Ch2信息的表示和处理——caspp深入理解计算机系统
第2章 信息的表示和处理
2.1 信息存储
一些基础概念引入:
- 虚拟存储器:机器级程序将存储器视为一个非常大的字节数组
- 地址:存储器的每个字节都由唯一的数字来标识
- 虚拟地址空间:所有可能地址的集合
2.1.1 十六进制
一、表示法
一个字节:(二进制)00000000 ~ 11111111;(十六进制)00 ~ FF
二、加减
不转换为十进制或二进制,直接相加减,超过16则进位或取位即可。
三、进制转换
16 and 2
16 to 2 :分位转换
十六进制 1 7 3 A 4 C 二进制 0001 0111 0011 1010 0100 1100 2 to 16:四位四位的转
二进制 11 1100 1010 1101 1011 0011 十六进制 3 C A D B 3
16 and 10
- 16 to 10:3CA = 3 * 16^2 + 12 * 16^1 + 10
- 10 to 16:累除取余数
2.1.2 字
字长:指明整数和指针数据的标称大小。对于一个字长为 w 位的机器而言,虚拟地址的范围为 $0 $ ~ \(2^{w-1}\) ,程序最多访问 \(2^w\) 个字节。
2.1.3 数据大小
| C声明 | 32位机器 | 64位机器 |
|---|---|---|
| char | 1 | 1 |
| short int | 2 | 2 |
| int | 4 | 4 |
| long int | 4 | 8 |
| long long int | 8 | 8 |
| **char *** | 4 | 8 |
| float | 4 | 4 |
| double | 8 | 8 |
2.1.4 字节顺序与表示
对于跨越多字节的程序对象,两个规则:这个对象的地址是什么,在存储器中如何排列这些字节。在几乎所有机器上,多字节对象被存储为连续的字节序列,地址为所使用字节最小的地址。
一、字节的排列规则
假设 x 类型为 int,位于地址 0x100 处,十六进制值为 0x01234567
小端法:按照从最低有效字节到最高有效字节的顺序存储对象,大多 Intel 兼容机采用

大端法:按照从最高有效字节到最低有效字节的顺序存储对象,大多 IBM 的机器采用

二、打印字节
- 实现程序
#include<bits/stdc++.h>
using namespace std;
typedef unsigned char* byte_pointer;
/* show_bytes 为字节打印函数 */
void show_bytes(byte_pointer start, int len){
int i;
for(i = 0; i < len; i++)
printf(" %.2x",start[i]);
printf("\n");
}
void show_int(int x){
show_bytes((byte_pointer) &x, sizeof(int));
}
void show_pointer(void* x){
show_bytes((byte_pointer) x, sizeof(void*));
}
int main()
{
int a = 100;
show_int(a);
return 0;
}
/*
* 输出结果为 64 00 00 00
* 标志着编译的该机器为小端法
*/
结果比较
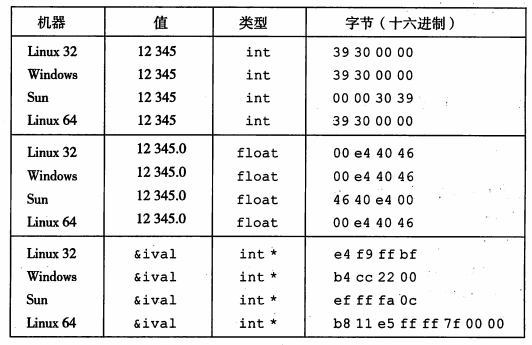
- int & float:除了顺序,值是相同的,且可以看出只有 Sun 处理器是大端法
- 指针:不同机器配置使用不同的存储分配规则,其中注意只有 Linux 64 指针是 8 字节
三、字符串的字节表示
C 语言中字符串被编码为一个以 null (其值为0)字符字符的字符数组。
/* 利用代码输出s的字节表示*/
char s[] = "12345";
show_bytes((byte_pointer)s,strlen(s)+1); //注意要加 1
/* 结果如下 */
// 31 32 33 34 35 00 可以看到最后null的值为0,即'\0'
四、代码表示
同一个C语言文件在不同机器编译时,由于规则方式不同,会产生不同的机器代码。因此二进制代码是不兼容的,很少能在不同机器和操作系统组合之间移植。
2.1.5 位级预算
一、布尔运算
编码:true & false 编码为二进制 1 和 0;
运算:非、与、或、异或

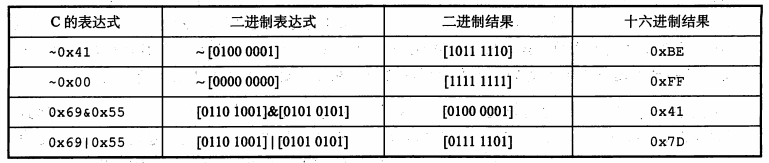
表达式运算:
确定一个位级表达式的结果最好的方法,就是将十六进制的参数扩展成二进制表示并执行二进制运算,然后再转换成十六进制。
二、掩码运算
掩码是一个位模式,表示从一个字中选出的位的集合。
比如,掩码 0xFF(最低的8位为1)表示一个字的低位字节。x&0xFF生成一个由x的最低有效字节组成的值****,其他的字节设置为0. 若 x=0x89abcdef,则将得到 0x000000EF.
