突触前脉冲的增加而增加,并在几毫秒内衰减回零(Clopath et al., 2010)。LTP的突触后因素依赖于突触后电压yi,通过一个函数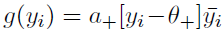 ,其中a+是一个正常数,θ+是电压阈值,方括号表示修正分段线性函数,
,其中a+是一个正常数,θ+是电压阈值,方括号表示修正分段线性函数, 是电压的运行平均值(时间常数为几十毫秒)。突触前脉冲和突触后电压的类似却更简单的组合定义了LTD的第二个突触标志
是电压的运行平均值(时间常数为几十毫秒)。突触前脉冲和突触后电压的类似却更简单的组合定义了LTD的第二个突触标志 (Clopath et al., 2010)。突触权重的总变化是LTP和LTD的两个突触标志的组合:
(Clopath et al., 2010)。突触权重的总变化是LTP和LTD的两个突触标志的组合: 。请注意,由于突触标志都依赖于突触后电压,突触后脉冲不是改变的必要条件,符合电压依赖性规则(Artola and Singer, 1993;Ngezahayo et al., 2000)。因此,在电压依赖性规则和电压依赖性模型中,“一起连接”是可能的,而不需要“一起发放”—— 这表明上述理论框架超出了Hebbian学习的狭隘视角;参见图1A(ii)。
。请注意,由于突触标志都依赖于突触后电压,突触后脉冲不是改变的必要条件,符合电压依赖性规则(Artola and Singer, 1993;Ngezahayo et al., 2000)。因此,在电压依赖性规则和电压依赖性模型中,“一起连接”是可能的,而不需要“一起发放”—— 这表明上述理论框架超出了Hebbian学习的狭隘视角;参见图1A(ii)。
如果我们将突触后变量的讨论局限于超阈值脉冲,那么Clopath模型就与三重STDP模型(Pfister et al., 2006)相同,这又与其他非线性STDP模型(Senn et al., 2001;Froemke and Dan, 2002;Izhikevich and Desai, 2003)以及之前所讨论的BCM模型(Pfister et al., 2006;Gjorjieva et al., 2011)密切相关。基于配对的经典STDP模型(Gerstner et al., 1996;Kempter et al., 1999;Song et al., 2000;van Rossum et al., 2000;Rubin et al., 2001)是等式(1)的一般理论框架以及一些结构可塑性模型的进一步示例(Helias et al., 2008;Deger et al., 2012;Fauth et al., 2015)。突触加强的Hebbian模型有几个隐藏的标志变量(Fusi et al., 2005;Barrett et al., 2009;Benna and Fusi, 2016),但也可以作为Hebbian规则的一般框架内的示例。注意,在目前为止的大多数例子中,测量的突触权重是突触标志变量的线性函数。然而,事实并非如此。例如,在一些基于电压的模型(Brader et al., 2007)或基于钙的模型(Shouval eet al., 2002;Rubin et al., 2005)中,只有当eij高于或低于某个阈值时,或仅在进一步滤波之后,突触标志才会转换为权重变化。
总而言之,在理论文献中,Hebbian模型是一个相当普遍的框架,涵盖了所有由突触前活动和突触后神经元状态共同驱动的模型。因此,Hebbian模型依赖于与突触前活动和突触后神经元状态相关的两个因素。这两个因素之间的相关性可以在不同的时间尺度上使用一个或多个标志变量(如有必要)。标记变量触发测量的突触权重的变化。在下文中,我们以Hebbian学习为基础,但将理论框架扩展到包括第三个因素。
2.2 Three-factor learning rules
我们感兴趣的是一个框架,其中两个神经元的Hebbian共同激活会在连接这些神经元的突触上留下一个或多个标记(资格迹)。该标记不直接可见,也不会自动触发突触权重的变化。只有当第三个信号(例如,神经调节剂活性的相位性增加或额外输入(表示特殊事件的发生)同时出现或在不久的将来出现时,才实现实际的权重变化。理论家将这种可塑性模型称为三因素学习规则(Xie and Seung, 2004;Legenstein, 2008;Vasulaki, 2009;Frémaux et al., 2013;Frémaux and Gerstner, 2016)。三因素规则也被称为“neoHebbian”(Lisman et al., 2011;Lisman, 2017)或“异突触体(调节性输入依赖)”(Bailey et al., 2000),如果没有更早的话,可以追溯到1960年代(Crow, 1968)。据我们所知,“三因素”一词最早由(Barto, 1985)使用。资格和资格迹这两个词在(Klopf, 1972;Sutton and Barto, 1981;Barto et al., 1983;Barto, 1985;Williams, 1992;Schultz, 1998;Sutton and Barto, 1998)中使用,但在早期的一些研究中,仍不清楚资格迹是否仅由突触前活动确定(Klopf, 1972;Sutton and Barto, 1981)或仅通过Hebbian共同激活突触前和突触后神经元(Barto et al., 1983;Barto, 1985;Williams, 1992;Schultz, 1998;Sutton and Barto, 1998)。
现代资格迹的基本思想是,突触前活动xj和突触后因素yi并存,根据公式(1)设置突触标志变量eij。通过棘体积或兴奋性突触后电位(EPSP)的振幅测量的突触权重wij的更新如下:

