聊聊kafka-client的源码
一,感想
kafka 客户端代码很早以前 我就想研究借鉴一下,我前前后后至少阅读过三遍源码,我发现我看不下去,不知道为啥这么写,在次期间,我也参考了很多的网上的源码分析,我发现自己依然一知半解的,
慢慢的我明白了,我之所以看不懂,是因为缺少基础理论知识支持。我对NOI,TCP,IO模型基本上都是完全木有接触过。下面的内容我会列举一下,看懂kafka源码需要储备的理论知识。
按照我阅读源码的经验,带着问题看源码,效果事半功倍。我们以kafka 发送请求为例
1,KAFKA 数据发送不是请求以后立马发送,而是存储在本地,那么发送数据在本地如何存储
2,KAFKA 信息格式是啥样的(https://blog.csdn.net/u013256816/article/details/80300225 目前看V1 版本的消息格式即可,后续kafka-client 消息也是以V1版本为主)
3,KAFKA 通信协议是啥样的(https://www.jianshu.com/p/e921628bf461 大神分享的,非常详细,建议完整读一遍)
4,KAFKA 数据在broker如何保存,以及模拟一下根据offset 如何查找到准确的数据
5,kafka-client 内存如何管理的(https://www.cnblogs.com/huxuhong/p/13651696.html )