三、移位运算
运算
左移
x << k 表示 x 的字节值向左移动 k 位,并在右端补 k 个 0
右移
- 逻辑右移:在左侧补 k 个 0
- 算数右移:在左侧补 k 个最高有效位的值(有符号整数的运算)
当 k 超出位数时
对于一个由 w 位组成的数据类型,若移动 k >= w 位时,C语言标准规定移动 k mod w
优先级
移位运算的优先级低于加减法(不确定时加上括号就完事)
2.2 整数表示
描述两种不同的方式:无符号和有符号
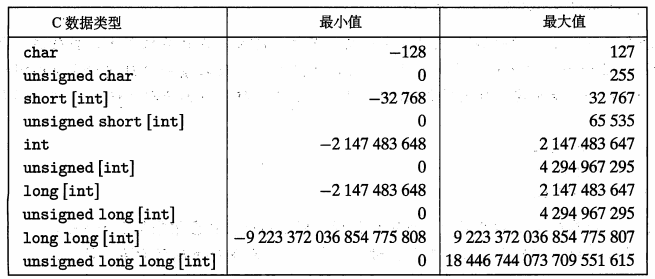
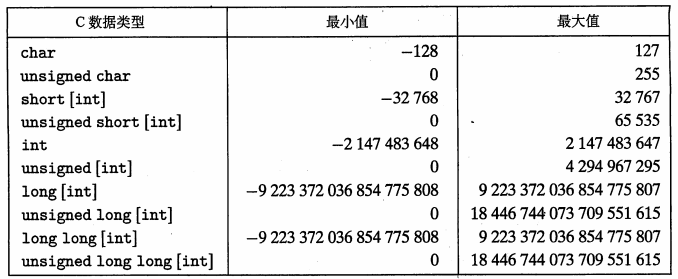
2.2.1 整型数据类型
需要注意的是,取值范围不是对称的,负数的范围比整数的范围大 1
32 位机器
64位机器
2.2.2 编码方式
一、无符号编码
假设一个整数数据类型有w 位,函数B2U (Binary to Unsigned):
\]
其实就是将十进制转换为二进制。
二、补码编码(有符号)
最高有效位为符号位,且|TMin|=|TMax|+1
B2T(Binary to Two's-complement):
\]
- 负数的补码:其绝对值的补码,取反后加一
- 非负数的补码:与无符号编码一致,需注意其他位(尤其是最高位)必是 0
三、有符号数的其他表示方法
反码:除了最高有效位的权是\(-(x^{w-1}-1)\) 而不是\(-2^{w-1}\),其它与补码一致
\[B2O_W(x)=-x_{w-1}(2^{w-1}-1)+\sum_{i=0}^{w-2}x_i2^i
\]原码:最高有效位是符号位,用来确定剩下的位应该取负权还是正权
三、有无符号数的转换
强制类型转换的结果保持位值不变,只是改变了解释这些位的方式。
T2U
\[T2U_w(x)=\begin{cases}x+2^w,&x<0\\x,&x\geq0\end{cases}
\]证明:
计算B2U - B2T 的差,从0到w-2 的位的加权和抵消,剩下 \(B2U(x)-B2T(x)=x_{w-1}(2^{w-1}--2^{w-1})=x_{w-1}2^w\),因此可得\(T2U(x)=B2U(T2B(x))=x_{w-1}2^w+x\)。且在x 的补码表示中,\(x_{w-1}\)决定了x 是否为负,故得上式。
U2T
\[U2T(u)=\begin{cases}u,&u<2^{w-1}\\u-2^w,&u\geq 2^{w-1}\end{cases}
\]证明跟上面差不多,自己推推。
四、位的扩展
将一个较小的数据类型转换到一个较大的类型
- 零扩展:将一个无符号数转换位一个更大的数据类型,在字节位表示的开头添加 0
- 符号扩展:将一个补码数字转换为一个更大的数据类型,在表示中添加最高有效位值的副本
五、数的截断
将一个较大的数据类型转换到一个较小的类型
先看例子:
int x = 53191;
short sx = (short) x; /* 将32位的int阶段为16位的short,截断后位模式为-12345的补码 */
int y = sx; /* 符号扩展上一行的-12345,得到-12345的32位补码表示 */
将一个 w 位的数截断为k 位数字时,丢弃高w-k 位,可能会改变它的值(overflow)。下面探究截断前后的数值变化的规律。
对于一个无符号数字x ,截断它到k 位的结果就相当于计算 x mod 2^k,综合上面T2U 和U2T,不难推理出:
- 无符号
\]
- 补码数字
