Elasticsearch7.X ILM索引生命周期管理(冷热分离)
Elasticsearch7.X ILM索引生命周期管理(冷热分离)
一、“索引生命周期管理”概述
Elasticsearch索引生命周期管理指:Elasticsearch从设置、创建、打开、关闭、删除的全生命周期过程的管理。
二、为什么要使用“索引生命周期管理”
1、ELK集群之前的索引模式,通过app_name和日期区分,随着时间累积,索引数量逐渐增多,造成服务器内存、CPU、IO等指标上涨;
2、需要创建额外定时任务执行索引删除脚本,这种方式无法避免kafka重复消费造成的大量已删除索引重建,并无法用脚本按日期删除;
3、根据日志查询和存储的特点,将数据冷热分离,热数据使用高性能磁盘提高写入与查询效率,温数据只做查询不影响数据写入性能,冷数据用OSS等低价存储作为归档节约存储成本。
三、面临的问题
1、ES生命周期策略要紧密贴合业务模型
2、数据冷热节点和生命周期策略需要合理规划
3、数据高可用性规划(单纯日志场景对数据可用性并不高,可以规划0副本索引,减小系统开销)
四、配置方法及原理
1、生命周期管理的本质--RollOver
当现有索引被认为太大或太旧时,滚动索引API将别名滚动到新索引。该API接受一个别名和一个条件列表。别名必须只指向一个索引。如果索引满足指定条件,则创建一个新索引,并将别名切换到指向新索引的位置
2、使用场景
RollOver适合存放日志数据、索引非常大、索引实时导入数据等场景
在索引模板配置好索引的setting、mapping等参数,然后配置好_rollover规则,es会帮助你处理剩余的事情
索引生命周期管理使用了rollover的特性,将rollover分成四个阶段。
3、四个阶段
ES索引生命周期管理分为4个阶段:hot、warm、cold、delete,其中hot主要负责对索引进行rollover操作,warm、cold、delete分别对rollover后的数据进一步处理
| 阶段 | 描述 |
|---|---|
| hot | 主要处理时序数据的实时写入 |
| warm | 可以用来查询,但是不再写入 |
| cold | 索引不再有更新操作,并且查询也会很少 |
