2.2 Python3基础-基本数据类型
>>返回主目录


源代码
# 基本数据类型
# Number类型:如何查看变量的数据类型?
name = 'Portos'
print(type(name)) # 结果:str
print(isinstance(name, str)) # 结果:str
# 如何转换数据类型?
score = 99.5 # 浮点型转换成整型和字符型
score_int = int(score)
score_str = str(score)
# 字符串可以转换成数字类型么?反之呢?
# 纯字符串的数字可以转换成数字类型,反之,数字类型可以转换成字符串
# 数字类型间的运算
score_1 = 88.6
score_2 = 99.5
score_total = score_1 + score_2
print(score_total) # 结果:188.1
源代码
# String类型
'''
字符串的截取的语法格式如下:
变量[头下标:尾下标:间隔值]
索引值以 0 为开始值,-1 为从末尾的开始位置
'''
str_1 = 'I Love Python'
print(str_1) # 输出字符串
print(str_1[0:-1]) # 输出第一个到倒数第二个的所有字符
print(str_1[0]) # 输出字符串第一个字符
print(str_1[2:5]) # 输出从第三个开始到第五个的字符
print(str_1[2:]) # 输出从第三个开始的后的所有字符
print(str_1[-1]) # 输出最后一位
print(str_1[:]) # 输出全部字符串
print(str_1[::2]) # 每隔2个字符输出字符串
print(str_1[::-1]) # 倒序输出字符串
print(str_1 * 2) # 输出字符串两次,也可以写成:print(2 * str_1)
print(str_1 + "TEST") # 连接字符串
源代码
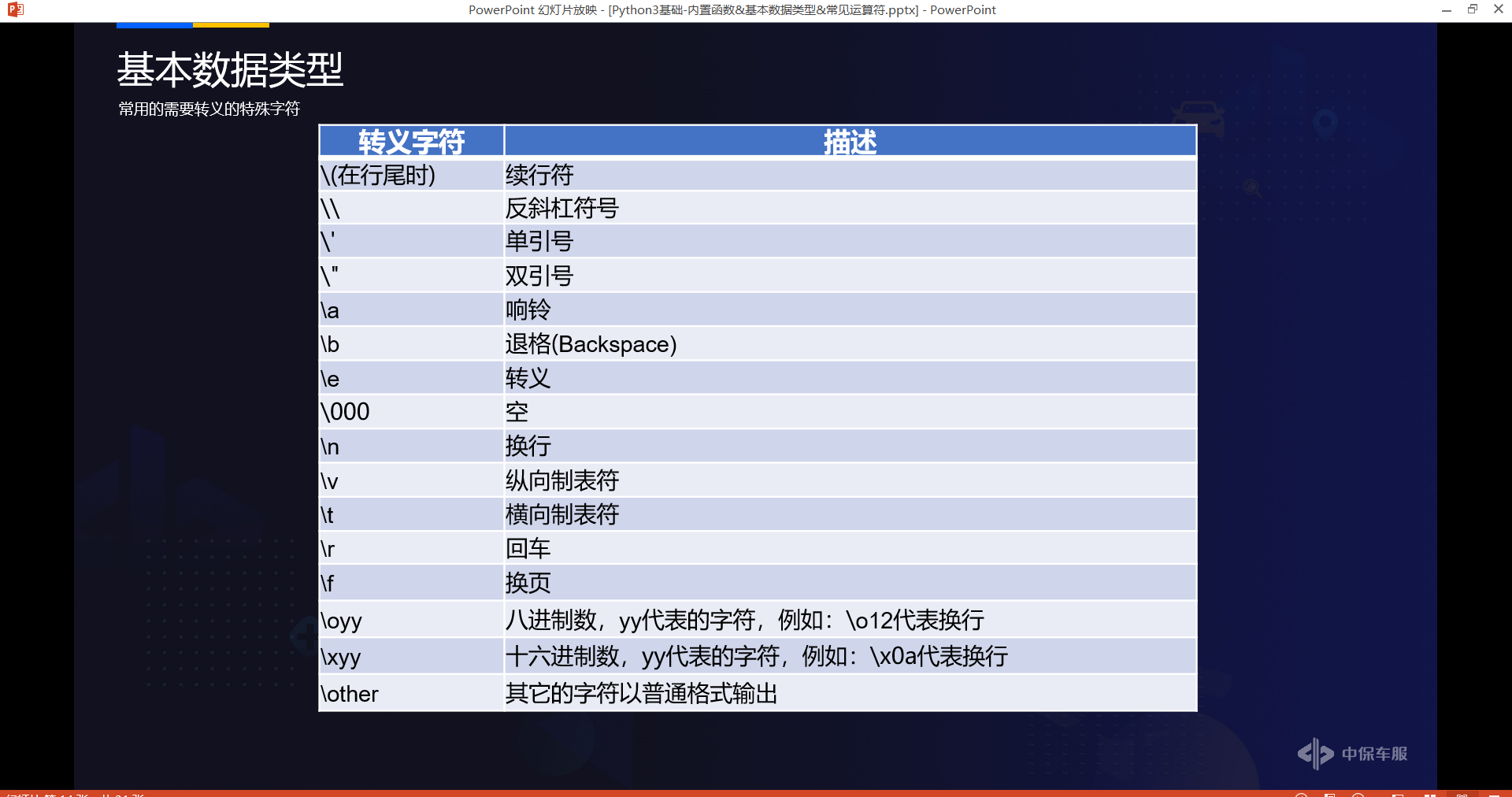
# 转义字符:\
# Python 使用反斜杠 \ 转义特殊字符,如果你不想让反斜杠发生转义,可以在字符串前面添加一个 r,表示原始字符串:如:
print('Pytho\n') # 转义
print(r'Pytho\n') # 没有转义
print('I say I love "Python"') # 双引号显示
print('I say I love \'Python\'') # 转义单引号
# 反斜杠(\)可以作为续行符,表示下一行是上一行的延续
print('I say I love \
Python') # 结果:I say I love Python

源代码
# list列表
"""
列表的截取的语法格式如下:
变量[头下标:尾下标:间隔值]
索引值以 0 为开始值,-1 为从末尾的开始位置
"""
list_1 = ['a', 678, 2.23, ['b', 70.2]]
list_2 = [22, 'b']
print(list_1) # 输出列表
print(list_1[0:-1]) # 输出第一个到倒数第二个的所有元素
print(list_1[0]) # 输出字符串第一个元素
print(list_1[1:3]) # 输出从第二个开始到第三个的元素
print(list_1[2:]) # 输出从第三个开始的后的所有元素
print(list_1[-1]) # 输出最后一位元素
print(list_1[:]) # 输出全部列表元素
print(list_1[::2]) # 每隔2个元素输出列表元素
print(list_1[::-1]) # 倒序输出列表,亦可list_1.reverse()
print(list_1 * 2) # 输出列表两次,也可以写成:print(2 * list_1)
