神经网络结构:DenseNet
论文地址:密集连接的卷积神经网络
博客地址(转载请引用):https://www.cnblogs.com/LXP-Never/p/13289045.html
前言
在计算机视觉还是音频领域,卷积神经网络(CNN)已经成为最主流的方法,比如最近的GoogLenet,VGG-19,Incepetion、时序TCN等模型。CNN史上的一个里程碑事件是ResNet模型的出现,ResNet可以训练出更深的CNN模型,从而实现更高的准确度。ResNet模型的核心是通过建立前面层与后面层之间的“短路连接”(shortcuts,skip connection),这有助于训练过程中梯度的反向传播,从而能训练出更深的CNN网络。今天我们要介绍的是DenseNet模型,它的基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(dense connection),它的名称也是由此而来。DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用(feature reuse)。这些特点让DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能,DenseNet也因此斩获CVPR 2017的最佳论文奖。本篇文章首先介绍DenseNet的原理以及网路架构,然后讲解DenseNet的代码实现。
设计理念
相比ResNet,DenseNet提出了一个更激进的密集连接机制:即互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入。图1为ResNet网络的连接机制,作为对比,图2为DenseNet的密集连接机制。可以看到,ResNet是每个层与前面的某层(一般是2~3层)短路连接在一起,连接方式是通过元素级相加。而在DenseNet中,每个层都会与前面所有层在channel维度上连接(concat)在一起(这里各个层的特征图大小是相同的,后面会有说明),并作为下一层的输入。对于一个$L$层的网络,DenseNet共包含$\frac{L(L+1)}{2}$个连接,相比ResNet,这是一种密集连接。而且DenseNet是直接concat来自不同层的特征图,这可以实现特征重用,提升效率,这一特点是DenseNet与ResNet最主要的区别。
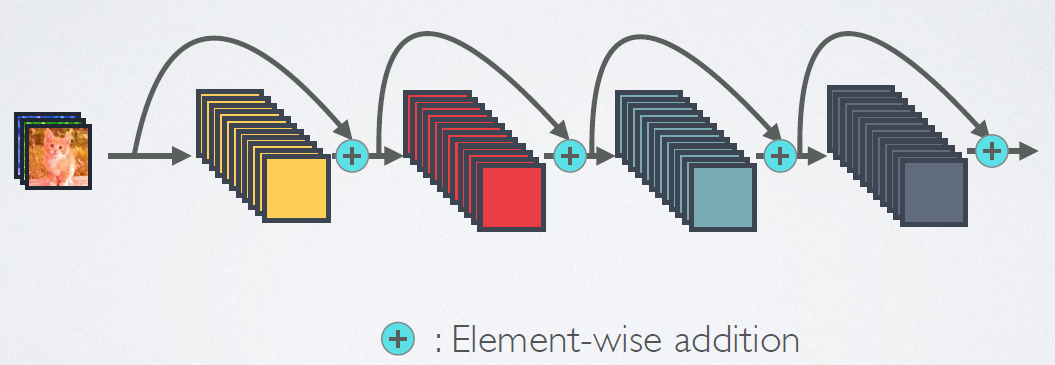
图1 ResNet网络的短路连接机制(其中+代表的是元素级相加操作)
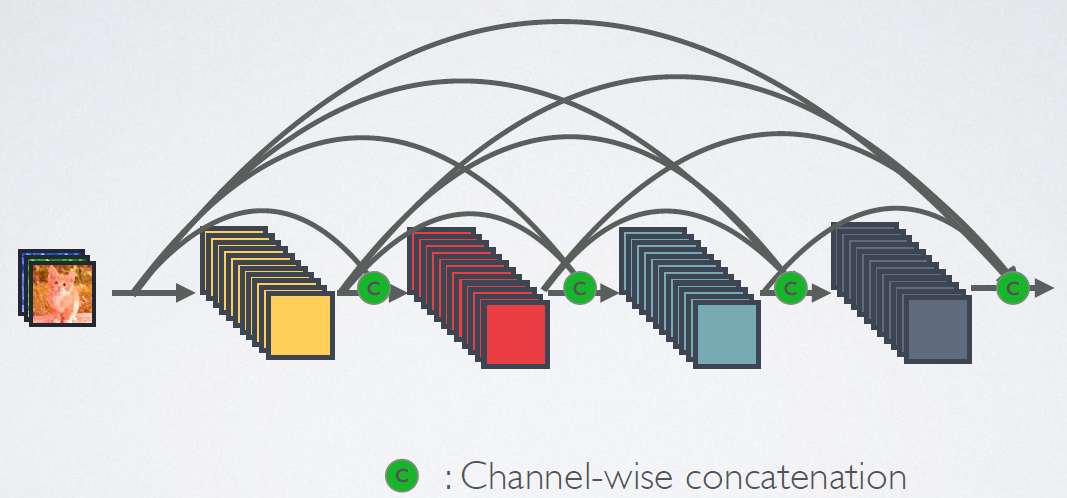
图2 DenseNet网络的密集连接机制(其中c代表的是channel级连接操作)
如果用公式表示的话,传统的网络在$l$层的输出为:
$$x_l = H_l(x_{l-1})$$
而对于ResNet,增加了来自上一层输入的identity函数:
$$x_l = H_l(x_{l-1}) + x_{l-1}$$
在DenseNet中,会连接前面所有层作为输入:
$$x_l = H_l([x_0, x_1, ..., x_{l-1}])$$
其中,上面的$H_l(\cdot)$代表是非线性转化函数(non-liear transformation),它是一个组合操作,其可能包括一系列的BN(Batch Normalization),ReLU,Pooling及Conv操作。注意这里$l$层与$l-1$层之间可能实际上包含多个卷积层。