\[B2T_k([x_{k-1},\cdots,x_0])=U2T_k(B2U_w([x_{w-1},..,x_0])mod\space2^k)
\]
上面表述是课本表述,简单点说其实就是,先将 x 无符号化,然后对 2^k 取余,即可得到无符号类型的截断结果,若要得到有符号类型,直接运用U2T 即可。
2.2.3 C语言中的有无符号数
声明一个像 12345 的常量时,这个值被认为是有符号的。要创建无符号常量,须加上后缀'u';用 printf 输出时,%d、%u和%x 分别表示以十进制、无符号十进制和十六进制格式输出
C语言允许无符号数与有符号数的转换,服从T2U 和 U2T ,其中w 表示数据类型的位数。
/* 显式的强制类型转换 */
int tx, ty;
unsigned ux, uy;
tx = (int) ux;
uy = (unsigned) ty;
/* 不同类型变量赋值也会发生隐式类型转换 */
需要注意的是,当一个运算式中同时出现有符号和无符号数时,C语言会隐式的将有符号转换为无符号。

另外这里补充一下C TMin 的写法
#define INT_MAX 2147483647
#define INT_MIN (- INT_MAX - 1) //这样表示,因为limits.h头文件写法如此
2.3 整数运算
2.3.1 加法
一、无符号加法
无符号数字相加运算
考虑两个非负整数x 和y,满足 \(2\leq x,y\leq 2^w-1\)。实际上就是两者位数为w。
无符号运算可以视为一种模运算形式。无符号加法等价于计算和模上\(2^w\)。在数位上,可以通过简单的丢弃x+y 的w+1 位表示的最高位,来计算这个数值。
{w+1}\end{cases}
\]
判断无符号相加是否溢出
当且仅当 s<x(或者等价地*s<y)时,发生了溢出。
- 证明:
- 若没有溢出,\(x+y\geq x\),则必然\(s\geq x\)
- 若溢出了,有\(s=x+y-2^w\),又由于 \(y<2^w\),则 \(y-2^w<0\),因此 \(s=x+(y-2^w)<x\)
- 证明:
加法逆元
对于每个值x,必然有某个值\(-_w^ux\)满足\(-_w^ux+_w^ux=0\),则该值称为x 的加法逆元。
\[-_w^ux=\begin{cases}x,&x=0\\2^w-x,&x>0\end{cases}
\]- 证明:
- 当x =0时,加法逆元显然是0
- 当x >0时,考虑 \(2^w-x\),\((x+2^w-x)\space mod\space 2^w=0\),故该值即为x 的逆元
- 证明:
二、补码加法
补码加法定义
定义字长为w 的、运算数 x 和 y 上的补码加法(x 和 y 满足 \(-2^{w-1}\leq x,y\leq 2^{w-1}\),表示为 \(+_w^t\):
\[x+_w^ty=U2T(T2U(x)+_w^uT2U(y))=U2T[(x+y)\space mod\space 2^w]
\]溢出情况
下面分四种情况分析:定义 z 为整数和 z=x+y ,z' 为 \(z'=z\space mod\space 2^w\),而 z'' 为 \(z''=U2T(z')\),即 \(x+_w^ty\)
- \(-2^w\leq z< -2^{w-1}\):负溢出。\(z'=z+2^w\),得出\(0\leq z'\leq 2^{w-1}\),则 \(z''=z'=x+y+2^w\)
- \(-2^{w-1}\leq z<2^{w-1}\):易得 \(z''=x+y\)
