字段解析之OopMapBlock(4)
OopMapBlock是一个简单的内嵌在Klass里面的数据结构,用来描述oop中包含的引用类型属性,即该oop所引用的其他oop在oop中的内存分布,然后就可以根据当前oop的地址找到所有引用的其他oop了,其定义如下:
- 源代码位置:oops/instanceKlass.hpp
- // ValueObjs embedded in klass. Describes where oops are located in instances of
- // this klass.
- class OopMapBlock VALUE_OBJ_CLASS_SPEC {
- public:
- // Byte offset of the first oop mapped by this block.
- int offset() const { return _offset; }
- void set_offset(int offset) { _offset = offset; }
- // Number of oops in this block.
- uint count() const { return _count; }
- void set_count(uint count) { _count = count; }
- // sizeof(OopMapBlock) in HeapWords.
- static const int size_in_words() {
- return align_size_up(int(sizeof(OopMapBlock)), HeapWordSize) >>
- LogHeapWordSize;
- }
- private:
- int _offset;
- uint _count;
- };
OopMapBlock结构可以描述某个对象中引用区域的起始偏移和引用个数。offset描述第一个所引用的oop相对于当前oop地址的偏移量,count表示包含的oop的个数,注意这里的包含并不是指这些oop位于OopMapBlock里面,而是有count个连续存放的oop。为啥会有多个OopMapBlock了?因为每个OopMapBlock只能描述当前子类中包含的引用类型属性,父类的引用类型属性由单独的OopMapBlock描述。
之前介绍过,可以利用-XX:+PrintFieldLayout来查看布局情况。该选项只在调试版本中有效。至于布局模式,可以使用-XX:+FieldsAllocationStyle=mode来指定,默认是1。之前介绍过布局模式有3种,如下:
- allocation_style=0,字段排列顺序为oops、longs/doubles、ints、shorts/chars、bytes,最后是填充字段,以满足对齐要求;
- allocation_style=1,字段排列顺序为longs/doubles、ints、shorts/chars、bytes、oops,最后是填充字段,以满足对齐要求;
- allocation_style=2,JVM在布局时会尽量使父类oops和子类oops挨在一起。
当allocation_style的值为2时,父子oop的布局会连续在一起,这样至少有2个好处:
- 减少OopMapBlock的数量。由于GC收集时要扫描存活的对象,所以必须知道对象中引用的内存位置。原始类型不需要扫描。
- 连续的对象区域使得缓存行的使用效率更高。试想如果父对象和子对象的对象引用区域不连续,而中间插入了原始类型字段的话,那么在做GC对象扫描时,很可能需要跨缓存行读取才能完成扫描。
下面我们用HSDB来实际探查下相关的内存布局:
- package jvmTest;
- import java.lang.management.ManagementFactory;
- import java.lang.management.RuntimeMXBean;
- class Base{
- private int a=1;
- private String s="abc";
- private Integer a2=12;
- private int a3=22;
- }
- class A extends Base {
- private int b=3;
- private String s2="def";
- private int b2=33;
- private Base a=new Base();
- }
- class B extends A{
- private String s3="ghk";
- private Integer c=4;
- private int c2=44;
- }
- public class jvmTest {
- public static void main(String[] args) {
- Base a=new Base();
- A a2=new A();
- B b=new B();
- while (true){
- try {
- System.out.println(getProcessID());
- Thread.sleep(600*1000);
- } catch (Exception e) {
- }
- }
- }
- public static final int getProcessID() {
- RuntimeMXBean runtimeMXBean = ManagementFactory.getRuntimeMXBean();
- System.out.println(runtimeMXBean.getName());
- return Integer.valueOf(runtimeMXBean.getName().split("@")[0]).intValue();
- }
- }
运行main方法后,用HSDB查看main线程的线程栈,从中找出变量a,a2,b对应的oop的地址,如下:

分别查看0x00000000d69d98a0,0x00000000d69db5f8,0x00000000d69dd070对应的oop,如下:

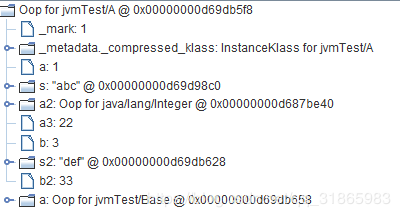

上从面的截图可知,子类会完整的保留父类的属性,从而方便调用父类方法时能够正确的使用父类的属性。上述对oop的属性打印是按照类声明属性的顺序来的,内存中是这样保存的么?可以通过查看属性的偏移量来判断。
在Class Browser中搜索jvmTest,可以查找到我们三个自定义类对应的Klass,如下图:
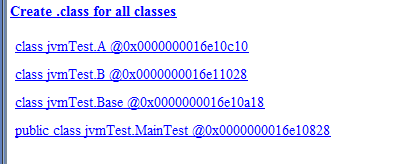
分别点击这三个类查看属性的偏移量,如下:



根据上述偏移量,我们可以得出jvmTest.B对象的内存布局,如下:

int本身占4个字节,引用类型属性本质上就是一个指针,这里因为默认开启了指针压缩,所以也是4字节。
我们再看下表示OopMapBlock在Klass中的字宽数的属性_nonstatic_oop_map_size在三个类中的取值,如下:
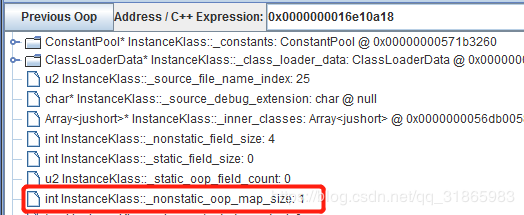
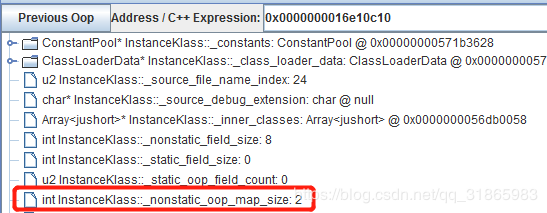
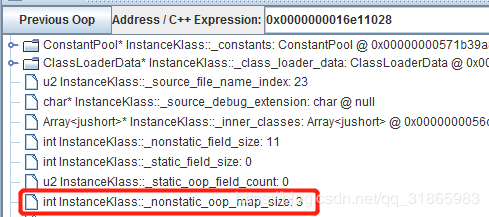
OopMapBlock本身就只有两个int属性,所以一个OopMapBlock实例只有8字节,即一个字宽,jvmTest.B的_nonstatic_oop_map_size属性值为3,即由3个OopMapBlock,下面通过CHSDB的mem命令来看看这3个OopMapBlock对应的内存数据。
首先执行inspect对象得到该Klass本身的大小,即sizeof的大小,如下:

vtable,itable,OopMapBlock这三个都是内嵌在Klass里面的,所谓的内嵌实际是指这块内存是紧挨着Klass自身的属性对应的内存的下面,从上一节的分析可知,OopMapBlock在itable的后面,itable在vtable的后面,而vtable是紧挨着Klass的,从上述inspect命令的输出,也可知道itable和vtable的内存大小,单位是字宽,如下:

因此OopMapBlock的起始地址就是Klass的地址加上Klass本身的大小440字节即55字宽,再加上vtable的5字宽,itable的2字宽,总共加62字宽,OopMapBlock本身占用3个字宽,因此用mem查看这65字宽的数据,如下:

最后的3个字宽如下:

每个字宽对应一个OopMapBlock,前面4字节就是count属性,这里都是2,后面4字节就是offset,分别是20,36,48,与jvmTest.B的内存结构是完全一致的。
相关文章的链接如下:
1、在Ubuntu 16.04上编译OpenJDK8的源代码
13、类加载器
14、类的双亲委派机制
15、核心类的预装载
16、Java主类的装载
17、触发类的装载
18、类文件介绍
19、文件流
20、解析Class文件
21、常量池解析(1)
22、常量池解析(2)
23、字段解析(1)
24、字段解析之伪共享(2)
25、字段解析(3)
作者持续维护的个人博客classloading.com。
关注公众号,有HotSpot源码剖析系列文章!