print(list_1 + list_2) # 连接列表
源代码
# list内置函数,例如:
list_1 = ['a', 678, 2.23, ['b', 70.2]]
list_2 = ['c', 'd']
# 列表添加元素:append()
list_1.append('c') # 在list_1末尾追加元素c
list_1.append(list_2)
# 列表插入元素:insert()
list_1.insert(2, 'f') # 在第二个元素678后面,插入元素f
# 列表更新元素:下标0,表示第一个元素a,更新成e
list_1[0] = 'e'
# 列表删除元素:remove()
list_1.remove(678)
# 列表返回索引位置,从0开始数:index()
list_1.index(2.23)
# 列表排序:sort(),默认会按一定顺序从小到大,排序元素的类型要统一
list_2.sort()
print(list_2) # 结果:['c', 'd']
源代码
"""
Author:PortosHan
Datetime:2021/3/5 15:19
Project:zbcf_python_lesson_project
"""
str_1 = 'I Love Python'
list_1 = ['1', '2', 'c', 'd']
# 字符串转换成列表
print(list(str_1)) # 结果:['I', ' ', 'L', 'o', 'v', 'e', ' ', 'P', 'y', 't', 'h', 'o', 'n']
# 字符串以空格为分隔符,转换成列表:split()分割函数,默认返回列表
print(str_1.split(' ')) # 结果:['I', 'Love', 'Python']
# 列表转换成字符串:join()连接函数,默认返回字符串
print(''.join(str_1))
# 列表转换成字符串,且以空格隔开
print(' '.join(str_1)) # ' '号里面就是连接符
# 如何知道字符串|列表的其他内置方法:.出来的
# 在PyCharm里通过,str.内置方法,list.内置方法

源代码
# 虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表
tup0 = (3, 22, ['a', 'b'])
print(id(tup0)) # 结果:1907682610112
tup0[2][0] = 'c'
print('New tup0 is:', tup0, ';and id is:', id(tup0)) # 结果:New tup0 is: (3, 22, ['c', 'b']) ;and id is: 1907682610112
# 构造包含 0 个或 1 个元素的元组比较特殊,所以有一些额外的语法规则:
tup1 = () # 空元组
tup2 = (20,) # 一个元素,需要在元素后添加逗号
# 元组也可以使用+操作符进行拼接
tup3 = (3, 55)
print(tup1 + tup2 + tup3) # 结果:(20, 3, 55)
源代码
set_1 = {'Google', 'Taobao', 'Facebook', 'Taobao', 'Baidu'}
set_2 = {'Baidu', 'CIAS', 'test'}
# 集合(set)是一个无序的不重复元素序列
print(set_1) # 结果去重且无序,结果:{'Facebook', 'Baidu', 'Taobao', 'Google'}
# 集合中的元素必须是不可变类型,且可以为不同类型
# 添加元素:add()
set_1.add('CIAS')
print(set_1) # 结果:{'Baidu', 'Facebook', 'Google', 'CIAS', 'Taobao'}