- \(2^{w-1}\leq z<2^w\):正溢出。\(z'=z\),得到 \(2^{w-1}\leq z'<2^w\),但在该范围内,\(z''=z'-2^w=x+y-2^w\)。
综上所述:
\[x+_w^ty=
\begin{cases}
x+y-2^w,&2^{w-1}\leq x+y\\
x+y,&-2^{w-1}\leq x+y<2^{w-1}\\
x+y+2^w,&x+y<-2^{w-1}
\end{cases}
\]从上式也可判断,负加负得正时负溢出,正加正得负时正溢出
补码加法实例
下图是4位补码加法的实例:
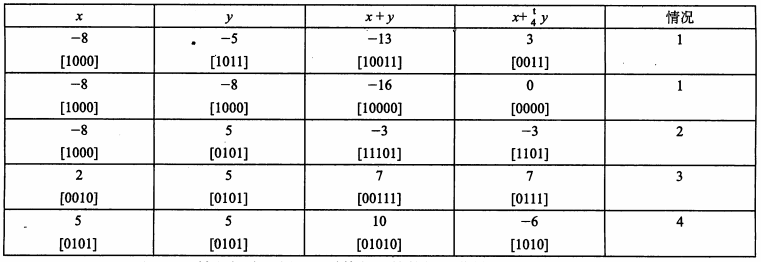
补码的非(加法逆元)
\[-_w^tx=
\begin{cases}
-2^{w-1},&x=-2^{w-1}\\
-x,&x>-2^{w-1}
\end{cases}
\]
2.3.2 乘法
一、无符号乘法
w 位无符号乘法运算 \(*_w^u\) 的结果为:
\]
二、补码乘法
w 位的补码乘法运算 \(*_w^t\) 的结果为:
\]
三、无符号与补码乘法的关联
给定长度为 w 的位向量 x,y,两者无符号相乘和补码相乘,截断为 w 位的位级表示相同。
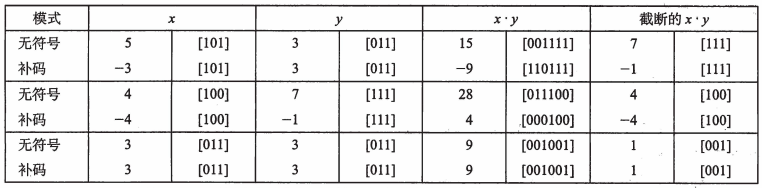
四、乘以常数
由于整数乘法指令相当慢,机器常使用移位和加法运算的组合来代替乘以常数因子的乘法。
先考虑乘以 2 的幂
对于一个位模式为 \([x_{w-1},x_{w-2},..,x_0]\)的补码数 x ,以及范围在 \(0\leq k<w\) 内的任意的 k ,位模式 \([x_{w-1},x_{w-2},..,x_0,0,..,0]\) 就是 \(x*_w^t2^k\) 的补码表示。(事实上无符号结果也是如此)
因此对于有符号变量 x,C表达式 x<<k 等价于 \(x*2^k\)。
无论是无符号还是补码运算,乘以2的幂都可能会导致溢出,但通过移位得到的结果是一样的
乘以一个任意常数
先举几个例子:
- x*14:利用等式 14=23+22+2^1,编译器重写为 (x<<3)+(x<<2)+(x<<1)
- x*14:也可以利用 14=2^4-2 ^1,重写为 (x<<4)-(x<<1)
对于某个常数 K 的表达式 x * K 生成代码,编译器会将 K 的二进制表示表达为一组 0 和 1 交替的序列:\([(0\cdots0)(1\cdots1)(0\cdots0)\cdots(1\cdots1)]\)
考虑一组从位位置 n 到位位置 m 的连续的 1 ( n>=m)。用下列两种形式中的一种来计算这些位对乘积的影响:
- 形式 A:(x<<n) + (x<<n-1) + ... + (x<<m)
- 形式 B:(x<<n+1) - (x<<m)
五、除以 2 的幂
整数除法总是舍入到零。对于 \(x\geq0\) 和 \(y>0\) ,结果是 \([x/y]\),这里对于任何实数 a,[a]定义为唯一的整数 a',使得 a' <= a < a'+1. 例如[3.14]=3, [-3.14]=-4.
记清楚,向零舍入,是我们做除法所需要的正确结果。
无符号数(逻辑移位)
对一个无符号数执行逻辑右移 k 位的效果,和除以 \(2^k\) 有一样的效果。C 表达式 x >> k 等价于 x/pwr2k.
有符号数(算术移位)

可以发现,对 x<0 和 y>0,整数除法的结果应该是 [x/y],即将负的结果向上朝零舍入,当舍入发生时,将一个负数右移 k 位不等价于把它除以 2^k.