| delete | 数据将被删除 |
注意:上述四个阶段不是必须同时存在
4、配置方法
实现索引生命周期,必须同时存在如下要素,缺一不可,上述四个阶段可以根据实际情况配置,并为ES数据节点添加相应的标签。
| 配置项 | 描述 |
|---|---|
| 节点标签 | 配置数据节点标签,区分热节点、温节点以及冷节点 |
| 生命周期策略 | 定义热阶段的大小、最大文档数或最大时长,温阶段是否缩小索引、冷阶段存在时长及删除周期 |
| 索引模板引用生命周期策略 | 模板中指定引用的生命周期策略,按模板规则创建索引后,加载生命周期策略 |
| 索引模板指定调度节点 | 将新建索引分片都分配到热节点 |
4.1、节点
热节点
这种类型的数据节点执行集群内所有的操作,节点存储的数据经常被查询,属于IO、CPU密集型操作,因而需要CPU比较空闲和装有高性能IO读写的磁盘(如SSD)的服务器支撑。
#配置方法
vim /data/app/elasticsearch/config/elasticsearch.yml #每个热节点加入如下配置并重启服务
node.attr.box_type: hot
node.attr.rack: rack1
#这两项配置是为节点增加标签,具体名称并不是写死的,与后面模板和策略配置有关
温节点
这种类型的数据节点处理不太常用的索引(比如前一天的日志数据),这种数据查询的实时性不算高,索引为只读索引,不会有写入操作,因此不需要SSD磁盘存储,降低存储成本。
#配置方法
vim /data/app/elasticsearch/config/elasticsearch.yml #每个温节点加入如下配置并重启服务
node.attr.box_type: warm
node.attr.rack: rack1
冷节点
冷节点数据适合作为归档使用,比温节点查询还要少(比如半月以上的归档日志),这种类型数据一般很少查询,并不会消耗CPU性能及IO,但是存储容量会很大,需要更低成本的存储,例如OSS或S3;ES可以使用经过fuse协议挂载的对象存储作为后端存储。
#配置方法
vim /data/app/elasticsearch/config/elasticsearch.yml #每个温节点加入如下配置并重启服务