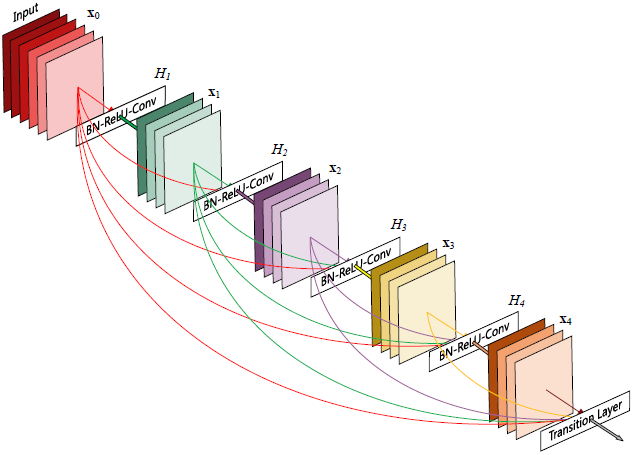
DenseNet的前向过程如图3所示,可以更直观地理解其密集连接方式,比如$h_3$的输入不仅包括来自$h_2$的$x_2$,还包括前面两层的$x_1$和$x_2$,它们是在channel维度上连接在一起的。

图3 DenseNet的前向过程
CNN网络一般要经过Pooling或者stride>1的Conv来降低特征图的大小,而DenseNet的密集连接方式需要特征图大小保持一致。为了解决这个问题,DenseNet网络中使用DenseBlock+Transition的结构,其中DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。而Transition模块是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低。图4给出了DenseNet的网路结构,它共包含4个DenseBlock,各个DenseBlock之间通过Transition连接在一起。

图4 使用DenseBlock+Transition的DenseNet网络
网络结构
如前所示,DenseNet的网络结构主要由DenseBlock和Transition组成,如图5所示。下面具体介绍网络的具体实现细节。

图6 DenseNet的网络结构
在DenseBlock中,各个层的特征图大小一致,可以在channel维度上连接。DenseBlock中的非线性组合函数$H(\cdot)$采用的是BN+ReLU+3x3 Conv的结构,如图6所示。另外值得注意的一点是,与ResNet不同,所有DenseBlock中各个层卷积之后均输出$k$个特征图,即得到的特征图的channel数为$k$,或者说采用$k$个卷积核。$k$在DenseNet称为growth rate,这是一个超参数。一般情况下使用较小的$k$(比如12),就可以得到较佳的性能。假定输入层的特征图的channel数为$k$,那么$l$层输入的channel数为$k_0+k(l-1)$,因此随着层数增加,尽管$k$设定得较小,DenseBlock的输入会非常多,不过这是由于特征重用所造成的,每个层仅有$k$个特征是自己独有的。
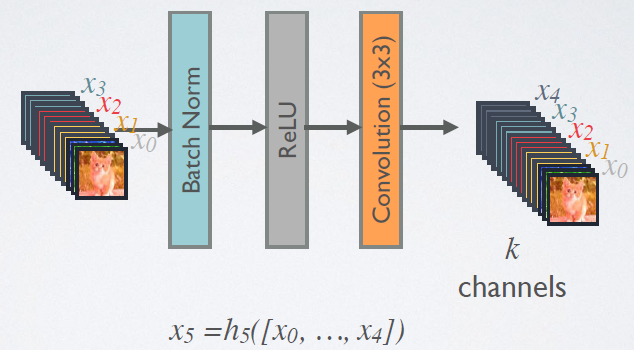
图6 DenseBlock中的非线性转换结构
由于后面层的输入会非常大,DenseBlock内部可以采用bottleneck层来减少计算量,主要是原有的结构中增加1x1 Conv,如图7所示,即BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv,称为DenseNet-B结构。其中1x1 Conv得到$4k$个特征图它起到的作用是降低特征数量,从而提升计算效率。
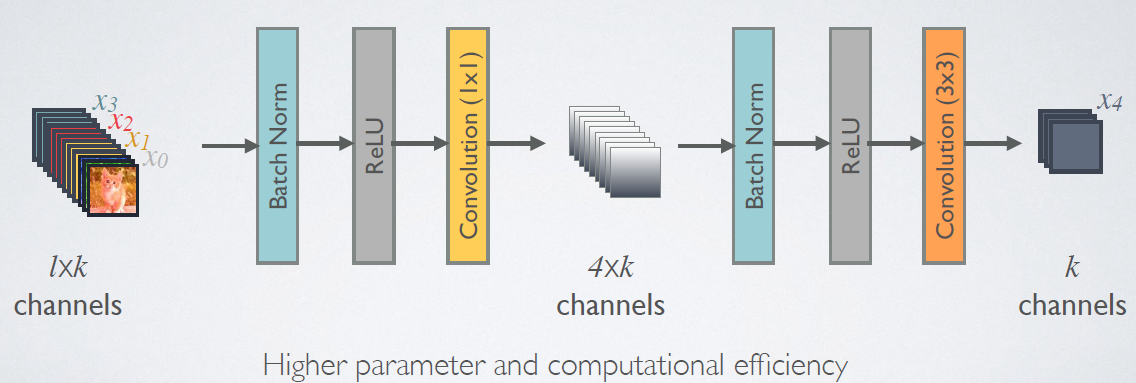
图7 使用bottleneck层的DenseBlock结构