6,了解过nio吗,NIO模拟通过TCP完成一次通信能够完成吗(https://www.cnblogs.com/huxuhong/p/13713511.html ,给了一个通过nio发送文件的demo,以及一些基础理论知识,快速入门)
7,IO复用模型了解过吗(select,poll,epoll,IO复用模型的三种方式以及异同点)
8,零拷贝了解过吗?对虚拟内存,页缓存,内存映射这些名字又基本的了解吗(总结一次网络请求的步骤,区别)
1,最早的socket=read+write,read负责数据从磁盘copy到内核缓冲区,内核缓冲区copy到用户缓冲区,用户缓冲区copy到内核socket缓冲区,socket缓冲区copy到协议引擎。
2,mmap在read的基础上,省去了内核与用户缓冲区的拷贝。因为两者会共享一个缓冲区。这样磁盘copy到内核共享缓冲区,共享缓冲区copy到socket缓冲区,后者copy到协议引擎。(零拷贝,)
3,sendFile在nmap的基础上,省去了内核共享缓冲区copy到socket缓冲区,而是直接从内核共享缓冲区copy到协议引擎。在此过程中,socket缓冲区只是记录一些元信息(零拷贝)
https://blog.csdn.net/weixin_42447959/article/details/103499353(参考链接)
https://blog.csdn.net/alex_xfboy/article/details/90174840(参考链接)
9,堆外内存的申请和回收(Reference),使用场景,为啥要使用堆外内存,以及带来的风险点了解吗