其中M3rd(t)指第三个因素(Izhikevich, 2007;Legenstein et al., 2008;Frémaux et al, 2013)。因此,需要第三个因素来将资格迹转换为权重变化;参见图1A(iii)。注意,权重变化与M3rd(t)成正比。因此,第三个因素影响学习的速度。在没有第三个因素(M3rd(t)=0)的情况下,突触权重不变。我们强调正值突触标志和负值M3rd(t)的结合会导致权重的下降。因此,第三个因素也会影响变化的方向。
第三个因素是什么?第三个因素可能是由注意过程、意外事件或奖励触发的。多巴胺、5-羟色胺、乙酰胆碱或去甲肾上腺素等神经调节剂的相位信号显然是第三个因素的候选,但可能不是唯一的。注意,大多数多巴胺能神经元、5-羟色胺能神经元、胆碱能神经元或肾上腺素能神经元的轴突分支广泛投射到皮层的大区域,这样一个相位神经调节信号并行到达许多神经元和突触(Schultz, 1998)。由于神经调节信息被许多神经元共享,在我们的数学公式中,第三个因素的变量M3rd(t)没有神经元特异性索引(i 和 j 都没有)。由于其不特定的性质,理论文献有时将第三个因素称为“全局”广播信号,尽管实际上并非每个大脑区域和每个突触都由每个神经调节剂到达。
请注意,我们在数学上将相位信号定义为与运行平均值的偏差,以便等式(2)中的M3rd(t)可以取正值和负值。然而,第三个因素也可以通过使用两种基准活性非常低的不同神经调节剂的活性正偏移来实现。第一个调节剂的活性可以表明第三个因素的正值,第二个调节剂的活性可以表明第三个因素的负值,类似于视网膜上的开关细胞。类似地,neoHebbian三因素规则的框架足够通用,能够生物学实现LTP和LTD的单独资格迹,如上文在Clopath模型中所讨论的(Clopath et al., 2010)。
2.3 Examples and theoretical predictions
在neoHebbian三因素法则的理论文献中,有几个已知的例子。我们简要介绍了其中的三个,并从理论框架中提出了期望,我们希望将其与下一节中的实验结果进行比较。
作为第一个例子,我们考虑了neoHebbian三因素规则与基于奖励的学习的关系。时序差分(TD)算法,如来自强化学习理论的SARSA(λ)或TD(λ)算法(Sutton and Barto, 1998)以及来自策略梯度理论的学习规则(Williams, 1992)可以用neoHebbian三因素学习规则在神经网络中解释。由此产生的可塑性规则适用于连接"状态神经元"(例如,为动物当前位置编码的位置细胞)和"动作神经元"(例如,启动“左转”等动作程序的细胞)的突触(Brown and Sharp, 1995;Suri and Schultz, 1999;Arleo and Gerstner, 2000;Foster et al., 2000;Xie and Seung, 2004;Loewenstein and Seung, 2006;Florian, 2007;Izhikevich, 2007;Legenstein et al., 2008;Vasilaki et al., 2009;Frémaux et al., 2013;综述见(Frémaux and Gerstner, 2016)。在"状态神经元"和"动作神经元"的联合激活过程中,资格迹增加,此后呈指数衰减,符合等式(1)的框架。第三个因素定义为奖励减去预期奖励,其中预期奖励的确切定义取决于实施细节。Wolfram Schultz及其同事(Schultz et al., 1997;Schultz, 1998;Schultz and Dickinson, 2000;Schultz, 2002)的一系列研究表明,神经调节剂多巴胺的相位性增加具有强化学习理论框架中第三个因素所需的必要特性。
然而,尽管在过去25年中积累了丰富的关于多巴胺和基于奖励的学习的文献,但据我们所知,在2015年之前,公式(1)中资格迹eij的衰减时间常数τe的测量是不可用的。从neoHebbian三因素规则的数学框架可以清楚地看出,在动作学习的背景下,资格迹的时间常数(即突触标志的持续时间)应该大致与从动作开始到奖励传递的时间跨度相匹配。作为一个例子,让我们想象一个婴儿试图抓住她的奶瓶。一次抓取动作的典型持续时间在秒范围内,但可能只有第三次抓取尝试可能成功。让我们假设每个抓取动作对应于大脑中一些神经元的共同激活。如果突触标记的持续时间远小于1s,则设置突触标记(资格迹)的突触前和突触后神经元的共同激活不能在1s后与奖励联系起来,突触也不会改变。如果突触标记的持续时间比1s长得多,那么两次“错误”抓取尝试的强化程度几乎与第三次相同,成功的尝试将“错误”的协同激活与正确的协同激活混淆起来。因此,现有的三因素学习规则理论预测,突触标志(动作学习的资格迹)应该在典型的基本动作范围内,大约200ms到2s;例如,参见(Schultz, 1998)第15页,(Izhikevich, 2007)第3页,(Legenstein et al., 2008)第3页,(Frémaux et al., 2010)第13327页,或(Frémaux et al., 2013)第13页。100ms或20s的资格迹比200ms到2s范围内的资格迹对学习典型的基本动作或延迟奖励任务的作用要小。突触资格迹的预期时间尺度应大致与条件反射实验中强化因素的最大延迟相匹配(Thorndike, 1911;Pavlov, 1927;J.Blac et al., 1985),将突触过程与行为联系起来。对于人类行为而言,与立即强化相比,在进行的动作中延迟强化因素10s会降低学习效果(Okouchi, 2009)。