对于Transition层,它主要是连接两个相邻的DenseBlock,并且降低特征图大小。Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为BN+ReLU+1x1 Conv+2x2 AvgPooling。另外,Transition层可以起到压缩模型的作用。假定Transition的上接DenseBlock得到的特征图channels数为$m$,Transition层可以产生$\lfloor\theta m\rfloor$个特征(通过卷积层),其中$\theta \in (0,1]$是压缩系数(compression rate)。当$\theta =1$时,特征个数经过Transition层没有变化,即无压缩,而当压缩系数小于1时,这种结构称为DenseNet-C,文中使用$\theta =0.5$。对于使用bottleneck层的DenseBlock结构和压缩系数小于1的Transition组合结构称为DenseNet-BC。
DenseNet共在三个图像分类数据集(CIFAR,SVHN和ImageNet)上进行测试。对于前两个数据集,其输入图片大小为$32*32$,所使用的DenseNet在进入第一个DenseBlock之前,首先进行进行一次3x3卷积(stride=1),卷积核数为16(对于DenseNet-BC为$2k$)。DenseNet共包含三个DenseBlock,各个模块的特征图大小分别为$32*32$,$16*16$和$8*8$,每个DenseBlock里面的层数相同。最后的DenseBlock之后是一个global AvgPooling层,然后送入一个softmax分类器。注意,在DenseNet中,所有的3x3卷积均采用padding=1的方式以保证特征图大小维持不变。对于基本的DenseNet,使用如下三种网络配置:$\{L=40, k=12\}$, $\{L=100, k=12\}$, $\{L=40, k=24\}$。而对于DenseNet-BC结构,使用如下三种网络配置:$\{L=100, k=12\}$, $\{L=250, k=24\}$, $\{L=190, k=40\}$。这里的$L$指的是网络总层数(网络深度),一般情况下,我们只把带有训练参数的层算入其中,而像Pooling这样的无参数层不纳入统计中,此外BN层尽管包含参数但是也不单独统计,而是可以计入它所附属的卷积层。对于普通$\{L=40, k=12\}$的网络,除去第一个卷积层、2个Transition中卷积层以及最后的Linear层,共剩余36层,均分到三个DenseBlock可知每个DenseBlock包含12层。其它的网络配置同样可以算出各个DenseBlock所含层数。
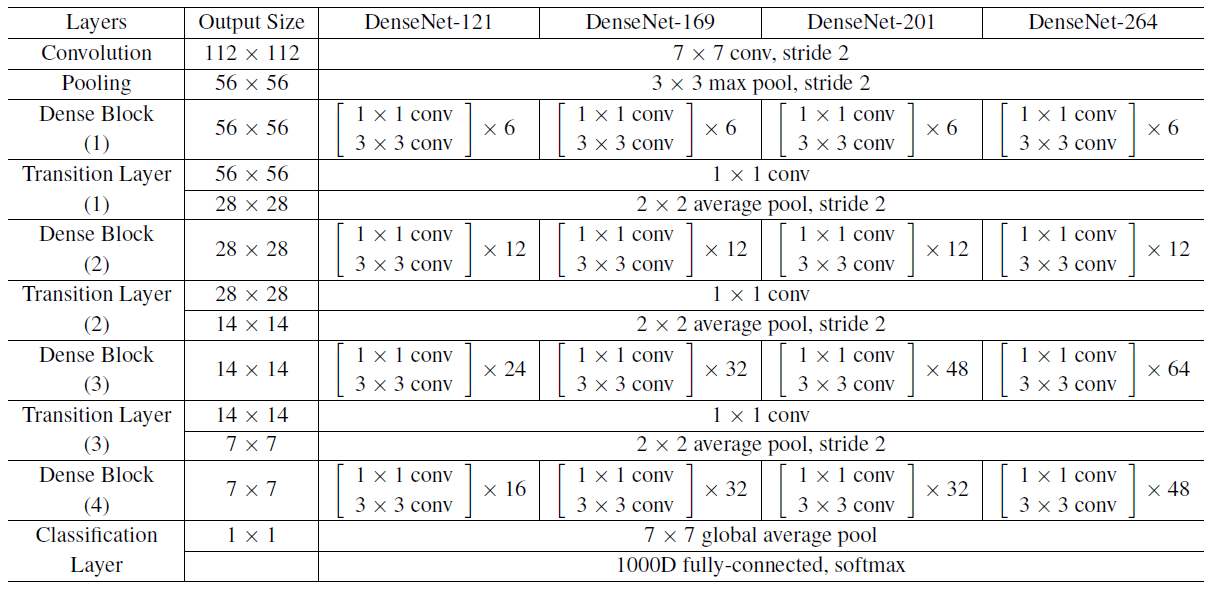
对于ImageNet数据集,图片输入大小为$224*224$,网络结构采用包含4个DenseBlock的DenseNet-BC,其首先是一个stride=2的7x7卷积层(卷积核数为$2k$),然后是一个stride=2的3x3 MaxPooling层,后面才进入DenseBlock。ImageNet数据集所采用的网络配置如表1所示:
表1 ImageNet数据集上所采用的DenseNet结构
实验结果及讨论
这里给出DenseNet在CIFAR-100和ImageNet数据集上与ResNet的对比结果,如图8和9所示。从图8中可以看到,只有0.8M的DenseNet-100性能已经超越ResNet-1001,并且后者参数大小为10.2M。而从图9中可以看出,同等参数大小时,DenseNet也优于ResNet网络。其它实验结果见原论文。
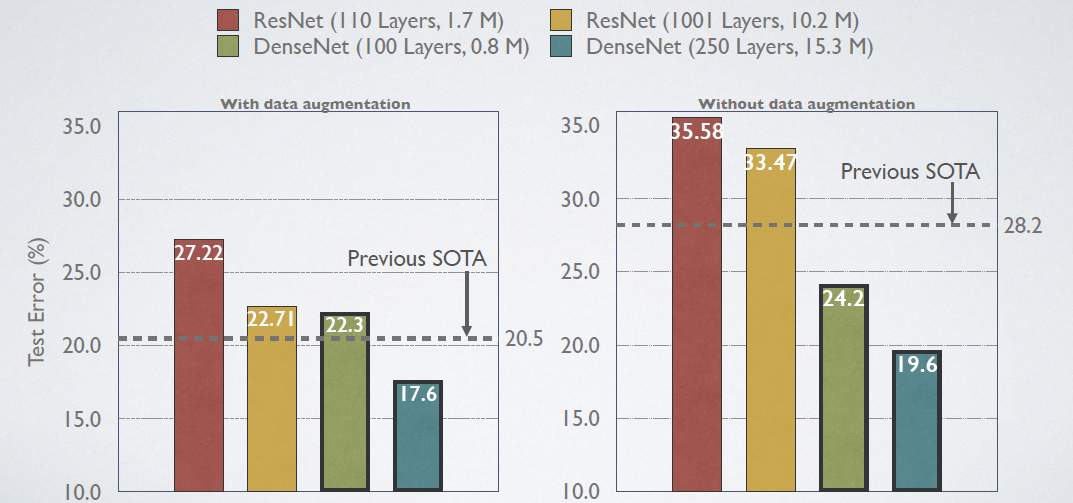
图8 在CIFAR-100数据集上ResNet vs DenseNet
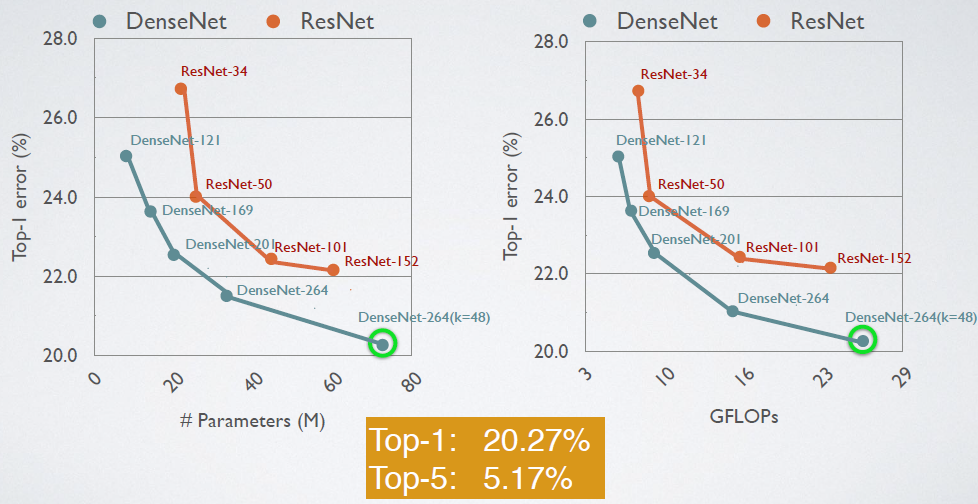