https://ifeve.com/java-reference%E6%A0%B8%E5%BF%83%E5%8E%9F%E7%90%86%E5%88%86%E6%9E%90/(从Java级别分析)
https://github.com/farmerjohngit/myblog/issues/10(从jvm级别分析)
如果对上述都了解,建议可以直接上手源码,你会发现KAFKA CLIENT源码,很简单,花个三五小时就可以完全明白。
2,3,6,7是必须掌握的理论知识,否则你会发现无法理解KAFKA CLIENT源码,下文采用kafka-client-0.10.0.1版本,之所以强调版本是因为kafka-client这个版本之后,消息格式就采用了V2版本,V2消息格式极其复杂,新手建议直接上手V1版本的消息格式。
要想理解kakfa-producer的发送过程,我们按照正常顺序按照代码的运行顺序一步一步debug往下看,说实话有点难,那么我们换一个思路,我们先了解kafka-client 网络通信模型(因为前期准备的所有数据,都是为了适配这个模型)
二,从kafka-client 网络通信模型了解整个kafka-client的发送过程
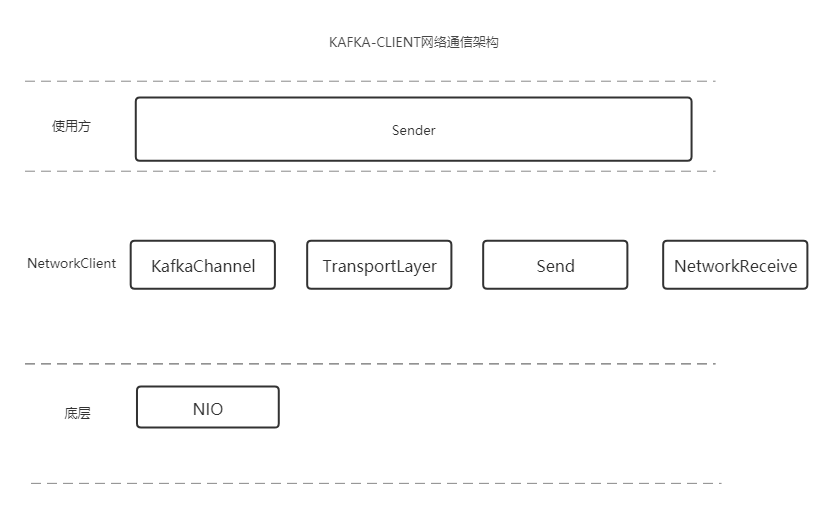
Sender 使用kafka-client 网络通信调用方
