Phoneix(一)简介及常用命令
一、简介
Apache Phoneix是运行在HBase之上的高性能关系型数据库,通过Phoneix可以像使用jdbc访问关系型数据库一样访问HBase。
Phoneix操作的表以及数据存储在HBase上,phoneix只需要和HBase进行表关联。然后在用工具进行一些读写操作。
可以把Phoneix只看成一种代替HBase语法的工具。虽然Java可以用jdbc来连接phoneix操作,但是在生成环境找那个,不可以用OLTP。phoenix在查询hbase时,虽然做了一些优化,但是延迟还是不小。所以依然用在OLAT中,在将结果返回存储下来。
说明:
当今的数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果.
二、常用命令
1、登录phoneix shell
python sqlline.py master:2181
2、基本命令
查看table列表 !tables
查看表字段信息 !describe tablename
查看执行历史 !history
查看table 的索引 !index tablename
其他操作 help
3、插入数据
在Phoneix是没有Insert语句的,取而代之的是upsert 。
Upsert有两种用法:
1、upsert into旨在单条插入
upsert into tb values('ak','hhh',222)
upsert into tb(stat,city,num) values('ak','hhh',222)
2、upsert select旨在批量插入
upsert into tb1 (state,city,population) select state,city,population from tb2 where population < 40000;
upsert into tb1 select state,city,population from tb2 where population > 40000;
upsert into tb1 select * from tb2 where population > 40000;
注意:
在Phoenix在插入语句并不会像传统数据库一样存在重复数据,因为phoneix是构建在HBase之上的,也就是主键唯一。后面插入数据会覆盖前面的,但是时间戳不一样。
4、删除数据
delete from tb;
清空表中所有记录,Phoenix中不能使用truncate table tb;
delete from tb where city = 'kenai';
drop table tb;删除表
delete from system.catalog where table_name = 'int_s6a';
drop table if exists tb;
drop table my_schema.tb;
drop table my_schema.tb cascade;用于删除表的同时删除基于该表的所有视图。
5、更新数据
由于HBase的主键设计,相同rowkey的内容可以直接覆盖,这就变相的更新了数据。
所以Phoenix的更新操作仍旧是upsert into 和 upsert select
upsert into us_population (state,city,population) values('ak','juneau',40711);
6、查询数据
union all, group by, order by, limit 都支持
select * from test limit 1000;
select * from test limit 1000 offset 100;
select full_name from sales_person where ranking >= 5.0
union all select reviewer_name from customer_review where score >= 8.0
7、创建表
a、加盐(SALT_BUCKETS)
加盐Salting能够通过预分区(pre-splitting)数据到多个region中来显著提升读写性能。本质是在hbase中,rowkey的byte数组的第一个字节位置设定一个系统生成的byte值,这个byte值是由rowkey的byte数组做一个哈希算法,计算来的。
SALT_BUCKETS的值范围在(1-256):
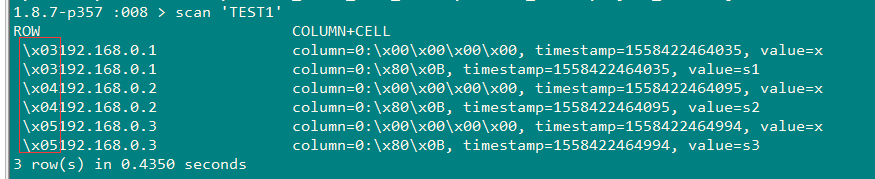
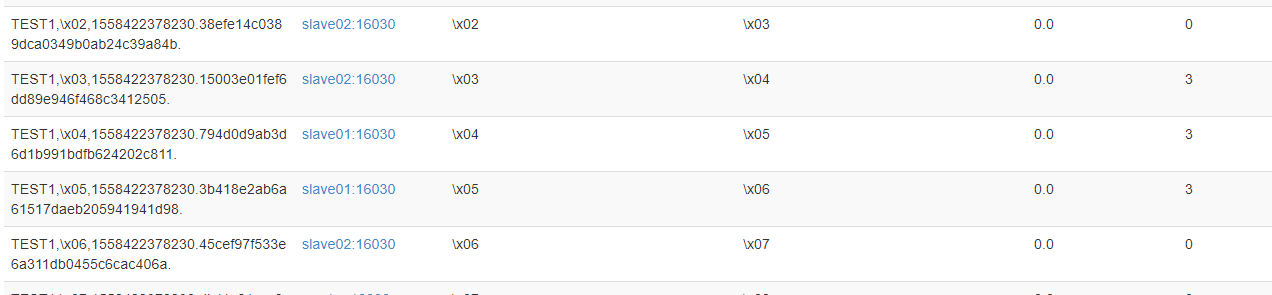
create table TEST1(host varchar not null primary key, description varchar)salt_buckets=16;
upsert into TEST1 (host,description) values ('192.168.0.1','s1');
upsert into TEST1 (host,description) values ('192.168.0.2','s2');
upsert into TEST1 (host,description) values ('192.168.0.3','s3');
salted table可以自动在每一个rowkey前面加上一个字节,这样对于一段连续的rowkeys,