node.attr.box_type: cold
node.attr.rack: rack1
4.2、生命周期策略
配置方法:
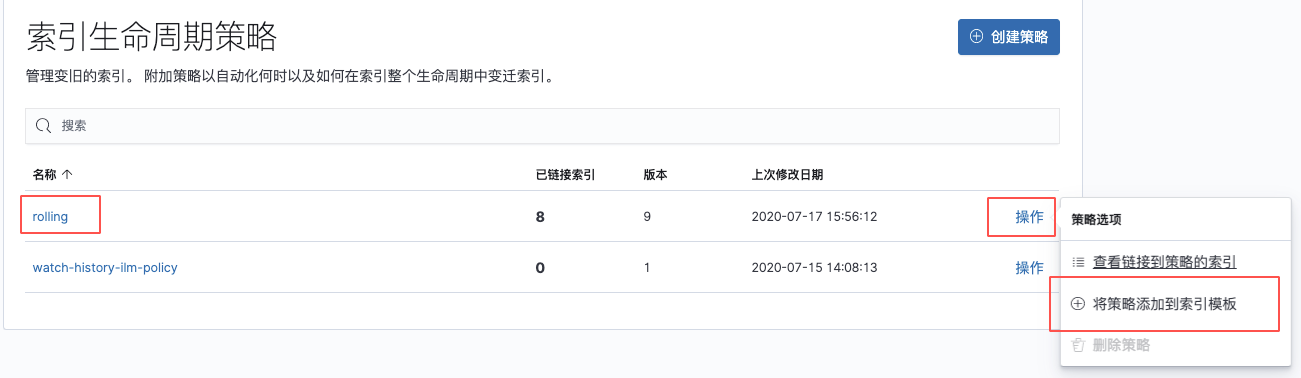
1、利用Kibana新建策略并指定到模板
打开Kibana--->管理--->索引生命周期策略
创建策略
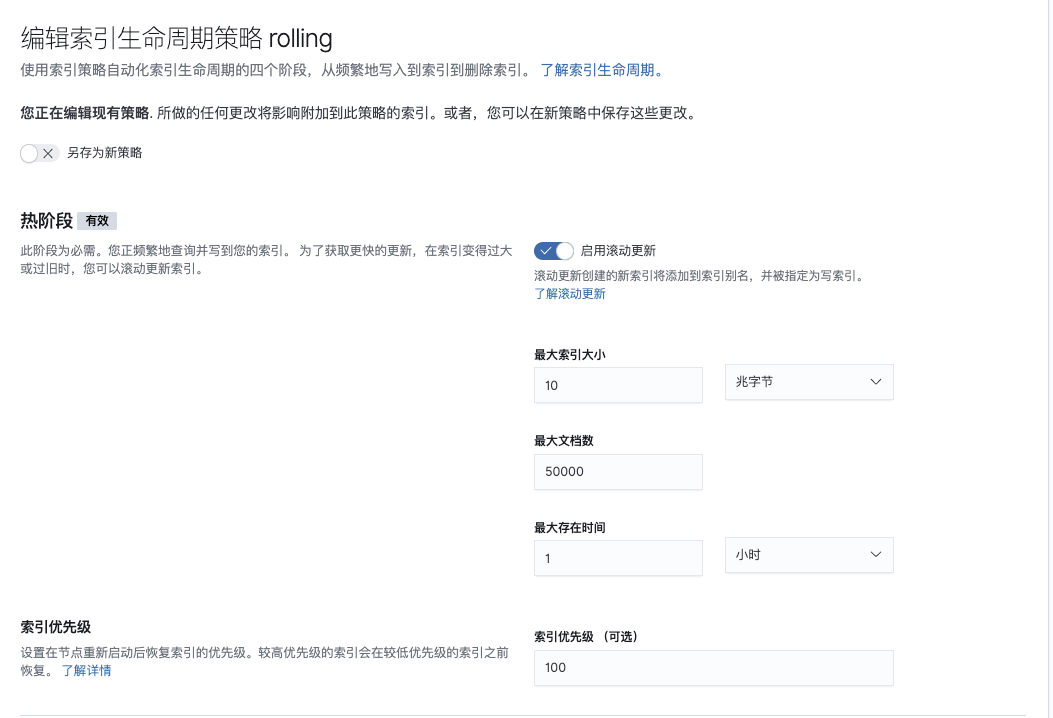
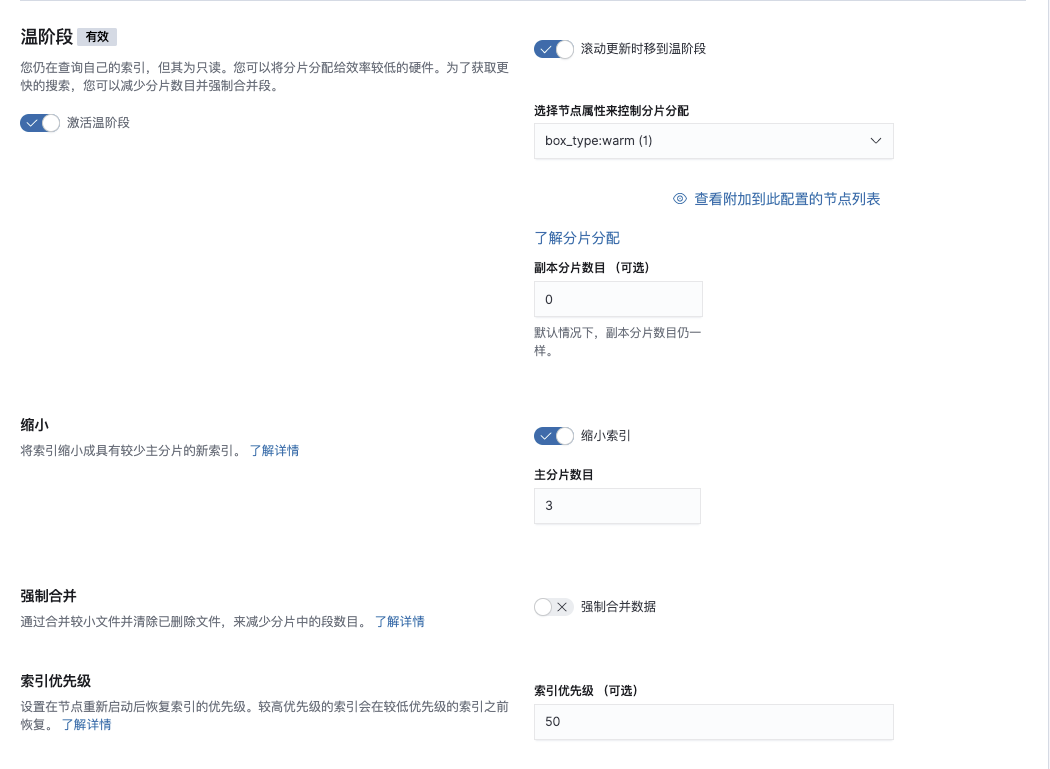
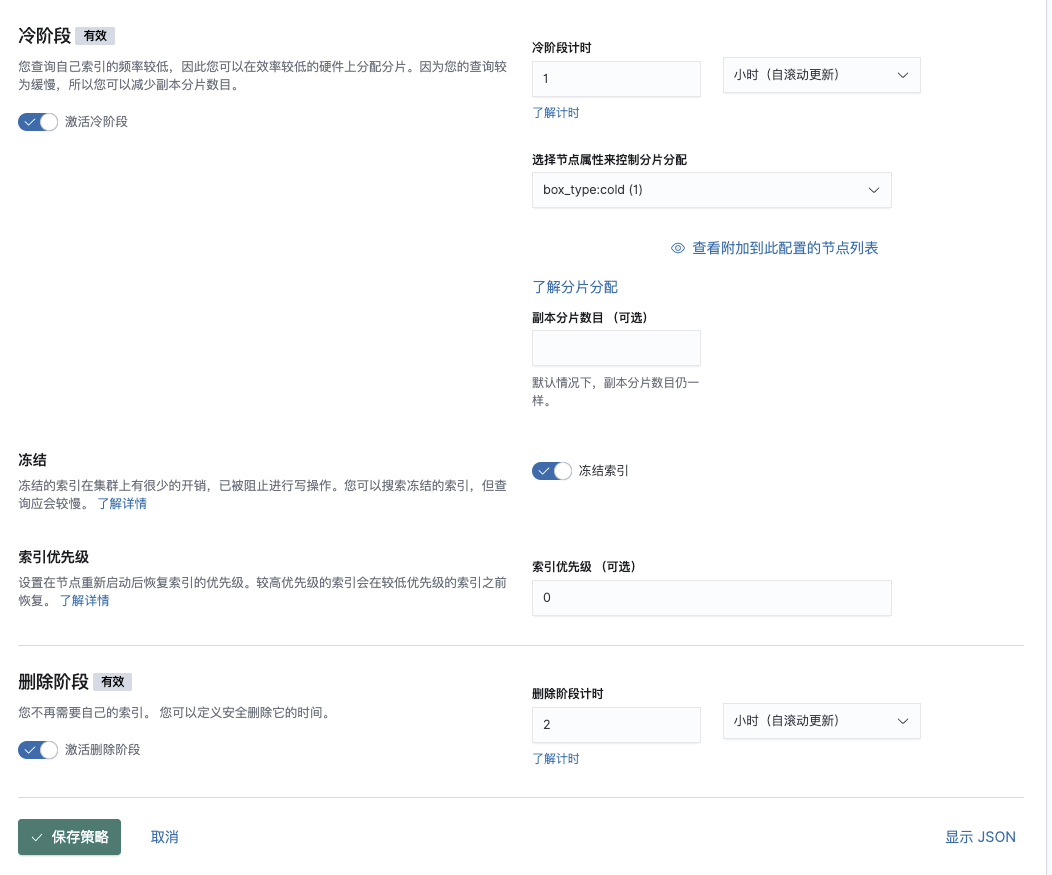
保存策略并在创建模板后添加到模板中
2、调用ESApi将策略写入ES
curl -XPUT -H "content-type:application/json" http://es_addr:9200/_ilm/policy/test_policy \
-d "{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_age": "1h",
"max_size": "10mb",
"max_docs": 50000
},
"set_priority": {
"priority": 100
}
}
},
"warm": {
"min_age": "0ms",
"actions": {
"allocate": {
"number_of_replicas": 0,
"include": {},
"exclude": {},
"require": {
"box_type": "warm"
}
},
"shrink": {
"number_of_shards": 3
},
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "1h",
"actions": {
"freeze": {},
"allocate": {
"include": {},
"exclude": {},
"require": {
"box_type": "cold"
}
},
"set_priority": {
"priority": 0