KafkaChannel:一个broker对应一个kafkachannel,具体发送请求交给TransportLayer
TransportLayer:这个东西是对socketChannel 的封装,负责具体发送请求
Send:存储要发送的数据
NetworkReceive:接收broker响应数据
下面kafka-client 一种请求类型(更多请求类型请查看类:ApiKeys):更新元数据的一次简单模拟请求过程(简化版本)
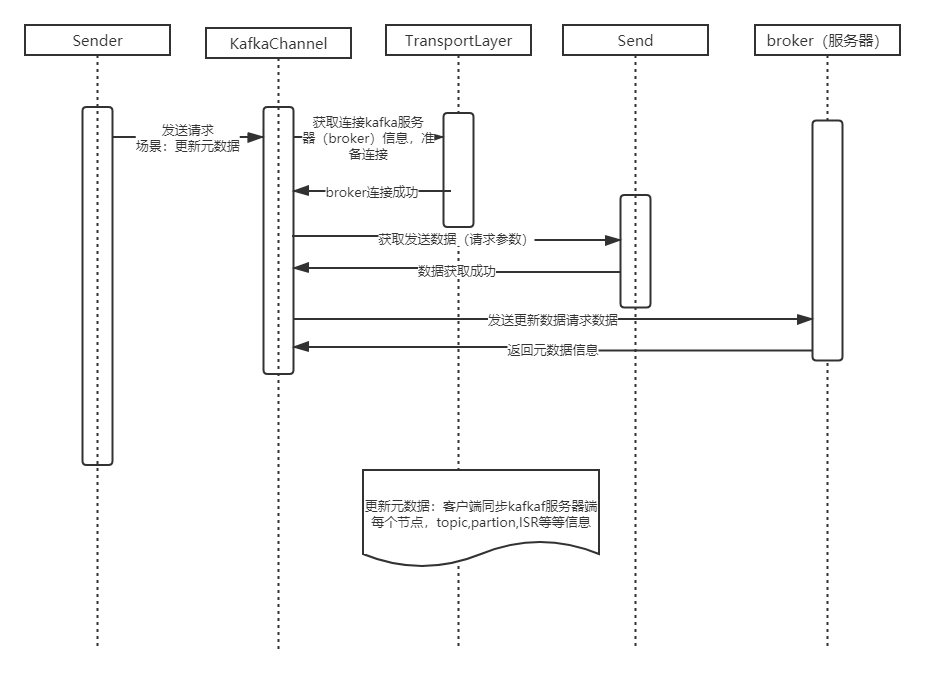
那么完成一次kakfa-client和broker通信,逆向推理一下,只要满足下面几个条件即可
①:填充上述几个类的数据 ==> ②:准备数据 ==> ③:根据 kafka 通信协议以及kakfa V1版本信息格式准备数据
不知道元数据信息,就无法知道当前请求应该投递到那个服务器,无法和服务器建立TCP长链接,所以,元数据信息是一切请求的基点
三,kakfka-client 数据准备流程分析
1,元数据如何更新(KafkaChannel ,TransportLayer初始化)下述的bootstrap.servers就是服务器节点,需要通过向这个节点发起更新元数据请求,更新client端的元数据信息,完成元数据初始化
/**
* 最简单的kafka-client producer代码
*/
Properties props = new Properties();