在第二个例子中,我们考虑超出标准的基于奖励的学习的情况。即使在没有奖励的情况下,一个令人惊奇的事件也可能触发去甲肾上腺素、乙酰胆碱和多巴胺等神经调节剂的组合,它们可能成为突触可塑性的第三个因素。想象一下,一个小婴儿躺在摇篮里,一个漂亮的五颜六色的物体在他上方摆动。他自发地做了几次手臂动作,直到最后他成功地抓住了这个物体。这次行动没有食物奖励。然而,事实上,他现在可以转动物体,从不同的角度看它,或者把它放进嘴里,这是令人满意的,因为它导致了许多新奇的(和令人兴奋的!)刺激。基本思想是,在这种情况下,即使完全没有食物奖励,新奇或惊奇也会起到强化作用(Schmidhuber, 1991;Singh et al., 2004;Oudeyer et al., 2007)。理论家们在好奇心(Schmidhuber, 2010)、主动探索期间的信息获取(Storck et al., 1995;Sun et al., 2011;Schmidhuber, 2006;Sun et al., 2011;Little and Sommer, 2013;Friston et al., 2016)的背景下,通过对惊奇的正式定义(Storck et al., 1995;Itti and Baldi, 2009;Schmidhuber, 2010;Shannon, 1948;Friston, 2010;Faraji et al., 2018)研究了这些想法。请注意,惊奇并不总是与主动探索联系在一起,但也可能发生在被动的情况下,例如,聆听音调哔哔声或观看简单的刺激(Squires et al., 1976;Kolossa et al., 2013, 2015;Meyniel et al., 2016)。可测量的生理反应包括瞳孔扩张(Hess and Polt, 1960)和脑电图的P300成分(Squires et al., 1976)。
如果惊奇可以起到类似于奖励的作用,那么惊奇传播的广播信号应该会加速可塑性。事实上,与已知刺激(Yu and Dayan, 2005;Nassar et al., 2010;Mathys et al., 2011, 2014;Faraji et al., 2018)相比,惊奇理论和分层贝叶斯模型预测出令人惊奇的刺激的模型参数变化更快,与众所周知的Kalman滤波器(Kalman, 1960)相似,但更为普遍。由于将这些抽象模型转换成脉冲神经网络的工作仍然缺乏,因此还无法以三因素规则的形式精确预测可塑性的惊奇调节。然而,如果我们考虑去甲肾上腺素、乙酰胆碱和/或多巴胺作为发送新奇和惊奇信号的候选神经调节剂,我们期望这些神经调节剂对可塑性有强烈的影响,从而促进对令人惊奇的刺激的学习。各种神经调节剂的tonic应用对突触可塑性的影响已在许多研究中得到证明(Gu, 2002;Hasselmo, 2006;Reynolds and Wickens, 2002;Pawlak et al., 2010)。然而,在上述例子的背景下,我们对相位神经调节信号感兴趣。如果相位信号与要学习的刺激(例如,被动听或看)同步,或出现与一个探索性动作(例如,抓取)对应的延迟,则表示惊奇时刻的相位信号对于学习最有用。因此,我们根据这些考虑,在1s范围内预测突触标志的衰减常数τe,但对同步或接近同步事件有显著影响。
作为最后一个例子,我们想谈谈突触增强。突触标记并捕获(tagging-and-capture)假说(Frey and Morris, 1997;Reymann and Frey, 2007;Redondo and Morris, 2011)完全符合三因素学习规则的框架:突触前和突触后的联合活动设置突触标志(在加强的情况下称为“标记”),在1h内衰减回零。为了使突触权重稳定超过1h,还需要一个额外的因素来触发长期维持突触权重所需的蛋白质合成(Redondo and Morris, 2011;Reymann and Frey, 2007)。多巴胺等神经调节剂被认为是增强的第三个必要因素(Bailey et al., 2000;Reymann and Frey, 2007;Redondo and Morris, 2011;Lisman, 2017)。事实上,突触增强的现代计算模型考虑了神经调节剂的影响(Clopath et al., 2008;Ziegler et al., 2015),其框架让人想起前面公式(1) 和(2)定义的三因素规则。然而,有两个值得注意的区别。首先,与基于奖励的学习相比,突触标记eij的衰减时间τe在1h的范围内(而不是1s),这与切片实验(Frey and Morris, 1997)以及行为实验(Moncada and Viola, 2007)一致。其次,在切片中,测量的突触权重wij在诱导流程结束后几分钟增强,并随着突触标记的时间进程而衰减,而在最简单的三因素规则框架的实现中,如公式(1)和(2)所述,可见权重仅在存在第三个因素时更新。然而,更为复杂的模型,其中可见权重取决于突触标记变量和长期稳定权重(Clopath et al., 2008;Ziegler et al., 2015),正确地解释了加强实验中测量的突触权重的时间过程(Frey and Morris, 1997;Reymann and Frey, 2007;Redondo and Morris, 2011)。
总之,neoHebbian三因素规则框架具有广泛的适用性。在突触加强的背景下,从切片实验(Frey and Morris, 1997)中提取的标记(突触标记)的持续时间在1h内,这一点已经得到了很好的证实,与恐惧条件反射实验(Moncada and Viola, 2007)一致。这个时间尺度明显长于基本动作的行为学习或记忆令人惊奇的事件所需的时间尺度。因此,理论家假设,类似于设置标记(“资格迹”)的过程也必须存在于1s的时间尺度上。下一节将讨论支持这一理论预测的一些最新实验证据。
3 Experimental evidence for eligibility traces
以下三个小节回顾了纹状体(Yagishita et al., 2014)、皮层(He et al., 2015)和海马体(Brzosko et al., 2015, 2017;Bittner et al., 2017)资格迹的最新实验证据。

3.1 Eligibility traces in dendritic spines of medial spiny striatal neurons in nucleus accumbens