# 删除元素:remove()
set_1.remove('Facebook')
print(set_1) # 结果:{'CIAS', 'Taobao', 'Baidu', 'Google'}
# 添加多个元素:update()
set_1.update({'a', 'b'})
print(set_1) # 结果:{'CIAS', 'Taobao', 'Baidu', 'b', 'a', 'Google'}
# 集合支持:交、并、差、非等集合运算
# 交:set_1.intersection(set_2) # 或set_1 – set_2
set_all = set_1.intersection(set_2)
print(set_all) # 结果:{'CIAS', 'Baidu'}
# 并:set_1.union(set_2) # 或set_1 | set_2
set_all = set_1.union(set_2)
print(set_all) # 结果:{'Baidu', 'CIAS', 'Taobao', 'a', 'Google', 'test', 'b'}
# 差:set_1.difference(set_2) # 或set_1 & set_2
set_all = set_1.difference(set_2)
print(set_all) # 结果:{'a', 'Google', 'b', 'Taobao'}
# 非:set_1.symmetric_difference(set_2) # 或set_1 ^ set_2
set_all = set_1.symmetric_difference(set_2)
print(set_all) # 结果:{'test', 'a', 'Taobao', 'Google', 'b'}
# 判断元素是否在集合中存在:'Baidu' in set_1
print('Baidu' in set_1) # 结果:True
源代码
dic_1 = {'name': 'Portos', 'age': 18, 'sex': 'man'}
# 字典是另一种可变容器模型,且可存储任意类型对象
# 不允许同一个键出现两次,否则只记录最后一个同键的值
dic_2 = {'name': 'PortosHan', 'name': 'Portos'}
print(dic_2) # 结果:{'name': 'Portos'}
# 键必须是不可变元素
# 访问字典里的值,如:
print(dic_1['name']) # 结果:Portos
print(dic_1.get('name')) # 结果:Portos
# 添加元素:如:
dic_1['score'] = 99
dic_1.update({'a': 1})
print(dic_1) # 结果:{'name': 'Portos', 'age': 18, 'sex': 'man', 'score': 99, 'a': 1}
# 删除元素:
del(dic_1['name'])
dic_1.pop('age')
print(dic_1) # 结果:{'sex': 'man', 'score': 99, 'a': 1}
# 清空字典:dic_1.clear()
# 判断键是否在字典里:key in dict,如:'name' in dic_1
print('name' in dic_1) # 结果:False
>>返回主目录
2.2 Python3基础-基本数据类型的更多相关文章
- Python3基础之数据类型(字典)
Python3数据类型之 字典 字典是另一种可变容器模型,且可存储任意类型对象. 字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({} ...