props.put("bootstrap.servers", "***.***.***.***:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 2; i++){
//看这里,请求开始的地方
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
}
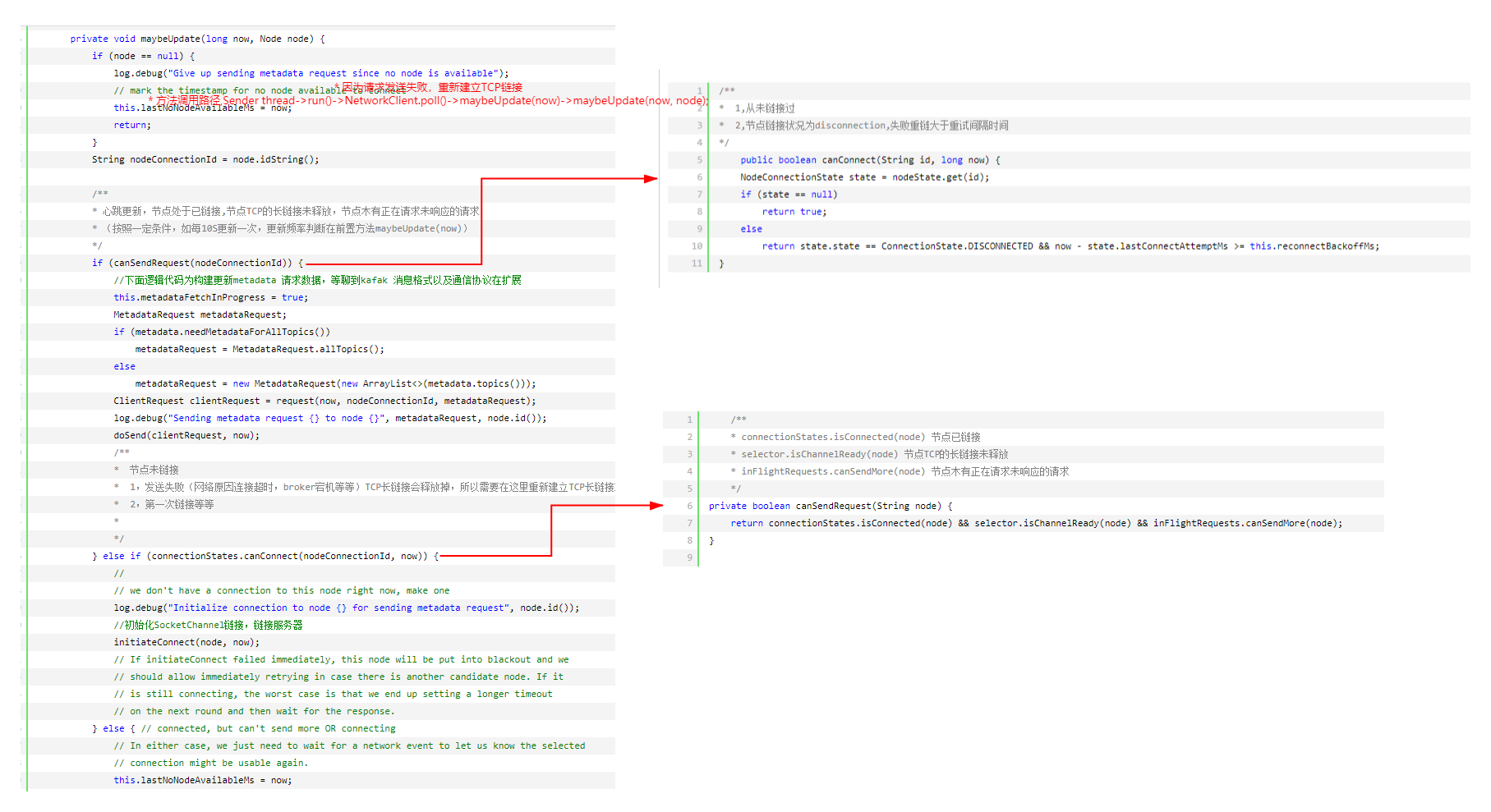
猜想一下,如何更新元数据,(元数据为kafka服务器端集群信息,包括集群节点,节点每个topic,partition,ISR等等),总共有三种情况,需要更新metadata(元数据)
①:我们至少知道一个broker服务器地址(bootstrap.servers配置)
②:初始化以后,第一次发送数据(example:给你一个Topic,木有元数据,我们不知道这个topic在那个broker上,没法发送数据)

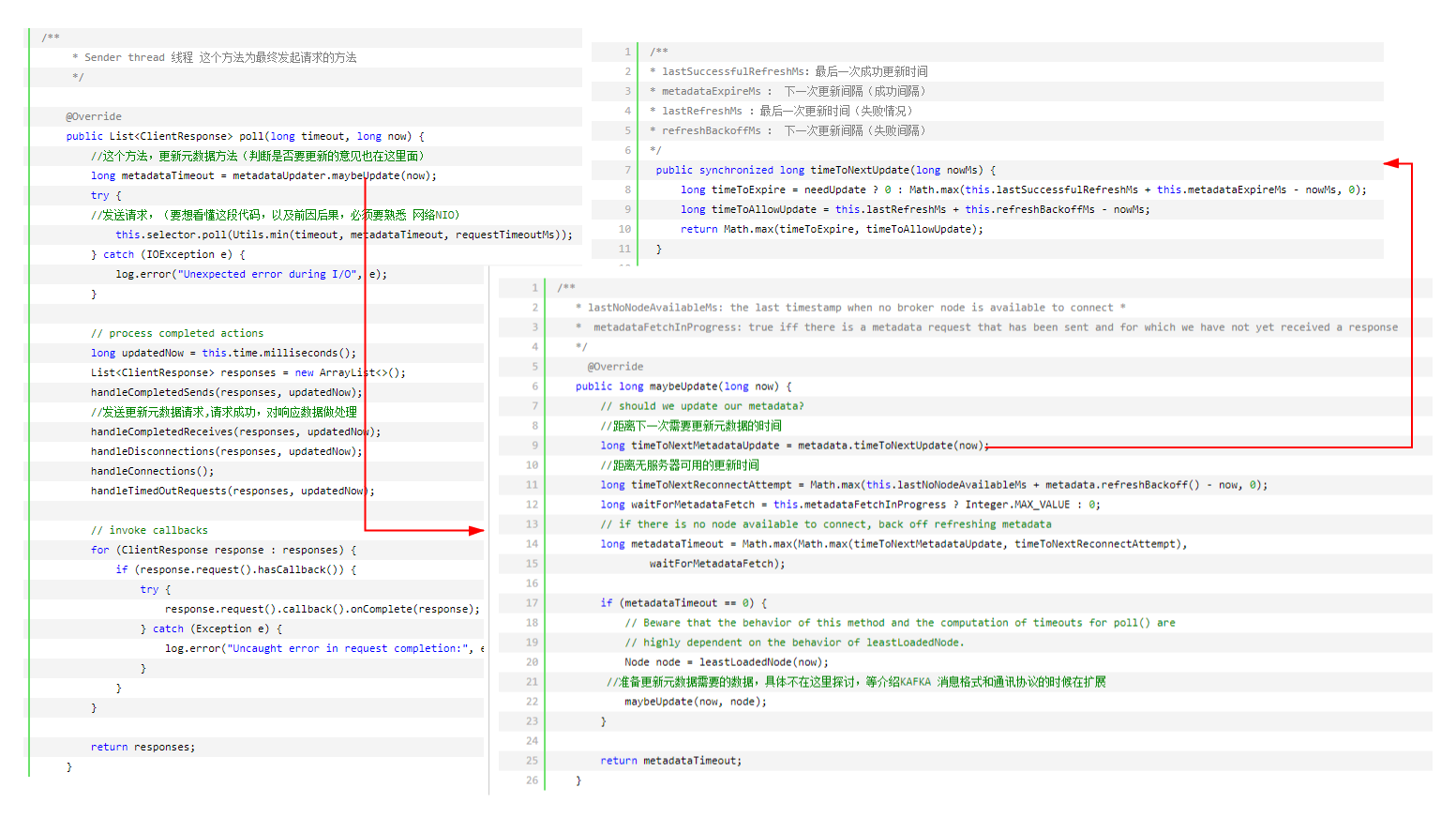
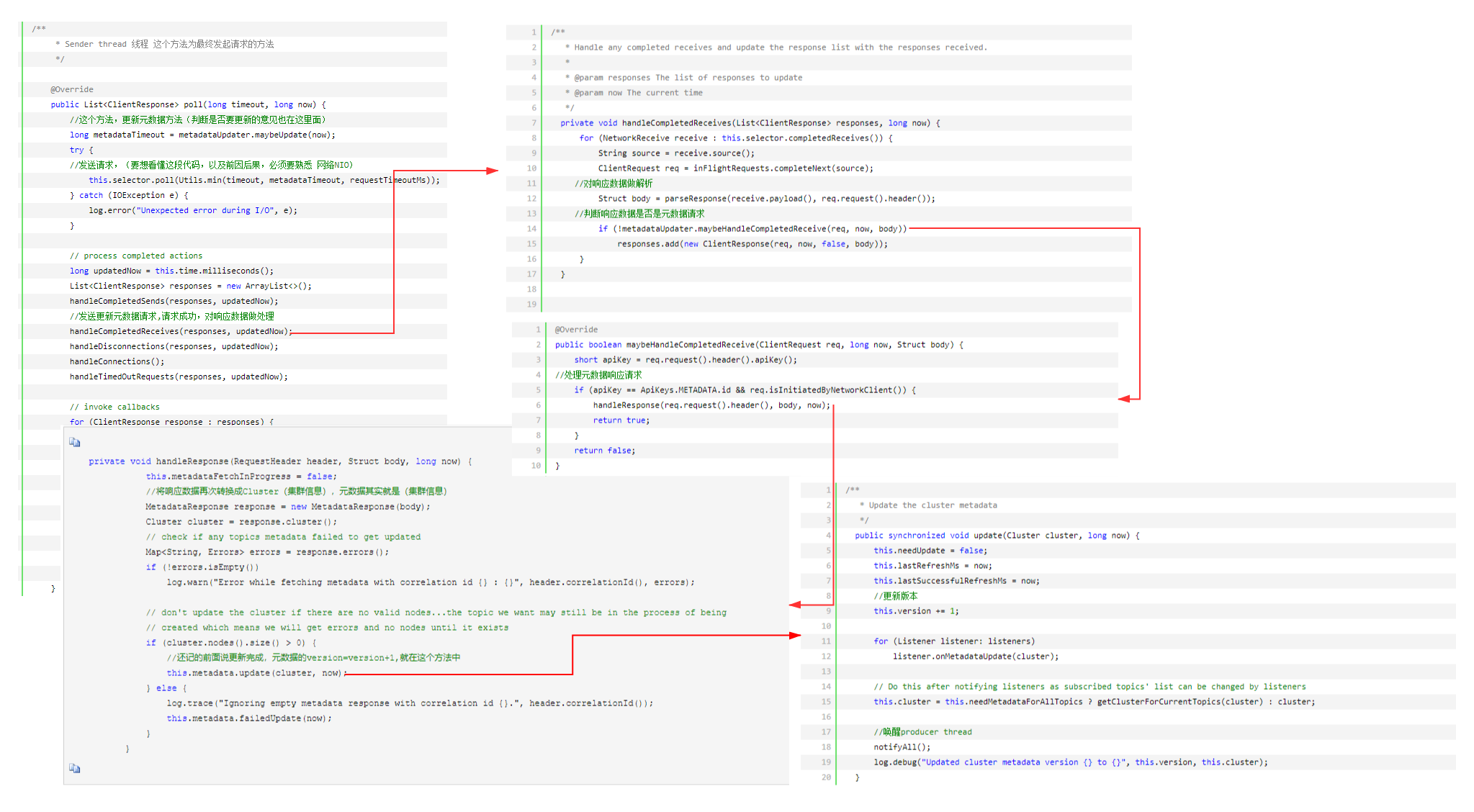
③:发送失败(网络波动连接超时,broker宕机等等)
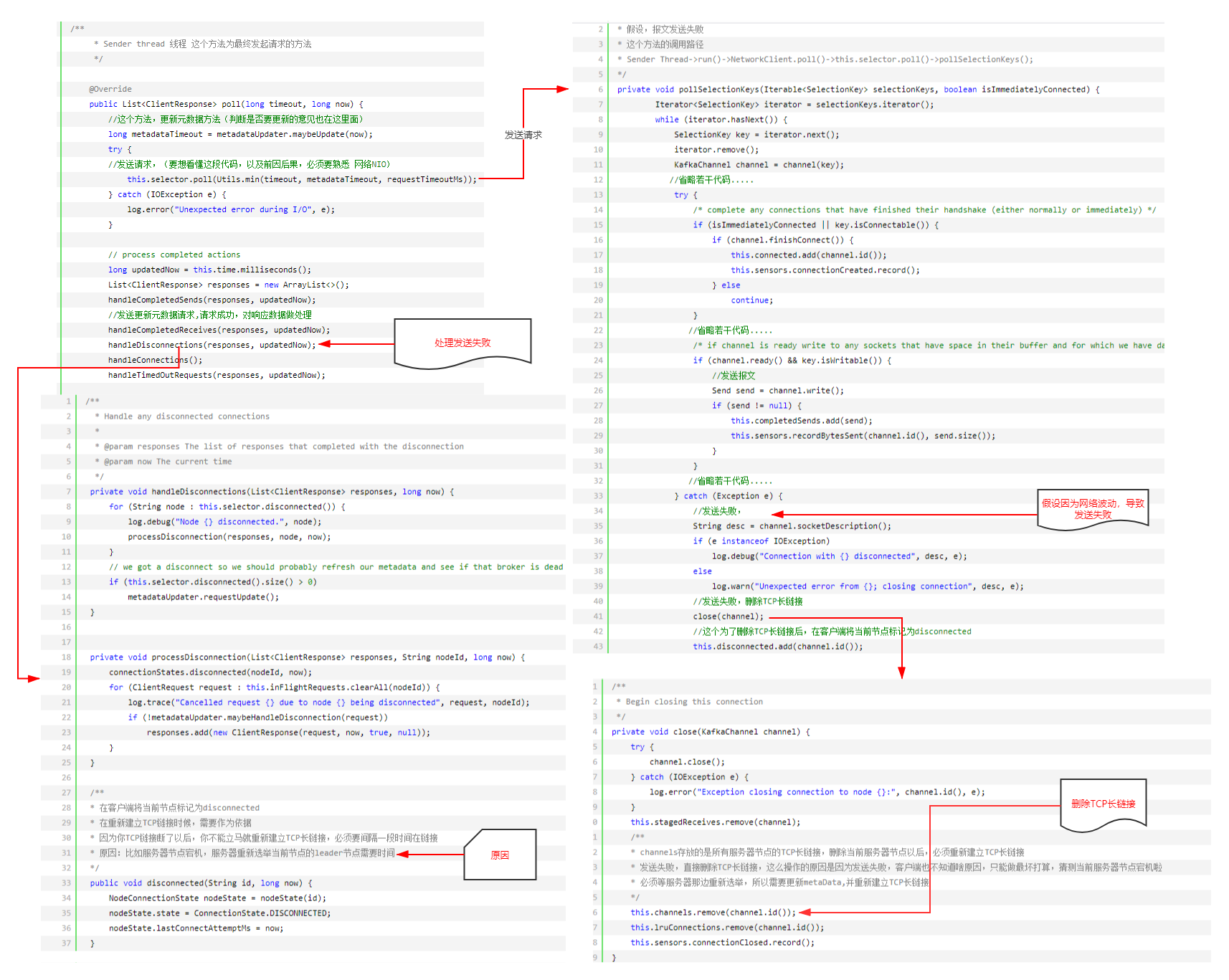
请求发送失败以后,第二次在发送请求之前,重新建立TCP链接,TCP建立链接以后,第三次发起请求时,会重新更新元数据
④:第一次加载以后,心跳更新(按照一定条件,如每10S更新一次)