在伏隔核神经元树突棘的优雅成像实验中,Yag ishita et al.(2014)通过谷氨酸解链(突触前因素)模拟突触前脉冲的到达,然后立即与三个突触后脉冲配对(突触后因素),重复十次这种类似STDP的pre-before-post序列,并在不同延迟下与多巴胺纤维(第三个因素)的光遗传学刺激相结合(Yagishita et al., 2014)。在10hz时,10次重复的pre-before-post序列大约需要1s,而从腹侧被盖区(VTA)投射到伏隔核的多巴胺能纤维(30Hz时有10次多巴胺脉冲)的刺激大约需要0.3s,如果多巴胺刺激在1s长的诱导期结束后立即开始(延迟=STDP和多巴胺的开启时间差),则多巴胺被认为延迟1s,但为了与其他数据一致,我们在此将延迟d定义为自STDP过程结束以来经过的时间。在15次完整的试验后,测量了突触强度的指标,棘体积(Matsuzaki et al., 2001),并与诱导过程前的棘体积进行了比较。作者发现,只有在1s长的STDP过程期间或之后的狭窄时间窗内给予相位多巴胺,多巴胺才能促进棘增大;参见图2A。
如果多巴胺信号在STDP过程期间开始(d = -0.4s),则棘的增大量最大,但即使在延迟d = 1s时,LTP仍然可见。过早(d = -2s)或过晚(d = +4s)服用多巴胺没有效果。棘增大对应于兴奋性突触后电流振幅的增加,表明在过程实施后突触权重确实增强(Yagishita et al., 2014)。因此,我们可以总结出,我们在纹状体中有一个三因素学习规则,用于诱导LTP,其中资格迹的衰减发生在1s的时间尺度上;参见图2A。
为了得到这些结果,Yagishita et al.(2014)集中在伏隔核(基底核腹侧纹状体的一部分)的内侧棘神经元。从功能上讲,纹状体是强化学习的一个特别有趣的候选者(Brown and Sharp, 1995;Schultz, 1998;Doya, 2000a;Arleo and Gerstner, 2000;Daw et al., 2005),原因如下。首先,纹状体通过谷氨酸能突触从新皮质和海马体接收高度加工的感觉信息(Mink, 1996;Middleton and Strick, 2000;Haber et al., 2006)。其次,纹状体也接受与奖励处理相关的多巴胺输入(Schultz, 1998)。第三,纹状体和额叶皮层一起参与了肌肉动作程序的选择(Mink, 1996;Seo et al., 2012)。
在分子水平上,纹状体三因素可塑性依赖于NMDA、CaMKII、蛋白质合成和多巴胺D1受体(Yagishita et al., 2014)。CaMKII的增加被发现局限于棘,其时间进程与相位多巴胺的临界窗口大致相同,提示CaMKII可能参与类似STDP诱导过程触发的“突触标志”,而蛋白激酶A(PKA)的非特异性细胞分布表明将PKA解释为与多巴胺触发的第三个因素相关的分子(Yagishita et al., 2014)。
3.2 Two distinct eligibility traces for LTP and LTD in cortical synapses
在He et al.(2015)最近的一次实验中,前额叶或视觉皮层切片中的2/3层锥体细胞受STDP过程刺激,无论是pre-before-post的LTP诱导还是post-before-pre的LTD诱导。在重复整个过程之前,在一个STDP序列之后延迟应用神经调节剂;参见图2B。神经调节剂,即去甲肾上腺素(NE)、5-羟色胺(5-HT)、多巴胺(DA)或乙酰胆碱(ACh)从移液管中喷射10s或从内源性纤维(使用光遗传学)喷射1s(He et al., 2015)。他们发现NE对LTP是必要的,而5-HT对LTD是必要的。DA或ACh兴奋剂对视觉皮层没有影响,但DA对额叶皮层LTP的诱导有积极影响(He et al., 2015)。
对于STDP准则,He et al.(2015)使用细胞外刺激从第4层到第2/3层(突触前因素)的两条突触前通路,结合4个突触后动作电位(突触后因素),不论是pre-before-post还是post-before-pre。在实验的第一个变体中,在给予NE或5-HT之前,STDP刺激在10hz下重复200次,相当于总刺激时间20s。在第二种变体中,他们将突触前刺激(第一个因素)和突触后去极化(第二个因素)配对到-10mV以诱导LTP,或配对到-40mV以诱导LTD。在这两种方案中,发现如果神经调节剂NE(第三个因素)在LTP后延迟5s或更少时间,但不是10s后到达,则LTP可以被诱导。如果5-HT(第三个因素)在LTD后延迟2.5s或更少时间,但不是5s后到达,则LTD可能被诱导(He et al., 2015)。
实验的第三个变体涉及在一个由一个突触前脉冲和四个突触后脉冲组成的最小STDP过程(无论是pre-before-post还是post-before-pre)后,立即或几秒钟内通过重复的光脉冲对去甲肾上腺素、多巴胺或5-羟色胺途径进行光遗传学刺激在生理上更合理。以20s为间隔重复40次STDP配对和神经调节的最小序列。结果与上述结果一致,并且显示在STDP刺激前立即应用NE或5-HT不会诱发LTP或LTD。总体而言,这些结果表明在视觉和额叶皮层,pre-before-post配对会留下一个资格迹,衰减超过5-10s,可以通过神经调节剂去甲肾上腺素转换成LTP。类似地,post-before-pre配对会留下较短的资格迹,衰减超过3s,可由神经调节剂5-羟色胺转换为LTD;参见图2B。
在功能上,同一篇论文中的理论模型(He et al., 2015)表明,具有两个独立资格迹的测量三因素学习规则稳定并延长了网络活动,从而允许“事件预测”。作者假设,三因素规则与皮层中基于奖励的学习有关,例如猴子(Schoups et al., 2001)或小鼠(Poort et al., 2015)的感知学习或奖励预测(Shuler and Bear, 2006)。与惊奇的关系没有讨论,但可能是进一步探索的方向。