图9 在ImageNet数据集上ResNet vs DenseNet
综合来看,DenseNet的优势主要体现在以下几个方面:
- 由于密集连接方式,DenseNet提升了梯度的反向传播,使得网络更容易训练。由于每层可以直达最后的误差信号,实现了隐式的“deep supervision”;
- 参数更小且计算更高效,这有点违反直觉,由于DenseNet是通过concat特征来实现短路连接,实现了特征重用,并且采用较小的growth rate,每个层所独有的特征图是比较小的;
- 由于特征复用,最后的分类器使用了低级特征。
要注意的一点是,如果实现方式不当的话,DenseNet可能耗费很多GPU显存,一种高效的实现如图10所示,更多细节可以见这篇论文Memory-Efficient Implementation of DenseNets。不过我们下面使用Pytorch框架可以自动实现这种优化。
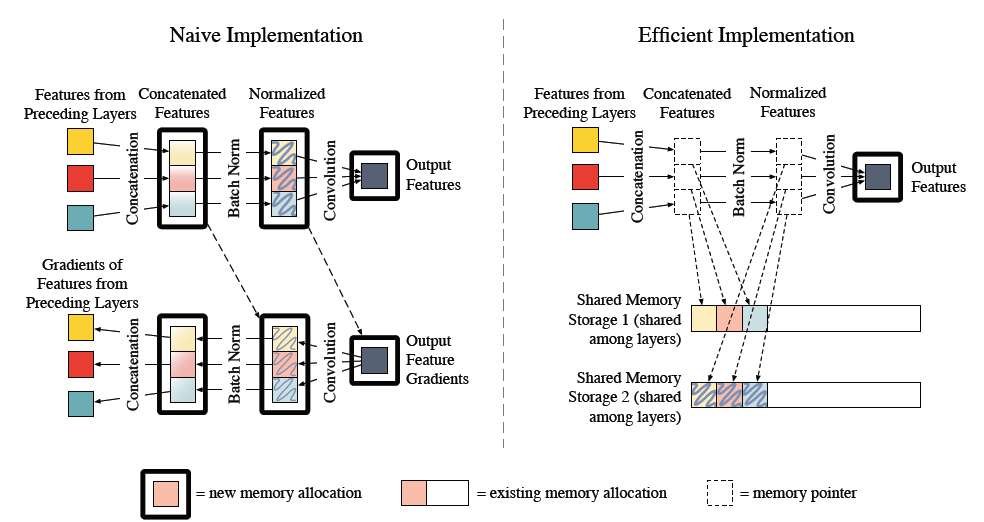
图10 DenseNet的更高效实现方式
使用Pytorch实现DenseNet
这里我们采用Pytorch框架来实现DenseNet,目前它已经支持Windows系统。对于DenseNet,Pytorch在torchvision.models模块里给出了官方实现,这个DenseNet版本是用于ImageNet数据集的DenseNet-BC模型,下面简单介绍实现过程
首先实现DenseBlock中的内部结构,这里是BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv结构,最后也加入dropout层以用于训练过程。
class _DenseLayer(nn.Sequential):
"""Basic unit of DenseBlock (using bottleneck layer) """
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(_DenseLayer, self).__init__()
self.add_module("norm1", nn.BatchNorm2d(num_input_features))
self.add_module("relu1", nn.ReLU(inplace=True))
self.add_module("conv1", nn.Conv2d(num_input_features, bn_size*growth_rate,
kernel_size=1, stride=1, bias=False))
self.add_module("norm2", nn.BatchNorm2d(bn_size*growth_rate))
self.add_module("relu2", nn.ReLU(inplace=True))
self.add_module("conv2", nn.Conv2d(bn_size*growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False))
self.drop_rate = drop_rate def forward(self, x):
new_features = super(_DenseLayer, self).forward(x)
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return torch.cat([x, new_features], 1)