这种状况,就不梳理啦,很简单,有兴趣的可以自己在梳理一下。其实在上面发送失败的时候场景下,已提及。
2,数据存储(Send 初始化)
通过上面更新元数据信息,我们已经知道数据往哪里发送,下面我们梳理,数据如何在本地存储,这一部分涉及到kafka消息设计和通讯协议。
https://www.cnblogs.com/huxuhong/p/13813654.html
聊聊kafka-client的源码的更多相关文章
- 高吞吐量的分布式发布订阅消息系统Kafka之Producer源码分析
引言 Kafka是一款很棒的消息系统,今天我们就来深入了解一下它的实现细节,首先关注Producer这一方. 要使用kafka首先要实例化一个KafkaProducer,需要有brokerIP.序列化 ...
- Kafka 探险 - 生产者源码分析: 核心组件
这个 Kafka 的专题,我会从系统整体架构,设计到代码落地.和大家一起杠源码,学技巧,涨知识.希望大家持续关注一起见证成长! 我相信:技术的道路,十年如一日!十年磨一剑! 往期文章 Kafka 探险 ...
- IdentityServer4同时使用多个GrantType进行授权和IdentityModel.Client部分源码解析
首先,介绍一下问题. 由于项目中用户分了三个角色:管理员.代理.会员.其中,代理又分为一级代理.二级代理等,会员也可以相互之间进行推荐. 将用户表分为了两个,管理员和代理都属于后台,在同一张表,会员单 ...