分子水平上,Hebbian的pre-before-post资格迹转化为LTP,涉及β-肾上腺素能受体和细胞内环腺苷酸;而post-before-pre资格迹转化为LTD,涉及5-HT2c受体(He et al., 2015)。这两个受体都锚定在突触后密度,这与将资格迹转化为实际权重变化的作用一致(He et al., 2015)。
3.3 Eligibility traces in hippocampus
两个实验组用互补方法研究了CA1海马体神经元的资格迹。在Brzosko et al.(2015, 2017)的研究中,海马体脑片中的CA1神经元在大约8min内被刺激,在一个STDP过程中,包括100次重复(0.2Hz)的一个细胞外传递的突触前刺激脉冲(突触前因素)和一个突触后动作电位(突触后因素)配对(Brzosko et al., 2015)。相对时间+10ms的重复pre-before-post给予LTP(在天然内源性多巴胺存在的情况下),而post-before-pre(-20 ms)给予LTD。然而,在bathing方案中加入额外的多巴胺(第三个因素),post-before-pre(-20ms)给予LTP(Zhang et al., 2009)。类似地,当内源性多巴胺存在时,使用post-before-pre(-10ms)的STDP过程会导致LTP,但当多巴胺被阻断时,会导致LTD(Brzosko et al., 2015)。因此,多巴胺将LTP的STDP窗口扩大到post-before-pre方式(Zhang et al., 2009;Pawlak et al., 2010)。此外,在STDP刺激过程期间,若存在ACh,则pre-before-post(+10ms)也给予LTD(Brzosko et al., 2017)。因此,ACh拓宽了LTD的窗口。
Brzosko et al.(2015)的关键实验涉及多巴胺的延迟(Brzosko et al., 2015)。Brzosko et al.开始注射多巴胺,要么在post-before-pre(-20ms)诱导过程结束后立即进行,要么有一定延迟。由于多巴胺被注射了大约10min,它不能被认为是一个相位信号,但至少多巴胺注射的开始被延迟了。Brzosko et al.发现如果多巴胺的延迟在1min或更短的范围内,通常给予LTD的刺激会转变为LTP,但如果多巴胺在STDP过程结束后10min开始,则不会发生这种现象(Brzosko et al., 2015)。注意,对于LTD向LTP的转化,重要的是突触在多巴胺存在的情况下受到低频弱刺激。类似地,在ACh存在下,延长pre-before-post过程(+10ms)的时间会导致LTD,但在给予多巴胺的且延迟不到1min的情况下,同样的过程会导致LTP(Brzosko et al., 2017)。总之,在海马体中,一个延长的post-before-pre过程(或在ACh存在下的pre-before-post过程)产生可见的LTD,但也为LTP设置了一个不可见的突触标志。如果多巴胺的应用延迟不到1min,在持续的弱突触前刺激下,突触标志会转换成正的权重变化;参见图2C。
在分子水平上,反复刺激前-后脉冲配对后,LTD转化为LTP依赖于NMDA受体和环磷酸腺苷(cAMP)—— PKA信号级联(Brzosko et al., 2015)。多巴胺的来源可能是蓝斑,蓝斑与兴奋和新奇有关(Takeuchi et al., 2016),也可能来自其他与奖励有关的多巴胺核(Schultz, 1998)。由于在(Brzosko et al., 2015, 2017)报告的突触标志的时间尺度在分钟范围内,因此Brzosko et al.研究的这一过程可能与突触加强有关(Frey and Morris, 1997;Reymann and Frey, 2007;Redondo and Morris, 2011;Lisman, 2017),而不是需要较短时间常数的强化学习中的资格迹(Izhikevich, 2007;Legenstein et al., 2008;Frémaux et al., 2010, 2013)。Brzosko et al.(2017)的计算研究使用时间常数为2s的资格迹,显示多巴胺作为奖励信号诱导了奖励位置的学习,而探索期间的ACh在奖励位置发生变化后能够快速再学习(Brzosko et al., 2017)。
第二项研究结合了体内和体外数据(Bittner et al., 2017)。通过体内研究,我们已经知道,在“钙高稳电位”(Bittner et al., 2015)的影响下,小鼠海马体中的CA1神经元可以在一次试验中开发出一个新的、可靠的、相当广泛调谐的定位场(在胞体处可见一个复杂的脉冲)。此外,人工诱导的复杂脉冲足够在体内诱导这种新的位置场(Bittner et al., 2015, 2017)。
在另外的切片实验中,从CA3到CA1神经元的几个输入纤维在1s内被来自细胞外电极的10个脉冲刺激。在多个突触处产生的几乎同步的输入,可能导致胞体总EPSP高于基准约10mV,在树突中可能稍大,但没有引起CA1神经元的体细胞脉冲。如果突触前刺激与突触后神经元的钙高稳电位(复杂脉冲)配对,则受刺激的突触显示LTP。即使突触前刺激在高稳电位开始前1-2s停止,或者高稳电位在突触前刺激开始前停止,也会发生LTP(Bittner et al., 2017)。该过程在5次配对后,增强率在200%左右,具有显著的效率。因此,许多突触的联合激活在激活的突触上设置了一个标记,如果在突触激活前几秒钟或之后出现钙高稳电位(复杂脉冲),则该标记被转换为LTP;参见图2D。分子上,可塑性过程暗示NMDA受体和钙通道(Bittner et al., 2017)。
