kafka笔记——入门介绍
- kafka的优势
- 首先几个概念
- kafka的四大核心API
- kafka的基本术语
- 主题和日志(Topic和Log)
- 每个分区都是一个顺序的,不可变的队列,并且可以持续的添加,分区中的每个消息都被分配了一个偏移量(offset),相当于下标,在每个分区中这个偏移量都是唯一的
- kafka集群的图示
- kafka集群的主分区和备份
- pritition如何持久化数据
- 消费者组
- 分布式(Distribution)
- Geo-Replication(异地数据同步技术)
- 生产者(Producers)
- 消费者(Consumers)
- kafka的保证
- kafka作为一个消息队列
- kafka作为一个存储系统
- kafka的流处理
kafka的优势
- 构建实时的流数据管道,可靠的获取系统和应用程序之间产生的数据
- 构建实时流的应用程序,对数据流进行转换或者反应
首先几个概念
- kafka作为一个集群运行在一个或者多个服务器上
- kafka集群存储的消息是以topic为类别记录的
- 每个消息是以key,value,时间戳组成
kafka的四大核心API
- Producer API:应用程序使用这个API发布消息到一个或者多个topic中
- Consumer API:应用程序使用这个API订阅一个或者多个topic,并处理产生的数据
- Stream API:应用程序使用这个API充当一个流处理器,从一个或者多个topic消费输入流,并生产一个输出流到一个或者多个输出topic,将输入流转化成输出流
- Connector API:可构建或运行可重用的生产者或者消费者,将topic连接到现有的应用程序或数据系统,例如连接到关系数据库的连接器可以捕获表的每个变更
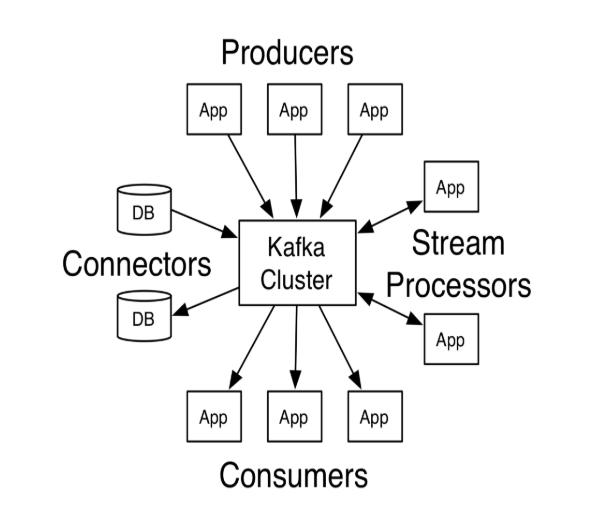
Client和Service之间通过一条简单的,高性能的并且和开发环境无关的TCP协议进行通信,kafka提供了Java Client(客户端),此外还有其他语言的客户端
kafka的基本术语
- Topic
kafka将消息分类,每个类叫做一个主题(Topic)
- Producer
发布消息的对象称为消息生产者(Producer)
- Consumer
订阅消息并处理消息的对象称为消息消费者(Consumer)
- Broker
已发布的消息保存在一组服务器中,这个服务器称为kafka集群,集群中的每个服务器都是一个代理(Broker),消费者可以订阅一个或者多个主题,并从Broker中拉取数据,从而消费这些消息。
主题和日志(Topic和Log)
Topic是发布消息的类别名,对于每个topic,kafka会维护一个分区log,每个分区log中有多个分区(partition),