可以在移位前“偏置”这个值,利用属性 [x/y]=[(x+y-1)/y],这样通过给 x 增加一个偏量 y-1,然后再将除法向下舍入,当 y 整除 x 时,得到 k,否则得到 k+1。因此在右移前,先将 x 加上 2^k-1,就可以得到正确舍入的结果。
C表达式 (x<0? (x + (1<<k) - 1) : x) >> k 等价于 x/pwr2k
不幸的是,不能用除以 2 的幂的除法来表示除以任意常数 K 的除法
2.4 浮点数
2.4.1 浮点表示
一、二进制小数
形如 \(b_mb_{m-1}\cdots b_1b_0.b_{-1}\cdots b_{-n}\) ,表示的数 b 定义如下:
\]
例如,101.11表示数字 \(1\times 2^2+0\times 2^1+1\times 2^0+1\times2^{-1}+1\times 2^{-2}=4+0+1+1/2+1/4=5\frac{3}{4}\)
不过我们并不能把 0.20 准确的表示为一个二进制小数,只能近似地表示它,增加二进制表示的长度可以提高表示的精度:
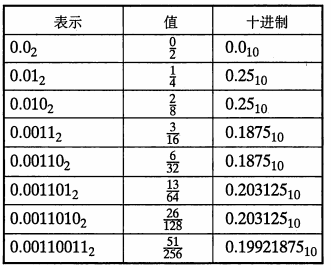
二、IEEE 浮点表示
浮点表示定义
IEEE 浮点标准用 \(V=(-1)^s\times M\times 2^E\) 的形式来表示一个数:
- 符号: s 决定这个数是负数(s=1)还是正数(s=0),对于数值 0 的符号位解释作为特殊情况处理。
- 尾数:M 是一个二进制小数,范围是 1~2-e,或者是 0~1-e。
- 阶码:E 的作用是对浮点数加权,这个权重是 2 的 E 次幂(可能是负数)
将浮点数的位表示划分为三个字段,分别对这些值进行编码:
- 一个单独的符号位 s 直接编码符号 s
- k 位的阶码字段 exp = \(e_{k-1}\cdots e_1e_0\) 编码阶码 E
- n 位小数字段 frac = \(f_{n-1}\cdots f_1f_0\) 编码尾数 M,但是编码出来的值也依赖于阶码字段的值是否等于 0
单精度与双精度
- 单精度:(float)s、exp、frac 字段分别为 1 位、k = 8 位和 n = 23位
- 双精度:(double)s、exp、frac 字段分别为 1 位、k = 11 位和 n = 52 位
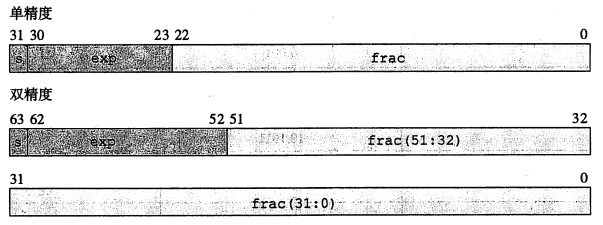
位表示的三种情况
根据 exp 的值,被编码的值可以分成三种不同情况(最后一种情况有两个变种)
下图展示了对单精度格式的情况
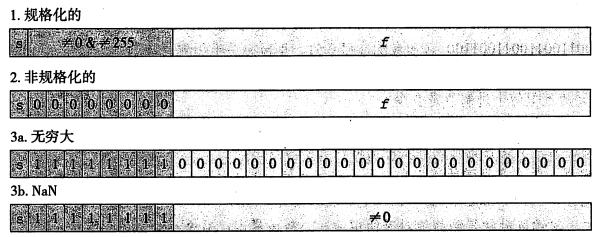
规格化的值
最普遍。exp 的位模式不全为0,也不全为1(单精度数值为255,双精度为2047)
- 阶码:阶码字段被解释为以偏置形式表示的有符号整数,E = e - Bias ,其中e 为无符号数,Bias 是一个等于 \(2^{k-1}-1\)(单精度是127,双精度是1023)的偏置值。由此产生指数的取值范围,单精度是 -126 ~ +127,双精度是 -1022 ~ +1023。
- 尾数:小数字段 frac 为小数值f,范围大于等于0小于1,其二进制小数点在最高有效位的左边。而尾数 \(M=1+f\)。(包含隐含开头1)
非规格化的值
exp 的位模式全为 0。
阶码值是 E = 1 - Bias ,尾数的值是 M = f ,也就是小数字段的值,不包含隐含开头 1.