- 聊聊最近撸Spring源码感悟
一.前言 最近一段时间撸了Spring IOC.AOP.Transactional源码,这篇文章聊聊我写了哪些小玩意,这可能就是阅读源码以后最大收获.希望大家在里面能学习一些什么东西吧: 二. ...
- Kafka 0.8源码分析—ZookeeperConsumerConnector
1.HighLevelApi High Level Api是多线程的应用程序,以Topic的Partition数量为中心.消费的规则如下: 一个partition只能被同一个ConsumersGrou ...
- 聊聊 JDK 阻塞队列源码(ReentrantLock实现)
项目中用到了一个叫做 Disruptor 的队列,今天楼主并不是要介绍 Disruptor 而是想巩固一下基础扒一下 JDK 中的阻塞队列,听到队列相信大家对其并不陌生,在我们现实生活中队列随处可见, ...
- kafka producer 概要(看源码前,最好能掌握)
kafakproducer概要(看源码前,最好能理解) 摘要 kafak 被设计用来作为一个统一的平台来处理庞大的数据的实时工具,在设计上有诸多变态的要求 它必须具有高吞吐量才能支持大量事件流 ...
- Kafka#4:存储设计 分布式设计 源码分析
https://sites.google.com/a/mammatustech.com/mammatusmain/kafka-architecture/4-kafka-detailed-archite ...
- KClient——kafka消息中间件源码解读
目录 kclient消息中间件 kclient-processor top.ninwoo.kclient.app.KClientApplication top.ninwoo.kclient.app.K ...
- Docker源码分析(二):Docker Client创建与命令执行
1. 前言 如今,Docker作为业界领先的轻量级虚拟化容器管理引擎,给全球开发者提供了一种新颖.便捷的软件集成测试与部署之道.在团队开发软件时,Docker可以提供可复用的运行环境.灵活的资源配置. ...
随机推荐
- 在IIS中部署前后端应用,多么痛的领悟!
目前手上的Web项目是前后端分离的,所以有时也会倒腾Vue框架. 前后端应用最终以容器形态.在k8s中部署, 为此我搭建了基于Gitlab flow的Devops流程. 在Devops实践中,容器部署 ...
- MarkDown及Typora文本编辑器
文章介绍主要介绍MarkDown语法和与之能够配套使用的文本编辑器Typora的下载使用 1. MarkDown简介 MarkDown是一种纯文本标记语言,其书写与txt.word文档类似: 所有网站 ...
- linux 安装部署
[smb] service smb restart vim /etc/selinux/config systemctl stop firewalld.service(centos7 64) seten ...
- springboot + post 中文乱码
去检查你的 filter 配置,是否配置了一个最高优先级的 filter, 这个最高优先级的 filter 会影响 springboot 自动配置的 CharacterEncodingFilter.原 ...
- 走进C# abstract,了解抽象类与接口的异同
前言: 最近在研究.NET Core的一些类库源码的时候发现在底层类库中使用了大量的抽象类,然而发现自己搬砖这么多年好像从来没有在项目中使用抽象类或者抽象方法去实现某个功能模块,并且对修饰符Abstr ...
- JMeter100个线程竟然只模拟出1个并发
线程组,是说到 JMeter 会第一时间想到的东西,也是我认为 JMeter 最难理解的知识点.因为项目让你做个压测,首先就是要考虑并发,用 JMeter 就是用多线程 来模拟多并发.但在看到线程组编 ...
- C# 字符串处理类
using System;using System.Collections.Generic;using System.Text;using System.Text.RegularExpressions ...
- leetcode134:3sum
题目描述 给出一个有n个元素的数组S,S中是否有元素a,b,c满足a+b+c=0?找出数组S中所有满足条件的三元组. 注意: 三元组(a.b.c)中的元素必须按非降序排列.(即a≤b≤c) 解集中不能 ...
- 关于Wrapper Class
public class RunTest{ public static void main(String[] args) { Integer ten=new Integer(10); Long nin ...
- C/C++中内存对齐问题的一些理解(转)
内存对齐指令 一般来说,内存对齐过程对coding者来说是透明的,是由编译器控制完成的 如对内存对齐有明确要求,可用#pragma pack(n)指定,以n和结构体中最长数据成员长度中较小者为有效值 ...