参考文章:
(1)https://zhuanlan.zhihu.com/p/28226360
(2)https://blog.csdn.net/lqp276/article/details/52190503
(3)https://blog.csdn.net/qq_31865983/article/details/104284546#t3
(6)https://blog.csdn.net/qq_31865983/article/details/104284546#4%E3%80%81OopMapBlock
字段解析之OopMapBlock(4)的更多相关文章
- 简单sql字段解析器实现参考
用例:有一段sql语句,我们需要从中截取出所有字段部分,以便进行后续的类型推断,请给出此解析方法. 想来很简单吧,因为 sql 中的字段列表,使用方式有限,比如 a as b, a, a b... 1 ...
- iis日志字段解析
IIS日志字段 #Software: Microsoft Internet Information Services 7.5 #Version: 1.0 #Date: 2013-08-21 01:00 ...
- C++11 STL Regex正则表达式与字符串字段解析
简单的日期正则表达式 一个简单的日期解析程序,从yyyy-mm-dd格式的日期字符串中,分别获取年月日. 先设置一个简单的正则表达式,4位数字的"年",1-2位数字的"月 ...
- Linux iostat字段解析
iostat主要用于监控系统设备的IO负载情况,iostat首次运行时显示自系统启动开始的各项统计信息,之后运行iostat将显示自上次运行该命令以后的统计信息.用户可以通过指定统计的次数和时间来获得 ...
- Linux mpstat字段解析
mpstat是Multiprocessor Statistics的缩写,是实时系统监控工具.其报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中.在多CPUs系统里,其不但能查看所有 ...
- Linux free字段解析
下面是free的运行结果,一共有4行.为了方便说明,我加上了列号.这样可以把free的输出看成一个二维数组FO(Free Output).例如: FO[2][1] = 24677460 FO[3][2 ...
- python scapy dns 包字段解析
qr: 0表示查询报文,1表示响应报文opcode: 通常值为0(标准查询),其他值为1(反向查询)和2(服务器状态请求).aa: 表示授权回答(authoritative answer)tc: ...
- python orm字段解析
null # 是否可以为空 default # 默认值 primary_key # 主键 db_column # 列名 db_index # 索引(db_index=True) unique # 唯一 ...
- 【转】odoo学习之:开发字段解析
odoo新API中,字段类型不变,继承改变 1.旧的API定义模型: from openerp.osv import osv,fields class oldmodel(osv.osv): #模型名称 ...
随机推荐
- vue 集成html5 plus
首先要安装一个包 vue-html5plus npm i vue-html5plus -S 然后配置这个文件 在main.js添加一串代码 var onPlusReady = function (ca ...
- MySQL 三万字精华总结 + 面试100 问,吊打面试官绰绰有余(收藏系列)
写在之前:不建议那种上来就是各种面试题罗列,然后背书式的去记忆,对技术的提升帮助很小,对正经面试也没什么帮助,有点东西的面试官深挖下就懵逼了. 个人建议把面试题看作是费曼学习法中的回顾.简化的环节,准 ...
- MySQL索引——总结篇
MySQL索引 MySQL索引 数据库的三范式,反模式 零碎知识 索引 索引原理 B Tree索引 B+Tree索引 B Tree 与 B+Tree的比较 聚集索引和辅助索引 聚集索引的注意事项 索引 ...
- “我放弃了年薪20W的offer......”
我的职业生涯开始和大多数测试人一样,开始接触都是纯功能界面测试.那时候在一家电商公司做测试,做了有一段时间,熟悉产品的业务流程以及熟练测试工作流程规范之后,效率提高了,工作比较轻松,也得到了更好的机会 ...
- OSCP Learning Notes - Exploit(2)
Compiling an Exploit Exercise: samba exploit 1. Search and download the samba exploit source code fr ...
- Python Ethical Hacking - VULNERABILITY SCANNER(2)
VULNERABILITY_SCANNER How to discover a vulnerability in a web application? 1. Go into every possibl ...
- 集训作业 洛谷P1032 字串变换
集训的题目有点多,先写困难的绿题吧(简单的应该想想就会了) 嗯,这个题看起来像个搜索呢(就是个搜索) 我们仔细想想就知道这个题肯定不能用深搜,可以优化的地方太少了,TLE是必然的. 那我们该怎么办呢? ...
- db2创建nickname
db2创建nickname创建步骤 1.创建 server create server servername type DB2/AIX version 10.5 wrapper drda authid ...
- 数字货币交易所(火币为例)如何使用二次验证码/虚拟MFA/两步验证/谷歌验证器?
一般点账户名——设置——安全设置中开通虚拟MFA两步验证 具体步骤见链接 数字货币交易所(火币为例)如何使用二次验证码/虚拟MFA/两步验证/谷歌验证器? 二次验证码小程序于谷歌身份验证器APP的优 ...
- WeChat 小程序开发
第一步 去微信公众号平台注册> 一个账号https://mp.weixin.qq.com/ 填写完后 会获得一个APPID 2. 点击工具下载微信开发者工具安装即可, 1 2 3 微信开发者工具 ...