}
}
},
"delete": {
"min_age": "2h",
"actions": {
"delete": {}
}
}
}
}"
4.3、索引模板
以下为索引模板配置,要有以下配置项策略才会生效,其他选项如字段mapping等请参考官方文档
PUT _template/my_template
{
"index_patterns": ["test-*"],
"settings": {
"number_of_shards": 5,
"number_of_replicas": 0,
"index.lifecycle.name": "test_policy", #指定索引生命周期策略名称
"index.lifecycle.rollover_alias": "test-alias", #指定rollover别名(索引写入与读取时所用的名称)
"routing.allocation.require.box_type": "hot" #指定索引新建时所分配的节点(此项不指定会默认分配到所有节点)
}
}
注意:索引创建的名称应该是以 “-00001”等可自增长的字段结尾,否则策略不生效,es指定所以的别名写入
Elasticsearch7.X ILM索引生命周期管理(冷热分离)的更多相关文章
- Elasticsearch 索引生命周期管理 ILM 实战指南
文章转载自:https://mp.weixin.qq.com/s/7VQd5sKt_PH56PFnCrUOHQ 1.什么是索引生命周期 在基于日志.指标.实时时间序列的大型系统中,集群的索引也具备类似 ...
- Logstash & 索引生命周期管理(ILM)
Grok语法 Grok是通过模式匹配的方式来识别日志中的数据,可以把Grok插件简单理解为升级版本的正则表达式.它拥有更多的模式,默认,Logstash拥有120个模式.如果这些模式不满足我们解析日志 ...
- Elastic 使用索引生命周期管理实现热温冷架构
Elastic: 使用索引生命周期管理实现热温冷架构 索引生命周期管理 (ILM) 是在 Elasticsearch 6.6(公测版)首次引入并在 6.7 版正式推出的一项功能.ILM 是 Elast ...