据此,实现DenseBlock模块,内部是密集连接方式(输入特征数线性增长):
class _DenseBlock(nn.Sequential):
"""DenseBlock"""
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(num_input_features+i*growth_rate, growth_rate, bn_size,
drop_rate)
self.add_module("denselayer%d" % (i+1,), layer)
此外,我们实现Transition层,它主要是一个卷积层和一个池化层:
class _Transition(nn.Sequential):
"""Transition layer between two adjacent DenseBlock"""
def __init__(self, num_input_feature, num_output_features):
super(_Transition, self).__init__()
self.add_module("norm", nn.BatchNorm2d(num_input_feature))
self.add_module("relu", nn.ReLU(inplace=True))
self.add_module("conv", nn.Conv2d(num_input_feature, num_output_features,
kernel_size=1, stride=1, bias=False))
self.add_module("pool", nn.AvgPool2d(2, stride=2))
最后我们实现DenseNet网络:
class DenseNet(nn.Module):
"DenseNet-BC model"
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64,
bn_size=4, compression_rate=0.5, drop_rate=0, num_classes=1000):
"""
:param growth_rate: (int) number of filters used in DenseLayer, `k` in the paper
:param block_config: (list of 4 ints) number of layers in each DenseBlock
:param num_init_features: (int) number of filters in the first Conv2d
:param bn_size: (int) the factor using in the bottleneck layer
:param compression_rate: (float) the compression rate used in Transition Layer
:param drop_rate: (float) the drop rate after each DenseLayer
:param num_classes: (int) number of classes for classification
"""
super(DenseNet, self).__init__()