它们在表中实际存储时,就被自动地分布到不同的region中去了。当指定要读写该段区间内的数据时,
也就避免了读写操作都集中在同一个region上。简而言之,如果我们用Phoenix创建了一个saltedtable,
那么向该表中写入数据时,原始的rowkey的前面会被自动地加上一个byte(不同的rowkey会被分配不同的byte),
使得连续的rowkeys也能被均匀地分布到多个regions。
结果:如图;
b、Pre-split(预分区)
Salting能够自动的设置表预分区,但是我们得控制表是如何分区的,所以在使用phoneix建表时,可以精确的指定要根据什么值来做预分区,如下实例:
create table TEST2 (host varchar not null primary key, description varchar) split on ('cs','eu','na');

c、使用多列簇
列簇包含相关的数据都在独立的文件中,在Phoneix设置多个列簇可以提高查询性能。
如下建表语句,创建了a,b两个列簇
create table TEST3 ( mykey varchar not null primary key, a.col1 varchar, a.col2 varchar, b.col3 varchar);
upsert into TEST3 values ('key1','a1','b1','c1');
upsert into TEST3 values ('key2','a2','b2','c2');

d、使用压缩
create table test (host varchar not null primary key, description varchar) compression='snappy';
8、创建视图,删除视图
create view "my_hbase_table"( k varchar primary key, "v" unsigned_long) default_column_family='a';
create view my_view ( new_col smallint ) as select * from my_table where k = 100;
create view my_view_on_view as select * from my_view where new_col > 70;
create view v1 as select * from test where description in ('s1','s2','s3');
drop view my_view;
drop view if exists my_schema.my_view;
drop view if exists my_schema.my_view cascade;
9、创建索引
创建二级索引支持可变数据和不可变数据(数据插入后不再更新)上建立二级索引
create index my_idx on opportunity(last_updated_date desc);全局索引
create index my_idx on event(created_date desc) include (name, payload) salt_buckets=10;覆盖索引并加盐
create index my_idx on sales.opportunity(upper(contact_name));函数索引
create index test_index on test (host) include (description);覆盖索引
10、删除索引
drop index 索引名 on 表名;
11、默认是可变表,手动创建不可变表
create table hao2 (k varchar primary key, v varchar) immutable_rows=true;
alter table HAO2 set IMMUTABLE_ROWS = false; 修改为可变
alter index index1 on tb rebuild;索引重建是把索引表清空后重新装配数据。
12、Global Indexing多读少写,适合条件较少
CREATE INDEX IPINDEX ON TEST(IP);
调用方法:强制索引
SELECT /*+ INDEX(TEST IPINDEX) */ * FROM TEST WHERE IP='139.204.122.144';
13、覆盖索引 Covered Indexes,需要include包含需要返回数据结果的列
create index index1_c on hao1 (age) include(name); name已经被缓存在这张索引表里了。
对于select name from hao1 where age=2,查询效率和速度最快
select * from hao1 where age =2,其他列不在索引表内,会全表扫描
14、Local Indexing写多读少,不是索引字段索引表也会被使用,索引数据和真实数据存储在同一台机器上
CREATE LOCAL INDEX IPINDEX ON TEST(IP);
Phoneix(一)简介及常用命令的更多相关文章
- Git的原理简介和常用命令
Git和SVN是我们最常用的版本控制系(Version Control System, VCS),当然,除了这二者之外还有许多其他的VCS,例如早期的CVS等.顾名思义,版本控制系统主要就是控制.协调 ...