在功能上,海马体的突触可塑性尤其重要,因为海马体在空间记忆中的作用(O'keefe and Nadel, 1978)。CA1神经元的输入来自于CA3神经元,它们有一个狭窄的空间场。因此,在CA1中出现一个广阔的位置场被解释为将几个CA3神经元(覆盖了例如,在当前位置之前,大鼠穿过的50厘米空间轨迹)连接到一个为当前位置编码的CA1细胞(Bittner et al., 2017)。注意,在啮齿动物的典型奔跑速度下,50厘米相当于几秒钟的奔跑。因此,CA1细胞的广泛活动被解释为对即将发生的事件或地点的预测性表征(Bittner et al., 2017)。这样一个即将到来的事件会是什么?例如,对于正在探索T迷宫的啮齿动物来说,在T形交叉点上建立一个比在一条长走廊内更精确的空间表征可能很重要。在T形交叉口有一个广阔的CA1位置场,在动物到达交叉口前几秒钟,就可以获得即将出现的分叉的信息。
Bittner et al.将他们的发现解释为在行为时间尺度上具有特别长的并存窗口的一种特殊形式的STDP的特征(Bittner et al., 2017)。考虑到突触前刺激和突触后复杂脉冲之间数秒的时间跨度超出了输入和输出之间潜在因果关系的范围,他们将可塑性规则归类为非Hebbian,因为突触前神经元不参与触发突触后神经元(Bittner et al., 2017)。作为另一种观点,我们建议对Bittner et al.的发现进行分类。作为来自CA3(突触前因素)的突触前脉冲和突触后CA1神经元(突触后因素)在突触位置的阈下去极化共同出现留下的资格迹的标志;参见图2D。在这一看法中,突触标志的设置是由“Hebbian”型诱导引起的,只是突触后侧没有脉冲,只有去极化,这与去极化作为突触后因素的作用一致(Artola and Singer, 1993;Ngezahayo et al., 2000;Sjöström et al., 2001;Clopath et al., 2010)。在这种观点下,Bittner et al.的发现建议由诱导过程设置的突触标志留下一个衰减超过2s的资格迹,如果在这2s内产生一个高稳电位(与第三个因素有关),则由诱导过程引起的资格迹将转化为突触权重的可测量变化。等式(2)中的第三个因素M3rd(t)可对应于以约1s的时间常数过滤的复杂脉冲。重要的是,高稳电位可以被认为是由令人惊奇的新奇或有奖励的事件(Bittner et al., 2017)触发的神经元宽度信号(Bittner et al., 2015)。在这种观点下,Bittner et al.的研究结果符合neoHebbian三因素学习规则的框架。如果高稳电位确实与令人惊奇的事件有关,那么三因素规则框架预测,在体内,CA1中的许多神经元接收到第三种输入,如类似广播信号。然而,只有那些同时从CA3获得足够强输入的神经元可能会发展出可见的高稳电位(Bittner et al., 2015)。
两种不同观点的主要区别在于,在Bittner et al.(2017)讨论的模型中,每一个激活的突触都有一个资格迹(独立于突触后神经元的状态),而根据三因素法则,只有当突触前激活与突触后膜的强去极化同时发生时,才设置资格迹。因此,在Bittner et al.的模型中资格迹是由突触前因素单独设定的,而在三因素规则描述中,资格迹是由突触前因素和突触后因素组合设定的。这两种模型可以在未来的实验中加以区分,实验中要么突触前刺激期间控制突触后电压,要么同时受刺激的输入纤维数量最小化。三因素规则的预测是,单个突触的脉冲到达,或者脉冲到达与超过静息值小于2mV的非常小的去极化,不足以设置资格迹。因此,在这些情况下,即使1s后出现钙高稳电位,LTP也不会发生。
4 Discussion and Conclusion
4.1 Policy gradient versus TD-learning
具有离散状态和离散时间的TD学习算法模型不需要超过一个时间步骤的资格迹(Sutton and Barto, 1998)。在一个场景中,在一个目标状态下给出的唯一奖励与初始状态有几步之遥,在多次试验中,奖励信息从目标状态向后移动,即使一步资格迹只将一个状态连接到下一个状态(Sutton and Barto, 1998)。然而,在时序差分算法(如TD(λ)或SARSA(λ))中,跨越多个时间步骤的扩展资格迹被认为是加速学习的方便启发式工具(Singh and Sutton, 1996;Sutton and Barto, 1998)。
在策略梯度法(Williams, 1992)和连续时空TD学习(Doya, 2000b;Frémaux et al., 2013)中,资格迹自然出现在奖励最大化问题的表述中。重要的是,一大类TD学习和策略梯度方法可以被表述为三因素规则,用于脉冲神经元,其中第三个因素定义为奖励减去预期奖励(Frémaux and Gerstne, 2016)。在策略梯度法和相关的三因素规则中,预期奖励被计算为奖励的运行平均值(Frémaux et al., 2010)或通过选择奖励计划固定为零(Florian, 2007;Legenstein et al., 2008)。在TD学习中,给定时间步骤的期望奖励定义为当前状态和下一状态的价值之差(Sutton and Barto, 1998)。在强化学习的最新大规模应用中,策略梯度中的预期即时奖励通过用于状态相关的价值估计的TD算法计算(Greensmith et al., 2004;Mnih et al., 2016)。关于强化学习算法及其之前研究的优秀现代总结,请参见(Sutton and Barto, 2018)。
4.2 Specificity
如果相位神经调节剂信号在大脑的大区域传播,那么突触可塑性是否仍然是选择性的问题就产生了。在三因素规则的框架下,特异性是从突触标志遗传而来的,这些标志是由突触前的脉冲到达和突触位置的突触后电压升高共同决定的。只有一小部分突触满足这一要求,因为单靠突触前或单靠突触后活动是不够的;参见图1B。此外,在所有标记的突触中,只有那些在许多试验中显示与奖励信号相关的突触才会持续增强(Legenstein et al., 2008;Loewenstein and Seung, 2006)。注意反馈机制(Roelfsema and van Ooyen, 2005;Roelfsema et al., 2010)可以进一步增强特异性,该机制将资格突触的数量限制在可能参与任务的“有趣”突触的数量上。这种注意门控信号作为一个额外因素,将三个因素转化为四个因素的学习规则(Rombouts et al., 2015)。