# first Conv2d
self.features = nn.Sequential(OrderedDict([
("conv0", nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
("norm0", nn.BatchNorm2d(num_init_features)),
("relu0", nn.ReLU(inplace=True)),
("pool0", nn.MaxPool2d(3, stride=2, padding=1))
])) # DenseBlock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(num_layers, num_features, bn_size, growth_rate, drop_rate)
self.features.add_module("denseblock%d" % (i + 1), block)
num_features += num_layers*growth_rate
if i != len(block_config) - 1:
transition = _Transition(num_features, int(num_features*compression_rate))
self.features.add_module("transition%d" % (i + 1), transition)
num_features = int(num_features * compression_rate) # final bn+ReLU
self.features.add_module("norm5", nn.BatchNorm2d(num_features))
self.features.add_module("relu5", nn.ReLU(inplace=True)) # classification layer
self.classifier = nn.Linear(num_features, num_classes) # params initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0) def forward(self, x):
features = self.features(x)
out = F.avg_pool2d(features, 7, stride=1).view(features.size(0), -1)
out = self.classifier(out)
return out
选择不同网络参数,就可以实现不同深度的DenseNet,这里实现DenseNet-121网络,而且Pytorch提供了预训练好的网络参数:
def densenet121(pretrained=False, **kwargs):
"""DenseNet121"""
model = DenseNet(num_init_features=64, growth_rate=32, block_config=(6, 12, 24, 16),
**kwargs) if pretrained:
# '.'s are no longer allowed in module names, but pervious _DenseLayer
# has keys 'norm.1', 'relu.1', 'conv.1', 'norm.2', 'relu.2', 'conv.2'.
# They are also in the checkpoints in model_urls. This pattern is used
# to find such keys.
pattern = re.compile(