- Docker-Compose简介及常用命令
1.Docker-Compose简介 Docker-Compose项目是Docker官方的开源项目,负责实现对Docker容器集群的快速编排.Docker-Compose将所管理的容器分为三层,分别是 ...
- Nginx学习——简介及常用命令
Nginx简介 Nginx是什么 同Apache一样,都是一种WEB服务器 基于REST架构风格,以统一资源描述符(URI)或者统一资源定位符(URL)作为沟通依据,通过HTTP协议提供各种网络服务 ...
- adb 简介与常用命令
1. abd 简介 2. adb 常用命令 1. abd 简介 adb 的全称为 Android Debug Bridge,就是起到调试桥的作用. 借助 adb 工具,我们可以管理设备或手机模拟器的状 ...
- Linux文件系统简介及常用命令
在linux系统中一切皆是文件,下面简要总结了一下linux文件系统中分区类型.文件系统类型以及常用命令. 一.分区类型1.主分区:最多只能有四个2.扩展分区:只能有一个,也可以看做是主分区的一种.即 ...
- hadoop(十一)HDFS简介和常用命令介绍
HDFS背景 随着数据量的增大,在一个操作系统中内存不了了,就需要分配到操作系统的的管理磁盘中,但是不方便管理者维护,迫切需要一种系统来管理多态机器上的文件,这就是分布式文件管理系统. HDFS的概念 ...
- Linux简介及常用命令使用4--linux高级命令与技巧
top 几个磁盘fdisk -l 磁盘空间 df -lhdf -al 查看进程:ps -ef"grep java杀死进程:kill -9 进程号 more中过滤 more xxx |grep ...
- Gcc简介与常用命令
一.对于GUN编译器来说,程序的编译要经历预处理.编译.汇编.连接四个阶段,如下图所示: 在预处理阶段,输入的是C语言的源文件,通常为*.c.它们通常带有.h之类头文件的包含文件.这个阶段主要处理源文 ...
- Linux简介及常用命令使用5--linux shell编程入门
生成 测试数据的shell脚本 Vim data_create.sh rm -rf ./data.txttouch data.txtfor((i=0;i<2000;i++))dostr=',na ...
随机推荐
- APP非功能测试
1.移动APP启动时间测试 问题:如何获取启动时间? 答:通过adb的logcat来获取Activity启动时间.用户体验时间=Activity启动时间+启动中异步UI绘制的时间. 启动时间的测试主要 ...
- 中间件面试专题:kafka高频面试问题
- POJ1422
题目大意: 一个有向无环图,求最小路径覆盖 板子题... 把每个点拆成\(x\)和\(x^{'}\) \((u,v)\)有一条边则\(u\)向\(v^{'}\)连一条边,然后跑最大匹配,最小路径覆盖= ...
- Android Studio/IDEA插件
1.android parcelable code generator 2.android code generator3.gson format4.android postfix completio ...
- sql server的bcp指令
有时需要允许bcp指令 -- 允许配置高级选项EXEC sp_configure 'show advanced options', 1GO-- 重新配置RECONFIGUREGO-- 启用xp_cmd ...
- window启动mongoDB
windows启动mongo服务 建议使用docker,方便又快捷,可以查看我的其他文章有介绍 创建好日志文件夹后执行以下命令 mongod.exe --logpath "C:\mongod ...
- Day5 - 03 函数的参数-位置参数和默认参数
位置参数 调用函数时,传入函数的参数,按照位置顺序依次赋值给函数的参数.#计算乘方的函数 def power(x, n): s = 1 ...
- oracle ADG启动顺序
一.oracle ADG启动顺序 1.启动主备库监听 [oracle@dgdb1 ~]$ lsnrctl start [oracle@dgdb2 ~]$ lsnrctl start 2.启动备库 ...
- com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Specified key was too long; max key length is 767 bytes
hive 安装完成后创建表的时候出现错误 NestedThrowablesStackTrace:com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorExce ...
- do while 后面要加分号,你大爷的
do { //do something } while (0) TSfree(url); 这个TSFree 正好是个宏,然后编译就提示错误: error: expected ';' before '_ ...