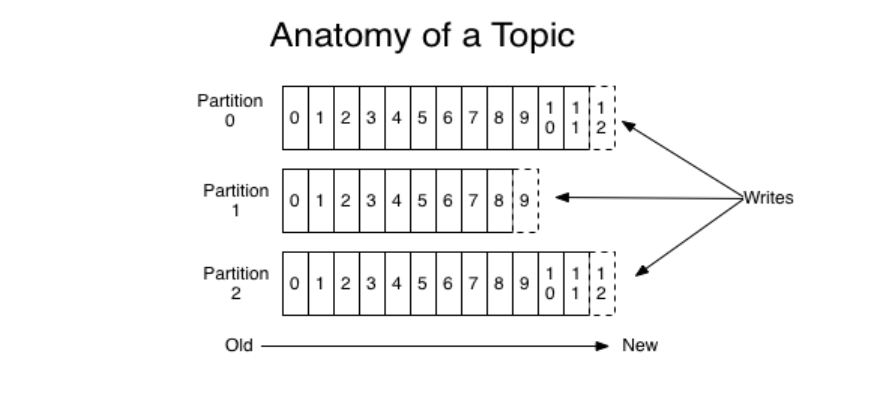
每个分区都是一个顺序的,不可变的队列,并且可以持续的添加,分区中的每个消息都被分配了一个偏移量(offset),相当于下标,在每个分区中这个偏移量都是唯一的
kafka集群保持所有的消息直到他们过期,无论是否被消费过,一个消费者持有一个offset的值,当消费消息的时候,offset可以线性的增加,消费者也可以控制偏移量重置为更早的位置,读取到更早的消息,并且一个消费者的操作不会影响到其他消费者对这个分区的处理。
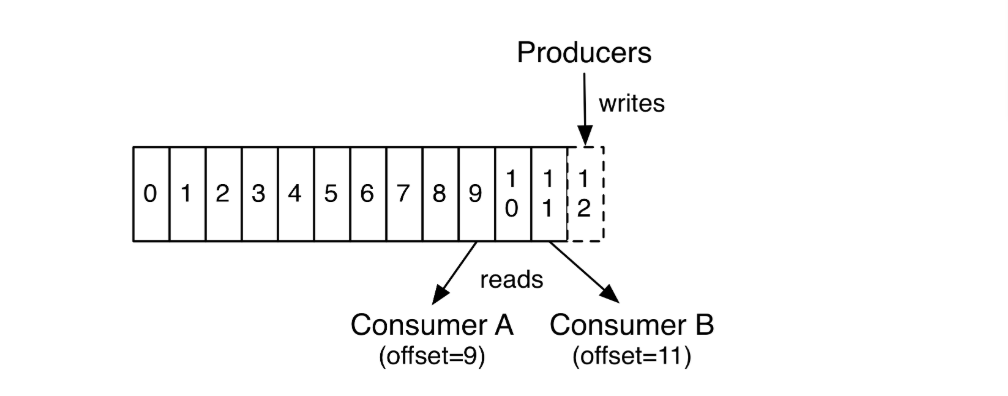
kafka分区的设计有几个目的
- 可以处理更多的消息,不受单台服务器的限制,topic拥有更多的分区意味着它可以不受限制的处理更多的数据,提高队列的吞吐量
- topic分区可以作为并行处理的单元
kafka集群的图示
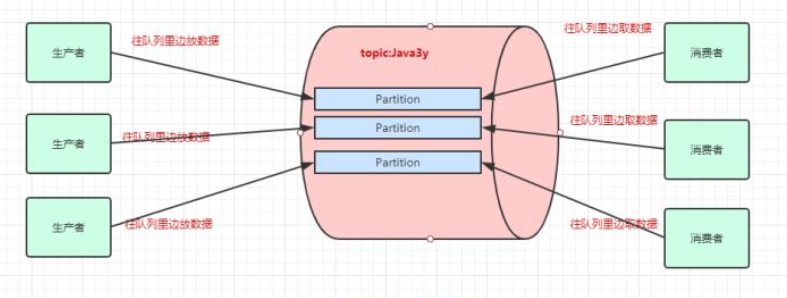
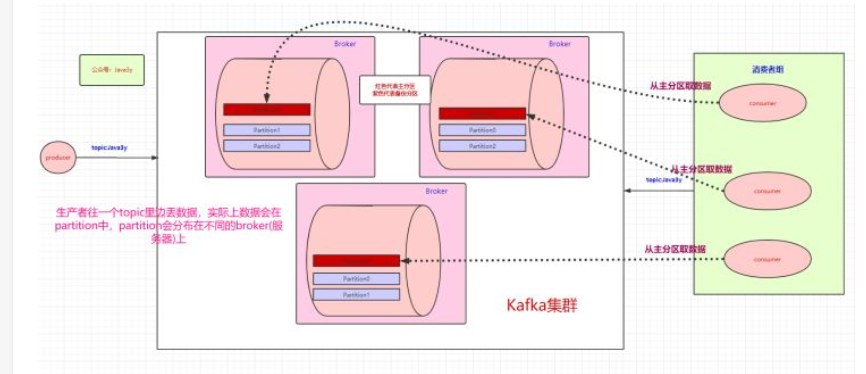
kafka集群的主分区和备份
根据上面的介绍,生产者在topic中存入数据,数据实际上会分布在不同的partition中,这些partition分布在不同的broker(服务器)上,那么当一个服务器宕机了该怎么办
对于这个问题,当我们存储数据时,kafka会将数据存储在一个的broker的主分区中,并且将数据备份到其他broker的备份分区中,每个broker都会有其他的broker的主分区的备份,服务器中生产者和消费者是和主分区进行交互,备份区只是起到备份数据的功能,不做读写。如果某个broker挂了,kafka就会选举出其他broker中的备份分区来作为主分区,这就实现了高可用。
pritition如何持久化数据
kafka会将数据存储在磁盘的消息日志中,不过kafka只允许追加写入,(顺序访问),避免了缓慢的随机IO操作,kafka也不是partition一有数据就立即写入的,他会先缓存一部分,等有足够多的数据或者等一段时间之后,就会一次性将数据写入磁盘。
消费者组
之前是一个消费者消费一个三个分区(一个topic),kafka中有消费者组,所有group.id相同的消费者在一个消费者组中
group.id表示消费者组标识,consumer.id非强制性,目前我也没明白啥意思。
当三个消费者的group.id一样时,就会形成一个消费者组,一个partition只能被消费者组中的一个消费者消费,
所以,现在就可以每个消费者消费一个partition,提高了吞吐量
- 当一个消费者组中的消费者挂掉时,那么其他消费者会分担它的partition
- 当新增一个消费者时,这个消费者会分担其他消费者的partition,而且当消费者多于partition时,会有消费者空闲
- 各个消费者组之间相互独立,彼此不影响
分布式(Distribution)