- Python3基础之数据类型(字符串和列表)
1.Python字符串方法 1.1.如何在Python中使用字符串 a.使用单引号(') 用单引号括起来表示字符串,例如: str1="this is string"; print ...
- Python3基础语法和数据类型
Python3基础语法 编码 默认情况下,Python3源文件以UTF-8编码,所有字符串都是unicode字符串.当然你也可以为原码文件制定不同的编码: # -*- coding: 编码 -*- 标 ...
- python002 Python3 基础语法
python002 Python3 基础语法 编码默认情况下,Python 3 源码文件以 UTF-8 编码,所有字符串都是 unicode 字符串. 当然你也可以为源码文件指定不同的编码: # -* ...
- Python3基础(十二) 学习总结·附PDF
Python是一门强大的解释型.面向对象的高级程序设计语言,它优雅.简单.可移植.易扩展,可用于桌面应用.系统编程.数据库编程.网络编程.web开发.图像处理.人工智能.数学应用.文本处理等等. 在学 ...
- Python3基础-目录
Python3基础-目录(Tips:长期更新Python3目录) 第一章 初识Python3 1.1 Python3基础-前言 1.2 Python3基础-规范 第二章 Python3内置函数&a ...
- C#基础--之数据类型
C#基础--之数据类型 摘自:http://www.cnblogs.com/tonney/archive/2011/03/18/1987577.html 在第一章我们了解了C#的输入.输出语句后,我这 ...
- page74-泛型可迭代的基础集合数据类型的API-Bag+Queue+Stack
[泛型可迭代的基础集合数据类型的API] 背包:就是一种不支持从中删除元素的集合数据类型——它的目的就是帮助用例收集元素并迭代遍历所有收集到的元素.(用例也可以检查背包是否为空, 或者获取背包中元素的 ...
- JavaScript基础:数据类型的中的那些少见多怪
原文:JavaScript基础:数据类型的中的那些少见多怪 Javascript共有6种数据类型,其中包括3个基本数据类型(string,number,boolean).2个特殊数据类型(undefi ...
随机推荐
- CF1466-D. 13th Labour of Heracles
CF1466-D. 13th Labour of Heracles 题意: 给出一个由\(n\)个点构成的树,每个点都有一个权值.现在你可以用\(k,k\subset\)\([1, n]\)个颜色来给 ...
- 排序算法 以及HKU的一些数据结构 相关题目 以及 K叉树,二叉树 排列
冒泡排序.选择排序.快速排序.插入排序.希尔排序.归并排序.基数排序以及堆排序,桶排序 https://www.cnblogs.com/Glory-D/p/7884525.html https://b ...
- Java中集合的有序问题
Java中的容器主要包括两方面: Collection:List.Set.queue Map:HashMap.treeMap: 一. Collection 1. Set TreeSet:基于红黑树实现 ...
- select函数详细用法解析
1.表头文件 #include #include #include 2.函数原型 int select(int n,fd_set * readfds,fd_set * writefds,fd_set ...
- codevs1169传纸条 不相交路径取最大,四维转三维DP
这个题一个耿直的思路肯定是先模拟.. 但是我们马上发现这是具有后效性的..也就是一个从(1,1)开始走,一个从(n,m)开始走的话 这样在相同的时间点我们就没法判断两个路径是否是相交的 于是在dp写挂 ...
- 常用SQL语句1-增删改查
一.名词解释 RDBMS 即关系数据库管理系统(Relational Database Management System)的特点: 1.数据以表格的形式出现 2.每行为各种记录名称 3.每列为记录名 ...
- Python errors All In One
Python errors All In One SyntaxError: invalid character in identifier \u200b, ZERO WIDTH SPACE https ...
- pure CSS3 实现三角形icon的方法
pure CSS3 实现三角形icon的方法 border: color+transparent transform : rotate() /rotateZ() ? 使用 实体字符"◆&qu ...
- node os env reader
node os env reader node-os-env-reader.js #!/usr/bin/env node "use strict"; /** * * @author ...
- window.ShadyCSS
window.ShadyCSS Web Components # install $ yarn add @webcomponents/shadycss@1.7.1 # OR $ npm i @webc ...