用途是,1. 提供了一种表示数值 0 的方法;2. 表示那些非常接近于 0.0 的数
特殊值
exp 的位模式全为1。
- 当小数域全为 0 时,得到的值表示无穷。s = 0 时为 +infty,s = 1 时为 -infty
- 当小数域为非零时,结果值被称为“NaN”(not a number)。一些运算结果不是实数或无穷时,会返回NaN,比如 \(\sqrt{-1}\) 或 \(\infty - \infty\)。
三、数字示例
情况一
假定 6 位格式,k=3 的阶码位和 n=2 的尾数位,偏置量是 \(2^{3-1}=3\).
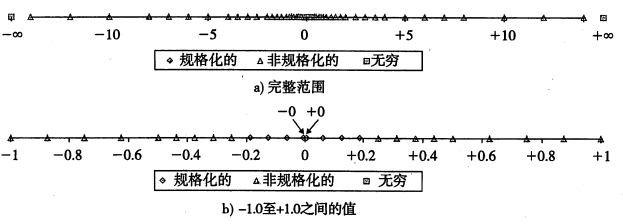
注意,规格化数的阶码无符号数最大值是 \(2^{k-1}-1\),因为不能全为1
最大数量值的规格化数是 \(\pm14\),非规格化数聚集在 0 的附近。
情况二
假定 8 位格式,k=4 的阶码位和 n=3 的小数位,偏置量是 \(2^{4-1}-1=7\)。
这种格式的非规格化的数的 E = 1-7 = -6,得到权 \(2^E=\frac{1}{64}\),小数\(f\) 的范围是 \(0,\frac{1}{8},..,\frac{7}{8}\),从而得到数 V 的范围是 \(0\) ~ \(\frac{1}{64}\times\frac{7}{8}=\frac{7}{512}\)。
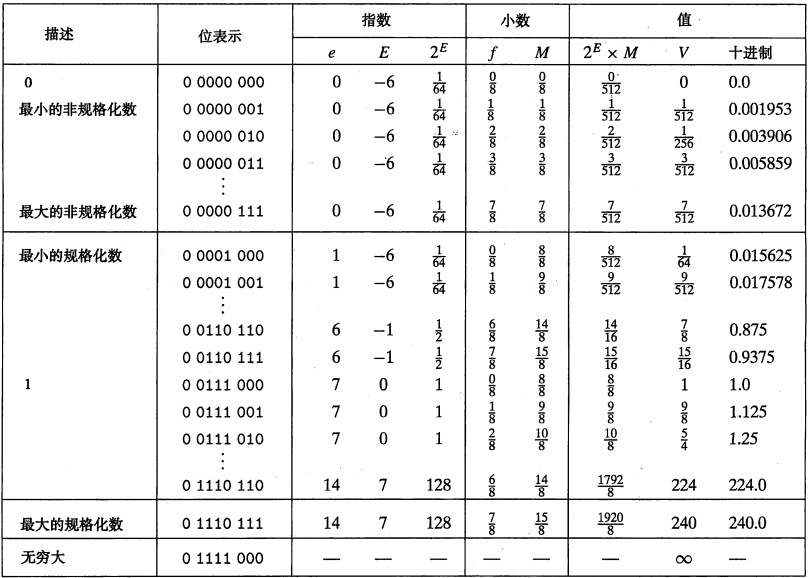
一般属性
- 值 +0.0 总有一个全为 0 的位表示。
- 最小的正非规格化值的位表示:最低有效位为1其他位为0,小数值\(M=f=2^{-n}\)和阶码值\(E=-2^{k-1}+2\),因此它的数字值为 \(V=2^{-n-2^{k-1}+2}\)
- 最大的非规格化值的位表示:位模式是由全为0的阶码字段和全为1的小数字段组成
- 最小的正规格化的位表示:阶码字段的最低有效位为1,其它位全为0
- 值 1.0 的位表示的阶码字段除了最高有效位等于 0 以外,其它位都等于 1
- 最大的规格化值的位表示的符号位为 0,阶码的最低有效位等于 0 ,其它位等于 1
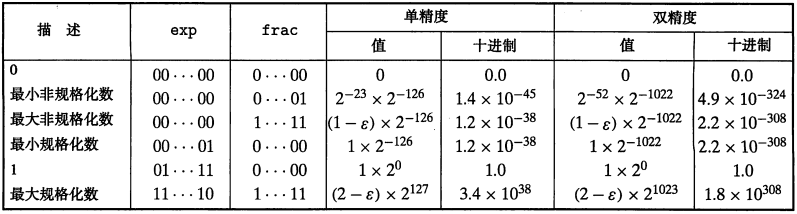
整数转换成浮点形式的例子
12345 的二进制表示为 \([11000000111001]\),通过将二进制小数点左移 13 位,创建了这个数的一个规格化表示,得到 \(12345 = 1.1000000111001_2\times 2^{13}\)。利用 IEEE 单精度形式来编码,即逆过程:
- 小数字段:丢弃开头的 1,在末尾增加 10 个 0,得到\([10000001110010000000000]\)
- 阶码字段:13 + 127 = 140,其二进制为 \([10001100]\)
- 符号位:0
然后拼在一起就是结果了,可以观察到 12345 和 12345.0 在位表示上有一部分是重叠的。
2.4.2 舍入
因为表示方法限制了浮点数的范围和精度,所以浮点运算只能近似地表示实数运算。因此对于值 x ,一般想用一种系统地方法,能够找到“最接近的”匹配值 x',可以用期望的浮点式表示出来。即舍入。