Leader和follower就是上面提到的主分区和备份分区,这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理。
Geo-Replication(异地数据同步技术)
Kafka MirrorMaker为群集提供geo-replication支持。借助MirrorMaker,消息可以跨多个数据中心或云区域进行复制。 您可以在active/passive场景中用于备份和恢复; 或者在active/passive方案中将数据置于更接近用户的位置,或数据本地化。
不懂。。。。
生产者(Producers)
生产者往某个Topic上发布消息。生产者也负责选择发布到Topic上的哪一个分区。最简单的方式从分区列表中轮流选择。也可以根据某种算法依照权重选择分区。开发者负责如何选择分区的算法。
消费者(Consumers)
通常来讲,消息模型可以分为两种, 队列和发布-订阅式。 队列的处理方式是 一组消费者从服务器读取消息,一条消息只有其中的一个消费者来处理。在发布-订阅模型中,消息被广播给所有的消费者,接收到消息的消费者都可以处理此消息。
kafka的保证
- 生产者发送消息到一个topic上,消息会按他们发送的顺序依次加入,消费者收到的消息也是这个顺序
- 如果一个topic配置了复制因子为N,那么可以允许N-1个服务器宕机而不丢失数据
kafka作为一个消息队列
kafka相对于传统消息队列
传统的消息系统有两种模式,队列和发布订阅模式,队列模式中,消费者池从服务器读取数据,每个消费者只能被其中一个读取,如果读取过程中出现错误,数据丢失之后就无法恢复,在发布订阅模式中允许广播数据给多个订阅者,但是不能缩放处理。
kafka中的消费者组中有两个概念,消费者组中的所有消费者从队列读取数据,相当于队列模式,而不同的消费者组订阅不同的topic,允许广播数据给多个消费者组,各个消费者组之间互不干扰,相当于发布订阅模式。kafka有更强的消息顺序保证
传统的消息系统按顺序保存数据,如果多个消费者从队列消费,则服务器按存储的顺序发送消息,但是,尽管服务器按顺序发送,消息异步传递到消费者,因此消息可能乱序到达消费者。这意味着消息存在并行消费的情况,顺序就无法保证。消息系统常常通过仅设1个消费者来解决这个问题,但是这意味着没用到并行处理。
kafka做的更好。通过并行topic的parition —— kafka提供了顺序保证和负载均衡。每个partition仅由同一个消费者组中的一个消费者消费到。并确保消费者是该partition的唯一消费者,并按顺序消费数据。每个topic有多个分区,则需要对多个消费者做负载均衡,但请注意,相同的消费者组中不能有比分区更多的消费者,否则多出的消费者一直处于空等待,不会收到消息。
kafka作为一个存储系统