4.3 Mapping to Neuromodulators
第三个因素可能与神经调节剂有关,但从理论家的角度来看,没有必要指定一个神经调节剂给人惊奇,另一个给人奖励。事实上,如果每个神经调节剂为不同的变量组合编码,例如惊奇、新奇或奖励,理论框架也会起作用,就像我们可以使用不同的坐标系来描述同一物理系统一样(Frémaux and Gerstner, 2016)。因此,无论多巴胺是纯奖励相关的还是新奇相关的(Ljunberg and amd W.Schultz, 1992;Schultz, 1998;Redgrave and Gurney, 2006),只要与新奇、惊奇和奖励相关的维度都包含在一组神经调节剂中,对三因素学习规则的制定就不是至关重要的。
从VTA投射到纹状体的多巴胺神经元可以有独立的回路和功能,从腹侧纹状体的奖励到纹状体尾部的新奇,这增加了生物学的复杂性(Menegas et al, 2017)。类似地,从VTA开始的多巴胺能纤维与蓝斑开始的多巴胺能纤维具有不同的功能(Takeuchi et al., 2016)。三因素规则的框架足够普遍,可以允许这些以及许多其他变化。
4.4 Alternatives to eligibility traces for bridging the gap between the behavioral and neuronal timescales
从理论的角度来看,除了概念上的优雅,没有什么比选择其他神经元机制来关联被1s或更长时间分隔的事件更倾向于选择合适的线索。例如,在具有延迟反馈的学习行为任务中,循环网络(Maass et al., 2002;Jaeger and Haas, 2004;Buonomano and Maass, 2009;Sussillo, 2009)或循环网络中的短期突触可塑性(Mongillo et al., 2008)丰富的发放活动模式中隐藏的记忆痕迹。在一些模型中,学习延迟配对关联任务涉及的是神经元而不是突触的活动迹(Brea et al., 2016),在行为时间尺度上学习使用了突触资格迹和延长的单个神经元活动的组合(Rombouts et al., 2015)。本文回顾的实证研究支持这样的观点,即大脑利用具有突触资格迹和三因素学习规则的优雅解决方案,但不排除其他机制并行工作。
4.5 The paradoxical nature of predictions in computational neuroscience
如果一个神经科学家想到一个理论模型,他通常会在一开始就设想出几个假设,一组从模拟或数学分析中得出的结果,理想情况下还有一些新颖的预测——但这就是建模的工作方式吗?在计算神经科学中,至少有两种预测:详细预测和概念预测。多通道生物物理学Hodgkin-Huxley模型(Hodgkin and Huxley, 1952)的变体已经产生了详细预测的众所周知的例子,例如:“如果X通道被阻断,那么我们预测……“,其中X是具有已知动态和预测的通道,包括去极化、超极化、动作电位发放、动作电位反向传播或其失效。所有这些都是有用的预测,很容易转化为实验,并在实验中得到验证。
从抽象概念模型得到的概念预测可能更有趣,但更难表述。概念模型发展了一些想法,并形成了我们对特定神经系统如何工作来解决行为任务的思考,例如工作记忆(Mongillo et al., 2008)、动作选择和决策(Sutton and Barto, 1998)、记忆的长期稳定性(Lisman, 1985;Crick, 1984;Fusi et al., 2005),记忆形成和记忆回忆(Willshaw et al., 1969;Hopfield, 1982)。自相矛盾的是,这些模型往往没有作出上述意义上的详细预测。相反,在这些和其他概念理论中,最相关的模型特征被表述为假设,从松散的意义上讲,这些假设可以被视为扮演概念预测的角色。把它表述为一个简短的口号:假设就是预测。让我们回到三因素规则的概念框架:把粗略的思想提纯成三因素的作用,是概念工作的重要内容和部分假设。此外,对于资格迹,时间常数在1s范围内的具体选择已由理论家作为模型假设之一,而不是作为预测;参见“实例和理论预测”一节中的脚注。为什么是这个案例?
大多数理论家都回避把他们的概念建模工作称为“预测”,因为没有逻辑上的必然性,大脑必须按照他们在模型中假设的方式工作——大脑本可以找到一个不那么优雅、不太一样,但仍然是在考虑中的问题的功能性解决方案;请参阅上一小节中的示例。计算神经科学中一个好的概念模型表明,存在一个(好的)解决方案,理想情况下不应该与太多已知事实明显矛盾。重要的是,概念模型必然依赖于假设,而这些假设在许多情况下还没有被证明是正确的。因此,仲裁员对实验期刊上的模型化工作的反应常常是:“但这一点从未显示出来”。事实上,有些假设可能看起来有些牵强,甚至与已知的事实相矛盾:例如,为了回到资格迹,关于突触标记和捕捉的实验在20世纪90年代表明,突触标志的时间尺度在1h的范围内(Frey and Morris, 1997;Reymann and Frey, 2007;Redondo and Morris, 2011;Lisman, 2017),然而行动学习的资格迹理论需要一个1s时间尺度上的突触标志。突触标记结果是否意味着动作学习的三个因素规则是错误的,因为它们使用了错误的时间尺度?或者,恰恰相反,这些实验结果是否更确切地意味着三因素规则的生物机制确实存在,因此,对于其他神经元类型和大脑区域,可以使用并重新调整到不同的时间尺度(Frémaux et al., 2013)?