- ElasticSearch——索引生命周期管理
从ES6.6开始,Elasticsearch提供索引生命周期管理功能,索引生命周期管理可以通过API或者kibana界面配置,详情参考[index-lifecycle-management] 本文仅通 ...
- 这么简单的ES索引生命周期管理,不了解一下吗~
对于日志或指标(metric)类时序性强的ES索引,因为数据量大,并且写入和查询大多都是近期时间内的数据.我们可以采用hot-warm-cold架构将索引数据切分成hot/warm/cold的索引.h ...
- Elasticsearch索引生命周期管理方案
一.前言 在 Elasticsearch 的日常中,有很多如存储 系统日志.行为数据等方面的应用场景,这些场景的特点是数据量非常大,并且随着时间的增长 索引 的数量也会持续增长,然而这些场景基本上只有 ...
- Elasticsearch索引生命周期管理探索
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484130&idx=1&sn=454f199 ...
- ES 7.13版本设置索引模板和索引生命周期管理
第一步:索引管理中查看都有哪些索引文件,然后添加索引模式(后面的日期用*表示) 第二步:索引生命周期管理 自带的有一个log,就使用这个,不用再新建了,根据需求修改里面的配置就行了 第三步:添加索引模 ...
- ELK 索引生命周期管理
kibana 索引配置 管理索引 点击设置 --- Elasticsearch 的 Index management 可以查看 elk 生成的所有索引 (设置,Elasticsearch ,管理) 配 ...
随机推荐
- 微信小程序-返回并更新上一页面的数据
小程序开发过程中经常有这种需求,需要把当前页面数据传递给上一个页面,但是wx.navigateBack()无法传递数据. 一般的办法是把当前页面数据放入本地缓存,上一个页面再从缓存中取出. 除此之外还 ...
- IDEA SonarLint安装及使用
SonarLint插件安装IDEA菜单栏选择File->Settings,左边栏选择Plugins 在线安装选择Browse repositories,搜索Sonar,选择SonarLint进行 ...
- JavaWeb网上图书商城完整项目--发送邮件
1.首先注册一个163邮箱 自己的邮箱地址是18780279472@163.com 登陆的密码是key@wy111***19 使用邮箱发邮件,邮件必须开启pop和smtp服务,登陆邮件 开启pop服务 ...
- 如何用Tesseract做日文OCR(c#实现)
首先做一下背景介绍,Tesseract是一个开源的OCR组件,主要针对的是打印体的文字识别,对手写的文字识别能力较差,支持多国语言(中文.英文.日文.韩文等).是开源世界里最强的一款OCR组件.当然和 ...
- 入门大数据---Flume 简介及基本使用
一.Flume简介 Apache Flume 是一个分布式,高可用的数据收集系统.它可以从不同的数据源收集数据,经过聚合后发送到存储系统中,通常用于日志数据的收集.Flume 分为 NG 和 OG ( ...
- SpringBoot--使用redis实现分布式限流
1.引入依赖 <!-- 默认就内嵌了Tomcat 容器,如需要更换容器也极其简单--> <dependency> <groupId>org.springframew ...
- SpringBoot--数据库管理与迁移(LiquiBase)
随着开发时间积累,一个项目会越来越大,同时表结构也越来越多,管理起来比较复杂,特别是当想要把一个答的项目拆分成多个小项目时,表结构拆分会耗很大的精力:如果使用LiquiBase对数据库进行管理,那么就 ...
- DOM-BOM-EVENT(1)
1.DOM简介 DOM(Document Object Model)即文档对象模型,是HTML和XML文档的编程接口.它提供了对文档的结构化的表述,并定义了一种方式可以使得从程序中对该结构进行访问,从 ...
- 实现MFC扩展DLL中导出类和对话框
如果要编写模块化的软件,就要对对动态链接库(DLL)有一定的了解,本人这段时间在修改以前的软件时,决定把重复用的类和对话框做到DLL中,下面就从一个简单的例子讲起,如何实现MFC扩展DLL中导出类和对 ...
- C#客户端通过安全凭证调用webservice
怎么解决给XML Web services 客户端加上安全凭据,从而实现调用安全的远程web方法?首先,有远程web服务Service继承自System.Web.Services.Protocols. ...