所有发布消息到消息队列和消费分离的系统,实际上都充当了一个存储系统(发布的消息先存储起来)。Kafka比别的系统的优势是它是一个非常高性能的存储系统。
写入到kafka的数据将写到磁盘并复制到集群中保证容错性。并允许生产者等待消息应答,直到消息完全写入。
kafka的磁盘结构 - 无论你服务器上有50KB或50TB,执行是相同的。
client来控制读取数据的位置。你还可以认为kafka是一种专用于高性能,低延迟,提交日志存储,复制,和传播特殊用途的分布式文件系统
kafka的流处理
仅仅读,写和存储是不够的,kafka的目标是实时的流处理。
在kafka中,流处理持续获取输入topic的数据,进行处理加工,然后写入输出topic。例如,一个零售APP,接收销售和出货的输入流,统计数量或调整价格后输出。
可以直接使用producer和consumer API进行简单的处理。对于复杂的转换,Kafka提供了更强大的Streams API。可构建聚合计算或连接流到一起的复杂应用程序。
助于解决此类应用面临的硬性问题:处理无序的数据,代码更改的再处理,执行状态计算等。
Sterams API在Kafka中的核心:使用producer和consumer API作为输入,利用Kafka做状态存储,使用相同的组机制在stream处理器实例之间进行容错保障。
一个简单的kafka项目:链接,有时间学习下
kafka笔记——入门介绍的更多相关文章
- Kafka入门介绍
1. Kafka入门介绍 1.1 Apache Kafka是一个分布式的流平台.这到底意味着什么? 我们认为,一个流平台具有三个关键能力: ① 发布和订阅消息.在这方面,它类似一个消息队列或企业消息系 ...
- _00017 Kafka的体系结构介绍以及Kafka入门案例(0基础案例+Java API的使用)
博文作者:妳那伊抹微笑 itdog8 地址链接 : http://www.itdog8.com(个人链接) 博客地址:http://blog.csdn.net/u012185296 博文标题:_000 ...
- 【转帖】Kafka入门介绍
Kafka入门介绍 https://www.cnblogs.com/swordfall/p/8251700.html 最近在看hdoop的hdfs 以及看了下kafka的底层存储,发现分布式的技术基本 ...
- PHP学习笔记 - 入门篇(3)
PHP学习笔记 - 入门篇(3) 常量 什么是常量 什么是常量?常量可以理解为值不变的量(如圆周率):或者是常量值被定义后,在脚本的其他任何地方都不可以被改变.PHP中的常量分为自定义常量和系统常量 ...
- Kafka【入门】就这一篇!
为获得更好的阅读体验,建议您访问原文地址:传送门 前言:在之前的文章里面已经了解到了「消息队列」是怎么样的一种存在(传送门),Kafka 作为当下流行的一种中间件,我们现在开始学习它! 一.Kafka ...