IEEE 浮点格式定义了四种不同的舍入方式,默认方法是找到最接近的匹配(向偶数舍入),其它三种可用于计算上界和下界。向偶数舍入,即默认试图找到一个最接近的匹配值,当值处于两个可能结果中间数值时,向偶数舍入(使得结果的最低有效数字是偶数)

向偶数舍入法,能运用于二进制小数。(将最低有效位的值 0 认为是偶数,值 1 认为是奇数)
看例子:考虑舍入值到最近的四分之一,即二进制小数点右边 2 位
非中间值:\(10.00011_2(2\frac{3}{32})\) 向下舍入到 \(10.00_2(2)\),\(10.00110_2(2\frac{3}{16})\) 向上舍入到 \(10.01_2(2\frac{1}{4})\)
中间值:\(10.11100_2(2\frac{7}{8})\) 向上舍入到 \(11.00_2(3)\),\(10.10100_2(2\frac{5}{8})\) 向下舍入到 \(10.10_2(2\frac{1}{2})\)
中间值凑偶,其实就是凑出有效位最后一位为 0
2.4.3 浮点运算
浮点运算的结果是对实际运算的精确结果进行舍入后的结果,记为\(Round(x+y)\)
一、加法
- 定义:\(x+^fy = Round(x+y)\)
- 性质:
- 可交换:\(x+^fy=y+^fx\)
- 不可结合:因为舍入,\((3.14+1e10)-1e10=0.0\),而\(3.14+(1e10-1e10)=3.14\)
- 大多数值有加法逆元:\(x+^f-x=0\),无穷和NaN 是例外,对于任何x,\(NaN+^fx=NaN\)
- 单调性:如果 \(a\geq b\),那么对于任何 a、b、x,除了 NaN ,都有 \(x+a\geq x+b\)。无符号或补码加法不具有这个属性。
二、乘法
- 定义:\(x*^fy=Round(x\times y)\)
- 性质:可交换,不可结合,在加法上不可分配,单调性
这里关于单调性提一点,从浮点运算符合单调性可以看出,浮点不会因为溢出而改变符号
2.4.4 C语言中的浮点数
强制类型转换
这个好像常考
- int 2 float:数字不会溢出,但可能被舍入
- int 或 float 2 double:double 有更大的范围和更高的精度,所以能够保留精确的数值
- double 2 float:范围减小,值可能溢出,精度降低,可能被舍入
- float or double 2 int:值将会向零舍入,也可能会溢出。且,一个从浮点数到整数的转换,如果不能为该浮点数找到一个合理的整数近似值,将会产生一个整数不确定值。
Ch2信息的表示和处理——caspp深入理解计算机系统的更多相关文章
- 深入理解计算机系统 第二章 信息的表示和处理 Part2 第二遍
<深入理解计算机系统> 第三版 第二遍读这本书,每周花两到三小时时间,能读多少读多少(这次看了 29 ~ 34 页) 第一遍对应笔记链接 https://www.cnblogs.com/s ...
- 深入理解计算机系统 第二章 信息的表示和处理 Part1 第二遍
<深入理解计算机系统> 第三版 第二遍读这本书,每周花两到三小时时间,能读多少读多少(这次看了 22 ~ 28 页) 第一遍对应笔记链接 https://www.cnblogs.com/s ...