如前所述,资格迹和三因素规则的概念可以追溯到20世纪60年代,从文字形式的模型(Crow, 1968),到离散时间和离散状态下的发放率模型(Klopf, 1972;Sutton and Barto, 1981;Barto et al., 1983;Barto, 1985;Williams, 1992;Schultz, 1998;Sutton and Barto, 1998;Bartlett and Baxter, 1999),以连续状态空间中的脉冲和明确的时间尺度为资格迹的模型(Xie and Seung, 2004;Loewenstein and Seung, 2006;Florian, 2007;Izhikevich, 2007;Legenstein et al., 2008;Vasilaki et al., 2009;Frémaux et al., 2013)。尽管海马体突触标记的时间尺度与已知的不匹配(以及在其他大脑区域缺乏实验支持),理论家们坚持完善他们的理论,在会议上讨论这些模型,直到最终实验技术和实验人员的科学兴趣直接与检验这些理论的假设。鉴于三因素学习规则的悠久历史,最近的优雅实验(Yagishita et al., 2014;He et al., 2015;Brzosko et al., 2015, 2017;Bittner et al., 2017)为概念理论如何影响实验神经科学提供了一个有指导意义的例子。
Eligibility Traces and Plasticity on Behavioral Time Scales: Experimental Support of neoHebbian Three-Factor Learning Rules的更多相关文章
- 强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces)
强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces) 学习笔记: Reinforcement Learning: An Introduction, Richard S. S ...
- 强化学习(八):Eligibility Trace
Eligibility Traces Eligibility Traces是强化学习中很基本很重要的一个概念.几乎所有的TD算法可以结合eligibility traces获得更一般化的算法,并且通常 ...
- The Go Programming Language. Notes.
Contents Tutorial Hello, World Command-Line Arguments Finding Duplicate Lines A Web Server Loose End ...
- 增强学习(五)----- 时间差分学习(Q learning, Sarsa learning)
接下来我们回顾一下动态规划算法(DP)和蒙特卡罗方法(MC)的特点,对于动态规划算法有如下特性: 需要环境模型,即状态转移概率\(P_{sa}\) 状态值函数的估计是自举的(bootstrapping ...
- Awesome Reinforcement Learning
Awesome Reinforcement Learning A curated list of resources dedicated to reinforcement learning. We h ...
- DRL之:策略梯度方法 (Policy Gradient Methods)
DRL 教材 Chpater 11 --- 策略梯度方法(Policy Gradient Methods) 前面介绍了很多关于 state or state-action pairs 方面的知识,为了 ...
- 论文笔记之:Asynchronous Methods for Deep Reinforcement Learning
Asynchronous Methods for Deep Reinforcement Learning ICML 2016 深度强化学习最近被人发现貌似不太稳定,有人提出很多改善的方法,这些方法有很 ...
- 强化学习(五)用时序差分法(TD)求解
在强化学习(四)用蒙特卡罗法(MC)求解中,我们讲到了使用蒙特卡罗法来求解强化学习问题的方法,虽然蒙特卡罗法很灵活,不需要环境的状态转化概率模型,但是它需要所有的采样序列都是经历完整的状态序列.如果我 ...
- [Reinforcement Learning] Model-Free Prediction
上篇文章介绍了 Model-based 的通用方法--动态规划,本文内容介绍 Model-Free 情况下 Prediction 问题,即 "Estimate the value funct ...
随机推荐
- Spring报错: org.springframework.beans.factory.CannotLoadBeanClassException: Cannot find class [xxx]
如果确实没有这个类,就挨个将总项目,子项目clean,install一下,注意他们的依赖关系.
- Python File seek() 方法
概述 seek() 方法用于移动文件读取指针到指定位置.高佣联盟 www.cgewang.com 语法 seek() 方法语法如下: fileObject.seek(offset[, whence]) ...
- 海华大赛第一名团队聊比赛经验和心得:AI在垃圾分类中的应用
摘要:为了探究垃圾的智能分类等问题,由中关村海华信息研究院.清华大学交叉信息研究院以及Biendata举办的2020海华AI垃圾分类大赛吸引了大量工程师以及高校学生的参与 01赛题介绍 随着我国经济的 ...
- 中国剩余定理(CRT)及其扩展(EXCRT)详解
问题背景 孙子定理是中国古代求解一次同余式方程组的方法.是数论中一个重要定理.又称中国余数定理.一元线性同余方程组问题最早可见于中国南北朝时期(公元5世纪)的数学著作<孙子算经>卷下第 ...
- [转] 总结了N个真实线上故障
以下文章来源于架构师进阶之路 ,作者二马读书 1. JVM频繁FULL GC快速排查 在分享此案例前,先聊聊哪些场景会导致频繁Full GC: 内存泄漏(代码有问题,对象引用没及时释放,导致对象不能及 ...
- [转]Post和Get的区别
作者:zhanglinblog 来源:https://urlify.cn/FnYBbu 这个问题几乎面试的时候都会问到,是一个老生常谈的话题,然而随着不断的学习,对于以前的认识有很多误区,所以 ...
- LeetCode(2)---路径总和
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和. 说明: 叶子节点是指没有子节点的节点. 示例: 给定如下二叉树,以及目标和 sum = ...
- 洛谷3月月赛div2 题解(模拟+数学+贪心+数学)
由于本人太蒻了,div1的没有参加,胡乱写了写div2的代码就赶过来了. T1 苏联人 题目背景 题目名称是吸引你点进来的. 这是一道正常的题,和苏联没有任何关系. 题目描述 你在打 EE Round ...
- 在Spring Boot中动态实现定时任务配置
原文路径:https://zhuanlan.zhihu.com/p/79644891 在日常的项目开发中,往往会涉及到一些需要做到定时执行的代码,例如自动将超过24小时的未付款的单改为取消状态,自动将 ...
- 【每日一个小技巧】Python | input的提示信息换行输出,提示信息用变量表示
[每日一个小技巧]Python | input的提示信息换行输出,提示信息用变量表示 在书写代码的途中,经常会实现这样功能: 请输入下列选项前的序号: 1.选择1 2.选择2 3.选择3 在pytho ...