- Kafka从入门到放弃(三) —— 详说生产者
上一篇对Kafka做了简单介绍,还没看的朋友可以点击下方链接. Kafka从入门到放弃(一) -- 初识别Kafka 消息中间件必须与生产者和消费者一起存在才有意义,这次先来聊聊Kafka的生产者. ...
- Kafka从入门到放弃(三)—— 详说消费者
之前介绍了Kafka以及生产者,包括它的一些特性和参数,这回写一下消费者. 之前没看得可以点击链接阅读. Kafka从入门到放弃(一) -- 初识Kafka Kafka从入门到放弃(二) -- 详说生 ...
- C# BackgroundWorker组件学习入门介绍
C# BackgroundWorker组件学习入门介绍 一个程序中需要进行大量的运算,并且需要在运算过程中支持用户一定的交互,为了获得更好的用户体验,使用BackgroundWorker来完成这一功能 ...
- 初识Hadoop入门介绍
初识hadoop入门介绍 Hadoop一直是我想学习的技术,正巧最近项目组要做电子商城,我就开始研究Hadoop,虽然最后鉴定Hadoop不适用我们的项目,但是我会继续研究下去,技多不压身. < ...
随机推荐
- JavaScript基础数组的字面声名法(010)
1.两种方法的对比 数组在JavaScript中,就像大多数的其它语言 一样,是对象.我们可以使用JavaScript内置的数组构造函数Array()来创建数组.就象对象的字面声名法一样,数组也可以采 ...
- HTML重构与网页常用工具
下面这张思维导图,是我对全书大体内容的一个概括性总结: 工具 本书推荐的工具主要包含的是自动化测试,但是我觉得现行的开发环节当中实际用到的会比较少.这里就推荐一下其他方面的优秀工具: 1. YSlow ...
- Orleans 框架3.0 官方文档中文版系列一 —— 概述
关于这个翻译文档的一些说明: 之前逛博客园的时候,看见有个园友在自己的博客上介绍Orleans. 觉得Orleans 是个好东西. 当时心想:如果后面有业务需要的时候可以用用Orleans框架. 当真 ...
- eIQ WSL下工具及环境配置
1. 配置WSL 参考[https://www.cnblogs.com/hayley111/p/12844337.html] 2. 配置VScode 参考[https://zhuanlan.zhihu ...
- Java编程资料
Java相关免费编程书籍推荐(都是PDF版) 编程进阶 2017年9月11日 IDE IntelliJ IDEA 简体中文专题教程 https://github.com/judasn/IntelliJ ...
- [Python] list vs tupple
前言 列表(list)和 元组(tupple) 是 Python 中常见的两种数据结构.这两者使用方法有一定的相似,俩者都是 Python 内置类型,都可以保存数据集合,都可以保存复合数据,我们同样可 ...
- All elments are null 异常
问题描述:1.查询的size是1,但是里面的展示All elmemts are null . 因为之前没有遇到过这个问题,所以先百度了一下,发现有字段不对的,resultMap对不上的,我看了一下都是 ...
- 我们现在的git版本管理
1.git发布正式版都统一用master分支的代码发布2.每次开发下一版本的需求时,将master分支的代码打一个tag,版本号与后台一致3.需要紧急修复线上的bug时,从master分支拉一个分支出 ...
- 机器学习实战基础(二十四):sklearn中的降维算法PCA和SVD(五) PCA与SVD 之 重要接口inverse_transform
重要接口inverse_transform 在上周的特征工程课中,我们学到了神奇的接口inverse_transform,可以将我们归一化,标准化,甚至做过哑变量的特征矩阵还原回原始数据中的特征矩阵 ...
- 数据可视化之PowerQuery篇(九)巧用Power Query,Excel也可以轻松管理文档
https://zhuanlan.zhihu.com/p/111674088 来自知乎一个朋友的问题,如何在Excel中批量插入文件的超链接,以便在Excel中对文档进行有序的目录管理? 这个问题的 ...