- 深入理解计算机系统 第二章 信息的表示和处理 part2
上一周遗留问题的解决 问题:原码.反码.补码是只针对有符号数吗?无符号数有没有这三种编码方式? 得到的答案:对于无符号数,原码.反码和补码是一致的 进一步,由于有符号数是以补码的形式存储在计算机中 ...
- 深入理解计算机系统 第二章 信息的表示和处理 part1
欣哥划的重点: 第二章比较难,建议至少掌握下面几个知识点: 1. 字节顺序 : 大端和小端 2. 运行 图2-24, 图2-25程序 show-bytes.c 观察结果,看看有什么问题 3. 理解布尔 ...
- 2017-2018-2 165X 『Java程序设计』课程 助教总结
2017-2018-2 165X 『Java程序设计』课程 助教总结 本学期完成的助教工作主要包括: 编写300道左右测试题,用于蓝墨云课下测试: 发布博客三篇:<2017-2018-2 165 ...
- 20145221 《信息安全系统设计基础》实验五 简单嵌入式WEB服务器实验
20145221 <信息安全系统设计基础>实验五 简单嵌入式WEB服务器实验 实验报告 队友博客:20145326蔡馨熠 实验博客:<信息安全系统设计基础>实验五 简单嵌入式W ...
- 教你如何利用分布式的思想处理集群的参数配置信息——spring的configurer妙用
引言 最近LZ的技术博文数量直线下降,实在是非常抱歉,之前LZ曾信誓旦旦的说一定要把<深入理解计算机系统>写完,现在看来,LZ似乎是在打自己脸了.尽管LZ内心一直没放弃,但从现状来看,需要 ...
- 20135328信息安全系统设计基础第二周学习总结(vim、gcc、gdb)
第三周学习笔记 学习计时:共8小时 读书:1 代码:5 作业:1 博客:7 一.学习目标 熟悉Linux系统下的开发环境 熟悉vi的基本操作 熟悉gcc编译器的基本原理 熟练使用gcc编译器的常用选项 ...
- linux查看CPU高速缓存(cache)信息
一.Linux下查看CPU Cache级数,每级大小 dmesg | grep cache 实例结果如下: 二.查看Cache的关联方式 在 /sys/devices/system/cpu/中查看相应 ...
随机推荐
- JPA query between的多种方式(mongodb为例)
背景 JPA+MongoDB查询,给定一段时间范围查询分页结果,要求时间范围包含. Page<Log> findByCtimeBetweenOrderByCtime( LocalDateT ...
- 为什么Java不允许创建范型数组
问题示例 List<Integer>[] intListArr = new ArrayList<Integer>[8]; // 编译时报错 能看到这么看似没啥问题的一个简单语句 ...
- 将input 的文本框改为不可编辑状态
<input type="text" id = "textid" name="名称" value="值" size ...
- img标签到底是行内元素还是块级元素
面试官问你<img>是什么元素时你怎么回答 写这篇文章源自我之前的一次面试,题目便是问img标签属于块级元素还是行内元素,当时想都没想就说了是行内(inline)元素,面试官追问为什么能够 ...
- Contest 1445
A \(a\) 中第 \(i\) 小的配 \(b\) 中第 \(i\) 大的. 限制相同,这样配最平均. 时间复杂度 \(O\left(tn\log n\right)\). B 最终的一百名至少是第一 ...
- O - Matching 题解(状压dp)
题目链接 题目大意 给你一个方形矩阵mp,边长为n(n<=21) 有n个男生和女生,如果\(mp[i][j]=1\) 代表第i个男生可以和第j个女生配对 问有多少种两两配对的方式,使得所有男生和 ...
- Python爬虫实战案例:取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一 ...
- PyQt(Python+Qt)学习随笔:QScrollArea的alignment属性不起作用的原因
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 Scroll Area滚动区域提供了一个呈现在其他部件上的可滚动区域视图,对应类为QScrollAr ...
- PyQt(Python+Qt)帮助文档官网及文档下载
一.帮助文档下载 老猿在网上找到一个Qt 5.9的帮助文档,没有找到最新版的,并且这个文档官网上没有下载,不知道源头在哪里可以下载. 文档存放在百度网盘: 链接:https://pan.baidu.c ...
- 用Python爬取了三大相亲软件评论区,结果...
小三:怎么了小二?一副愁眉苦脸的样子. 小二:唉!这不是快过年了吗,家里又催相亲了 ... 小三:现在不是流行网恋吗,你可以试试相亲软件呀. 小二:这玩意靠谱吗? 小三:我也没用过,你自己看看软件评论 ...