r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$')
state_dict = model_zoo.load_url(model_urls['densenet121'])
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
model.load_state_dict(state_dict)
return model
下面,我们使用预训练好的网络对图片进行测试,这里给出top-5预测值:
densenet = densenet121(pretrained=True)
densenet.eval() img = Image.open("./images/cat.jpg") trans_ops = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]) images = trans_ops(img).view(-1, 3, 224, 224)
outputs = densenet(images) _, predictions = outputs.topk(5, dim=1) labels = list(map(lambda s: s.strip(), open("./data/imagenet/synset_words.txt").readlines()))
for idx in predictions.numpy()[0]:
print("Predicted labels:", labels[idx])

给出的预测结果为:
Predicted labels: n02123159 tiger cat
Predicted labels: n02123045 tabby, tabby cat
Predicted labels: n02127052 lynx, catamount
Predicted labels: n02124075 Egyptian cat
Predicted labels: n02119789 kit fox, Vulpes macrotis
小结
这篇文章详细介绍了DenseNet的设计理念以及网络结构,并给出了如何使用Pytorch来实现。值得注意的是,DenseNet在ResNet基础上前进了一步,相比ResNet具有一定的优势,但是其却并没有像ResNet那么出名(吃显存问题?深度不能太大?)。期待未来有更好的网络模型出现吧!
参考文献
Densely Connected Convolutional Networks
神经网络结构:DenseNet的更多相关文章
- EAS:基于网络转换的神经网络结构搜索 | AAAI 2018
论文提出经济实惠且高效的神经网络结构搜索算法EAS,使用RL agent作为meta-controller,学习通过网络变换进行结构空间探索.从指定的网络开始,通过function-preservin ...
- 深度神经网络结构以及Pre-Training的理解
Logistic回归.传统多层神经网络 1.1 线性回归.线性神经网络.Logistic/Softmax回归 线性回归是用于数据拟合的常规手段,其任务是优化目标函数:$h(\theta )=\thet ...
- 神经网络结构在命名实体识别(NER)中的应用
神经网络结构在命名实体识别(NER)中的应用 近年来,基于神经网络的深度学习方法在自然语言处理领域已经取得了不少进展.作为NLP领域的基础任务-命名实体识别(Named Entity Recognit ...
- GoogLeNet 神经网络结构
GoogLeNet是2014年 ILSVRC 冠军模型,top-5 错误率 6.7% ,GoogLeNet做了更大胆的网络上的尝试而不像vgg继承了lenet以及alexnet的一些框架,该模型虽然有 ...
- Evolution of Image Classifiers,进化算法在神经网络结构搜索的首次尝试 | ICML 2017
论文提出使用进化算法来进行神经网络结构搜索,整体搜索逻辑十分简单,结合权重继承,搜索速度很快,从实验结果来看,搜索的网络准确率挺不错的.由于论文是个比较早期的想法,所以可以有很大的改进空间,后面的很大 ...
- CARS: 华为提出基于进化算法和权值共享的神经网络结构搜索,CIFAR-10上仅需单卡半天 | CVPR 2020
为了优化进化算法在神经网络结构搜索时候选网络训练过长的问题,参考ENAS和NSGA-III,论文提出连续进化结构搜索方法(continuous evolution architecture searc ...
- AlexNet神经网络结构
Alexnet是2014年Imagenet竞赛的冠军模型,准确率达到了57.1%, top-5识别率达到80.2%. AlexNet包含5个卷积层和3个全连接层,模型示意图: 精简版结构: conv1 ...
- CNN 卷积神经网络结构
cnn每一层会输出多个feature map, 每个Feature Map通过一种卷积滤波器提取输入的一种特征,每个feature map由多个神经元组成,假如某个feature map的shape是 ...
- 经典卷积神经网络结构——LeNet-5、AlexNet、VGG-16
经典卷积神经网络的结构一般满足如下表达式: 输出层 -> (卷积层+ -> 池化层?)+ -> 全连接层+ 上述公式中,“+”表示一个或者多个,“?”表示一个或者零个,如“卷积层+ ...
随机推荐
- 青蛙的约会 (ax+by=c求最小整数解)【拓展欧几里得】
青蛙的约会(点击跳转) 两只青蛙在网上相识了,它们聊得很开心,于是觉得很有必要见一面.它们很高兴地发现它们住 ...
- SpringMVC的url-pattern配置及原理剖析
SpringMVC的url-pattern配置及原理剖析 xml里面配置标签: <!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc./ ...
- python_lesson1 数学与随机数 (math包,random包)
math包 math包主要处理数学相关的运算.math包定义了两个常数: math.e # 自然常数e math.pi # 圆周率pi 此外,math包还有各种运算函数 (下面函数的功能可以 ...
- Elasticsearch系列---生产集群的索引管理
概要 索引是我们使用Elasticsearch里最频繁的部分日常的操作都与索引有关,本篇从运维人员的视角,来玩一玩Elasticsearch的索引操作. 基本操作 在运维童鞋的视角里,索引的日常操作除 ...
- 从零开始学习Prometheus监控报警系统
Prometheus简介 Prometheus是一个开源的监控报警系统,它最初由SoundCloud开发. 2016年,Prometheus被纳入了由谷歌发起的Linux基金会旗下的云原生基金会( C ...
- localStorage. sessionStorage、 Cookie不共同点:(面试题)
●存储大小的不同: localStorage的大小一般为5M sessionStorage的大小一般为5M cookies的大小一般为4K ●有效期不同: 1.localStorage的有效期为永久有 ...
- PHP利用FTP上传文件连接超时之开启被动模式解决方法
初始代码: <?php $conn = ftp_connect("localhost") or die("Could not connect"); ftp ...
- spring框架中JDK和CGLIB动态代理区别
转载:https://blog.csdn.net/yhl_jxy/article/details/80635012 前言JDK动态代理实现原理(jdk8):https://blog.csdn.net/ ...
- 入门大数据---Hive常用DML操作
Hive 常用DML操作 一.加载文件数据到表 1.1 语法 LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename ...
- openstack迁移计算节点所有云主机
迁移计算节点所有云主机 -------高德置地 王锦雄 使用host-evacuate-live热迁移主机 查看主机目前的云主机情况 nova hypervisor-servers cloud1 ...